Mybatis源码之美:3.10.1.探究CRUD元素解析工作前的知识准备
在前面的几篇文章中,我们深入的探究了 CRUD 元素的定义和用法,在对 CRUD 元素有了一定的了解之后,在这篇文章中,我们主要探究一下 mybatis 对 CRUD 元素的解析工作.
-
Mybatis源码之美:3.9.探究动态SQL参数
-
Mybatis源码之美:3.8.探究insert,update以及delete元素的用法
-
Mybatis源码之美:3.7.深入了解select元素
-
Mybatis源码之美:3.6.解析sql代码块
解析 CRUD 元素的入口在 XMLMapperBuilder 对象的 configurationElement() 方法中:
private void configurationElement(XNode context) {
// ... 省略 ...
// 构建声明语句(CRUD)
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
// ... 省略 ...
}
复制代码
该方法将获取到的 select , insert , update , delete 四种类型的元素配置交给 buildStatementFromContext() 方法来进行统一的处理.
buildStatementFromContext() 方法是一个中转方法,它调用了自身的一个重载实现来完成真正的处理工作.
/**
* 处理所有的【select|insert|update|delete】节点构建声明语句
*
* @param list 所有的声明语句节点
*/
private void buildStatementFromContext(List<XNode> list) {
if (configuration.getDatabaseId() != null) {
// 解析专属于当前数据库类型的Statement
buildStatementFromContext(list, configuration.getDatabaseId());
}
// 解析未指定数据库类型的Statement
buildStatementFromContext(list, null);
}
复制代码
在实现上, buildStatementFromContext() 方法本身调用了两次重载方法:
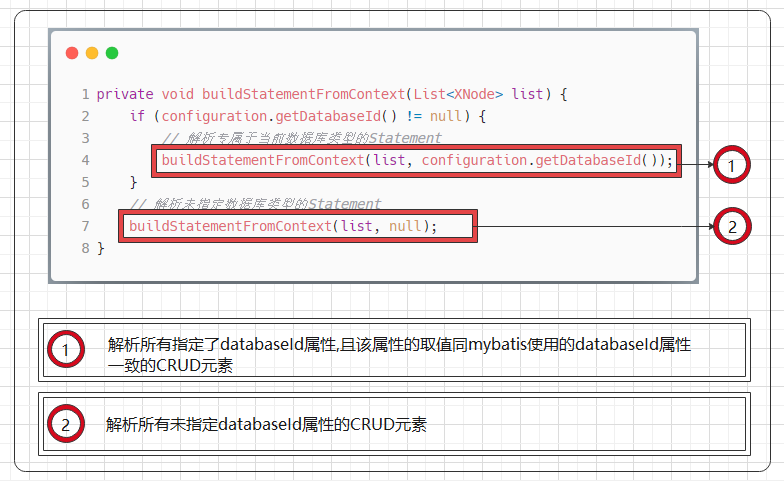
类似 sql 元素的解析,这两次调用相结合, mybatis 就可以完成 跨数据库语句支持 的功能.
重载方法 buildStatementFromContext() 的实现也并不复杂,针对具体的 CRUD 元素,他将解析该元素所需的数据整合在一起,并为其创建一个 XMLStatementBuilder 对象来完成后续的处理操作.
/**
* 构建声明语句
*
* @param list 所有的声明语句
* @param requiredDatabaseId 必须的数据库类型唯一标志
*/
private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {
for (XNode context : list) {
// 解析每一个声明
// 配置Xml声明解析器
final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
try {
// 委托给XMLStatementBuilder完成Statement的解析
statementParser.parseStatementNode();
} catch (IncompleteElementException e) {
// 发生异常,添加到未完成解析的声明语句集合
configuration.addIncompleteStatement(statementParser);
}
}
}
复制代码
这一点和 cache-ref , resultMap 元素的解析工作十分相似, XMLMapperBuilder 对象本身不完成后续的处理操作,而是将后续操作所需的数据整合起来创建一个新的对象去完成后续操作.
这是因为 cache-ref , resultMap 以及 CRUD 元素都是可以进行跨 Mapper 引用的,因此也就会产生在解析时被引用者尚未解析的场景,这时候,就需要缓存起来本次处理的所有数据,待被引用者完成解析操作之后,再重新尝试解析.
XMLStatementBuilder 对象也是 BaseBuilder 对象的实现类,从定义上来看,这也就意味着 XMLStatementBuilder 对象具有 mybatis 基础组件的解析构建能力.
但是和前面了解的 BaseBuilder 实现不同的是, XMLStatementBuilder 对象对外提供的解析方法不是 parse() ,而是 parseStatementNode() .
XMLStatementBuilder 对象的实现并不复杂, buildStatementFromContext() 方法创建该对象时,通过该对象的构造方法完成了必要属性的赋值工作:
public XMLStatementBuilder(Configuration configuration, MapperBuilderAssistant builderAssistant, XNode context) {
this(configuration, builderAssistant, context, null);
}
public XMLStatementBuilder(Configuration configuration, MapperBuilderAssistant builderAssistant, XNode context, String databaseId) {
super(configuration);
this.builderAssistant = builderAssistant;
this.context = context;
this.requiredDatabaseId = databaseId;
}
复制代码
在被赋值的属性中,唯一值得一提的是 context 属性,该属性维护了当前需要解析的 CURD 元素.
/**
* Statement节点
*/
private final XNode context;
复制代码
parseStatementNode() 方法的实现涉及到的知识点就相对要多一些,除了常规的属性获取工作之外,在解析过程中,我们还将接触到语言解释器 LanguageDriver ,以及主键生成器 KeyGenerator 等对象.
