spring解决循环源码分析
循环依赖在spring框架中有一个专有名词叫 Circular dependencies ,其具体是指受spring管理的两个bean对象 Bean1和Bean2,Bean1中有成员变量Bean2;Bean2中有成员变量Bean1。具体代码case如下:
代码结构如图:
前前后后一共使用了四个类,其中两个Bean类如下:
@Component
public class Chicken {
@Autowired
Egg egg;
}
复制代码
@Component
public class Egg {
@Autowired
Chicken chicken;
}
复制代码
一个配置类:
@ComponentScan("spring.post1.beans")
public class Config {
}
复制代码
一个简单的main方法启动类:
public class DemoSpringCircularDependencies {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(Config.class);
Chicken chicken = ac.getBean("chicken", Chicken.class);
System.out.println(chicken);
}
}
复制代码
通过代码可以看出,本章主要讨论下spring怎么解决基于@AutoWired注解的Bean的循环依赖问题。而两个循环依赖的Bean就是Chiken(里面需要属性Egg)和Egg(里面需要属性Chicken)。
2 前置知识
-
学习本文前需要对spring的基于注解的bean管理配置方式有基本的了解,不然看不懂上述4个类的作用,那么就无从谈及学习spring源码了,本系列的文章也不是基本的spring配置学习文章,这部分知识自行google。
-
需要对jdk8的lambda有基础的了解。
3 源码分析
3.1 源码栈帧
首先我们先看下需要分析的源码的主要栈帧:
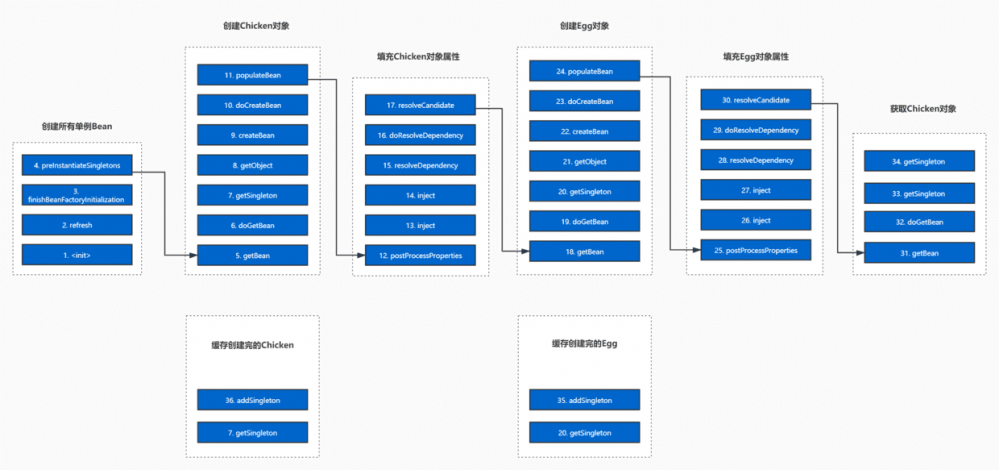
先对上图做简单的说明,上图中的每蓝色小块代表一个方法,里面的数字部分表示方法的执行先后顺序(数字小的先执行)。两个相邻的方法之间大数字方法是程序在执行小数字方法的过程中要调用的方法(和debug时的的栈信息类似)。我们对源码的分析也将按照“创建所有单例Bean”,“创建Chicken对象”,“填充Chicken对象属性”,“创建Egg对象”,“填充Egg对象属性”,“获取Chicken对象”等顺序进行。
3.2 创建所有单例Bean
方法1. 是AnnotationConfigApplicationContext类的构造方法,构造方法引出对Bean的初始化创建操作。其中可以留意下方法2. 中要执行的 finishBeanFactoryInitialization 方法也就是源码栈帧图中的3.方法。在方法3.上面有一句英文注释: “ // Instantiate all remaining (non-lazy-init) singletons. ”,清晰的表明方法3.的主要目的就是要创建剩下没被创建的非懒加载的单例对象。那么我们定义的两个Bean对象Chiken和Egg显然是在这个方法里面创建的,至于为什么是“剩下的”而不是所有的,其它的非懒加载的单例对象是在哪里创建的,不是本文要描述的问题。
3.3 创建Chicken对象
spring创建在创建Bean对象前会给每个Bean对象创建一个BeanDefinition对象,BeanDefinition对象会搜集用户定义的关于Bean的各种配置信息,如这个Bean对象的类型,这个Bean对象的id和name,是否为单例对象等等,这些配置信息可以是xml形式的配置文件,也可以是基于注解的配置信息。
以BeanDefinition的形式搜集了这些信息后,spring就开始初始化非懒加载的单例对象了( 这里我们只分析我们自己定义的和循环依赖相关的两个Bean对象Chicken和Egg的加载过程 )。也就是执行 5. getBean方法。方法5. 是个空壳方法其内部调用的是方法 6. doGetBean方法。doGetBean方法执行过程中会执行一个名为getSingleton(String beanName, boolean allowEarlyReference) 的方法。此方法定义如下:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
复制代码
