内存屏障及其在-JVM 内的应用(下)
Java 为了能在不同架构的 CPU 上运行,提炼出一套自己的内存模型,定义出来 Java 程序该怎么样和这个抽象的内存模型进行交互,定义出来程序的运行过程,什么样的指令可以重排,什么样的不行,指令之间可见性如何等。相当于是规范出来了 Java 程序运行的基本规范。这个模型定义会很不容易,它要有足够弹性,以适应各种不同的硬件架构,让这些硬件在支持 JVM 时候都能满足运行规范;它又要足够严谨,让应用层代码编写者能依靠这套规范,知道程序怎么写才能在各种系统上运行都不会有歧义,不会有并发问题。
在著名的 《深入理解 Java 虚拟机》一书的图 12-1 指出了在 JMM 内,线程、主内存、工作内存的关系。图片来自该书的 Kindle 版:
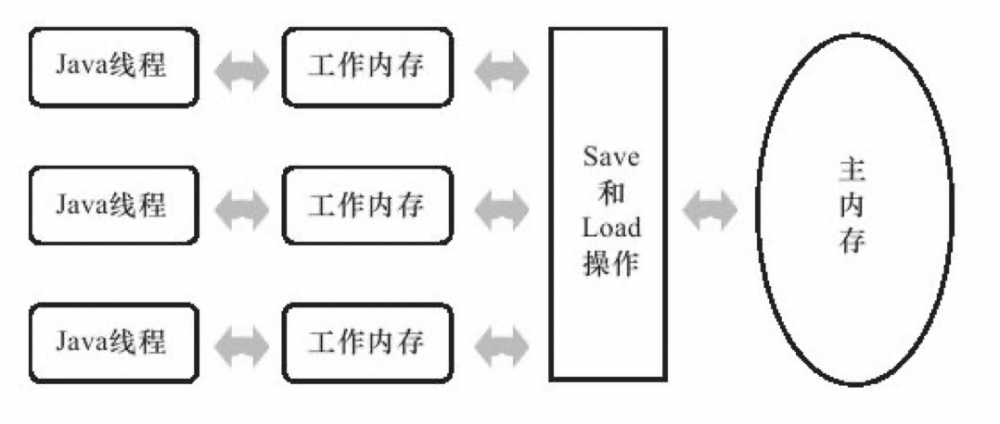
从内存模型一词就能看出来,这是对真实世界的模拟。图中 Java 线程对应的就是 CPU,工作内存对应的就是 CPU Cache,Java 提炼出来的一套 Save、Load 指令对应的就是缓存一致性协议,就是 MESI 等协议,最后主内存对应的就是 Memory。真实世界的硬件需要根据自身情况去向这套模型里套。
JMM 完善于 JSR-133 ,现在一般会把详细说明放在 Java Language 的 Spec 上,比如 Java11 的话在: Chapter 17. Threads and Locks 。在这些说明之外,还有个特别出名的 Cookbook,叫 The JSR-133 Cookbook for Compiler Writers 。
JVM 上的 Memory Barrier
JVM 按前后分别有读、写两种操作以全排列方式一共提供了四种 Barrier,名称就是左右两边操作的名字拼接。比如 LoadLoad Barrier 就是放在两次 Load 操作中间的 Barrier, LoadStore 就是放在 Load 和 Store 中间的 Barrier。Barrier 类型及其含义如下:
-
LoadLoad,操作序列 Load1, LoadLoad, Load2,用于保证访问 Load2 的读取操作一定不能重排到 Load1 之前。类似于前面说的Read Barrier,需要先处理 Invalidate Queue 后再读 Load2; -
StoreStore,操作序列 Store1, StoreStore, Store2,用于保证 Store1 及其之后写出的数据一定先于 Store2 写出,即别的 CPU 一定先看到 Store1 的数据,再看到 Store2 的数据。可能会有一次 Store Buffer 的刷写,也可能通过所有写操作都放入 Store Buffer 排序来保证; -