为了更好的连贯的去学习 CURD 元素的解析,我们先去探究一下 LanguageDriver 和 KeyGenerator 然后再回来继续后面的解析工作.
什么叫语言解释器
在介绍 mybatis 全局配置解析工作的时候,我们稍微提及了一下脚本语言解释器:
参考文章: Mybatis源码之美:2.11.通过settings配置初始化全局配置
那时候我将 LanguageDriver 称为 脚本语言处理器 ,后来发现 语言解释器 更形象一些,事实上,二者是一个意思.
同时,因为想更细致的探究 myabtis 源码的解析处理工作,所以决定提前学习语言解释器相关的内容.
LanguageDriver 作为语言解释器,他的职能是将用户配置的数据转换成 mybatis 可理解和使用的对象.
LanguageDriver 定义了两 类 方法,一类方法用于解析用户配置,获取 SqlSource 对象 ,一类用于在运行时为 CRUD 方法入参创建 ParameterHandler 对象.
-
SqlSource维护了用户配置的原始SQL信息,他提供了一个getBoundSql()方法来获取BoundSql对象,BoundSql对象的getSql()方法可以获取真正用于执行的SQL数据. -
ParameterHandler对象负责将用户调用CRUD方法时传入的参数转换成合适的类型用于SQL语句的执行.
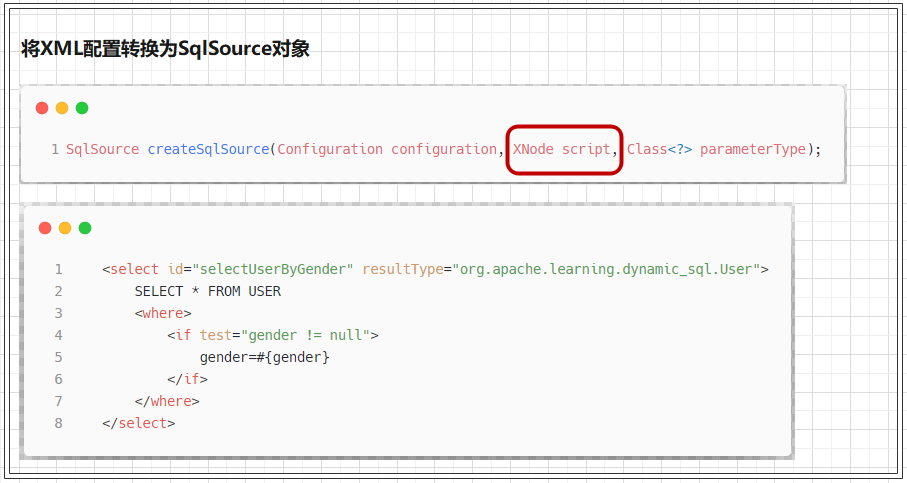
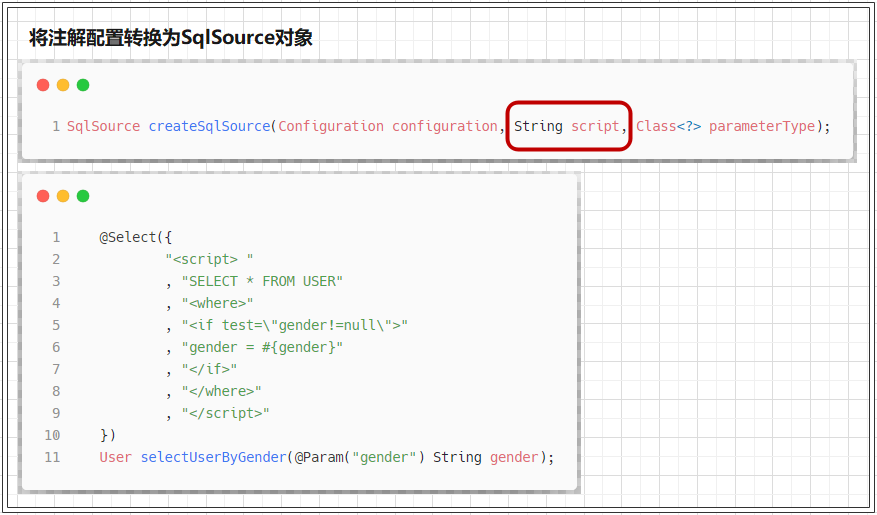
LanguageDriver 定义中用于获取 SqlSource 对象的 createSqlSource() 方法有两种重载形式,一种用于解析处理通过 XML 文件配置的 SQL 信息,一种用于解析处理通过注解配置的 SQL 信息.
// 处理XML配置 SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType); // 处理注解配置 SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType); 复制代码
用于创建 ParameterHandler 对象的方法只有一种定义:
// 创建ParameterHandler对象实例 ParameterHandler createParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql); 复制代码
createParameterHandler() 方法的入参 MappedStatement 对象是我们完成 CRUD 元素解析工作之后得到的最终对象,每个 CRUD 元素配置都会有一个与之相对应的 MappedStatement 对象, BoundSql 则是通过上面两个方法创建的 SqlSource 对象间接生成的,最后一个 Object 类型的 parameterObject 参数,则是我们在调用 CRUD 方法是传入的方法入参.
LanguageDriver 的 createParameterHandler() 方法我们在后面的文章中再深入了解,本篇主要深入探究 createSqlSource() 方法的实现.
mybatis 为 LanguageDriver 提供两种实现: RawLanguageDriver 和 XMLLanguageDriver .
