为 Cloud Spanner 引入 Hibernate ORM 以便使用数据库
文 / Mike Eltsufin,软件工程师
Google Cloud 线上课堂
5 月 21 日的 Google Cloud 线上课堂,技术工程师郭斌讲带领大家了解企业如何进行数据库的选型,并针对介绍 Cloud Spanner 的技术特性,了解如何在具体场景中释放 Cloud Spanner 的工程能力。
流程安排及报名须知请参见文章末尾。
当您采用新的数据库技术时,如何学习新的 SQL 方言或编写新的数据持久层逻辑,都是需要考虑的事项。我们希望尽可能简化这一流程。对于此类工作,Hibernate 实际上已成为 Java 项目的标准对象关系映射 (ORM) 解决方案。Hibernate 支持所有主要关系型数据库,并支持 Spring Data JPA 等功能更为强大的 ORM 工具。
我们已开发出全新开源 Cloud Spanner Dialect for Hibernate ORM ,让用户能够更加轻松地采用 Cloud Spanner。现在,您可以通过 Hibernate 所习惯使用的数据持久层处理获得 Cloud Spanner 的优势:即可扩展性和关系数据库语义。这样一来,您可以将现有应用程序迁移到云中,或使用 Hibernate 兼容环境的常用 API(例如 JPA、Spring Data JPA、Microprofile 和 Quarkus)编写新的应用。
Hibernate ORM 提供以下两大主要优势,可帮助解决采用新数据库技术时面临的挑战:跨数据库的可移植性,以及创建-读取-更新-删除 (CRUD) 逻辑的易编写性。借助这些优势,开发者的工作效率得以提高,云数据库的采用速度也得到提升。
如需了解详细信息,请查看我们的 文档 、 git 代码库 ,或试用 Codelab 。
用 Hibernate 和 Cloud Spanner 编写 Java 应用
接下来,我们将为您简要介绍如何编写使用 Hibernate 访问 Cloud Spanner 的 Java 应用。具体步骤与您在 Codelab 中看到的类似。我们将创建一个应用,将音乐人及其专辑存储在 Cloud Spanner 中。虽然这只是一个基本的 Hibernate 示例,但请记住,此方法也适用于由 Hibernate 提供支持的 JPA 型系统。
我们需要适用于 Hibernate 的 Cloud Spanner 方言, 开源 Cloud Spanner JDBC 驱动程序 ,以及 Hibernate 核心。我们先将这些依赖项添加至应用。
pom.xml
<dependencies>
<!-- Spanner Dialect -->
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-hibernate-dialect</artifactId>
<version>1.0.0</version>
</dependency>
<!-- JDBC Driver -->
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-spanner-jdbc</artifactId>
<version>1.11.0</version>
</dependency>
<!-- Hibernate -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>5.4.9.Final</version>
</dependency>
</dependencies>
现在,告知 Hibernate 我们会将哪些注解实体类映射至数据库。
src/main/resources/hibernate.cfg.xml
<hibernate-configuration>
<session-factory>
<!-- Annotated entity classes -->
<mapping class="demo.Album"/>
<mapping class="demo.Singer"/>
</session-factory>
</hibernate-configuration>
Hibernate 也需要知道如何连接到 Cloud Spanner 实例以及使用哪种方言。于是,我们指示 Hibernate 使用适合 SQL 语法的 SpannerDialect 、Cloud Spanner JDBC 驱动程序,以及带有数据库坐标的 JDBC 连接字符串。
src/main/resources/hibernate.properties
hibernate.dialect=com.google.cloud.spanner.hibernate.SpannerDialect
hibernate.connection.driver_class=com.google.cloud.spanner.jdbc.JdbcDriver
hibernate.connection.url=jdbc:cloudspanner:/projects/{INSERT_PROJECT_ID}/instances/{INSERT_INSTANCE_ID}/databases/{INSERT_DATABASE_ID}