LoadStore,操作序列 Load1, LoadStore, Store2,用于保证 Store2 及其之后写出的数据被其它 CPU 看到之前,Load1 读取的数据一定先读入缓存。甚至可能 Store2 的操作依赖于 Load1 的当前值。这个 Barrier 的使用场景可能和上一节讲的 Cache 架构模型很难对应,毕竟那是一个极简结构,并且只是一种具体的 Cache 架构,而 JVM 的 Barrier 要足够抽象去应付各种不同的 Cache 架构。如果跳出上一节的 Cache 架构来说,我理解用到这个 Barrier 的场景可能是说某种 CPU 在写 Store2 的时候,认为刷写 Store2 到内存,将其它 CPU 上 Store2 所在 Cache Line 设置为无效的速度要快于从内存读取 Load1,所以做了这种重排。 -
StoreLoad,操作序列 Store1, StoreLoad, Load2,用于保证 Store1 写出的数据被其它 CPU 看到后才能读取 Load2 的数据到缓存。如果 Store1 和 Load2 操作的是同一个地址,StoreLoad Barrier 需要保证 Load2 不能读 Store Buffer 内的数据,得是从内存上拉取到的某个别的 CPU 修改过的值。StoreLoad一般会认为是最重的 Barrier 也是能实现其它所有 Barrier 功能的 Barrier。
对上面四种 Barrier 解释最好的是来自这里: jdk/MemoryBarriers.java at 6bab0f539fba8fb441697846347597b4a0ade428 · openjdk/jdk · GitHub ,感觉比 JSR-133 Cookbook 里的还要细一点。
为什么这一堆 Barrier 里 StoreLoad 最重?
所谓的重实际就是跟内存交互次数,交互越多延迟越大,也就是越重。 StoreStore , LoadLoad 两个都不提了,因为它俩要么只限制读,要么只限制写,也即只有一次内存交互。只有 LoadStore 和 StoreLoad 看上去有可能对读写都有限制。但 LoadStore 里实际限制的更多的是读,即 Load 数据进来,它并不对最后的 Store 存出去数据的可见性有要求,只是说 Store 不能重排到 Load 之前。而反观 StoreLoad ,它是说不能让 Load 重排到 Store 之前,这么一来得要求在 Load 操作前刷写 Store Buffer 到内存。不去刷 Store Buffer 的话,就可能导致先执行了读取操作,之后再刷 Store Buffer 导致写操作实际被重排到了读之后。而数据一旦刷写出去,别的 CPU 就能看到,看到之后可能就会修改下一步 Load 操作的内存导致 Load 操作的内存所在 Cache Line 无效。如果允许 Load 操作从一个可能被 Invalidate 的 Cache Line 里读数据,则表示 Load 从实际意义上来说被重排到了 Store 之前,因为这个数据可能是 Store 前就在 Cache 中的,相当于读操作提前了。为了避免这种事发生,Store 完成后一定要去处理 Invalidate Queue,去判断自己 Load 操作的内存所在 Cache Line 是否被设置为无效。这么一来为了满足 StoreLoad 的要求,一方面要刷 Store Buffer,一方面要处理 Invalidate Queue,则最差情况下会有两次内存操作,读写分别一次,所以它最重。
StoreLoad 为什么能实现其它 Barrier 的功能?