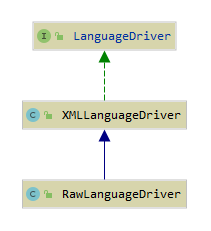
其中 XMLLanguageDriver 是 LanguageDriver 默认的,也是最主要的实现类.
在探究 XMLLanguageDriver 对象的实现之前,我们需要简单了解一下如何使用注解配置 SQL .
和使用 XML 文件配置 CRUD 语句相似, mybatis 提供了四个注解: Select , Insert , Update 以及 Delete ,这四个注解的效果和用法基本等同于 XML 配置中的同名元素.
针对于普通的 SQL 语句定义,二者的用法基本一致:
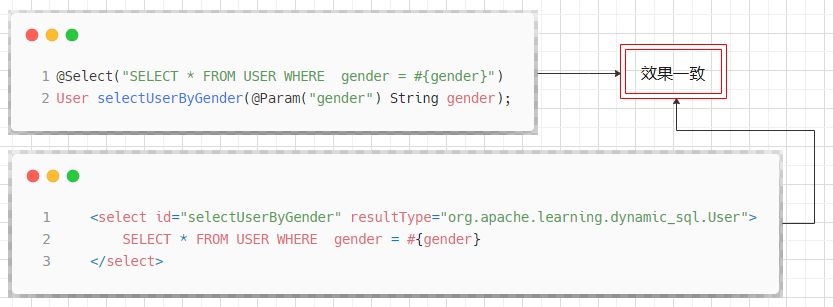
如果我们需要在 SQL 定义中包含动态 SQL ,只需要将 SQL 配置包含在 script 标签内即可:

LanguageDriver 中定义的两个 createSqlSource() 重载方法就分别用于处理上面这两种配置.
SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType); SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType); 复制代码
- 将
XML配置转换为SqlSource对象
- 将注解配置转换为
SqlSource对象
XMLLanguageDriver 对象对这两个方法的实现并不算复杂,负责处理 XML 配置的 createSqlSource() 方法把具体的实现基本都委托给了 XMLScriptBuilder 对象:
public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
// 动态元素解析器
XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
// 构架SQL源
return builder.parseScriptNode();
}
复制代码
XMLScriptBuilder 用于解析用户的 CRUD 配置,并创建相应的 SqlSource 对象,关于 XMLScriptBuilder 的实现细节,我们待会再展开.
负责处理 注解 配置的 createSqlSource() 方法的实现有两个分支,一种是处理包含 动态SQL元素 的配置,一种是普通的 SQL 配置.
public SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType) {
// issue #3
// 处理包含动态SQL元素的配置
if (script.startsWith("<script>")) {
XPathParser parser = new XPathParser(script, false, configuration.getVariables(), new XMLMapperEntityResolver());
return createSqlSource(configuration, parser.evalNode("/script"), parameterType);
} else {
// 常规SQL配置
// issue #127
script = PropertyParser.parse(script, configuration.getVariables());
TextSqlNode textSqlNode = new TextSqlNode(script);
if (textSqlNode.isDynamic()) {
return new DynamicSqlSource(configuration, textSqlNode);
} else {
return new RawSqlSource(configuration, script, parameterType);
}
}
}
复制代码
在实现上,处理 包含动态SQL元素配置 的操作是交给其重载方法完成的:
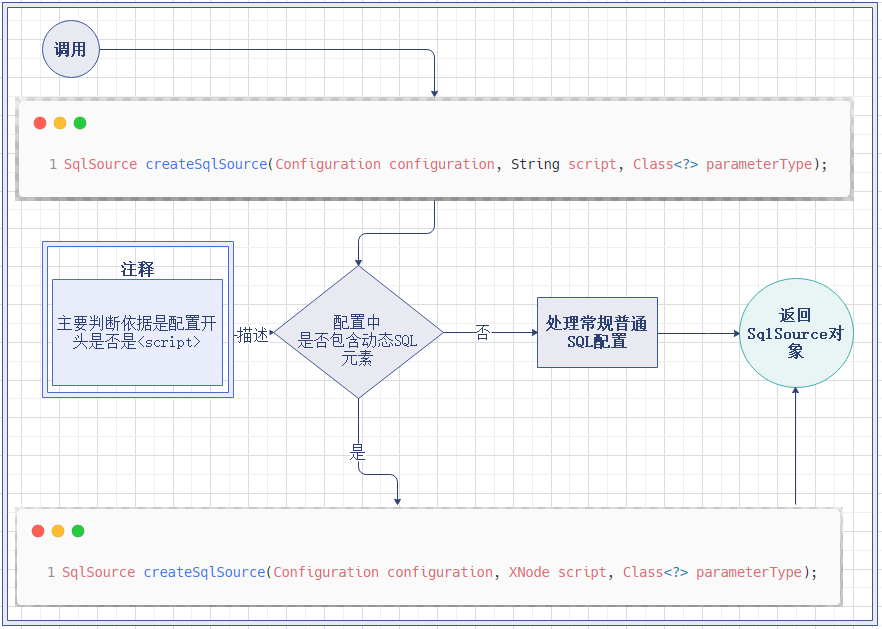
处理 常规SQL配置 的操作, XMLLanguageDriver 对象则亲力亲为:
处理 常规SQL配置 的流程不算复杂,首先借助于 PropertyParser 对象的 parse() 方法利用 mybatis 现有的 参数配置 替换掉用户配置的 CRUD 元素中包含的 ${} 占位符.
