Dubbo 授渔:微内核架构在 Dubbo 的应用
授人以鱼,不如授之以渔,其实这句话并不只是说如何教人。
从另一个角度看这句话,我们在学一样东西的时候,要找到这样东西的”渔“是什么。
对于一项技术来说,它背后的设计思想,就是学习它的”渔“,对于 Dubbo,”渔“,是微内核架构。
首先,我们以「保险索赔」为例,了解下什么是微内核架构。
保险索赔
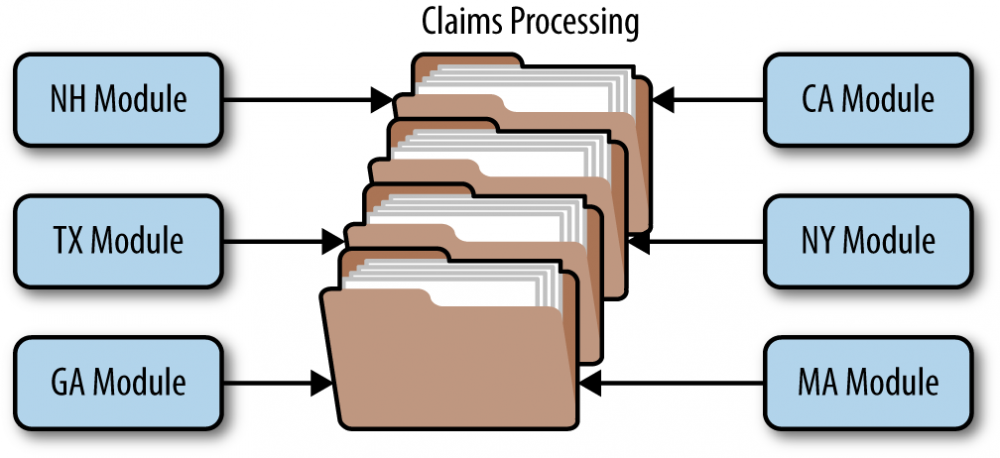
保险索赔的规则往往很复杂,不同保险产品、不同地区的索赔规则可能都不一样。
举个例子,假设在纽约州(NY),汽车挡风玻璃被岩石击碎,是可以索赔的,但是在加利福尼亚州(CA)则不行。这时候如果直接把这个逻辑写到代码里去,就是这样:
if (在纽约) {
if (被岩石击碎) {
// 索赔...
}
} else if (在加利福尼亚) {
if (被岩石击碎) {
// 不索赔...
}
}
而且保险规则可不只这一条,到时候写出来就是这样:
if (在纽约) {
if (被岩石击碎) {
// 索赔...
}
if (被陨石击碎) {
// 索赔...
}
if (被流星击碎) {
// 索赔...
}
// more and more...
} else if (在加利福尼亚) {
if (被岩石击碎) {
// 不索赔...
}
if (被陨石击碎) {
// 不索赔...
}
if (被流星击碎) {
// 不索赔...
}
// more and more...