# auto-create and update DB schema
hibernate.hbm2ddl.auto=update
我们将使用 GOOGLE_APPLICATION_CREDENTIALS 环境变量中的服务帐号 JSON 文件,或使用通过 gcloud auth application-default login 命令配置的应用默认凭据来确保完成身份验证凭据设置。
现在我们准备就绪,可以编写一些代码。
我们将定义两个普通的旧 Java 对象 (POJO),其将映射到 Cloud Spanner 中的两个表格( Singer 和 Album )。 Album 将与 Singer 建立 @ManyToOne 关系。我们也可以将 Singers 映射到带有 @OneToMany 注解的 Albums 列表,但在此示例中,我们不希望每次需要从数据库中获取歌手时都加载所有专辑。
由于没有现成的数据库架构,我们添加了 hibernate.hbm2ddl.auto=update 属性,以便让 Hibernate 于首次运行应用时在 Cloud Spanner 中创建两个表格。
src/main/java/demo/Application.java
@Entity
class Singer {
@Id
@GeneratedValue
@Type(type = "uuid-char")
UUID singerId;
String firstName;
String lastName;
@Temporal(TemporalType.DATE)
Date birthDate;
}
@Entity
class Album {
@Id
@GeneratedValue
@Type(type = "uuid-char")
UUID albumId;
@ManyToOne
Singer singer;
String albumTitle;
}
此外,还需要为每个实体添加无参数的构造函数 hashCode() 和 equals() ,因为 Hibernate 需要这些函数。您可在 完整示例 中查看全部操作。
此外,在此示例中,我们将使用自动生成的 UUID 作为主键。这是 Cloud Spanner 中的首选 ID 类型,因为其避开了系统按照键范围在服务器之间划分数据时的热点。也可使用单调递增的整数键,但性能可能会下降。
配置好所有内容并定义了实体对象之后,我们即可开始写入数据库。
创建 Hibernate Session 。
src/main/java/demo/Application.java
StandardServiceRegistry registry = new StandardServiceRegistryBuilder().configure().build();
SessionFactory sessionFactory = new MetadataSources(registry).buildMetadata()
.buildSessionFactory();
Session session = sessionFactory.openSession();
现在,将一些数据写入 Cloud Spanner。
src/main/java/demo/Application.java
session.beginTransaction();
Singer singerMelissa = new Singer("Melissa", "Garcia", makeDate("1981-03-19"));
Album albumGoGoGo = new Album(singerMelissa, "Go, Go, Go");
session.save(singerMelissa);
session.save(albumGoGoGo);
session.save(new Singer("Russell", "Morales", makeDate("1978-12-02")));
session.save(new Singer("Jacqueline", "Long", makeDate("1990-07-29")));
session.save(new Singer("Dylan", "Shaw", makeDate("1998-05-02")));
session.getTransaction().commit()
此时,如果您转到 Cloud Spanner 控制台并查看数据库中“歌手”和“专辑”表格的数据,则会看到以下内容:
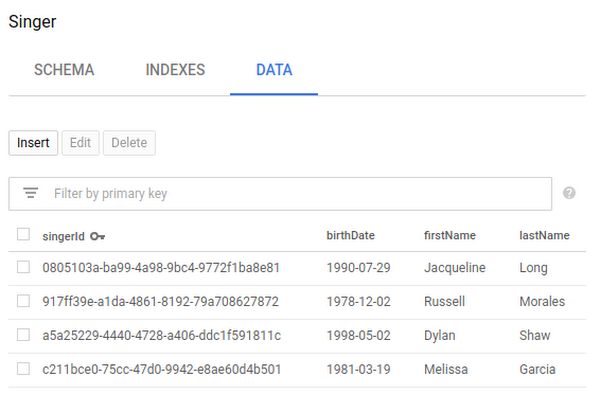
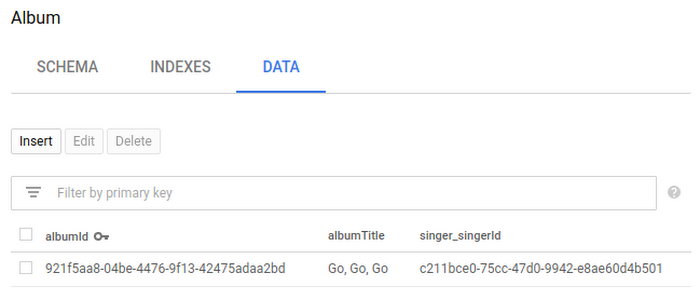
能够在 Cloud Console 中轻松浏览数据库表很好,但我们还希望能够在自己的应用中查询这些数据库表。因此最后,我们来使用 Hibernate 查询一些数据。请注意,我们使用的是 HQL,其可在各种 Hibernate 方言之间移植,而不仅仅是 Cloud Spanner。
src/main/java/demo/Application.java
List<Singer> singers =