然后利用处理后的文本内容创建一个 TextSqlNode 对象实例,并根据 TextSqlNode 对象中是否包含尚未处理的 ${} 占位符来决定创建何种 SqlSource 对象实例.
script = PropertyParser.parse(script, configuration.getVariables());
TextSqlNode textSqlNode = new TextSqlNode(script);
if (textSqlNode.isDynamic()) {
return new DynamicSqlSource(configuration, textSqlNode);
} else {
return new RawSqlSource(configuration, script, parameterType);
}
复制代码
很多人可能会对这一句话有些许疑问,为什么我们前面已经替换过了 ${} 占位符,这里还要再次判断 处理后的内容 中是否包含 ${} 占位符呢?
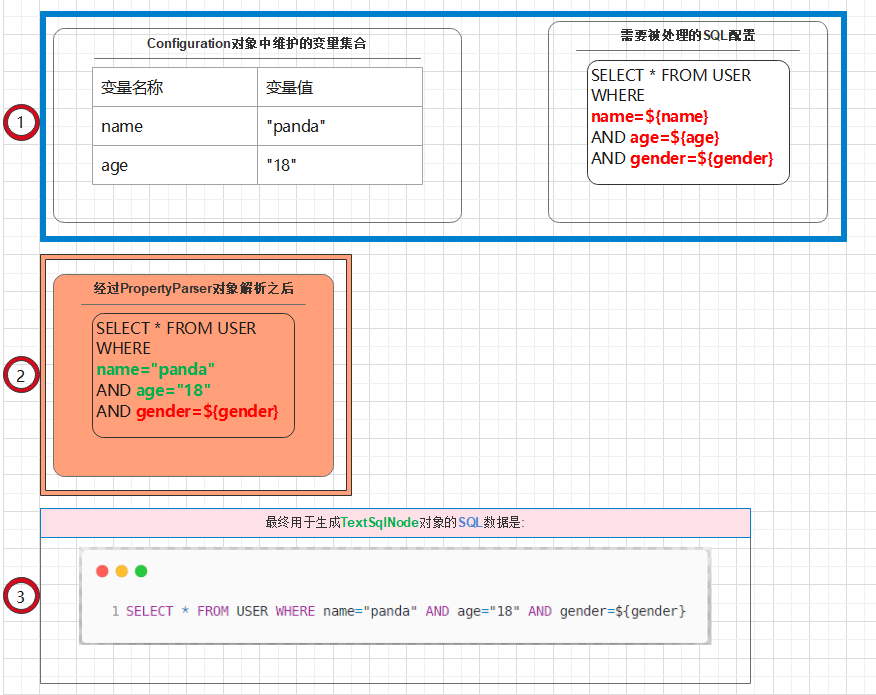
仔细看上面的图示,在经过第一次解析之后,最终用于生成 TextSqlNode 对象的 SQL 语句中依然包含 ${gender} 占位符.
负责解析占位符的 PropertyParser 对象的 parse() 方法有两个入参,其中类型为 String 的参数 string 是可能包含占位符的文本内容,类型为 Properties 的 variables 属性则负责提供用于替换占位符的参数配置.
public static String parse(String string, Properties variables) 复制代码
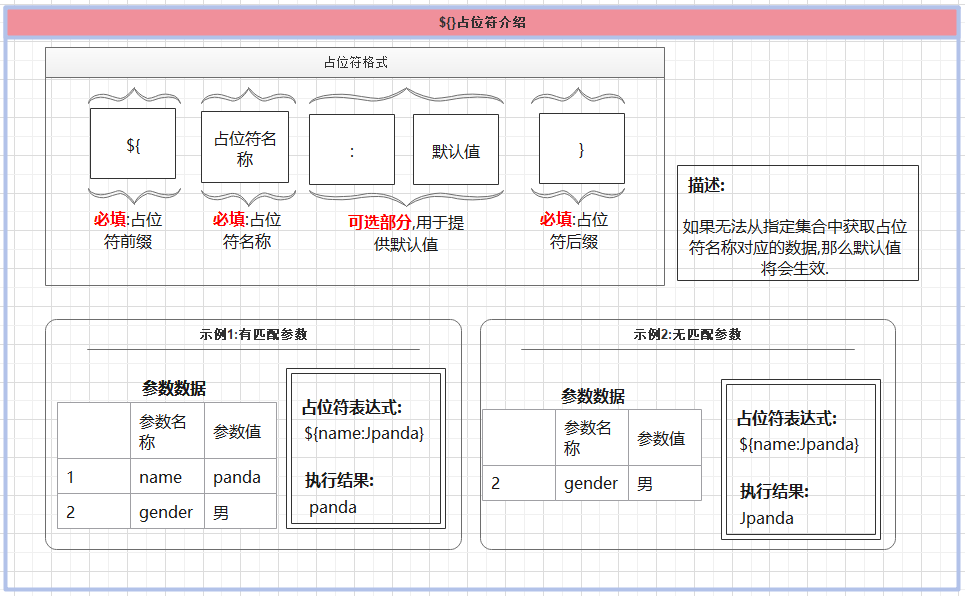
mybatis 提供的单元测试 PropertyParserTest 中包含了 PropertyParser 的应用场景.
mybatis 中关于占位符 ${} 的用法比较简单,具体的使用可以参考 [官方文档:参数:字符串]替换部分
后面将会单开一篇文章详细介绍 PropertyParser 对象的实现.
在对 createSqlSource() 方法有了整体认知之后,我们先深入了解 TextSqlNode ,再回头去了解 XMLScriptBuilder 对象的实现.
SqlNode
TextSqlNode 是 SqlNode 接口的实现类, SqlNode 实现类的作用是维护用户配置的 SQL 数据.
SqlNode 的接口定义应用了常见的设计模式中的组合模式.
组合模式的定义:将对象组合成树形结构以表示" 部分-整体 "的层次结构,组合模式使得用户对单个对象和组合对象的使用具有一致性.