}
可以看到,我们把索赔规则这的码耦合到索赔的核心系统中:
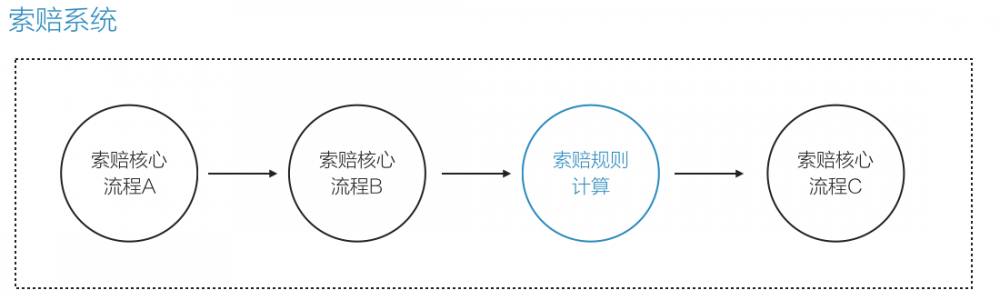
这会带来两个问题:
- 修改索赔规则需要重新发布整个系统
- 索赔规则的改动可能会影响整个系统,甚至导致整个系统不可用
于是我们把这些规则抽取出来,有个专门的地方去管理这些规则,简单说,就是「解耦」:
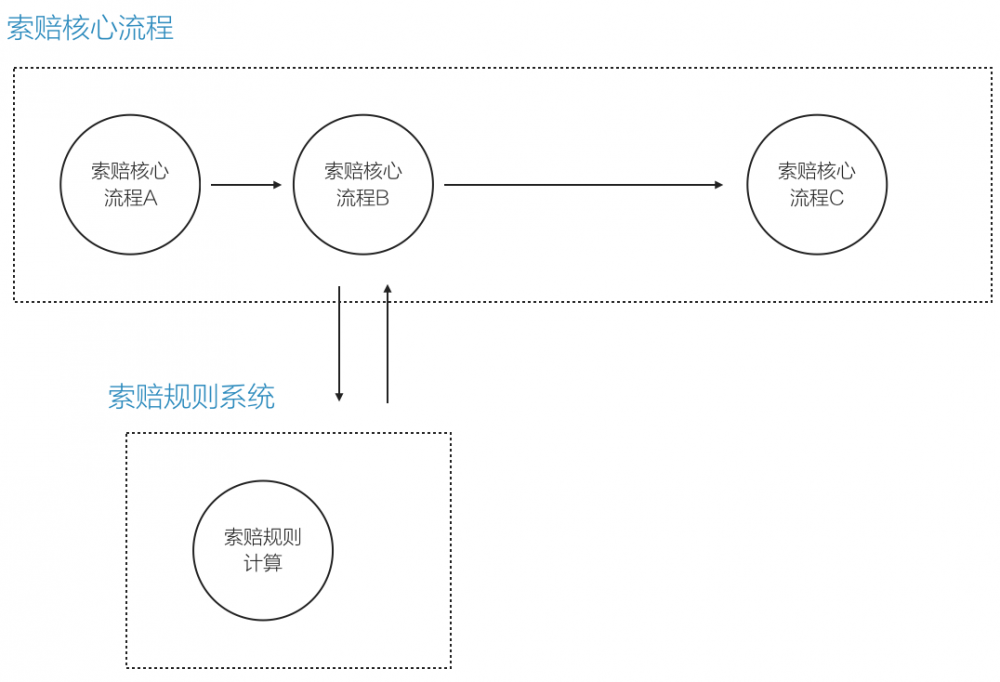
这样就解决了「耦合度高」的问题,但其实解耦的还不够彻底。
不同州的规则还是放到一起的,而我们在索赔处理的时候,每次只需要加载一个州的索赔规则,不存在既需要纽约州的规则,又需要加州规则的情况:

另外,如果后面新来了一个州,想接入索赔系统,那么如何让这个州,在不影响其他州的情况下,配置自己的索赔规则?
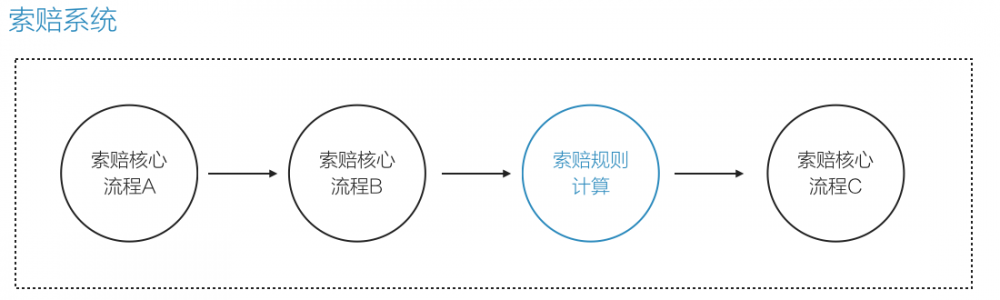
于是有了这样一套保险索赔的「微内核架构」:
简单说就是,这套系统分两个模块:
1、中间的核心模块
处理保险索赔的基本业务逻辑
2、保险规则
由每个州自己去实现,做成插件,可以被单独加载和移除,不影响核心系统和其他插件。
了解完了保险索赔系统的微内核实现,我们再来看看微内核架构,到底是什么。
什么是微内核架构
Oreilly 对于微内核架构的定义 是这样的(纯英文,大家要再三细品):
The microkernel architecture pattern consists of two types of architecture components: a core system and plug-in modules .