其主要流程就是通过beanName参数查看先查看map对象 singletonObjects 中是否有对应名称的Bean对象,有返回此Bean对象;没有查看map对象 earlySingletonObjects 中是否有对应名称的Bean对象,有返回此Bean对象;没有查看map对象 singletonFactories 是否有对应名称的ObjectFactory对象,有通过 ObjectFactory 对象的 getObject 方法获取到对应的Bean对象,然后清除 singletonFactories 对应的beanName的映射,同时将得到的Bean对象放到 earlySingletonObjects 中。这其中还有一个方法 isSingletonCurrentlyInCreation(String beanName) 其内部是通过查看一个名为singletonsCurrentlyInCreation的Set对象是否包含指定的beanName,来判断这个单例bean是否正在创建bean对象。
这三个Map对象和一个Set对象就是Spring中解决循环依赖非常重要的缓存,一下我们简称 “ 三Map一Set ”,三个map对象因其在执行获取beanName对应的Bean对象的过程中的先后执行顺序,分别简称为 一级缓存、二级缓存、三级缓存。
-
singletonObjects:一级缓存。此缓存中的Bean对象是经历Spring完整生命周期的Bean对象,
-
earlySingletonObjects:二级缓存。此缓存中的Bean对象是已经通过创建出来的但没有经历spring完整的生命周期的Bean对象。
-
singletonFactories:三级缓存。此缓存存在的是beanName和能获取Bean对象的一个工厂类 ObjectFactory 对象。
方法6. doGetBean 第一次调用 getSingleton(String beanName) 方法时从三个缓存中都没能获得参数chicken对应的Bean对象,程序继续执行到方法7. getSingleton(String beanName, ObjectFactory<?> singletonFactory) ,7. 方法中会执行一个 名为 beforeSingletonCreation(String beanName) 的方法,这个方法会在我们上文提到的中的三Map一Set中的Set添加对应的beanName(chicken)表示此chicken对应的单例Bean处在正在创建过程中,程序继续执行执行到 8. getObject() 方法,方法8. 是一个lambada对象对应的方法,其调用的是方法9. createBean方法进入Bean的创建过程。方法9. 中我们重点关注其执行的方法10. doCreateBean ,此方法是真正执行bean对象的创建的方法。在方法10. 中我们注意到其会执行一个名为 addSingletonFactory 方法,此方法会在我们提到的 三Map一Set中的 三级缓存singletonFactories添加一个beanName(chicken)对应的ObjectFactory对象,而后执行方法10. 中的方法11. populateBean,此时程序传给方法11. 的三个参数分别为beanName:值为chicken、mbd:ChickenBean的BeanDefiniton对象、instanceWrapper:通过构造方法创建的一个Chicken对象,即Spring注解中经常提到的raw bean对象。由方法11.的名称可知,此类的主要目的是填充Chicken对象中的属性(Egg对象),循环依赖正是在此方法中解决的。
3.4 填充Chicken对象属性
紧接上面小节,方法11.中spring通过在Chicken类中的@Autowired 注解来发现其需要的属性:Egg对象并填充其值,这个过程在方法12. postProcessProperties方法中执行,顺便提一句@Autowired注解依赖的属性由 AutowiredAnnotationBeanPostProcessor 类处理,@Resource注解依赖的属性由 CommonAnnotationBeanPostProcessor 类处理。 而方法13. 到方法17. 主要作用就是找到合适的beanName以便用来通过此beanName找到对应的Bean来填充Chicken中的Egg对象,此部分代码和本文主旨无关以后的文章会分析,感兴趣的童鞋可以自行debug看下代码。
3.5 创建Egg对象
紧接上面小节,spring通过方法17. resolveCandidate将找到的合适beanName(egg)传递下来,通过方法18. getBean 来执行对Egg Bean对象的获取操作。此小节调用的方法栈和 “ 3.3 创建chicken对象 ” 小节的方法栈是一样的,唯一的区别是3.3小节传递的beanName参数值为chicken,而本小节传递的beanName参数为egg。
3.6 填充Egg对象属性
