Java 生态圈中的嵌入式数据库,哪家强?
嵌入式数据库一个很陌生的词汇,以前只是听说,但是没有真正使用过,今天小编和大家一起来揭开它的面纱。

一、介绍
初次接触嵌入式数据库(Embedded Database)可能有点模糊,什么是嵌入式数据库?为什么要使用嵌入式数据库?怎么使用嵌入式数据库?如何选择?本文将带大家一起揭晓答案。
从软件角度来说,数据库分类为两种:
- 第一种:数据库服务器(Database Server)
- 第二种:嵌入式数据库(Embedded Database)
像 Oracle、PostgreSQL、MySQL 和 SQL Server 等这些大家熟知的数据库,我们一般称它为数据库服务器,当然也不排除某些数据库也提供嵌入式版本,例如 MySQL Embedded 就是一个嵌入式的数据库。
而像 SQLite、Berkeley DB、Derby、H2、HSQL DB 等数据库,一本内嵌在应用程序中,与应用程序一起运行,我们称它为嵌入式数据库。
嵌入式数据库跟数据库服务器最大的区别在于它们运行的地址空间不同。通常,数据库服务器独立地运行一个守护进程(daemon),而嵌入式数据库与应用程序运行在同一个进程。
在实际开发中,平时接触最多的应该是数据库服务器,对嵌入式数据库使用的比较少。
但是为何会出现嵌入式数据库呢?
在小型的应用程序中,例如小型掌上游戏机,不适合部署高达几百兆的数据库服务器,同时也没有联网的必要,一种轻量级的数据库需求由此诞生!
与常见的数据库相比,嵌入式数据库具有体积小、功能齐备、可移植性、健壮性等特点,例如我们所熟知的 SVN 版本控制软件就使用到了 SQLite 作为内置数据库,SQLite 的安装包只有不到 350 KB,在微型机中也有着广泛的应用,例如安卓、IOS 等移动设备操作系统都内置了 SQLite 数据库!
鉴于嵌入式数据库的种类比较多,有商业收费的、也有开源免费的!本文主要介绍开源免费版的,例如 Derby、SQLite、H2 等,下面我们就一起来实践一下各个数据库的配置和用法。
二、Derby
Derby 可以说是 100% 由 Java 编写的一款数据库,而且是开源免费的,非常小巧,核心部分derby.jar只有 2M!
很多人可能觉得 Derby 不是很热门,但 Derby 已经开发了将近二十年!
1996 年,一个叫做 Cloudscape, Inc 的新公司成立了,公司的目标是构建一个用 Java 语言编写的数据库服务器。
公司的第一个发行版在一年之后推出,后来产品的名称变成 Cloudscape。
1999 年,Cloudscape, Inc. 被大型数据库厂商 Informix Software, Inc. 收购。
Informix Software 在 2001 年又被 IBM 收购,然后 IBM Cloudscape™ 数据库系统在许多 IBM 的产品中被用作内嵌的数据库引擎。
2004 年 4 月,IBM 把 Cloudscape 数据库软件赠送给 Apache 软件基金会,从此 Apache Derby 项目诞生了。
接着 SUN 也为 Derby 捐献了一个团队。在JavaSE6.0中,SUN 将其命名为JavaDB。
2.1、项目引入
因为 Derby 是用 java 编写的,所以集成的时候比较容易,直接通过maven在pom.xml中依赖库文件,即可进行开发!