这个也是从前一个问题结果能看出来的。 StoreLoad 因为对读写操作均有要求,所以它能实现其它 Barrier 的功能。其它 Barrier 都是只对读写之中的一个方面有要求。
不过这四个 Barrier 只是 Java 为了跨平台而设计出来的,实际上根据 CPU 的不同,对应 CPU 平台上的 JVM 可能可以优化掉一些 Barrier。比如很多 CPU 在读写同一个变量的时候能保证它连续操作的顺序性,那就不用加 Barrier 了。比如 Load x; Load x.field 读 x 再读 x 下面某个 field,如果访问同一个内存 CPU 能保证顺序性,两次读取之间的 Barrier 就不再需要了,根据字节码编译得到的汇编指令中,本来应该插入 Barrier 的地方会被替换为 nop ,即空操作。在 x86 上,实际只有 StoreLoad 这一个 Barrier 是有效的,x86 上没有 Invalidate Queue,每次 Store 数据又都会去 Store Buffer 排队,所以 StoreStore , LoadLoad 都不需要。x86 又能保证 Store 操作都会走 Store Buffer 异步刷写,Store 不会被重排到 Load 之前, LoadStore 也是不需要的。只剩下一个 StoreLoad Barrier 在 x86 平台的 JVM 上被使用。
x86 上怎么使用 Barrier 的说明可以在 openjdk 的代码中看到,在这里 src/hotspot/cpu/x86/assembler_x86.hpp 。可以看到 x86 下使用的是 lock 来实现 StoreLoad ,并且只有 StoreLoad 有效果。在这个代码注释中还大致介绍了使用 lock 的原因。
volatile
JVM 上对 Barrier 的一个主要应用是在 volatile 关键字的实现上。对这个关键字的实现 Oracle 有这么一段描述:
Using volatile variables reduces the risk of memory consistency errors, because any write to a volatile variable establishes a happens-before relationship with subsequent reads of that same variable. This means that changes to a volatile variable are always visible to other threads. What's more, it also means that when a thread reads a volatile variable, it sees not just the latest change to the volatile, but also the side effects of the code that led up the change.
来自 Oracle 对 Atomic Access 的说明: Atomic Access 。大致上就是说被 volatile 标记的变量需要维护两个特性:
- 可见性,每次读
volatile变量总能读到它最新值,即最后一个对它的写入操作,不管这个写入是不是当前线程完成的。 - 禁止指令重排,也即维护
happens-before关系,对volatile变量的写入不能重排到写入之前的操作之前,从而保证别的线程看到写入值后就能知道写入之前的操作都已经发生过;对volatile的读取操作一定不能被重排到后续操作之后,比如我需要读volatile后根据读到的值做一些事情,做这些事情如果重排到了读volatile之前,则相当于没有满足读volatile需要读到最新值的要求,因为后续这些事情是根据一个旧volatile值做的。
需要看到两个事情,一个是禁止指令重排不是禁止所有的重排,只是 volatile 写入不能向前排,读取不能向后排。别的重排还是会允许。另一个是禁止指令重排实际也是为了去满足可见性而附带产生的。所以 volatile 对上述两个特性的维护就能靠 Barrier 来实现。
