java序列化和反序列化
public class User {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
SocketServer
public class SocketServer {
public static void main(String[] args) {
ServerSocket serverSocket=null;
BufferedReader in=null;
try{
serverSocket=new ServerSocket(8080);
Socket socket=serverSocket.accept();
ObjectInputStream objectInputStream=new ObjectInputStream(socket.getInputStream());
User user=(User)objectInputStream.readObject();
System.out.println(user);
}catch (Exception e){
e.printStackTrace();
}finally {
if(in != null){
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(serverSocket != null){
try {
serverSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
SocketClientConsumer
public class SocketClientConsumer {
public static void main(String[] args) {
Socket socket = null;
ObjectOutputStream out = null;
try {
socket = new Socket("127.0.0.1", 8080);
User user = new User();
out = new ObjectOutputStream(socket.getOutputStream());
out.writeObject(user);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (out != null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
运行结果
这段代码运行以后,能够实现Java对象的正常传输吗?
很显然,会报错

如何解决报错的问题呢?
对User这个对象实现一个Serializable接口,再次运行就可以看到对象能够正常传输了
public class User implements Serializable{
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
了解序列化的意义
我们发现对User这个类增加一个Serializable,就可以解决Java对象的网络传输问题。这就是今天想给大家讲解的序列化这块的意义
Java平台允许我们在内存中创建可复用的Java对象,但一般情况下,只有当JVM处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比JVM的生命周期更长。但在现实应用中,就可能要求在JVM停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。Java对象序列化就能够帮助我们实现该功能
简单来说
序列化是把对象的状态信息转化为可存储或传输的形式过程,也就是把对象转化为字节序列的过程称为对象的序列化
反序列化是序列化的逆向过程,把字节数组反序列化为对象,把字节序列恢复为对象的过程成为对象的反序列化
序列化的高阶认识
简单认识一下Java原生序列化
前面的代码中演示了,如何通过JDK提供了Java对象的序列化方式实现对象序列化传输,主要通过输出流java.io.ObjectOutputStream和对象输入流java.io.ObjectInputStream来实现。
java.io.ObjectOutputStream:表示对象输出流, 它的writeObject(Object obj)方法可以对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
java.io.ObjectInputStream:表示对象输入流,它的readObject()方法源输入流中读取字节序列,再把它们反序列化成为一个对象,并将其返回
需要注意的是,被序列化的对象需要实现java.io.Serializable接口
序列化的高阶认识serialVersionUID的作用
在IDEA中通过如下设置可以生成serializeid
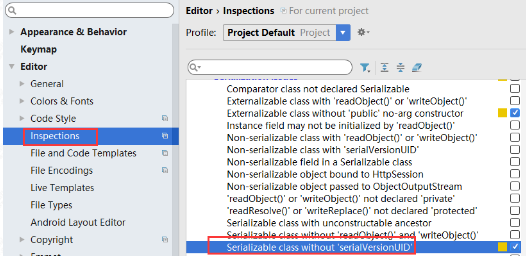
字面意思上是序列化的版本号,凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量
演示步骤
1.先将user对象序列化到文件中
2.然后修改user对象,增加serialVersionUID字段
3.然后通过反序列化来把对象提取出来
4.演示预期结果:提示无法反序列化
结论
Java的序列化机制是通过判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是InvalidCastException。
从结果可以看出,文件流中的class和classpath中的class,也就是修改过后的class,不兼容了,处于安全机制考虑,程序抛出了错误,并且拒绝载入。从错误结果来看,如果没有为指定的class配置serialVersionUID,那么java编译器会自动给这个class进行一个摘要算法,类似于指纹算法,只要这个文件有任何改动,得到的UID就会截然不同的,可以保证在这么多类中,这个编号是唯一的。所以,由于没有显指定serialVersionUID,编译器又为我们生成
了一个UID,当然和前面保存在文件中的那个不会一样了,于是就出现了2个序列化版本号不一致的错误。因此,只要我们自己指定了serialVersionUID,就可以在序列化后,去添加一个字段,或者方法,而不会影响到后期的还原,还原后的对象照样可以使用,而且还多了方法或者属性可以用。
tips:serialVersionUID有两种显示的生成方式:
一是默认的1L,比如:private static final long serialVersionUID = 1L;
二是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段当实现java.io.Serializable接口的类没有显式地定义一个serialVersionUID变量时候,Java序列化机制会根据编译的Class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,如果Class文件(类名,方法明等)没有发生变化(增加空格,换行,增加注释等等),就算再编译多次,serialVersionUID也不会变化的。
Transient关键字
Transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如int 型的是0,对象型的是null。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

