java实现大文本文件拆分
本文实例为大家分享了java实现大文本文件拆分的具体代码,供大家参考,具体内容如下
生成大文件
public static void createBigFile() throws IOException {
File file = new File("/Users/yangpeng/Documents/temp/big_file.csv");
FileWriter fileWriter = new FileWriter(file);
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
String str = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa1";
for (int i = 0; i < 1000000; i++) {
bufferedWriter.write(str);
bufferedWriter.newLine();
}
bufferedWriter.flush();
bufferedWriter.close();
}
文件拆分
此处没有给出根据文件大小计算需要拆分的文件数量,所以这里是给定一个拆分文件数量
思路
思路:给定带拆分数量,计算出每个文件的平均字节数,然后循环文件数进行每个文件的拆分。拆分第一个文件时,根据平均字节数往后取给定的大约行字节数的字节,然后循环字节判断是否为/r或者/n,如果字节为/r或者/n则代表到达行末尾,记录行尾字节位置。知道了开头字节位置与结束字节位置,就可以将此位置之间的数据生成子文件了。继续循环拆分下个文件,基于上个文件记录的结束字节位置继续计算当前文件的结束位置,直到到达拆分文件的数量或者大文件读取完毕。
举个栗子:
有一个3行记录的文件,假设每行记录行字节包含换行符的字节数为100,也就是说这个文件的总字节数为300。
我现在要将这个文件拆分成2个。按照上面的思路,首先我需要计算出文件的平均值300/2=150,这里计算出的平均值并不是拆分出来的子文件一定是150,因为这个数字位置的字节有可能在一行的中间,那么我要基于这个数字算出下个换行符出现的位置当做我这个子文件的结束位。
所以我给定一个行字节数100+150=250,这个150到250之间的字节我认为有换行符,所以我轮询这100字节,判断是否为换行符,结果我轮到到50的位置发现了换行。
那么我这个第一个文件的结束位置是150+50=200,然后将0到200之间的字节生成第一个文件。然后基于这个200的位置继续拆分下个文件,由于200+150已经大于了源文件的大小,所以直接将200到300的数据生成一个子文件。所以最终的结果是一二行为一个子文件,三行为第二个子文件。
代码
考虑到性能与内存占用的问题,此处实现采用NIO
public static void splitFile(String filePath, int fileCount) throws IOException {
FileInputStream fis = new FileInputStream(filePath);
FileChannel inputChannel = fis.getChannel();
final long fileSize = inputChannel.size();
long average = fileSize / fileCount;//平均值
long bufferSize = 200; //缓存块大小,自行调整
ByteBuffer byteBuffer = ByteBuffer.allocate(Integer.valueOf(bufferSize + "")); // 申请一个缓存区
long startPosition = 0; //子文件开始位置
long endPosition = average < bufferSize ? 0 : average - bufferSize;//子文件结束位置
for (int i = 0; i < fileCount; i++) {
if (i + 1 != fileCount) {
int read = inputChannel.read(byteBuffer, endPosition);// 读取数据
readW:
while (read != -1) {
byteBuffer.flip();//切换读模式
byte[] array = byteBuffer.array();
for (int j = 0; j < array.length; j++) {
byte b = array[j];
if (b == 10 || b == 13) { //判断/n/r
endPosition += j;
break readW;
}
}
endPosition += bufferSize;
byteBuffer.clear(); //重置缓存块指针
read = inputChannel.read(byteBuffer, endPosition);