Application logic is divided between independent plug-in modules and the basic core system, providing extensibility , flexibility , and isolation of application features and custom processing logic.
简单说,就是微内核架构包含两个组件:核心系统(core system)和插件模块(plug-in modules),目的是为了扩展性、灵活性和隔离性。
核心系统和插件模块又都有什么职责呢?
The core system of the microkernel architecture pattern traditionally contains only the minimal functionality required to make the system operational.
The plug-in modules are stand-alone, independent components that contain specialized processing , additional features , and custom code that is meant to enhance or extend the core system to produce additional business capabilities
核心系统只包含让系统可以运作的最小功能,有点像 MVP(Minimum Viable Product ,最小可用产品)。
而插件模块,则包含一些特殊处理逻辑、额外的功能、自定义代码,用于强化和扩展核心系统,提供更多的业务能力。
这么讲还是比较抽象,所以,接下来,进入主题,来看看 Dubbo 这个 RPC 框架,是如何基于微内核架构进行设计的。
什么是 RPC 系统的 core?
Dubbo 在本质上是在解决如何进行远程调用(rpc)的问题,通常一个 rpc 系统都长这个样子:
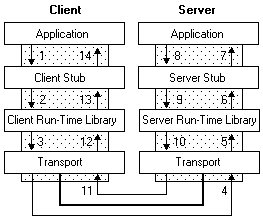
但是这些都是一个 rpc 系统所必须的吗?
能不能去掉哪个模块后,依然可以进行 rpc 调用?
相信大多数人都可以发现,stub 层是可以去掉的,去掉后,无非你就没法再进行透明式调用罢了。
还有吗?还有其他哪个模块也可以去掉吗?
我们来看一个极简的 rpc 调用。
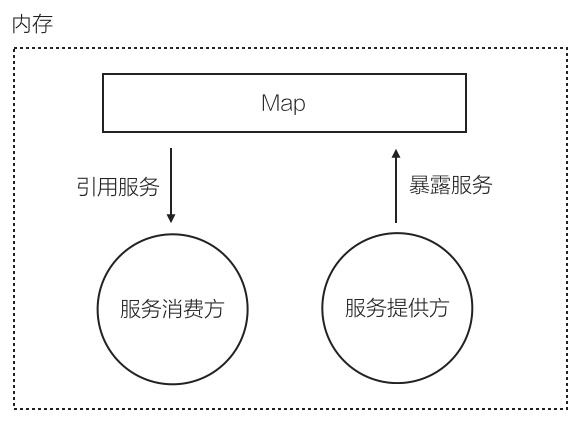
在这个例子里,服务提供方,和服务消费方,是位于同一块内存的:
- 服务提供方,暴露服务时,只需要把自己注册到一个 map 里
- 服务消费方,引用服务时,则只需从 map 里获取到服务提供方的引用
- 当服务消费方调用服务提供方的方法时,其实是一次本地内存调用,不涉及什么网络传输、协议转换、序列化、反序列化
大道至简,当我们把 rpc 这个模型进行简化后,会发现其实这样就足够了:
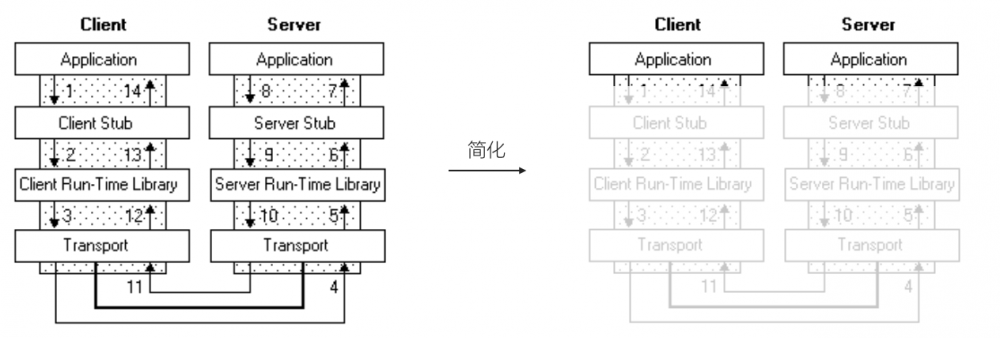
其实这也是 Dubbo 里 inJVM 协议的实现原理。
当然实际使用中,我们不可能只使用内存调用的 rpc,举这个例子,其实是为了下面介绍 Dubbo 的内核。
什么是 Dubbo 的 core?