假设约定 Normal Load, Normal Store 对应的是对普通引用的修改。好比有 int a = 1; 那 a = 2; 就是 Normal Store, int b = a; 就有一次对 a 的 Normal Load。如果变量带着 volatile 修饰,那对应的读取和写入操作就是 Volatile Load 或者 Volatile Store。 volatile 对代码生成的字节码本身没有影响,即 Java Method 生成的字节码无论里面操作的变量是不是 volatile 声明的,生成的字节码都是一样的。 volatile 在字节码层面影响的是 Class 内 Field 的 access_flags (参看 Java 11 The Java Virtual Machine Specification 的 4.5 节),可以理解为当看到一个成员变量被声明为 volatile ,Java 编译器就在这个成员变量上打个标记记录它是 volatile 的。JVM 在将字节码编译为汇编时,如果碰见比如 getfield , putfield 这些字节码,并且发现操作的是带着 volatile 标记的成员变量,就会在汇编指令中根据 JMM 要求插入对应的 Barrier。
根据 volatile 语义,我们依次看下面操作次序该用什么 Barrier,需要说明的是这里前后两个操作需要操作不同的变量:
volatile
上面四种情况要用 Barrier 的原因统一来说就是前面 Oracle 对 Atomic Access 的说明,写一个 volatile 的变量被别的 CPU 看到时,需要保证写这个变量操作之前的操作都能完成,不管前一个操作是读还是写,操作的是 volatile 变量还是不是。如果 Store 操作做了重排,排到了前一个操作之前,就会违反这个约定。所以 volatile 变量操作是在 Store 操作前面加 Barrier,而 Store 后如果是 Normal 变量就不用 Barrier 了,重不重排都无所谓:
- Volatile Store, Normal Load
- Volatile Store, Normal Store
对于 volatile 变量的读操作,为了满足前面提到 volatile 的两个特性,为了避免后一个操作重排到读 volatile 操作之前,所以对 volatile 的读操作都是在读后面加 Barrier:
- Volatile Load, Volatile Load。得用 LoadLoad。
- Volatile Load, Normal Load。得用 LoadLoad。
- Volatile Load, Normal Store。得用 LoadStore。
而如果后一个操作是 Load,则不需要再用 Barrier,能随意重排:
- Normal Store, Volatile Load。
- Normal Load, Volatile Load。
最后还有个特别的,前一个操作是 Volatile Store,后一个操作是 Volatile Load:
- Volatile Store, Volatile Load。得用 StoreLoad。因为前一个 Store 之前的操作可能导致后一个 Load 的变量发生变化,后一个 Load 操作需要能看到这个变化。
还剩下四个 Normal 的操作,都是随意重排,没影响:
- Normal Store, Normal Load
- Normal Load, Normal Load
- Normal Store, Normal Store
- Normal Load, Normal Store
这些使用方式和 Java 下具体操作的对应表如下:

图中 Monitor Enter 和 Monitor Exit 分别对应着进出 synchronized 块。Monitor Ender 和 Volatile Load 对应,使用 Barrier 的方式相同。Monitor Exit 和 Volatile Store 对应,使用 Barrier 的方式相同。
总结一下这个图,记忆使用 Barrier 的方法非常简单,只要是写了 volatile 变量,为了保证对这个变量的写操作被其它 CPU 看到时,这个写操作之前发生的事情也都能被别的 CPU 看到,那就需要在写 volatile 之前加入 Barrier。避免写操作被向前重排导致 volatile 变量已经写入了被别的 CPU 看到了但它前面写入过,读过的变量却没有被别的 CPU 感知到。写入变量被别的 CPU 感知到好说,这里读变量怎么可能被别的 CPU 感知到呢?主要是
在读方面,只要是读了 volatile 变量,为了保证后续基于这次读操作而执行的操作能真的根据读到的最新值做接下来的事情,需要在读操作之后加 Barrier。