组合模式的作用: 组合模式弱化了简单元素和复杂元素的概念,客户端可以像处理简单元素一样来处理复杂元素.
SqlNode 接口只对外暴露了一个 apply() 方法,该方法的作用是根据 运行上下文 筛选出有效的 SQL 配置.
boolean apply(DynamicContext context); 复制代码
这里的 运行上下文 指的是 DynamicContext 对象,该对象有一个重要的属性定义:
/**
* 当前绑定的上下文参数集合
*/
private final ContextMap bindings;
复制代码
ContextMap 类型的 bindings 属性用于缓存解析指定 SQL 时所需的上下文数据.
ContextMap 是 HashMap 的实现,他通过重写 HashMap 的 get() 方法实现了对 点式分隔形式的复杂属性导航 的支持:
/**
* 对象元数据
*/
private MetaObject parameterMetaObject;
public ContextMap(MetaObject parameterMetaObject) {
this.parameterMetaObject = parameterMetaObject;
}
@Override
public Object get(Object key) {
// 从当前集合中获取指定的key对应的值
String strKey = (String) key;
if (super.containsKey(strKey)) {
return super.get(strKey);
}
// 如果没有,则从参数对象元数据中获取
if (parameterMetaObject != null) {
// issue #61 do not modify the context when reading
return parameterMetaObject.getValue(strKey);
}
return null;
}
复制代码
实现原理比较简单,优先从 Map 本身取值,之后再借助于 MetaObject 来完成属性的取值.
关于 MetaObject 的内容,可以参考文章 Mybatis源码之美:2.9.解析ObjectWrapperFactory元素,解析并配置对象包装工厂 中的相关内容.
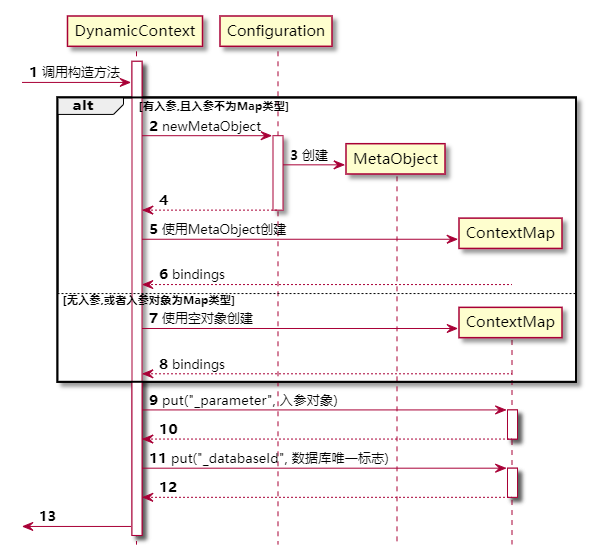
DynamicContext 对象的创建需要两个参数,一个是 mybatis 的全局配置对象 Configuration ,另一个是用户调用 CRUD 方法时传入的方法入参.
在 DynamicContext 对象的构造方法中,首先会根据用户的方法入参创建相应的 ContextMap 对象,之后将 方法入参 和 数据唯一标志 存放进 ContextMap 对象中.
public DynamicContext(Configuration configuration, Object parameterObject) {
if (parameterObject != null && !(parameterObject instanceof Map)) {
// 获取对象元数据
MetaObject metaObject = configuration.newMetaObject(parameterObject);
// 保存当前对象的元数据
bindings = new ContextMap(metaObject);
} else {
bindings = new ContextMap(null);
}
/*
* 保存参数集合
*/
bindings.put(PARAMETER_OBJECT_KEY, parameterObject);
// 保存数据库唯一标志
bindings.put(DATABASE_ID_KEY, configuration.getDatabaseId());
}
复制代码
public static final String PARAMETER_OBJECT_KEY = "_parameter"; public static final String DATABASE_ID_KEY = "_databaseId"; 复制代码
构造方法的执行过程大致如下:
@startuml
autonumber
hide footbox
participant DynamicContext as dc
participant Configuration as c
activate dc
[-> dc: 调用构造方法
alt 有入参,且入参不为Map类型
dc -> c ++ : newMetaObject
c -> MetaObject ** : 创建
return
dc -> ContextMap ** :使用MetaObject创建
return bindings
else 无入参,或者入参对象为Map类型
dc -> ContextMap ** :使用空对象创建
return bindings
end
dc -> ContextMap ++: put("_parameter", 入参对象)
return
dc -> ContextMap ++: put("_databaseId", 数据库唯一标志)
return
[<- dc
@enduml
复制代码
为了更好的理解 DynamicContext 对象在构造过程中如何处理的数据,我们做一个简单的小测试:
@Slf4j
class DynamicContextTest {
@Test
public void createDynamicContextTest() {
Configuration configuration = new Configuration();
configuration.setDatabaseId("数据库标志");
User user = new User("panda", 18, "男");
DynamicContext dynamicContext = new DynamicContext(configuration, user);
Map<String, Object> binds = dynamicContext.getBindings();
log.debug("最终数据为:{}", binds.toString());
log.debug("获取用户名称:{}", binds.get("name"));
}
@Data
@AllArgsConstructor
public static class User {
private String name;
private Integer age;
private String gender;
}
}
复制代码
上面的代码输入下列日志:
DEBUG [main] - 最终数据为:{_parameter=DynamicContextTest.User(name=panda, age=18, gender=男), _databaseId=数据库标志}
DEBUG [main] - 获取用户名称:panda
复制代码
实际数据在代码中的变化如下图:
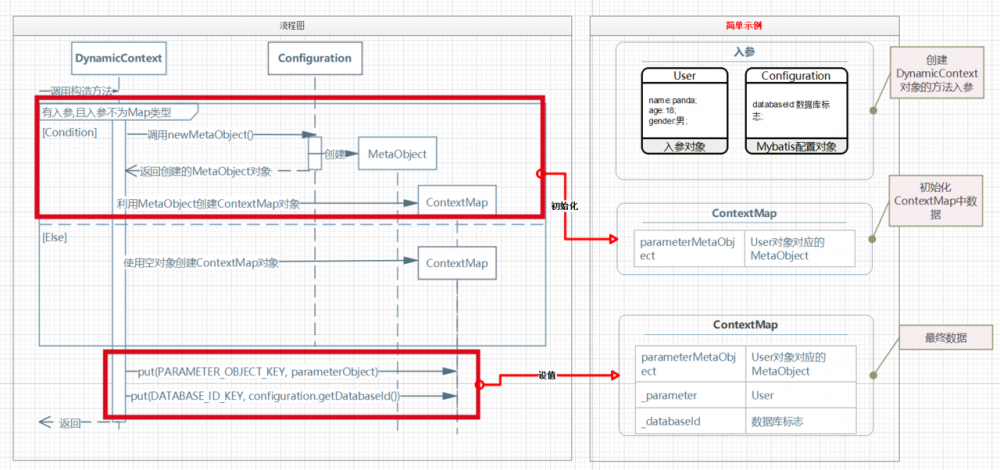
输出的日志内容不包含 parameterMetaObject 内容,是因为 AbstractMap 对象的 toString() 方法只输出其维护的 键值对 数据.