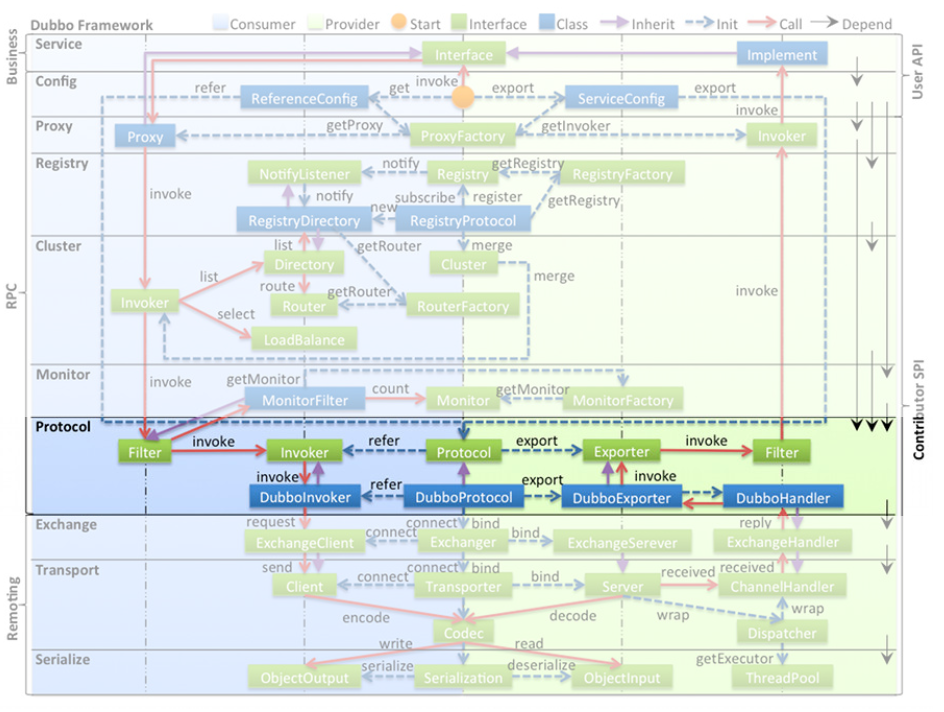
我们从系统的角度,看看 Dubbo 的整体设计图 :
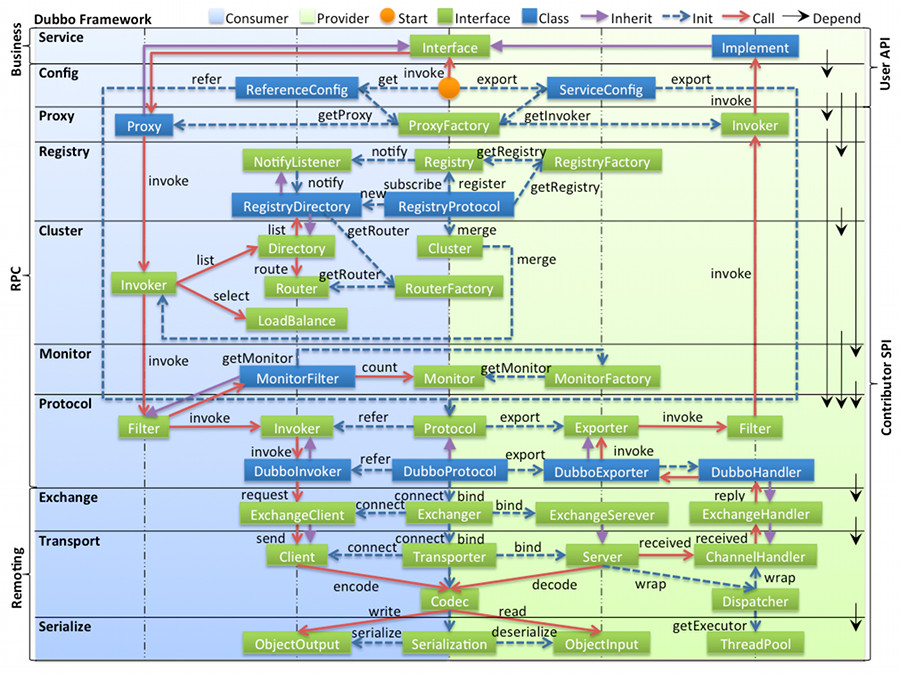
这个是一种传统的分层视角,每一层都有自己要解决的问题,用 DDD 的话来说,就是每个域都有自己的问题空间:
- proxy 层,解决的是:如何实现服务接口的透明代理;
- cluster 层,解决的是:当有多个服务提供者时,如何调用、如何负载均衡等等;
- 底下三层,也就是 remote 层,解决的是:如何进行远程调用;
按照这个视角来看,其实每一层都有自己的 core,每一层都支持通过 SPI 的方式,来实现扩展。
但如果我们换个视角来看,之前说过,Dubbo 本质上是为了解决 rpc 的问题,那么其实我们只需要 protocol 层就足够了:
我们也不必再用传统的分层架构来看,而是换一个视角:
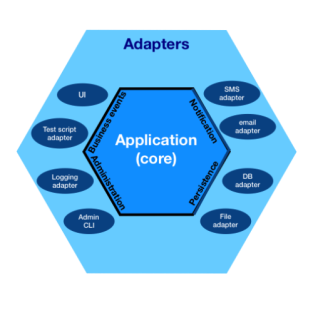
这个叫「六边形架构」(Hexagonal Architecture),也叫「端口-适配器架构」(Ports and Adapters Architecture),这里就不展开细讲了,有兴趣的同学可以谷歌下。
两种视角的不同就在于,传统分层视角没有突出核心和重点,你看不出哪一层是必须的,哪一层是整个架构的起源,而六边形架构,则一目了然。
对于 Dubbo 来说,只有 Protocol 层是核心,是必须的:
- 当你只需要一次 injvm 的 rpc 调用时,只用 Protocol ,足矣;
- 如果你需要远程调用,而且有多个服务提供方,那需要引入 remote、cluster 和 registry;
- 如果你还需要透明式的 rpc 调用,那就再引入 proxy 层
那么 Protocol 层都做了什么呢,为什么有了它就可以实现一次 rpc 调用?
Protocol 层如何实现 rpc 调用?