}
}else{
endPosition = fileSize; //最后一个文件直接指向文件末尾
}
FileOutputStream fos = new FileOutputStream(filePath + (i + 1));
FileChannel outputChannel = fos.getChannel();
inputChannel.transferTo(startPosition, endPosition - startPosition, outputChannel);//通道传输文件数据
outputChannel.close();
fos.close();
startPosition = endPosition + 1;
endPosition += average;
}
inputChannel.close();
fis.close();
}
public static void main(String[] args) throws Exception {
Scanner scanner = new Scanner(System.in);
scanner.nextLine();
long startTime = System.currentTimeMillis();
splitFile("/Users/yangpeng/Documents/temp/big_file.csv",5);
long endTime = System.currentTimeMillis();
System.out.println("耗费时间: " + (endTime - startTime) + " ms");
scanner.nextLine();
}
使用NIO可以高效的实现文件拆分,我的文件为100W行大小为1.02G的文本文件,拆分成5个子文件总耗时1224ms
后如下是使用jvisualvm监控的程序内存:
可以看到拆分期间内存浮动基本在1M左右。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
时间:2020-05-19
java IO流将一个文件拆分为多个子文件代码示例
文件分割与合并是一个常见需求,比如:上传大文件时,可以先分割成小块,传到服务器后,再进行合并.很多高大上的分布式文件系统(比如:google的GFS.taobao的TFS)里,也是按block为单位,对文件进行分割或合并. 看下基本思路: 如果有一个大文件,指定分割大小后(比如:按1M切割) step 1: 先根据原始文件大小.分割大小,算出最终分割的小文件数N step 2: 在磁盘上创建这N个小文件 step 3: 开多个线程(线程数=分割文件数),每个线程里,利用RandomAccessF
如何实用Java实现合并、拆分PDF文档
前言 处理PDF文档时,我们可以通过合并的方式,来任意组几个不同的PDF文件或者通过拆分将一个文件分解成多个子文件,这样的好处是对文档的存储.管理很方便.下面将通过Java程序代码介绍具体的PDF合并.拆分的方法. 工具:Free Spire.PDF for Java 2.0.0 (免费版) 注:2.0.0版本的比之前的1.1.0版本在功能上做了很大提升,支持所有收费版的功能,只是在文档页数上有一定限制,要求不超过10页,但是对于常规的不是很大的文件,这个类库就非常实用. jar文件导入: 方法
详解Java生成PDF文档方法

最近项目需要实现PDF下载的功能,由于没有这方面的经验,从网上花了很长时间才找到相关的资料.整理之后,发现有如下几个框架可以实现这个功能. 1. 开源框架支持 iText,生成PDF文档,还支持将XML.Html文件转化为PDF文件: Apache PDFBox,生成.合并PDF文档: docx4j,生成docx.pptx.xlsx文档,支持转换为PDF格式. 比较: iText开源协议为AGPL,而其他两个框架协议均为Apache License v2.0. 使用PDFBox生成PDF就像画图
Java如何设置PDF文档背景色详解
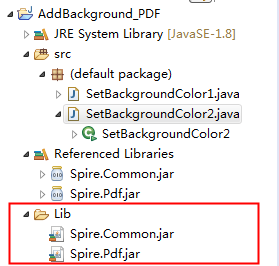
前言 一般生成的PDF文档默认的文档底色为白色,我们可以通过一定方法来更改文档的背景色,以达到文档美化以及保护双眼的作用. 以下内容提供了Java编程来设置PDF背景色的方法.包括: 设置纯色背景 设置图片背景 使用工具 Spire.PDF for Java 2.0.3 Jar文件引用: 方法一 步骤 1:在Java程序中新建一个文件夹可命名为Lib.下载安装包后,解压,将解压后的文件夹下的子文件夹lib中的Spire.Pdf.jar和Spire.Common.jar两个文件复制到新建的文件夹下
Java 生成PDF文档的示例代码