<!--derby数据库--> <dependency> <groupId>org.apache.derby</groupId> <artifactId>derby</artifactId> <version>10.14.1.0</version> <scope>runtime</scope> </dependency>
2.2、环境配置
和所有的数据库连接一样,基本都是配置驱动类、连接地址、账号、密码等信息。
String DRIVER_CLASS = "org.apache.derby.jdbc.EmbeddedDriver"; String JDBC_URL = "jdbc:derby:derbyDB;create=true"; String USER = "root"; String PASSWORD = "root";
说明:
- org.apache.derby.jdbc.EmbeddedDriver表示使用derby嵌入式数据库模式。
- JDBC_URL中的derbyDB表示创建一个名为derbyDB的临时数据库,如果没有会自动创建。
- USER、PASSWORD主要用于客户端登录使用。
2.3、单元测试应用
下面,我们使用JDBC编写一个测试类,来测试一下derby是否可以正常使用。
public class DerbyTest {
/**
* 以嵌入式(本地)连接方式连接数据库
*/
private static final String JDBC_URL = "jdbc:derby:derbyDB;create=true";
private static final String DRIVER_CLASS = "org.apache.derby.jdbc.EmbeddedDriver";
private static final String USER = "root";
private static final String PASSWORD = "root";
public static void main(String[] args) throws Exception {
//与数据库建立连接
Class.forName(DRIVER_CLASS);
Connection conn = DriverManager.getConnection(JDBC_URL, USER, PASSWORD);
Statement statement = conn.createStatement();
//删除表
statement.execute("DROP TABLE USER_INF");
//创建表
statement.execute("CREATE TABLE USER_INF(id VARCHAR(50) PRIMARY KEY, name VARCHAR(50) NOT NULL, sex VARCHAR(50) NOT NULL)");
//插入数据
statement.executeUpdate("INSERT INTO USER_INF VALUES('1', '程咬金', '男') ");
statement.executeUpdate("INSERT INTO USER_INF VALUES('2', '孙尚香', '女') ");
statement.executeUpdate("INSERT INTO USER_INF VALUES('3', '猴子', '男') ");
//查询数据
ResultSet resultSet = statement.executeQuery("select * from USER_INF");
while (resultSet.next()) {
System.out.println(resultSet.getInt("id") + ", " + resultSet.getString("name") + ", " + resultSet.getString("sex"));
}
//关闭连接
statement.close();
conn.close();
}
}
输出结果:
1, 程咬金, 男 2, 孙尚香, 女 3, 猴子, 男
当程序运行完之后,会在当前项目根目录生成一个derbyDB文件夹,里面会存放一些持久化的数据,当下次再连接derbyDB数据库名称时,可以查询出之前插入的历史数据,这个特性可以防止数据丢失!
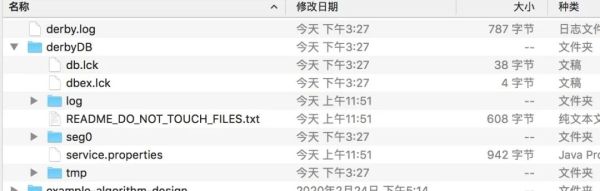
值得注意的是:derby 对很多 mysql 的关键字并不支持,同时 derby 不支持插入空值。
在之后的版本中,derby 还可以作为一个数据库服务器,通过jar启动单独部署在一台服务器上,在连接地址上加上 IP 和端口号,例如jdbc://derby://localhost:1527/derbyDB。
如果想使用可视化客户端工具来访问和管理derby,可以使用SQuirreL SQL Client客户端,下载地址http://www.squirrelsql.org/#installation。
在目前绝大多数的关于嵌入式数据库应用中,derby 的出场次数还是较少。
三、SQLite
SQLite 是 D.RichardHipp 用一个小型的C库开发的一种强有力的嵌入式关系数据库,虽然功能较 Berkeley DB(商业数据库)稍显逊色,但它简单易学、速度较快,同时提供了丰富的数据库接口,提供了对 SQL92 的大多数支持:支持多表和索引、事务、视图、触发和一系列的用户接口及驱动。
SQLite 不仅支持 Windows/Linux/Unix 等等主流的操作系统,同时能够跟很多程序语言相结合,比如 Tcl、C#、PHP、Java等,还有ODBC接口,比起 Mysql、PostgreSQL 这两款开源的世界著名数据库管理系统来讲,它的处理速度比他们都快,全部源码大致3万行C代码,文件大约 350KB,支持数据库大小至 2TB!
几乎常年占居嵌入式数据库的第一位!
3.1、SQLite安装
3.1.1、windows安装
1.访问 SQLite 下载页面https://www.sqlite.org/download.html。
2.下载sqlite-tools-win32-*.zip和sqlite-dll-win32-*.zip压缩文件。
3.创建文件夹C:/sqlite,并在此文件夹下解压上面两个压缩文件,将得到 sqlite3.def、sqlite3.dll和sqlite3.exe文件。
4.添加C:/sqlite到PATH环境变量。
最后在命令提示符下,输入sqlite3命令,显示如下结果表示安装成功!
C:/>sqlite3 SQLite version 3.7.15.2 2013-01-09 11:53:05 Enter ".help" for instructions Enter SQL statements terminated with a ";"
3.1.2、linux安装
目前,几乎所有版本的 Linux 操作系统都附带 SQLite。所以,只需要在命令行输入输入sqlite3,即可检查出机器上是否已经安装了 SQLite!