Protocol 层,其实就是上面提到的,一个最简化的 rpc 模型:
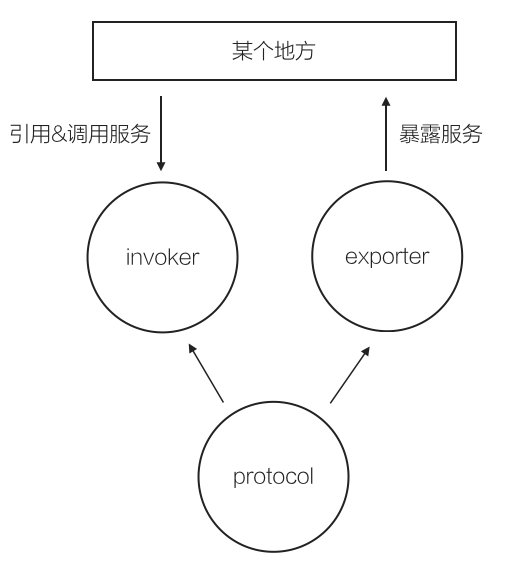
三个角色:
- exporter:对应服务提供方,负责把服务暴露到某个地方
- invoker:对应服务消费方,从某个地方引用服务,并调用服务
- protocol:使用什么样的 protocol,决定了会有什么样的 invoker 和 exporter
很明显,核心角色是 protocol,比如你采用 injvm
协议,那就会生成 InjvmInvoker 和 InjvmExporter:
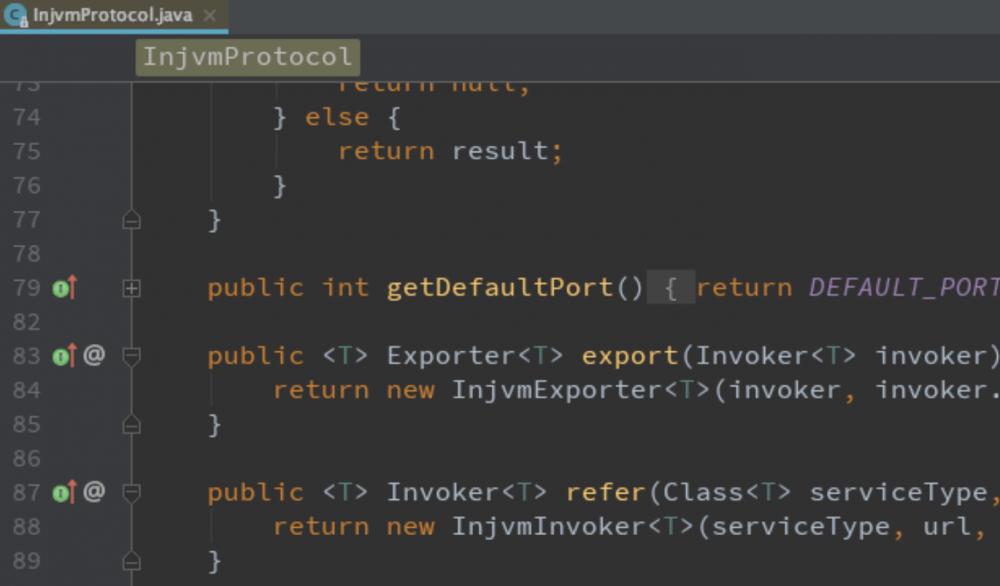
而如果你采用的是 dubbo
协议,则会生成 DubboInvoker 和 DubboExporter:
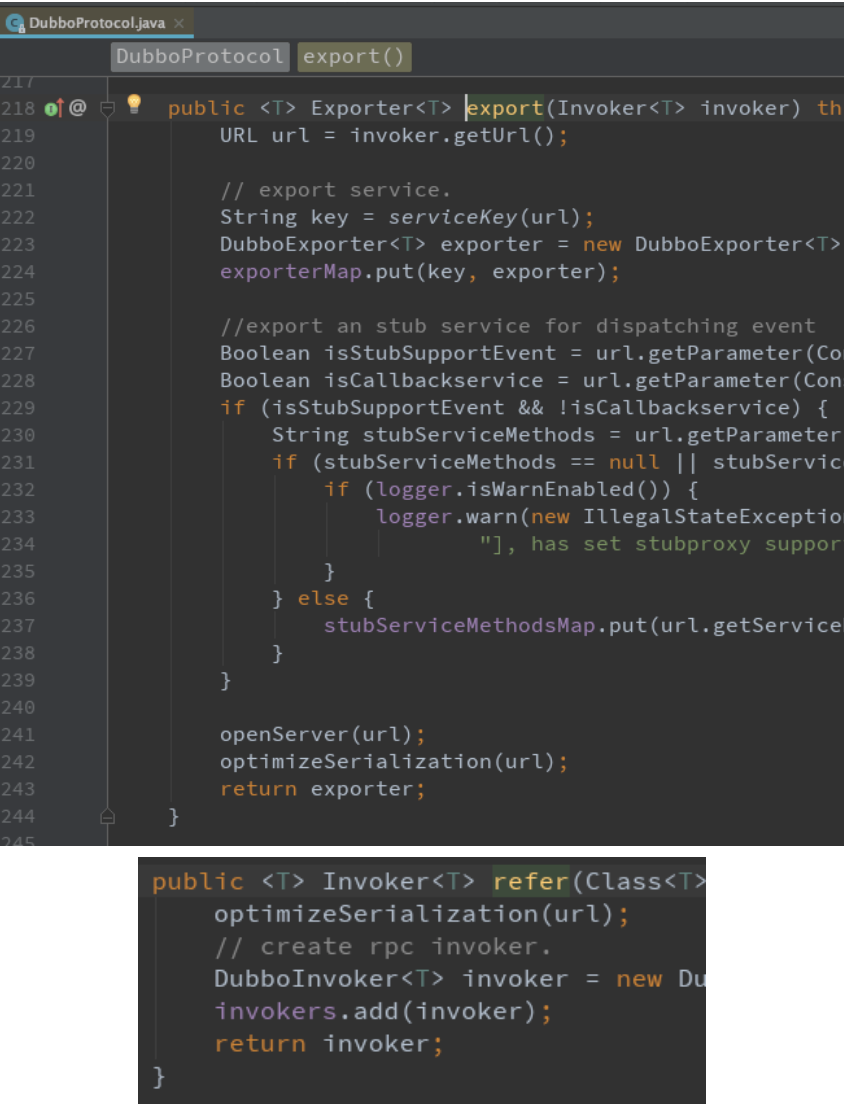
仔细看代码,你会发现, dubbo
协议的 refer 方法,会把 invoker 放进一个 invokers 集合里, injvm
协议的 refer 方法,则直接 new 一个 invoker 后就返回了,说明前者是有可能存在多个服务提供者的,而后者只会有一个。
而这些细节上的差异,追溯到根源,就是你用了什么样的协议(protocol)。
在 RPC 中,Protocol 是核心层,也就是只要有 Protocol + Invoker + Exporter 就可以完成非透明的 RPC 调用。 —— from Dubbo 框架设计
微内核架构的其他使用
除了上面提到的保险索赔、Dubbo,微内核架构还被用到很多地方。