在 DynamicContext 对象中还有一个静态方法:
static {
OgnlRuntime.setPropertyAccessor(ContextMap.class, new ContextAccessor());
}
复制代码
这意味着在 DynamicContext 对象被加载时,将会为 OGNL 注册一个属性访问器,有关于 OGNL 的相关知识,不在本篇文章的考虑之内,因此这里就不展开了.
mybatis 为 SqlNode 提供了 10 个实现类,这些实现类大部分和 myabtis 的 动态SQL元素 一一对应,只有极少数的三个实现具有特殊的意义.
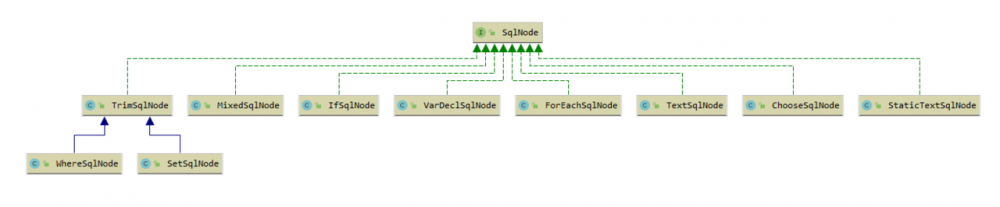
这三个具有特殊意义的实现分别是: TextSqlNode , StaticTextSqlNode 和 MixedSqlNode .
单纯的,生硬的去介绍,大家可能有些迷惑,不能很好的了解 SqlNode 实现类的区别,但是不用担心,我们接下来就深入的探究不同 SqlNode 的区别以及协作流程.
回顾 XMLLanguageDriver 对象中关于 处理注解中常规SQL配置 的代码( createSqlSource() 方法):
script = PropertyParser.parse(script, configuration.getVariables());
TextSqlNode textSqlNode = new TextSqlNode(script);
if (textSqlNode.isDynamic()) {
return new DynamicSqlSource(configuration, textSqlNode);
} else {
return new RawSqlSource(configuration, script, parameterType);
}
复制代码
mybatis 在拿到用户通过注解提供的的 SQL 配置之后,将其封装成了 TextSqlNode 对象,并根据 TextSqlNode 对象的 isDynamic() 方法的返回值来决定创建何种类型的 SqlSource 对象.
TextSqlNode 对象是对含有占位符 ${} 的 SQL 配置的包装,他所修饰的 SQL 配置中 可能 含有使用 ${} 修饰的占位符.
对含有 ${} 占位符的 Sql 配置我称其为 动态SQL ,对不含有 ${} 占位符的配置我称之为 静态SQL .
TextSqlNode 有两个属性定义,一个是 String 类型的 text 属性,该属性用于缓存 SQL配置 ,另一个是 Pattern 类型的 injectionFilter 属性,该属性负责维护一个正则表达式,主要作用是防止 SQL 注入.
/**
* 内容
*/
private final String text;
/**
* 条件正则表达式,主要用于防注入
*/
private final Pattern injectionFilter;
复制代码
TextSqlNode 额外对外暴露了一个 isDynamic() 方法,该方法的作用是判断当前 text 属性中是否包含 ${} 占位符:
public boolean isDynamic() {
/*
* 动态节点检查解析器
*/
DynamicCheckerTokenParser checker = new DynamicCheckerTokenParser();
// 解析${}
GenericTokenParser parser = createParser(checker);
// 解析文本
parser.parse(text);
// 只要包含占位符就是动态标签
return checker.isDynamic();
}
复制代码
该方法的实现借助了 DynamicCheckerTokenParser 和 GenericTokenParser 两个实现类,在这里 GenericTokenParser 的主要作用是解析出指定文本中被 ${} 修饰的占位符内容,并将该占位符的内容交给 DynamicCheckerTokenParser 的 handleToken() 来处理.