最近项目需要实现PDF下载的功能,由于没有这方面的经验,从网上花了很长时间查找了相关的资料.整理之后,发现有几个框架可以实现这个功能. 1. 开源框架支持 iText,生成PDF文档,还支持将XML.Html文件转化为PDF文件: Apache PDFBox,生成.合并PDF文档: docx4j,生成docx文档,支持转换为PDF格式. 2. 实现方案 比较了一番后,采用了FreeMarker+docx4j+Apache PDFBox的方案: maven依赖 <!-- pdfbox --> &
db2v8的pdf文档资料
正在看的db2教程是:db2v8的pdf文档资料.db2v8的pdf文档资料 下载地址: ftp://ftp.software.ibm.com/ps/produ...vr8/pdf/letter/ 文档资料说明: http://www-3.ibm.com/cgi-bin/db2www...ubs.d2w/en_main 英文文档名称对应列表: db2a1e80.pdf Application Development Guide:Programming Client Application
用PHP编写PDF文档生成器
PHP一个最大的优点就是它对新技术的支持非常容易,这种语言的可扩展性使得开发人员能够很方便地添加新的模块,而且遍布世界的技术团体的支持和众多扩展模块的支持使得PHP已经成为功能最齐全的Web编程语言之 一.目前可得到的扩展模块已经能够使开发人员执行IMAP和POP3操作,可以动态产生图象和Shockwave Flash动画,进行信用卡验证,敏感数据的加密解密,还能够解析XML格式的数据.但这还不是全部,现在,又有一个新的模块可以与PHP进行绑定了,那就是PDFLib扩展模块,它能够让开发人员动
利用python程序生成word和PDF文档的方法
一.程序导出word文档的方法 将web/html内容导出为world文档,再java中有很多解决方案,比如使用Jacob.Apache POI.Java2Word.iText等各种方式,以及使用freemarker这样的模板引擎这样的方式.php中也有一些相应的方法,但在python中将web/html内容生成world文档的方法是很少的.其中最不好解决的就是如何将使用js代码异步获取填充的数据,图片导出到word文档中. 1. unoconv 功能: 1.支持将本地html文档转换为docx
JSP生成WORD文档,EXCEL文档及PDF文档的方法
本文实例讲述了JSP生成WORD文档,EXCEL文档及PDF文档的方法.分享给大家供大家参考,具体如下: 在web-oa系统中,公文管理好象不可或缺,有时需要从数据库中查询一些数据以某种格式输出来,并以word文档的形式展现,有时许多word文档保存到数据库中的某个表的Blob字段里,服务器再把保存在Blob字段中的图片文件展现给用户.通过网上查找发现很少有关于此类的文章,现在整理起来供大家参考. 1 在client端直接生成word文档 在jsp页面上生成word文档非常简单,只需把conte
基于PHP与XML的PDF文档生成技术
摘要 本论文简要介绍了PHP.XML.PDF等技术的原理以及它们的应用情况.力图运用PHP面向对象的特性,构建出一套基于PHP和XML的在线PDF文档生成系统.文中详细探讨了整个系统的组成部分以及各自的实现过程.并在最后给出一个运用这套系统实现的动态创建报表的实例. AbstractThis article introduced the fundamentls of PHP,XML and PDF and their application situation at present,expect
Python实现pdf文档转txt的方法示例
本文实例讲述了Python实现pdf文档转txt的方法.分享给大家供大家参考,具体如下: 首先,这是一个比较粗糙的版本,因为已经够用了,而且对pdf的格式不熟悉,所以暂时没有进一步优化. 还有,这是转成txt的,所以如果是有图片的pdf是无法保存图片的. 至于本来就是图片的文本,这里是无法分析出来的.那些图片的pdf,估计要用图形匹配的方式来处理,类似于超速拍摄的车牌识别. 不过这样的程度,已经不是文本处理了.扯远了... 转出来的文字,好像按照pdf里面的所展示的来换行了,看不到有什么规则还原
正文到此结束
- 本文标签: maven 景色 Google HTML文件 final Word IO 分布式文件系统 apache 线程 管理 Document 开发 http NIO 加密 java db 数据库 IDE 解析 value src 图片 stream db2 tar 数据 HTML Excel lib Freemarker 缓存 IBM UI App iText client 免费 分布式 协议 js 安装 时间 XML ftp 下载 id 服务器 https map 需求 实例 jvisualvm 文章 希望 rand PHP ip cat 代码 DOM 开源 python 文件系统 UTC web
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

