看了这篇【JIT编译器】,你也能说你会java性能优化了!
大家好,我是小菜,一个渴望在互联网行业做到蔡不菜的小菜。可柔可刚,点赞则柔,白嫖则刚!
死鬼~看完记得给我来个三连哦!

本文主要介绍
java性能分析 之 JIT编译器
如有需要,可以参考
如有帮助,不忘 点赞 ❥
创作不易,白嫖无义!
参考书籍 :《Java性能权威指南》
作为Java开发人员,也许在工作中最经常用到的只是 CRUD , 解决性能问题 也许不经常接触到,但是也是需要了解一二的!这篇文章小菜带你一起探究 Java性能优化之JIT编译器 。
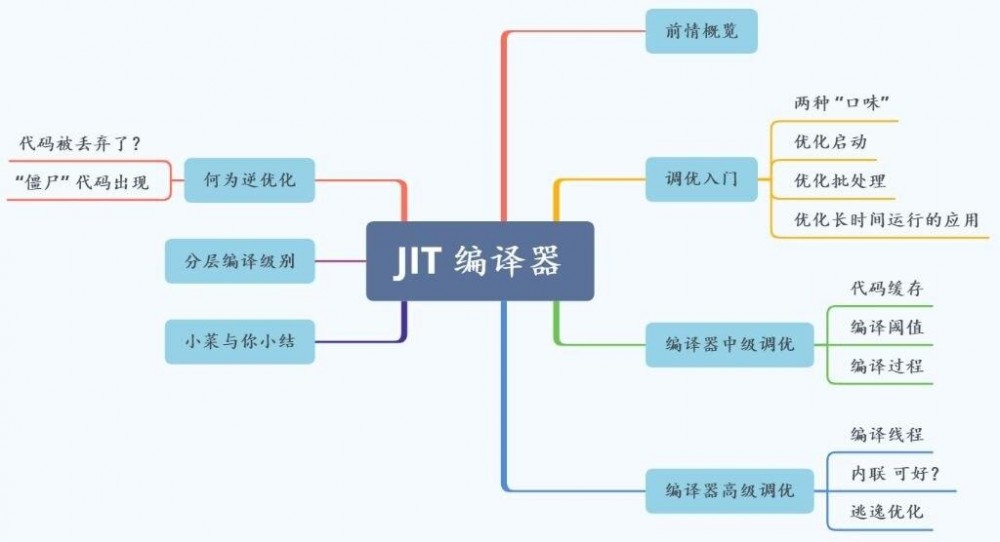
前情概览
即时 JIT(JUst-In-Time) 编译器是Java虚拟机的核心,对 JVM性能 影响最大的也就是编译器。
CPU 是计算机的核心,到时只能执行相对少而且特定的指令,例如 汇编码 和 二进制码 ,因此 CPU 所执行的程序都必须翻译成这种指令。
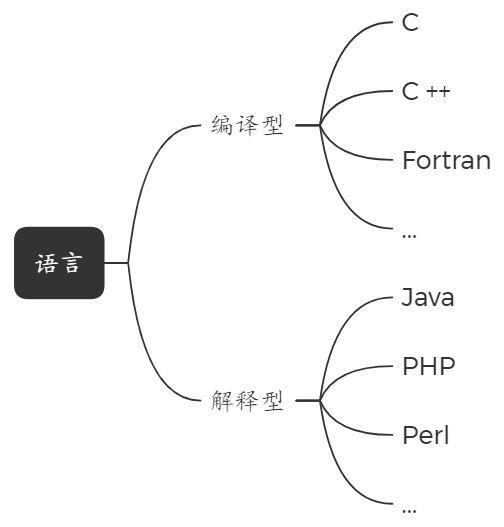
- 编译型语言:会编译成 二进制形式 交付,先写程序,然后用编译器静态生成二进制文件。
- 解释型语言:只要机器上有合适的解释器,相同的程序代码可以在任何 CPU 上执行,执行程序时,解释器会将相应代码转换为二进制代码。
Java试图走一条中间路线,Java应用会被编译——但不是编译成特定 CPU 所专用的二进制编码,而是被编译成一种理想化的汇编语言。然后该汇编语言(Java字节码)可以用Java运行 。因此 Java 是一门 平台独立性 的 解释型语言 。
热点编译
JVM 执行代码时,只会编译经常被调用的。因此被编译的代码需要具备以下特性:
- 代码是经常被调用的代码
- 运行很多次迭代的循环
而这些关键代码段被称为 应用的热点 ,代码执行得越多就被认为是 越热 的。因此编译器 会先解释执行代码,然后找出哪个方法被调用的足够频繁,才进行编译 。这也是为了 优化 :JVM 执行特定方法或者循环的次数越多,它就会越了解这段代码,这样可以使 JVM 在编译代码时进行大量优化。
小结
- Java的设计结合了脚本语言的平台独立性和编译型语言的本地性能
- Java文件被编译成中间语言(Java字节码),然后在运行时被JVM进一步编译成汇编语言
- 字节码编译成汇编语言的过程中有大量的优化,极大地改善了性能
调优入门
一、两种 “口味”
- Client 编译器
- Server编译器
命令行上选择编译器类型则采用以上两个名字: -client 和 -server 。通常这两个编译器也称为 c1 编译器(client编译器) 和 c2 编译器(server编译器)
分层编译器 :分层编译意味着必须使用 server 编译器
关闭分层编译: java -client -XX:+TieredCompilation other_args
两者的主要区别:
在于编译代码的时机不同。client编译器开启编译比server编译器要早。这意味着;在代码执行的开始阶段,client编译器比server编译器要快,因为他编译代码相比server编译器而言要多。
问题来了 :
JVM 能不能在启动的时候用 client 编译器,然后随着代码变热使用 server 编译器?
方案:
分层编译:代码先由 client 编译器编译,随着代码变热, 由 server 编译器重新编译。在 Java 1.8 中,分层编译是默认开启的。
二、优化启动
当快速启动时间是首要目标时了,最常使用 client 编译器。
当整体性能比启动性能更重要时,更适合使用 server 编译器。
小结:
- 如果应用的启动时间是首要的性能考量,那 client 编译器就是最有用的。