DynamicCheckerTokenParser 是 TokenHandler 接口定义的实现,他的 handlerToken() 方法的实现比较简单,只需更新负责记录是否有 ${} 占位符的 isDynamic 标记即可:
/**
* 动态节点检查解析器
*/
private static class DynamicCheckerTokenParser implements TokenHandler {
private boolean isDynamic;
public DynamicCheckerTokenParser() {
// Prevent Synthetic Access
}
public boolean isDynamic() {
return isDynamic;
}
@Override
public String handleToken(String content) {
this.isDynamic = true;
return null;
}
}
复制代码
TextSqlNode 对象的 isDynamic() 方法最终返回的也是 DynamicCheckerTokenParser 对象的 isDynamic 标记.
GenericTokenParser 对象与 TokenHandler 接口定义相关的内容我们会和 PropertyParser 对象一起探究.
TextSqlNode 对象还有一个用于获取 SQL 数据的 apply() 方法,该方法的实现也很简单:
@Override
public boolean apply(DynamicContext context) {
GenericTokenParser parser = createParser(new BindingTokenParser(context, injectionFilter));
context.appendSql(parser.parse(text));
return true;
}
复制代码
在借由 GenericTokenParser 对象获取到需要处理的占位符数据之后,后续的操作交给了 BindingTokenParser 对象来完成.
BindingTokenParser 是 TextSqlNode 的内部类,他只有两个通过构造方法初始化的属性:
/**
* 方法运行上下文
*/
private DynamicContext context;
/**
* 防止SQL注入的表达式
*/
private Pattern injectionFilter;
public BindingTokenParser(DynamicContext context, Pattern injectionFilter) {
this.context = context;
this.injectionFilter = injectionFilter;
}
复制代码
他的 handlerToken() 方法负责以 DynamicContext 中 维护的参数集合 作为 基础数据 来解析 占位符所描述的参数 对应的值.
public String handleToken(String content) {
Object parameter = context.getBindings().get("_parameter");
if (parameter == null) {
context.getBindings().put("value", null);
} else if (SimpleTypeRegistry.isSimpleType(parameter.getClass())) {
context.getBindings().put("value", parameter);
}
Object value = OgnlCache.getValue(content, context.getBindings());
String srtValue = value == null ? "" : String.valueOf(value); // issue #274 return "" instead of "null"
// 检测注入
checkInjection(srtValue);
return srtValue;
}
复制代码
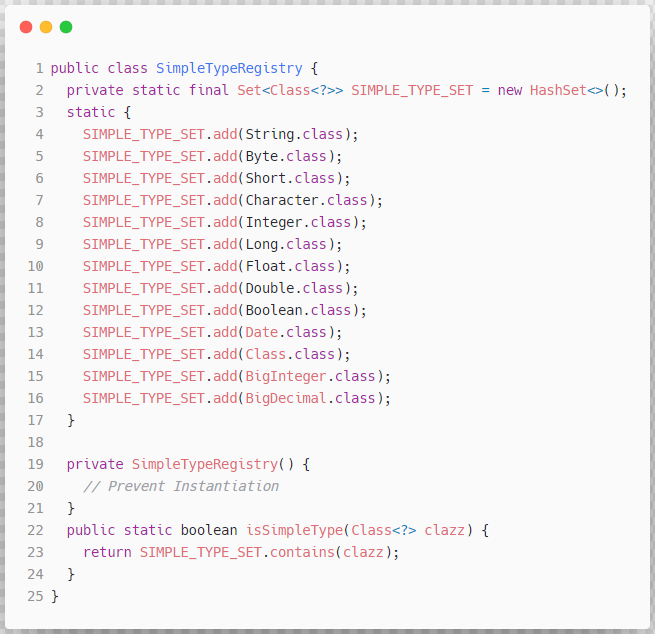
在实现上,该方法 可能 会为 DynamicContext 对象持有的 ContextMap 额外添加一个名为 value 的特殊值,该属性值的添加条件是 入参对象 为空,或者 入参对象 为 理论上不可拆分的简单类型 .
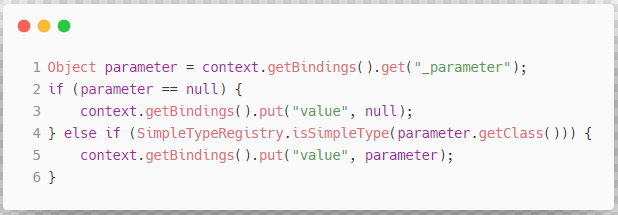
之后,使用 ContextMap 维护的参数集合来解析占位符中的 OGNL 表达式对应的值,并通过 checkInjection() 方法完成 防SQl注入 的校验工作:
private void checkInjection(String value) {
if (injectionFilter != null && !injectionFilter.matcher(value).matches()) {
throw new ScriptingException("Invalid input. Please conform to regex" + injectionFilter.pattern());
}
}
复制代码
有关 OgnlCache 相关的内容,这里不展开,如果条件允许的话,后面会单开一篇文章探究 OgnlCache 的实现.
上面就是 TextSqlNode 对象的实现了,总体来说,并不算复杂,回到 XMLLanguageDriver 的 createSqlSource() 方法中,如果创建的 TextSqlNode 对象包含 ${} 占位符, mybatis 就会将其包装成 DynamicSqlSource 对象,否则就包装成 RawSqlSource 对象.
DynamicSqlSource 和 RawSqlSource 都是 SqlSource 接口的实现类, DynamicSqlSource 负责维护包含 ${} 占位符的 SqlNode ,我称之为 动态SQL源 , RawSqlSource 负责维护不含 ${} 占位符的 SqlNode ,我称之为 静态SQL源 .