本小节对标的是 “ 3.4 填充Chicken对象属性 ”小节,两个小节调用的方法栈是一样的,区别也是参数的不同而已。Spring发现Egg对象需要注入一个Chicken对象。
3.7 获取Chicken对象
这里我们分析的方法31. getBean 和方法18. getBean都是因为我们自己定义的Bean对象中有需要的注入的Bean对象。但是方法31. 传递的参数是chicken,而Chicken对象在 3.3小节中分析得知,其在三Map一Set中的第三级缓存 singletonFactories 存放了一个对应的ObjectFactory对象。spring通过这个ObjectFactory对象获取到了对应的Chicken 对象,而避免了循环依赖。
3.8 缓存创建完的Egg 和缓存创建完的Chicken
通过3.6小节我们获取到了Egg对象需要的成员变量Chicken对象。随着方法栈帧的层层返回,我们将焦点聚焦在由方法21.返回后的方法20.中,在程序执行完方法21. getObject 并获取到经历完Bean生命周期的Egg Bean后,其在方法20. 中还要执行两个比较重要的方法 afterSingletonCreation 和 addSingleton ,其中前者会把三Map一Set中的Set对象singletonsCurrentlyInCreation中的egg移除,表示此Bean对象不是正在创建的Bean对象,Bean创建已经完成;后者会把Egg Bean存放在一级缓存中,同时清空二级缓存和三级缓存中egg对应的映射,至此Egg Bean的spring生命周期已经大体完成。Chicken对象也会执行 afterSingletonCreation 和 addSingleton 两个方法来完成Chicken Bean的spring生命周期。
3.9 源码分析小结
-
创建chicken对象、创建Egg对象:步骤主要解决一个Bean的raw bean对象的创建和的前期准备工作,和本文循环依赖相关的主要是对三Map一Set的对象的保存的内容的修改。
-
填充Chicken对象属性、填充Chicken对象属性:本文中主要通过AutowiredAnnotationBeanPostProcessor类完成依赖对象的搜集和适合依赖对象的beanName的筛选。
-
获取Chicken对象:主要是通过第三级缓存来获取,避免了Chicken对象的重复创建而进入一个死循环。
-
缓存创建完的Egg 和缓存创建完的Chicken:完成善后工作,将走完spring生命周期的Egg Bean和Chicken Bean放到一级缓存中,供客户端程序从spring中获取使用。
4 缓存数据变化
在 “3 源码分析” 章节中,随着程序运行过程中除了有由方法调用和方法返回而产生的线程方法栈图中方法的压栈和出栈外。在这进进出出的背后发生改变的是我们的 三Map一Set 中的数据。
在源码分析的开头小节“ 3.3 创建Chicken对象 ” 和结尾小节“3.8 缓存创建完的Egg 和缓存创建完的Chicken”我们有对三Map一Set的分析,但着并不是说只有这两个小节的部分有数据变更,而是其缓存变化的原理和这连个小节一直,唯一的区别是方法调用的参数不同。整个数据变化图如下:
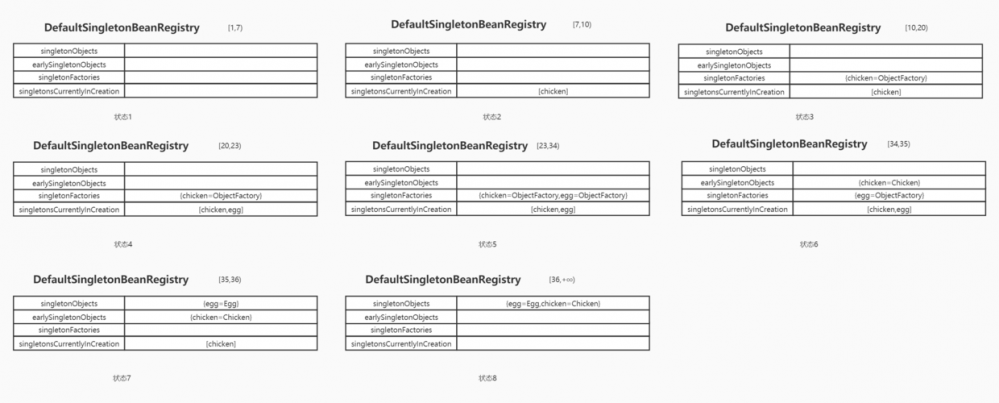
图中每个状态图都有一个“[a,b)”形式的步骤指示器,其中a,b分别表示 “3.1小节” 中源码栈帧图中一个方法数字,而括号用的是高等数学中常见的方式左闭右开方式,表示在程序在执行方法a到方法b(包含a不包含b)过程中缓存数据的状态和其下面的表格一致。
通过对八个表格数据的观察我们可以发现,对于同一个beanName所映射的对象,基本上经历从第三级缓存、第二级缓存、第一级缓存,的一个升级过程。而对网上经常困惑的第三级缓存的作用(认为第三级缓存没有必要存在),博主认为存在第三级缓存是基于以下两个事实的:
-
某些Bean对象(并不是所有的bean对象)在创建过程中且尚未创建完时就会被其它Bean对象所引用的问题(就是循环依赖,貌似是一句废话^_^)。
-
Bean的生命周期过程是一个成本较高的过程。
本文中只有Chicken 对象在创建过程中有被其它对象引用而Egg对象没有。因为第三级缓存存储的是一个raw bean后续创建的方法,那么对于在创建时被其它对象引用的Chicken对象来说,可以执行完第三级缓存中存储的bean对象后续的处理方法(AOP的功能就是在此实现的)后将Chicken bean返回,对于没有在创建过程中被引用的Egg对象来说,其只是浪费第三级缓存中的一点点内存,而避免重复执行spring对Egg Bean的某些生命周期逻辑的重复执行,这些重复的逻辑很可能是很高成本的过程,如AOP的实现。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