其实微内核架构的起源,是操作系统:
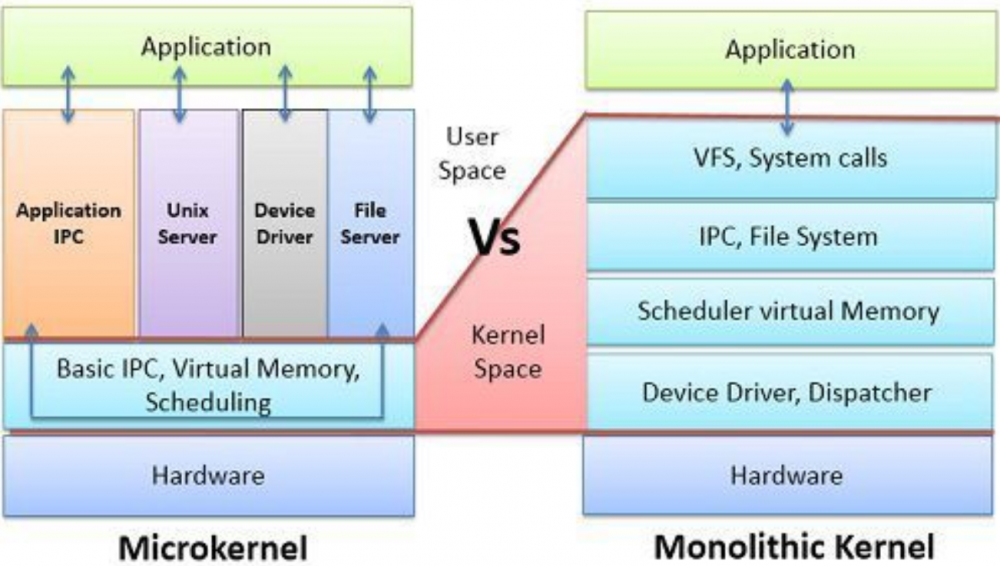
左边是 Microkernel,右边是与之对应的 Monolithic Kernel,前者只提供最最基础的操作系统能力,而把更多的能力开放给外界来提供,而后者则倾向于提供一个大而全的操作系统。
这里不展开讲,大家可以前往 维基百科 了解下。
后来,这种思想逐渐被演变成一种架构设计模式,于是有了「微内核架构」。
它被用在了许多客户端应用,像 Chrome 浏览器:

像 Eclipse 编辑器:
Chrome 核心就是一个浏览器,用来浏览网页。你可以给它添加各种各样的插件,像翻译插件、广告屏蔽插件等等;而对于第三方开发者,则可以给它开发各种插件。
Eclipse 也一样,核心就是一个编辑器,和记事本没什么区别,给它添加各种各样的插件,像代码高亮、java 代码编译等等,就成了一个好用的开发工具;第三方开发者同样可以给它开发各种插件。
之后它又被进一步用在了一些软件框架、业务系统上,比如今天讲到的 Dubbo 和保险索赔系统。
甚至在之后的「六边形架构」、DDD 上,都可以看到「微内核架构」的影子,这两种设计思想被大量用到各种框架、中间件的设计上,比如有赞的 MAXIM 全链路压测引擎 :
你可以用一两句话概况这种思想,比如:开闭原则、模板模式、把不变的和变化的隔离等等,但是仅仅通过这种标签式的、高浓缩的、刻板印象的语言就来概况它,未免还是太过缺乏细节和激情了。
微内核架构的优缺点
作为一种架构设计的模式,通常都会考虑这些问题:
- 如何降低系统的复杂度
- 如何提高系统的可维护性