在此之外加一个特殊的 Volatile Store, Volatile Load,为了保证后一个读取能看到因为前一次写入导致的变化,所以需要加入 StoreLoad Barrier。
JMM 说明中,除了上面表中讲的 volatile 变量相关的使用 Barrier 地方之外,还有个特殊地方也会用到 Barrier,是 final 修饰符。在修改 final 变量和修改别的共享变量之间,要有一个 StoreStore Barrier。例如 x.finalField = v; StoreStore; sharedRef = x; 下面是一组操作举例,看具体什么样的变量被读取、写入的时候需要使用 Barrier。
最后可以看一下 JSR-133 Cookbook 里给的例子,大概感受一下操作各种类型变量时候 Barrier 是怎么加的:

volatile 的可见性维护
总结来说, volatile 可见性包括两个方面:
- 写入的
volatile变量在写完之后能被别的 CPU 在下一次读取中读取到; - 写入
volatile变量之前的操作在别的 CPU 看到volatile的最新值后一定也能被看到;
对于第一个方面,主要通过:
- 读取
volatile变量不能使用寄存器,每次读取都要去内存拿 - 禁止读
volatile变量后续操作被重排到读volatile之前
对于第二个方面,主要是通过写 volatile 变量时的 Barrier 保证写 volatile 之前的操作先于写 volatile 变量之前发生。
最后还一个特殊的,如果能用到 StoreLoad Barrier,写 volatile 后一般会触发 Store Buffer 的刷写,所以写操作能「立即」被别的 CPU 看到。
一般提到 volatile 可见性怎么实现,最常听到的解释是「写入数据之后加一个写 Barrier 去刷缓存到主存,读数据之前加入 Barrier 去强制从主存读」。
从前面对 JMM 的介绍能看到,至少从 JMM 的角度来说,这个说法是不够准确的。一方面 Barrier 按说加在写 volatile 变量之前,不该之后加 Barrier。而读 volatile 是在之后会加 Barrier,而不在之前。另一方面关于 「刷缓存」的表述也不够准确,即使是 StoreLoad Barrier 刷的也是 Store Buffer 到缓存里,而不是缓存向主存去刷。如果待写入的目标内存在当前 CPU Cache,即使触发 Store Buffer 刷写也是写数据到 Cache,并不会触发 Cache 的 Writeback 即向内存做同步的事情,同步主存也没有意义因为别的 CPU 并不一定关心这个值;同理,即使读 volatile 变量后有 Barrier 的存在,如果目标内存在当前 CPU Cache 且处于 Valid 状态,那读取操作就立即从 Cache 读,并不会真的再去内存拉一遍数据。
需要补充的是无论是 volatile 还是普通变量在读写操作本身方面完全是一样的,即读写操作都交给 Cache,Cache 通过 MESI 及其变种协议去做缓存一致性维护。这两种变量的区别就只在于 Barrier 的使用上。
volatile 读取操作是 Free 的吗
在 x86 下因为除了 StoreLoad 之外其它 Barrier 都是空操作,但是读 volatile 变量并不是完全无开销,一方面 Java 的编译器还是会遵照 JMM 要求在本该加入 Barrier 的汇编指令处填入 nop ,这会阻碍 Java 编译器的一些优化措施。比如本来能进行指令重排的不敢进行指令重排等。另外因为访问的变量被声明为 volatile ,每次读取它都得从内存( 或 Cache ) 要,而不能把 volatile 变量放入寄存器反复使用。这也降低了访问变量的性能。
理想情况下对 volatile 字段的使用应当多读少写,并且尽量只有一个线程进行写操作。不过读 volatile 相对读普通变量来说也有开销存在,只是一般不是特别重。
回顾 False Sharing 里的例子
[[CPU Cache 基础]] 这篇文章内介绍了 False Sharing 的概念以及如何观察到 False Sharing 现象。其中有个关键点是为了能更好的观察到 False Sharing,得将被线程操作的变量声明为 volatile ,这样 False Sharing 出现时性能下降会非常多,但如果去掉 volatile 性能下降比率就会减少,这是为什么呢?