$ sqlite3 SQLite version 3.7.15.2 2013-01-09 11:53:05 Enter ".help" for instructions Enter SQL statements terminated with a ";"
如果没有看到上面的结果,安装也很简单!
1.访问 SQLite 下载页面https://www.sqlite.org/download.html。
2.下载sqlite-autoconf-*.tar.gz并上传到 linux 服务器。
3.执行安装操作
例如,安装步骤示例:
$ tar xvzf sqlite-autoconf-3071502.tar.gz $ cd sqlite-autoconf-3071502 $ ./configure --prefix=/usr/local $ make $ make install
3.1.3、mac安装
mac安装操作与linux类似。
3.2、项目引入
sqlite 也可以直接通过maven在pom.xml中依赖库文件,即可进行开发!
<!--sqlite--> <dependency> <groupId>org.xerial</groupId> <artifactId>sqlite-jdbc</artifactId> <version>3.7.2</version> </dependency>
3.3、环境配置
String DRIVER_CLASS = "org.sqlite.JDBC"; String JDBC_URL = "jdbc:sqlite:sqliteDB.db"; String USER = "root"; String PASSWORD = "root";
说明:
- org.sqlite.JDBC表示使用sqlite嵌入式数据库模式。
- JDBC_URL中的sqliteDB表示创建一个名为sqliteDB的临时数据库,如果没有会自动创建。
- USER、PASSWORD主要用于客户端登录使用。
3.4、单元测试应用
下面,来测试一下sqlite是否可以正常使用。
public class SQLiteTest {
/**
* 以嵌入式(本地)连接方式连接数据库
*/
private static final String JDBC_URL = "jdbc:sqlite:sqliteDB.db";
private static final String DRIVER_CLASS = "org.sqlite.JDBC";
private static final String USER = "root";
private static final String PASSWORD = "root";
public static void main(String[] args) throws Exception {
//与数据库建立连接
Class.forName(DRIVER_CLASS);
Connection conn = DriverManager.getConnection(JDBC_URL, USER, PASSWORD);
Statement statement = conn.createStatement();
//删除表
statement.execute("DROP TABLE IF EXISTS USER_INF");
//创建表
statement.execute("CREATE TABLE USER_INF(id VARCHAR(50) PRIMARY KEY, name VARCHAR(50) NOT NULL, sex VARCHAR(50) NOT NULL)");
//插入数据
statement.executeUpdate("INSERT INTO USER_INF VALUES('1', '程咬金', '男') ");
statement.executeUpdate("INSERT INTO USER_INF VALUES('2', '孙尚香', '女') ");
statement.executeUpdate("INSERT INTO USER_INF VALUES('3', '猴子', '男') ");
//查询数据
ResultSet resultSet = statement.executeQuery("select * from USER_INF");
while (resultSet.next()) {
System.out.println(resultSet.getInt("id") + ", " + resultSet.getString("name") + ", " + resultSet.getString("sex"));
}
//关闭连接
statement.close();
conn.close();
}
}
输出结果:
1, 程咬金, 男 2, 孙尚香, 女 3, 猴子, 男
当程序运行完之后,也会在当前项目的根目录下生成上文自定义的一个名为sqliteDB的文件。
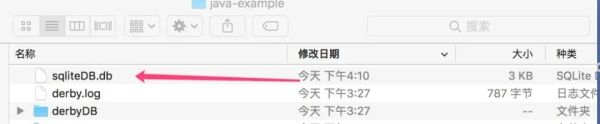
每次操作名为sqliteDB的数据库时候,数据会持久化到sqliteDB文件中,从而防止数据丢失。
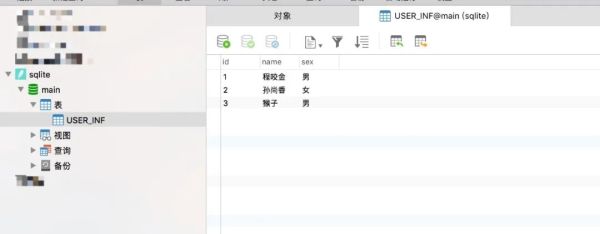
如果想使用可视化客户端工具来访问和管理sqliteDB,可以使用navicat来连接,选择生成的sqliteDB文件,输入相应的账号、密码,便可进行管理维护!