- 如何提高系统的可扩展性
- 如何提高系统的可配置性
微内核架构也不例外,它的优点很明显:
扩展性:高
- 核心系统和插件是低耦合的,插件可插拔
健壮性:高
- 核心系统和插件之间是隔离的,改变也是隔离的
- 核心系统可以保持稳定
易部署性:高
- 插件可支持动态添加(热部署)
可测试性:高
- 插件可以独立测试
缺点也有:
可伸缩性:低
- 大部分实现都是基于产品的(product based),实现时不会考虑高可伸缩性,当然这同样取决于你的实现方式。
开发难度:高
- 微内核架构需要深思熟虑的设计和契约的规划管理,因此实现起来比较复杂。
- 契约的版本机制、插件的注册机制、插件的粒度、插件连接方式的选择都使得实现起来是复杂的。
开发难度高这一点,从 Dubbo 的扩展点重构历程 就可以看出来,其实一开始 Dubbo 并不是我们看到的分层架构,而是一步一步演进过来的,每一步都包含这背后开发人员的卧薪尝胆和绞尽脑汁:

最后
授人以鱼不如授人以渔,其实这句古话是有出处的:
临河而羡鱼,不如归家织网。 —— 《淮南子·说林训》
人类历史上迸发过许多璀璨的思想,就像微内核架构其实来源于操作系统的微内核。
我们在回过头去看的时候,可以嘲笑他们有些观念落伍了,但不要忘了一件事,慢一点,再慢一点,不要错过一些可能闪耀出来的那点星光。
参考:
- Microkernel Architecture
- Microkernel
- 微内核架构详解
- Dubbo 框架设计
- Dubbo 扩展点重构
-
Previous
去昆明
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

