G1GC慢的排查过程分享

本文主要分析严选库存中心压测期间G1GC收集比较慢的问题。
背景
11月6日严选全链路压测期间,发现有部分机器RT有毛刺。耗时相对其余时间较为明显。现象如下:
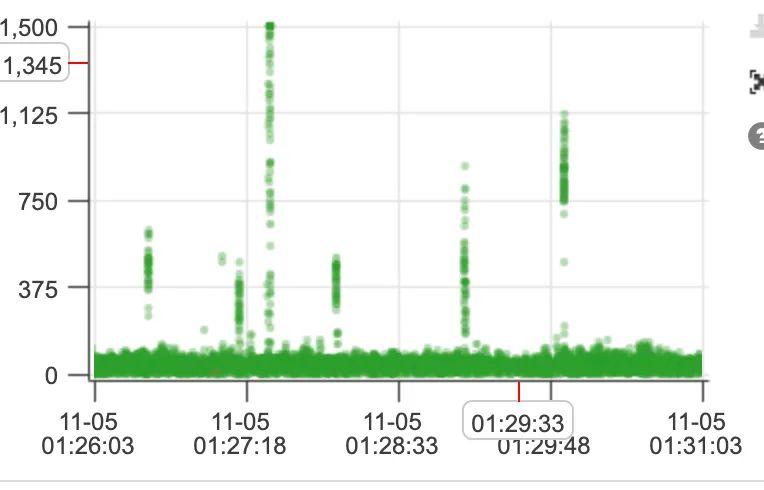
问题定位
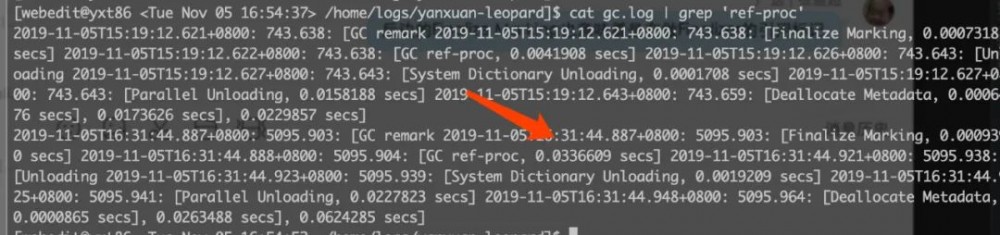
利用严选caesar分析很快清楚大部分情况是DB的瓶颈。但是还有部分卡在了和DB毫不相干的逻辑上。这里很快就明白应该是卡在GC这一层。查看生产环境GC日志果然在对应时刻又发现如下的gc.log:
2019-11-05T01:27:25.579+0800: 380439.759: [GC remark
2019-11-05T01:27:25.579+0800: 380439.759: [Finalize Marking, 0.0013365 secs]
2019-11-05T01:27:25.580+0800: 380439.761: [GC ref-proc, 0.6261676 secs]
2019-11-05T01:27:26.206+0800: 380440.387: [Unloading
2019-11-05T01:27:26.208+0800: 380440.389: [System Dictionary Unloading, 0.0018171 secs]
2019-11-05T01:27:26.210+0800: 380440.391: [Parallel Unloading, 0.0383157 secs]
2019-11-05T01:27:26.848+0800: 380441.029: [Deallocate Metadata, 0.0002577 secs],
0.0425845 secs],
0.6744903 secs]
这里能明显看到两个细节:
-
[GC ref-proc, 0.6261676 secs]
-
Finalize Marking
好了基本确定和GC有关了。
关于Finalize Marking和ref-proc
在当前使用的jvm版本中,普通的Java对象和Reference对象处理的逻辑是不一致的。Reference对象(包括SoftReference, WeakReference, PhantomReference, Finalizer)的回收有专属的处理逻辑。此处初始化代码可见:
https://hg.openjdk.java.net/jdk8u/jdk8u/hotspot/file/b44df6c5942c/src/share/vm/gc_implementation/g1/g1CollectedHeap.cpp#l2214
// STW ref processor
_ref_processor_stw =
new ReferenceProcessor(mr, // span
ParallelRefProcEnabled && (ParallelGCThreads > 1), // mt processing
MAX2((int)ParallelGCThreads, 1), // degree of mt processing
(ParallelGCThreads > 1), // mt discovery
MAX2((int)ParallelGCThreads, 1), // degree of mt discovery
true, // Reference discovery is atomic
&_is_alive_closure_stw); // is alive closure
// (for efficiency/performance)
从这里能看出jvm在初始化过程中,是可选对于引用对象是单线程还是多线程回收的。默认情况下,ParallelRefProcEnabled这个选项关闭,即使用单线程回收去遍历所有的Reference对象。这在Reference对象较多的情况下确实会成为一定的瓶颈。
当打开ParallelRefProcEnabled时,对应的ParallelGCThreads计算逻辑在:
https://hg.openjdk.java.net/jdk8u/jdk8u/hotspot/file/b44df6c5942c/src/share/vm/runtime/vm_version.cpp#l301
unsigned int Abstract_VM_Version::nof_parallel_worker_threads( unsigned int num, unsigned int den, unsigned int switch_pt) {
if (FLAG_IS_DEFAULT(ParallelGCThreads)) {
assert(ParallelGCThreads == 0, "Default ParallelGCThreads is not 0");
// For very large machines, there are diminishing returns
// for large numbers of worker threads. Instead of
// hogging the whole system, use a fraction of the workers for every
// processor after the first 8. For example, on a 72 cpu machine
// and a chosen fraction of 5/8
// use 8 + (72 - 8) * (5/8) == 48 worker threads.