四、H2
h2 是一款纯java编写的另一款嵌入式数据库,它本身只是一个类库,即只有一个 jar 文件,可以直接嵌入到应用项目中,同时还提供了非常友好的基于 web 的数据库管理界面。
网上有很多开发者拿它与 derby 做对比,称它与 mysql 数据库兼容性强,口碑较好。
具体是否真的如此,在后文我们会进行相应的性能测试,下面一起来看看在开发中如何使用。
4.1、项目引入
既然 h2 是纯java编写,可以直接通过maven在pom.xml中依赖库文件,即可进行开发!
<!--h2数据库--> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <version>1.4.200</version> <scope>runtime</scope> </dependency>
4.2、环境配置
String DRIVER_CLASS = "org.h2.Driver"; String JDBC_URL = "jdbc:h2:mem:h2DB"; String USER = "root"; String PASSWORD = "root";
说明:
- org.h2.Driver表示使用h2嵌入式数据库模式。
- JDBC_URL中的h2DB表示创建一个名为h2DB的临时数据库。
- USER、PASSWORD主要用于客户端登录使用。
4.3、单元测试应用
下面,来测试一下h2是否可以正常使用。
public class H2Test {
/**
* 以嵌入式(本地)连接方式连接H2数据库
*/
private static final String JDBC_URL = "jdbc:h2:mem:h2DB";
private static final String DRIVER_CLASS = "org.h2.Driver";
private static final String USER = "root";
private static final String PASSWORD = "root";
public static void main(String[] args) throws Exception {
//与数据库建立连接
Class.forName(DRIVER_CLASS);
Connection conn = DriverManager.getConnection(JDBC_URL, USER, PASSWORD);
Statement statement = conn.createStatement();
//删除表
statement.execute("DROP TABLE IF EXISTS USER_INF");
//创建表
statement.execute("CREATE TABLE USER_INF(id VARCHAR(50) PRIMARY KEY, name VARCHAR(50) NOT NULL, sex VARCHAR(50) NOT NULL)");
//插入数据
statement.executeUpdate("INSERT INTO USER_INF VALUES('1', '程咬金', '男') ");
statement.executeUpdate("INSERT INTO USER_INF VALUES('2', '孙尚香', '女') ");
statement.executeUpdate("INSERT INTO USER_INF VALUES('3', '猴子', '男') ");
//查询数据
ResultSet resultSet = statement.executeQuery("select * from USER_INF");
while (resultSet.next()) {
System.out.println(resultSet.getInt("id") + ", " + resultSet.getString("name") + ", " + resultSet.getString("sex"));
}
//关闭连接
statement.close();
conn.close();
}
}
输出结果:
1, 程咬金, 男 2, 孙尚香, 女 3, 猴子, 男
h2 作为嵌入式数据库应用可以选择两种类型的url,第一种是内存模式运行,这种模式将数据临时放到内存中,程序结束后数据表和数据立即被销毁,就不存在了;第二种是使用本地文件方式,将数据持久化到文件中,当再次连接数据库时,可以获取历史数据。
#第一种,内存模式运行 jdbc:h2:mem:testDB #第二种,使用本地文件方式 jdbc:h2:file:./target/testDB
h2 还可以作为数据库服务器使用,单独部署在服务器上,应用程序通过远程连接进行操作,连接方式如下:
#连接语法 jdbc:h2:tcp://<server>[:<port>]/[<path>]<databaseName> #范例: jdbc:h2:tcp://localhost:8080/~/test
如果想使用可视化客户端工具来访问和管理h2,可以通过它自带的 web 页面进行管理。
下面我们以springboot项目为例,通过配置使用h2自带的管理页面来维护。
新建一个WebConfig类,配置h2的 web 控制台,如下:
@Configuration
public class WebConfig {
/**
* 添加h2控制台的映射地址
* @return
*/
@Bean
ServletRegistrationBean h2servletRegistration(){
ServletRegistrationBean registrationBean = new ServletRegistrationBean(new WebServlet());
registrationBean.addUrlMappings("/h2-console/*");
return registrationBean;
}
}
启动springboot项目,打开浏览器,输入http://127.0.0.1:8080/h2-console访问管理页面!
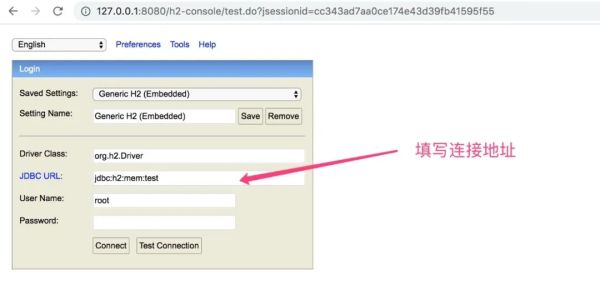
填写连接地址、账号、密码之后,进行连接!