- 分层编译的启动时间可以非常接近于 client 编译器所获得的启动时间。
三、优化批处理
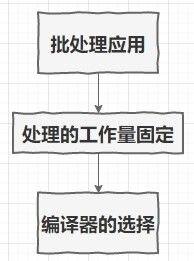
归根结底取决于哪种编译器使得应用运行的时间最优。
- 分层编译是批处理任务合理的默认选择
- 分层编译是适合所有情况的很好的备选方案
- 分层编译总是比标准的 server 编译器好一些
- 即便应用永远运行,server 编译器也不可能编译它的所有代码
- 对于计算量固定的任务来说,应该选择实际执行任务最快的编译器
四、优化长时间运行的应用
通常来说,在应用 “热身” 之后,意味着它已经运行了足够长的时间,重要的代码都已经被编译,这个时候便可以测试它处理的吞吐量。一个应用测试结果:
| 热身期 (秒) | - client | - server | -XX:+TieredCompilation |
|---|---|---|---|
| 0 | 15.87 | 23.72 | 24.23 |
| 60 | 16.00 | 23.73 | 24.26 |
| 300 | 16.85 | 24.42 | 24.43 |
相比单独的 server 编译器,分层编译可以编译更多代码,提供更多的性能。
对于长时间运行的应用来说,应该一直使用 server 编译器,最好配合分层编译。
编译器中级调优
大多数情况下,所谓编译器调优,其实就只是为目标机器上的 Java 选择正确的 JVM和编译器开关( -client -server -XX:+TieredCompilation )而已。分层编译通常是长期运行应用的最佳选择,而对于运行时间短的应用来说,分层编译与 client 编译器的性能差别也微乎其微。
一、代码缓存
JVM 编译代码时,会在代码缓存中保留编译之后的汇编语言指令集。代码缓存的大小固定,所以一旦填满,JVM 就不能编译更多代码了。 代码缓存过小 会导致只有部分热点编译,而应用的大部分代码都只是解释运行 —> 运行慢
代码缓存填满时,JVM会发出以下警告:
JAVA HotSpot(TM) 64-Bit Server VM warning:CodeCache is full
Compiler has been disabled
JAVA HotSpot(TM) 64-Bit Server VM warning:Try increasing the
code cache size using -XX:ReservedCodeCacheSize=
复制代码
| JVM 类型 | 代码缓存的默认大小 |
|---|---|
| 32 位 client,Java 8 | 32 MB |
| 32 位 server,分层编译,Java 8 | 240 MB |
| 64 位 server,分层编译,Java 8 | 240 MB |
| 32 位 client,Java 7 | 32 MB |
| 32 位 server,Java 7 | 32 MB |
| 64 位 server,Java 7 | 48 MB |
| 64 位 server,分层编译,Java 7 | 96 MB |
设置代码缓存最大值
-XX:ReservedCodeCacheSize=N
设置代码缓存初始大小
-XX:InitialCodeCacheSize=N
小结
-
代码缓存是一种有最大值的资源,它会影响 JVM 可运行的编译代码总量。
-
分层编译很容易达到代码缓存默认配置的上限(特别是在 Java 7)。使用分层编译时,应该监控代码缓存,必要时应该增加它的大小。
二、编译阈值
编译阈值和 代码执行的频度 有关,一旦代码执行达到一定次数,并且达到了编译阈值,编译器就可以获得足够多的信息来进行代码的编译。