session.createQuery("from Singer where birthDate >= '1990-01-01'").list();
List<Album> albums = session.createQuery("from Album").list();
最后,请务必先关闭 Hibernate 资源,然后再关闭应用。
src/main/java/demo/Application.java
session.close(); sessionFactory.close();
如需了解详细信息, 请查看完整工作示例 ,或查看使用 Spring Data JPA 、 Microprofile 或 Quarkus 的其他代码示例之一。请在 Cloud Spanner 上试用 Hibernate,然后通过 Github 问题跟踪器 发送您的反馈。
Google Cloud 线上课堂
主题: Cloud Spanner: 释放强大云原生数据库能力
活动日期 : 2020/5/21 15:00-16:00
活动日程:

如果您想详细了解 本文讨论 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
-
Spring Data JPA
https://spring.io/projects/spring-data-jpa
-
Cloud Spanner Dialect for Hibernate ORM
https://github.com/GoogleCloudPlatform/google-cloud-spanner-hibernate
-
Cloud Spanner https://cloud.google.com/spanner/
-
Hibernate ORM
https://hibernate.org/orm/
-
文档
https://cloud.google.com/spanner/docs/use-hibernate
-
git 代码库
https://github.com/GoogleCloudPlatform/google-cloud-spanner-hibernate
-
Codelab
https://codelabs.developers.google.com/codelabs/cloud-spanner-hibernate
-
开源 Cloud Spanner JDBC 驱动程序
https://cloud.google.com/spanner/docs/use-oss-jdbc
-
完整示例 https://github.com/GoogleCloudPlatform/google-cloud-spanner-hibernate/tree/master/google-cloud-spanner-hibernate-samples/spanner-hibernate-codelab
-
Spring Data JPA https://github.com/GoogleCloudPlatform/google-cloud-spanner-hibernate/tree/master/google-cloud-spanner-hibernate-samples/spring-data-jpa-sample
-
Microprofile
https://github.com/GoogleCloudPlatform/google-cloud-spanner-hibernate/tree/master/google-cloud-spanner-hibernate-samples/microprofile-jpa-sample
-
Quarkus
https://github.com/GoogleCloudPlatform/google-cloud-spanner-hibernate/tree/master/google-cloud-spanner-hibernate-samples/quarkus-jpa-sample
-
Github 问题跟踪器 https://github.com/GoogleCloudPlatform/google-cloud-spanner-hibernate/issues

正文到此结束
- 本文标签: 服务器 数据 CTO 软件 dataSource http ORM equals update js 开发者 UDP list 企业 DDL Service session java https UI 软件工程师 value Developer core Action 工程师 spring git 配置 代码 XML 开源 entity neToMany id 云 pom map GitHub json final src ManyToOne Master db sql Google 实例 开发 build JPA 希望 IBM cat API google cloud dependencies schema 文章 IO tk tab 数据库 NSA App 参数 Connection 删除 自动生成 JDBC
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