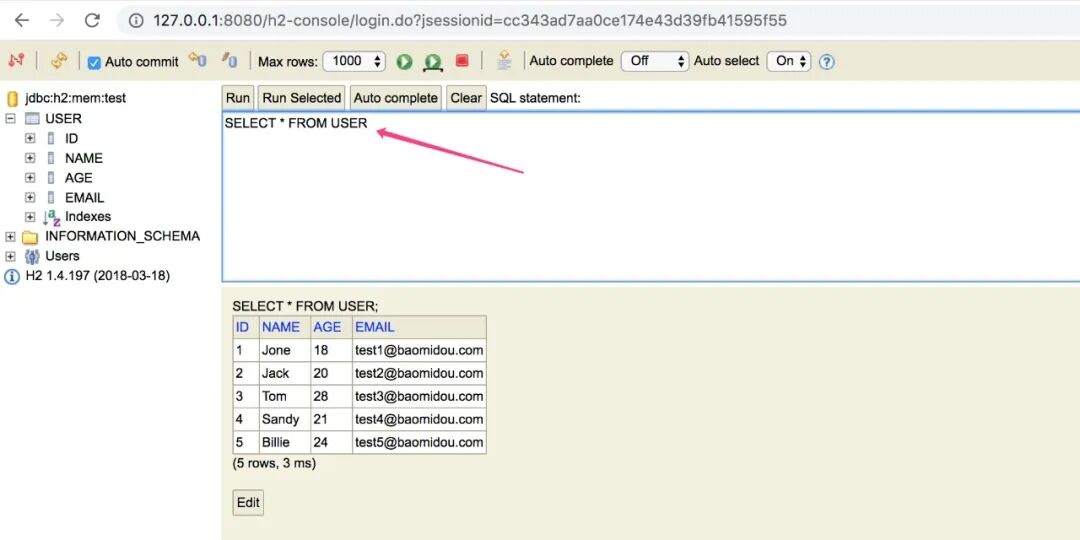
可以在工作台,编写 sql 语句进行查询,同时对查询结果还可以进行编辑操作。
五、性能测试
上文中我们介绍了三者数据库的使用,下面,我们以循环插入1000、10000、100000次操作,分别来测试三个数据库的性能,看看他们的表现如何?
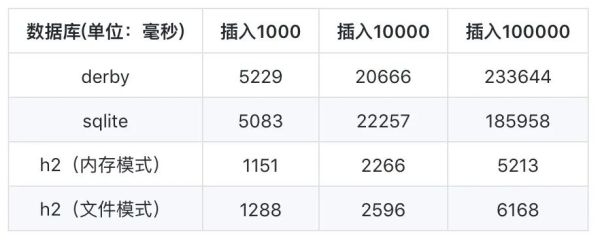
从结果上看:
- derby 与 sqlite 性能方面相差不大,但是随着插入数量越多,derby 比 sqlite 稍逊一些。
- 三者相比,h2 性能最好,无论是将数据写入内存,还是写入到数据库,性能都是最好的。
六、总结
- derby 作为嵌入式数据库,在性能和易用性都不错,数据库是以一个目录存储的,但只能用于Java程序中。
- sqlite 因为支持多种语言,也提供了对 SQL92 的大多数支持,执行效率也不错,作为嵌入式数据库应用最广,但如果想查询数据只能本地连接不能远程连接。
- h2 作为嵌入式数据库的新秀,主要优势:超轻量级,可以支持内存模式,高效高速,能支持基本的全文搜索,同时与 mysql 数据库兼容性最强,一般使用场景最多的就是在开发环境上进行回归测试使用。
正文到此结束
- 本文标签: linux apache tab servlet 数据库 基金 TCP value Connection SQLite springboot zip unix mina Oracle 配置 需求 key SQL Server 免费 id 部署 update 源码 pom tar 安装 代码 XML 开源 下载 十年 单元测试 java 测试 maven map 管理 Select 总结 Word IO ResultSet spring 服务器 db https sql 移动设备 HTML final 删除 ORM Statement rmi root 端口 struct cat 数据 App 开发 http bean JDBC 目录 PHP windows ip 产品 开发者 CTO 操作系统 src ODBC mysql web IBM SVN 进程 UI 空间 软件 client IOS 索引
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