编译是基于两种 JVM 计数器
- 方法调用计数器
- 方法中的循环回边计数器(回边可以看做是循环完成执行的次数,所谓循环完成执行,包括达到循环自身的末尾,也包括执行了像 continue 这样的分支语句)
1. 标准编译
JVM 执行了某个 Java 方法时,会检查该方法的两种计数器总数,然后判定该方法是否适合编译,如果适合,该方法就会进入编译队列。
更改编译阈值
由 -XX:CompileThreshold=N 标志触发,使用 client 编译器时,N 的默认值是 1500 ,使用 server 编译器时,N 的默认值是 10 000 ,更改 CompileThreshold 将会使编译器提高(或延迟)编译。
问题:
如果循环很长或者永远不会退出,怎么计数?
这种情况下,JVM 不等方法调用完成就会编译循环,所以循环每完成一轮,回边计数器就会增加并被检测。
2. 栈上编译 (OSR)
由于仅仅编译循环还不够,JVM 必须在循环进行的时候还能编译循环,在循环代码编译结束后,JVM 就会替换还在栈上的代码,循环的下一次迭代就会执行快得多的编译代码。
实际上会出现有些重要的方法永远不会被编译 。因为并不是还没达到编译阈值,而是 永远都达不到编译阈值 !
这是因为虽然计数器随着方法和循环的执行而增加,但是它们也会随时间而减少。这种方法也称为 温热方法
小结:
- 当方法和循环执行次数达到某个阈值的时候,就会发生编译
- 改变阈值会导致代码提早或推后编译
- 由于计数器会随着时间而减少,以至于 "温热方法" 可能永远都打不到编译的阈值(特别是对 server 编译器来说)
三、编译过程
如果我们想要看到编译器是如何工作的,可以使用 -XX:+PrintCompilation 命令来开启,默认是 false
如果程序启动时没有开启这个标志,可以用 jstat 了解编译器内部的部分工作情况。例如: jstat -compiler 25 或 jstat -printcompilation 25 1000
-compiler -printcompilation 25 1000
小结:
- 观察代码如何被编译的最好方法是开启 PrintCompilation
- PrintCompilation 开启后所输出的信息可用来确认编译是否和预期一样
编译器高级调优
一、编译线程
当方法(或循环)适合编译时,就会进入到 编译队列 。然后队列中的任务则由 一个或多个 后台线程处理,这意味着编译过程是 异步 的。这样的好处便是: 即便代码正在编译的时候,程序也能持续执行 。
如果是用 标准编译 所编译的方法,那下次调用该方法时就会执行编译后的方法;如果是用 OSR 编译的循环,那下次循环迭代时就会执行编译后的代码。
编译队列并不严格遵守 先进先出 的原则:调用计数次数多的方法有更高的优先级。所以即便在程序开始执行并有大量代码需要编译时,这样的优先顺序仍然有助于确保最重要的代码优先编译。
使用 client 编译器时,JVM会开启一个编译线程;使用 server 编译器时,则会开启两个线程。而分层编译器则是一个略复杂的等式而定,如下:
| CPU数量 | C1的线程数 | C2的线程数 |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 1 |
| 4 | 1 | 1 |
| 8 | 1 | 2 |
| 16 | 2 | 6 |
| 32 | 3 | 7 |
| 64 | 4 | 8 |
| 128 | 4 | 10 |
小结:
- 放置在编译队列中的方法的编译会被异步执行。
- 队列并不是严格按照先后顺序的;队列中的热点方法会在其他方法之前编译,这是编译输出日志中的 ID 为乱序的另一个原因。
二、内联 可好?