简单来说如果没有 volatile 声明,也即没有 Barrier 存在,每次对变量进行修改如果当前变量所在内存的 Cache Line 不在当前 CPU,那就将修改的操作放在 Store Buffer 内等待目标 Cache Line 加载后再实际执行写入操作,这相当于写入操作在 Store Buffer 内做了积累,比如 a++ 操作不是每次执行都会向 Cache 里执行加一,而是在 Cache 加载后直接执行比如加 10,加 100,从而将一批加一操作合并成一次 Cache Line 写入操作。而有了 volatile 声明,有了 Barrier,为了保证写入数据的可见性,就会引入等待 Store Buffer 刷写 Cache Line 的开销。当目标 Cache Line 还未加载入当前 CPU 的 Cache,写数据先写 Store Buffer,但看到例如 StoreLoad Barrier 后需要等待 Store Buffer 的刷写才能继续执行下一条指令。还是拿 a++ 来说,每次加一操作不再能积累,而是必须等着 Cache Line 加载,执行完 Store Buffer 刷写后才能继续下一个写入,这就放大了 Cache Miss 时的影响,所以出现 False Sharing 时 Cache Line 在多个 CPU 之间来回跳转,在被修改的变量有了 volatile 声明后会执行的更慢。
再进一步说,我是在我本机做测试,我的机器是 x86 架构的,在我的机器上实际只有 StoreLoad Barrier 会真的起作用。我们去 open jdk 的代码里看看 StoreLoad Barrier 是怎么加上的。
先看这里,JSR-133 Cookbook 里定义了一堆 Barrier,但 JVM 虚拟机上实际还会定义更多一些 Barrier 在 src/hotspot/share/runtime/orderAccess.hpp 。
每个不同的系统或 CPU 架构会使用不同的 orderAccess 的实现,比如 linux x86 的在 src/hotspot/os_cpu/linux_x86/orderAccess_linux_x86.hpp ,BSD x86 和 Linux x86 的类似在 src/hotspot/os_cpu/bsd_x86/orderAccess_bsd_x86.hpp ,都是这样定义的:
inline void OrderAccess::loadload() { compiler_barrier(); }
inline void OrderAccess::storestore() { compiler_barrier(); }
inline void OrderAccess::loadstore() { compiler_barrier(); }
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::acquire() { compiler_barrier(); }
inline void OrderAccess::release() { compiler_barrier(); }
inline void OrderAccess::fence() {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
compiler_barrier();
}
复制代码
compiler_barrier() 只是为了不做指令重排,但是对应的是空操作。看到上面只有 StoreLoad 是实际有效的,对应的是 fence() ,看到 fence() 的实现是用 lock 。为啥用 lock 在前面贴的 assembler_x86 的注释里有说明。
之后 volatile 变量在每次修改后,都需要使用 StoreLoad Barrier,在解释执行字节码的代码里能看到。 src/hotspot/share/interpreter/bytecodeInterpreter.cpp ,看到是执行 putfield 的时候如果操作的是 volatile 变量,就在写完之后加一个 StoreLoad Barrier。我们还能找到 MonitorExit 相当于对 volatile 的写入,在 JSR-133 Cookbook 里有说过,在 openjdk 的代码里也能找到证据在 src/hotspot/share/runtime/objectMonitor.cpp 。
JSR-133 Cookbook 还提到 final 字段在初始化后需要有 StoreStore Barrier,在 src/hotspot/share/interpreter/bytecodeInterpreter.cpp 也能找到。
这里问题又来了,按 JSR-133 Cookbook 上给的图,连续两次 volatile 变量写入中间不该用的是 StoreStore 吗,从上面代码看用的怎么是 StoreLoad 。从 JSR-133 Cookbook 上给的 StoreLoad 是说 Store1; StoreLoad; Load2 含义是 Barrier 后面的所有读取操作都不能重排在 Store1 前面,并不是仅指紧跟着 Store1 后面的那次读,而是不管隔多远只要有读取都不能做重排。所以我理解拿 volatile 修饰的变量来说,写完 volatile 之后,程序总有某个位置会去读这个 volatile 变量,所以写完 volatile 变量后一定总对应着 StoreLoad Barrier,只是理论上存在比如只写 volatile 变量但从来不读它,这时候才可能产生 StoreStore Barrier。当然这个只是我从 JDK 代码上和实际测试中得到的结论。
