Netty存在的问题 & 解决的问题

1. 维护Bytebuf带来的大量拷贝问题.
如果细心的童鞋会发现 io.netty.handler.codec.ByteToMessageDecoder 他提供了一个缓冲区. 那么缓冲区就要代表有拷贝.
Netty提供了两种方式 :
public static final Cumulator MERGE_CUMULATOR = new Cumulator() {
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
try {
final ByteBuf buffer;
// 1.如果原来的写空间不足了. c.w+in.r>c.capacity
if (cumulation.writerIndex() > cumulation.maxCapacity() - in.readableBytes()
|| cumulation.refCnt() > 1 || cumulation.isReadOnly()) {
// 新建一个. // 第一步新建一个新的对象. 第二步拷贝原来的, 第三步释放原来的.
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
} else {
//2.否则空间就满足.不需要扩展
buffer = cumulation;
}
// 3.复制新写入的数据到缓冲区
buffer.writeBytes(in);
// 返回
return buffer;
} finally {
// 释放对象
in.release();
}
}
};
复制代码
我们发现第一种实现给我们带来大量的拷贝. 但是我们可以提供一种 CompositeByteBuf , 也就是组合的Bytebuf. 实际上没有拷贝. 只是将他俩维护起来.
那么就减少了拷贝.
public static final Cumulator COMPOSITE_CUMULATOR = new Cumulator() {
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
ByteBuf buffer;
try {
// 如果引用大于1, 则出现问题了.会帮我们新建一个.
if (cumulation.refCnt() > 1) {
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
// 写入.
buffer.writeBytes(in);
} else {
CompositeByteBuf composite;
if (cumulation instanceof CompositeByteBuf) {
composite = (CompositeByteBuf) cumulation;
} else {
composite = alloc.compositeBuffer(Integer.MAX_VALUE);
composite.addComponent(true, cumulation);
}
// 直接添加进去
composite.addComponent(true, in);
// 取消引用,此时虽然为空了. 但是其实没有.只是放入了原来的composite.
in = null;
buffer = composite;
}
return buffer;
} finally {
// 为了防止第一种情况出现.最后统一处理.
if (in != null) {
in.release();
}
}
}
};
复制代码
但是这个存在一个问题 . 很严重, 就是内存泄漏. 为啥呢.
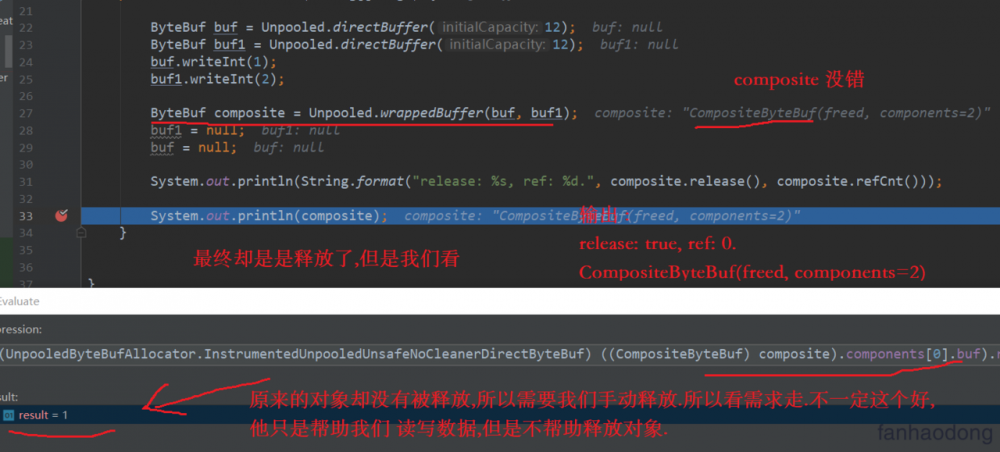
上面 这段代码很好地阐述了, 为什么不推荐使用这个. 因为存在大量的问题. 就是无法释放对象, 也可以释放对象. 但是需要用户手动操作. 这个就很无语. 所以基本不推荐使用 . 但是其实也可以的,需要你人工判断了. 哈哈哈 ,其实怎么说不统一很难维护的. 也就是这个 .
所以这个问题的根本原因目前无法处理掉的.
Netty如何解决 NIO空转问题.
目前我们只考虑 NIOEventLoop
首先看 io.netty.channel.nio.NioEventLoop 这个类.的 run方法.
@Override
protected void run() {
for (;;) {
try {
try {
switch (selectStrategy.calculateStrategy(selectNowSupplier, hasTasks())) {
case SelectStrategy.CONTINUE:
continue;
case SelectStrategy.BUSY_WAIT:
// 不支持直接. 切换到下一步.