unsigned int ncpus = (unsigned int) os::initial_active_processor_count();
return (ncpus <= switch_pt) ? ncpus : (switch_pt + ((ncpus - switch_pt) * num) / den);
} else {
return ParallelGCThreads;
}
}
可以看到在当前机器为8核的情况下,最终算出来的线程数为8。
而真正处理引用对象回收的代码可见:
https://hg.openjdk.java.net/jdk8u/jdk8u/hotspot/file/b44df6c5942c/src/share/vm/memory/referenceProcessor.cpp#l892
size_t
ReferenceProcessor::process_discovered_reflist(
DiscoveredList refs_lists[],
ReferencePolicy* policy,
bool clear_referent,
BoolObjectClosure* is_alive,
OopClosure* keep_alive,
VoidClosure* complete_gc,
AbstractRefProcTaskExecutor* task_executor)
{
bool mt_processing = task_executor != NULL && _processing_is_mt;
// If discovery used MT and a dynamic number of GC threads, then
// the queues must be balanced for correctness if fewer than the
// maximum number of queues were used. The number of queue used
// during discovery may be different than the number to be used
// for processing so don't depend of _num_q < _max_num_q as part
// of the test.
bool must_balance = _discovery_is_mt;
if ((mt_processing && ParallelRefProcBalancingEnabled) || must_balance)
{
balance_queues(refs_lists);
}
...
这里能明显看出来是否对于并发处理有做了区分。这个阶段也就是上面描述的ref-proc。
所以现在的问题变成了:为什么有这么多的Finalizer引用?
使用jmap -histo查看当时对象快照如下:
num #instances #bytes class name
----------------------------------------------
1: 248174 238918760 [B
2: 1286746 139404600 [C
3: 297861 25537144 [I
...
35: 22044 1058112 java.net.SocketInputStream
36: 22044 1058112 java.net.SocketOutputStream
37: 12688 1015040 redis.clients.jedis.Client
38: 25031 1001240 java.lang.ref.Finalizer
...
这几个对象出现的太突兀了。
commons-pool的驱逐机制
这个问题之前在另外一个问题中碰到,可以点击这里查看。
通俗点按顺序描述就是:
-
利用agent观察是谁在创建这么多的Socket对象,最终发现是commons-pool-EvictionTimer线程,而系统中使用commons-pool的地方是jedis连接池;
-
commons-pool会定时驱逐当前连接池中状态是idle的对象,使idle始终保持新鲜活跃状态,这会导致频繁的创建连接,jedis配置越大同时实际idle越多,实例创建越频繁;
-
jedis本身的连接基于Socket,是AbstractPlainSocketImpl的子类,而AbstractPlainSocketImpl实现了Finalizer方法;
-
产生了Finalizer引用。
贴下我们的jedis配置:
<bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig">
<property name="minIdle" value="100"/>
<property name="maxIdle" value="200"/>
<property name="maxTotal" value="500"/>
</bean>
总结
再重复下整个问题的链路。
-
不合理的jedis连接池配置,导致实际的idle连接会过多;
-
commons-pool会定时驱逐当前连接池中状态是idle的对象,使idle始终保持新鲜活跃状态;
-
jedis本身的连接基于Socket,是AbstractPlainSocketImpl的子类,而AbstractPlainSocketImpl实现了Finalizer方法;
-
产生了Finalizer引用,导致GC需要使用ReferenceProcess进行单线程处理。
-
当Finalizer数量增多,单线程开始吃力,整个GC耗时拉长
由于代码修改相对成本更高,所以最终加入jvm参数-XX:+ParallelRefProcEnabled并完成重启。重启后一段时间内加后续压测系统表现明显好转。
后续要做的就是合理调整redis的配置即可。
作者简介
盈超,2018年加入网易严选,目前参与严选库存中心以及库存周边的数据开发工作。曾在淘宝负责卖家中心,用户开店,商品心选等业务。对于JVM以及系统的疑难杂症有浓厚兴趣。
本文由作者授权严选技术团队发布


正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