怎么观察到上面说的内容是不是真的呢?我们需要把 JDK 编码结果打印出来。可以参考 这篇文章 。简单来说有两个关键点:
- 启动 Java 程序时候带着这些参数:
-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly - 需要想办法下载或编译出来 hsdis,放在
JAVA_HOME的jre/lib下面
如果缺少 hsdis 则会在启动程序时候看到:
Could not load hsdis-amd64.dylib; library not loadable; PrintAssembly is disabled 复制代码
之后我们去打印之前测试 False Sharing 例子中代码编译出来的结果,可以看到汇编指令中,每次执行完写 volatile 的 valueA 或者 valueB 后面都跟着 lock 指令,即使 JIT 介入后依然如此,汇编指令大致上类似于:
0x0000000110f9b180: lock addl $0x0,(%rsp) ;*putfield valueA
; - cn.leancloud.filter.service.SomeClassBench::testA@2 (line 22)
复制代码
内存屏障在 JVM 的其它应用
Atomic 的 LazySet
跟 Barrier 相关的还一个有意思的,是 Atomic 下的 LazySet 操作。拿最常见的 AtomicInteger 为例,里面的状态 value 是个 volatile 的 int ,普通的 set 就是将这个状态修改为目标值,修改后因为有 Barrier 的关系会让其它 CPU 可见。而 lazySet 与 set 对比是这样:
public final void set(int newValue) {
value = newValue;
}
public final void lazySet(int newValue) {
unsafe.putOrderedInt(this, valueOffset, newValue);
}
复制代码
对于 unsafe.putOrderedInt() 的内容 Java 完全没给出解释,但从添加 lazySet() 这个功能的地方: Bug ID: JDK-6275329 Add lazySet methods to atomic classes ,能看出来其作用是在写入 volatile 状态前增加 StoreStore Barrier。它只保证本次写入不会重排到前面写入之前,但本次写入什么时候能刷写到内存是不做要求的,从而是一次轻量级的写入操作,在特定场景能优化性能。
ConcurrentLinkedQueue 下的黑科技
简单介绍一下这个黑科技。比如现在有 a b c d 四个 volatile 变量,如果无脑执行:
a = 1; b = 2; c = 3; d = 4; 复制代码
会在每个语句中间加上 Barrier。直接上面这样写可能还好,都是 StoreStore 的 Barrier,但如果写 volatile 之后又有一些读 volatile 操作,可能 Barrier 就会提升至最重的 StoreLoad Barrier,开销就会很大。而如果对开始的 a b c 写入都是用写普通变量的方式写入,只对最后的 d 用 volatile 方式更新,即只在 d = 4 前带上写 Barrier,保证 d = 4 被其它 CPU 看见时,a、b、c 的值也能被别的 CPU 看见。这么一来就能减少 Barrier 的数量,提高性能。
JVM 里上一节介绍的 unsafe 下还有个叫 putObject 的方法,用来将一个 volatile 变量以普通变量方式更新,即不使用 Barrier。用这个 putObject 就能做到上面提到的优化。
ConcurrentLinkedQueue 是 Java 标准库提供的无锁队列,它里面就用到了这个黑科技。因为是链表,所以里面有个叫 Node 的类用来存放数据, Node 连起来就构成链表。 Node 内有个被 volatile 修饰的变量指向 Node 存放的数据。 Node 的部分代码如下:
private static class Node<E> {
volatile E item;
volatile Node<E> next;
Node(E item) {
UNSAFE.putObject(this, itemOffset, item);
}
....
}
复制代码
因为 Node 被构造出来后它得通过 cas 操作队尾 Node 的 next 引用接入链表,接入成功之后才需要被其它 CPU 看到,在 Node 刚构造出来的时候, Node 内的 item 实际不会被任何别的线程访问,所以看到 Node 的构造函数可以直接用 putObject 更新 item ,等后续 cas 操作队列队尾 Node 的 next 时候再以 volatile 方式更新 next ,从而带上 Barrier,更新完成后 next 的更新包括 Node 内 item 的更新就都被别的 CPU 看到了。从而减少操作 volatile 变量的开销。
正文到此结束
- 本文标签: IDE value lib Service bug 编译 js 数据 代码注释 同步 Atom 一致性 java https UI App 总结 queue 模型 linux git cat 注释 final 下载 id 并发 ip 线程 代码 锁 文章 IO 缓存 node Oracle GitHub volatile http 图片 synchronized tab 科技 内存模型 参数 DDL cache 字节码 测试 NSA REST src ORM JVM 协议
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