// fall-through to SELECT since the busy-wait is not supported with NIO
// 主要代码在这里.
case SelectStrategy.SELECT:
// 就是这个select方法.
select(wakenUp.getAndSet(false));
if (wakenUp.get()) {
selector.wakeup();
}
default:
}
} catch (IOException e) {
rebuildSelector0();
handleLoopException(e);
continue;
}
// 事件处理等等操作.
}
}
复制代码
我们再看看 select() 做了啥 这个方法
private void select(boolean oldWakenUp) throws IOException {
Selector selector = this.selector;
try {
int selectCnt = 0;
long currentTimeNanos = System.nanoTime();
// 这里会计算你轮询的时间, 最长时间, 比如我只让你轮询10次, 也就是+10S.具体实现可以看看.
long selectDeadLineNanos = currentTimeNanos + delayNanos(currentTimeNanos);
for (;;) {
long timeoutMillis = (selectDeadLineNanos - currentTimeNanos + 500000L) / 1000000L;
// 如果轮询时间超了最长轮询时间. 则直接返回了.不能一直轮询.
if (timeoutMillis <= 0) {
if (selectCnt == 0) {
selector.selectNow();
selectCnt = 1;
}
break;
}
if (hasTasks() && wakenUp.compareAndSet(false, true)) {
selector.selectNow();
selectCnt = 1;
break;
}
// 主要是这里改变了. 这里改成非阻塞的了, 默认不加参数属于无脑阻塞.可能出现bug.所以改成超时阻塞. 这里是1000ms
int selectedKeys = selector.select(timeoutMillis);
selectCnt ++;
// 如果selectorkey 不为空. 就break
if (selectedKeys != 0 || oldWakenUp || wakenUp.get() || hasTasks() || hasScheduledTasks()) {
break;
}
if (Thread.interrupted()) {
// ...
selectCnt = 1;
break;
}
long time = System.nanoTime();
// 如果确实等待超时了.就重置count, 否则小于的话就是bug,继续轮询,如果继续bug,当bug到512次就重新创建一个selector. 将原来的注册新建的中来.
if (time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos) {
// 重置.继续轮询
selectCnt = 1;
} else if (SELECTOR_AUTO_REBUILD_THRESHOLD > 0 &&
selectCnt >= SELECTOR_AUTO_REBUILD_THRESHOLD) {
// 这里就是超过阈值的流程. 就rebuild一下.(也就是重新创建一个,代码太长自己看,在openSelector方法中)
selector = selectRebuildSelector(selectCnt);
selectCnt = 1;
break;
}
//
currentTimeNanos = time;
}
// 循环结束.
if (selectCnt > MIN_PREMATURE_SELECTOR_RETURNS) {
// 日志
}
} catch (CancelledKeyException e) {
// 日志
}
}
复制代码
Netty 如何解决空转呢.
第一步: 确定一个最长的等待时间. 默认是 SCHEDULE_PURGE_INTERVAL=1s , 也就是只能轮询1S. 卡死的.
第二步 : 我们执行 int selectedKeys = selector.select(timeoutMillis); 这个会在超时时间范围内返回, 具体分为三种情况 :
1).如果有数据那么我们直接返回得了.
2).如果没有数据,等待超时了, 则继续轮询,这里想想也不会的, 默认的 timeoutMillis 是 (selectDeadLineNanos - currentTimeNanos + 500000L) / 1000000L 我们看看为何是这个. 也就是将1S换成多少毫秒罢了 . 也就是默认就是1000ms. 所以如果真的等待超时了, 这里也就跳出去了 .
- 如果发生了BUG , 空转BUG, 那么此时
selectCnt++不断执行. 会触发一个阈值. 这个阈值可以通过SystemPropertyUtil.getInt("io.netty.selectorAutoRebuildThreshold", 512);这个参数配置, 默认是512阈值, 就来解决BUG. 此时他会重新创建一个selector 对象. 这就解决了,
这也就是Netty为啥不使用我们传统的编程方式了.
while (true) {
// 这里会出现BUG.也就是空转问题了.
selector.select();
Iterator<SelectionKey> keyIterator = selector.selectedKeys().iterator();
while (keyIterator.hasNext()) {
// 注册事件
// 最后移除掉
keyIterator.remove();
}
}
复制代码
以上代码会出现Java的NIO空转问题 , 所以主流的实现都是Netty那套. 其实说到底还是Java的底层API问题, 再其次Java将其责任推给了 不同平台的底层实现上. 这层层委托, 不断的迭代, 完蛋了. 哈哈哈还是我们自己处理吧.
可以看看 这篇文章 不错 : www.cnblogs.com/JAYIT/p/824…
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