有了解过 final 的小伙伴应该都知道被 final 修饰的方法,编译时JVM会尝试找与其内联的方法。这是因为编译器所做的最重要的优化是 方法内联 。内联默认是 开启 的。可以通过 -XX:-Inline 关闭。
如果你从源代码编译 JVM,那可以用 -XX:+PrintInling 生成带调试信息的版本。方法是否 内联 取决于它有多热以及它的大小。JVM 依据内部计算来判定方法是否热点(譬如:调用很频繁);是否是热点并不直接与任何调优参数相关。
小结:
- 内联是编译器所能做的最有利的优化,特别是对属性封装良好的面向对象的代码来说。
- 几乎用不着调节内联参数,且提倡这样做的建议往往忽略了常规内联和频繁调用内联之间的关系。当考察内联效应时,确保考虑这两种情况。
三、逃逸分析
我们可以通过 -XX:+DoEscapeAnalysis 来开启逃逸分析,默认是 true 。逃逸分析可以决定哪些优化是可能的,并决定编译后的代码中哪些是必要的改变。
逃逸分析默认开启,极少数情况下,它会出错。在此类情况下关闭它会变得更快或更稳定。如果你发现了这种情况,最好的应对行为就是简化相关代码:代码越简单越好。
小结:
- 逃逸分析是编译器能做得最复杂的优化,此类优化常常会导致微基准测试失败。
- 逃逸分析常常会给不正确的同步代码引入 bug 。
何为逆优化
逆优化意味着编译器不得不 “撤销” 之前的某些编译;结果是应用的性能降低——至少是直到编译器重新编译相应代码为止。有两种逆优化的情形:
- 代码被丢弃(made not entrant)
- 产生僵尸代码(made zombie)
一、代码被丢弃了?
有两种原因导致代码被丢弃
- 与类与接口的工作方式有关
- 与分层编译的细节有关
当 server 编译器编译好代码之后,JVM 必须替换 client 编译器所编译的代码。它会将老弟阿玛标记为废弃。也用同样的方法替换新编译(和更有效)的代码。
二、“僵尸” 代码出现
何为 僵尸代码 :当编译后的代码,因为后续没有用到而被GC回收,全部回收之后,编译器就会注意到,这些代码现在适合标记为 僵尸代码 了。
从性能角度上看,这是好事。上面我们提到过 代码缓存 ,编译后的代码会保存在大小固定的代码缓存中。如果发现僵尸代码,这意味着这些有问题的代码可以从代码缓存中移除,腾出空间给其他将被编译的代码(或者限制 JVM 之后需要分配的内存量)。
可能产生不足的是,如果代码被僵尸化以后再次加载并且频繁使用,JVM 就需要重新编译和重新优化代码,那么这将会影响到性能。
小结:
- 逆优化使得编译器可以回到之前版本的编译代码
- 先前的优化不再有效时(例如,所涉及到的对象类型发生了更改),才会发生代码逆优化。
- 代码逆优化时,会对性能产生一些小而短暂的影响,不过新编译的代码会尽快地再次热身。
- 分层编译时,如果代码之前由 client 编译器编译而现在 server 编译器优化,就会发生逆优化。
分层编译级别
程序使用分层编译时,编译日志会输出所编译的分层级别。
其中 client 编译器有 3 种级别, server 编译器有 2 种编译级别,因此,编译级别有以下几种:
- 0:解释代码
- 1:简单 C1 编译代码
- 2:受限的 C1 编译代码
- 3:完全 C1 编译代码
- 4:C2 编译代码
多数方法第一次编译的级别是3 ,即完全 C1 编译(不过所有方法都从级别0开始)。如果方法运行得足够频繁,它就会编译成级别4(级别3的代码就会被丢弃)。
如果 server 编译器队列满了,就会从 server 队列中取出方法, 以级别2进行编译,在这个级别中,C1编译器使用方法调用计数器和回边计数器。这会让方法编译得更快,而方法也将在 C1 编译器收集分析信息之后被编译为级别3,最终当 server 编译器队列不太忙的时候被编译为级别4。
小结:
- 分层编译可以在两种编译器和 5 种级别之间进行。
- 不建议人为更改级别。
小菜与你小结
- 不用担心小方法,特别是 getter 和 setter ,因为它们很容易内联。
- 需要编译的代码在编译队列中,队列中的代码越多,程序达到最佳性能的时间越久。
- 虽然代码缓存的大小可以(也应该)调整,但它仍然是有限的资源。
- 代码越简单,优化越多,分析反馈和逃逸分析可以使代码更快,但复杂的循环结构和大方法限制了它的有效性。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