单纯的从名称上来看也不难发现,在获取 SQL 时, DynamicSqlSource 将会比 RawSqlSource 多做一次 ${} 占位符的解析工作.
到这里,我们算是大致了解了负责处理 由注解提供的常规SQL配置 的 createSqlSource() 方法的实现,虽然有很多细节我们还没有去特别深入的了解,但是不要紧,现在我们先回过头来看 XMLScriptBuilder 对象的实现.
XMLScriptBuilder 对象也是 BaseBuilder 的子类,他对外暴露的解析方法名为 parseScriptNode() .
XMLScriptBuilder 的构造方法需要三个参数,这三个参数分别是 mybatis 的 Configuration 对象,维护具体 SQL 配置的 XNode 对象,以及预期的方法入参的类型:
public XMLScriptBuilder(Configuration configuration, XNode context, Class<?> parameterType) {
super(configuration);
this.context = context;
this.parameterType = parameterType;
initNodeHandlerMap();
}
复制代码
在构造方法中,除了简单的属性赋值操作之外, XMLScriptBuilder 还执行了一个 initNodeHandlerMap() 方法,这个方法的作用是初始化 待解析动态SQL元素 与 负责解析该元素的处理器 之间的关系.
private void initNodeHandlerMap() {
// 注册(动态元素)子节点的解析器
nodeHandlerMap.put("trim", new TrimHandler());
nodeHandlerMap.put("where", new WhereHandler());
nodeHandlerMap.put("set", new SetHandler());
nodeHandlerMap.put("foreach", new ForEachHandler());
nodeHandlerMap.put("if", new IfHandler());
nodeHandlerMap.put("choose", new ChooseHandler());
nodeHandlerMap.put("when", new IfHandler());
nodeHandlerMap.put("otherwise", new OtherwiseHandler());
nodeHandlerMap.put("bind", new BindHandler());
}
复制代码
几乎与 动态SQL元素 的名称一一相对应, mybatis 为 NodeHandler 接口提供了 8 种实现:

NodeHandler 接口的设计目的是为指定的 动态SQL元素 创建与其相对应的 SqlNode 对象.
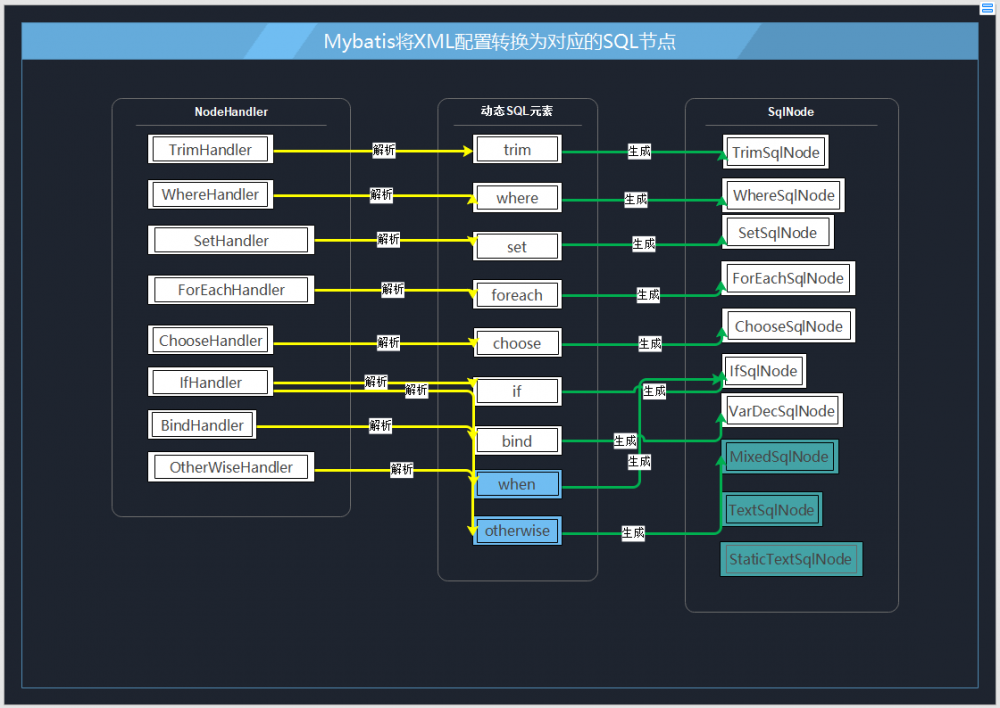
如果仔细看上图的话,我们可以发现 trim , where , set , foreach , choose , if 这 6 个元素都由同名的 NodeHandler 实现将其转换为同名的 SqlNode 对象, bind 元素则由同名的 BindHandler 将其转换为 VarDesSqlNode 对象.
至于多出来的 choose 元素的两个子元素: when 和 otherwise ,鉴于 when 的逻辑和 if 元素一致,因此 when 元素会被 IfHandler 转换为 IfSqlNode .
otherwise 则由 OtherWiseHandler 将其转换为 MixedSqlNode .
在上图中,还对三个特殊的 SqlNode 实现做了标记.
其中 TextSqlNode 是对含有占位符 ${} 的 SQL 配置的包装,它所对应的 SQL 配置中可能含有 ${} 占位符数据,比如: SELECT * FROM USER WHERE NAME=${name} .
StaticTextSqlNode 是最基本的 SQL 配置的封装对象,它封装的 SQL 配置可能包含 #{} 占位符,但是绝不可能包含 ${} 占位符.
MixedSqlNode 本身不维护 SQL 配置,但是他持有一组用于维护 SQL 配置的 SqlNode 集合,他获取所需 SQL 的操作,实际是拼接 SqlNode 集合中所有有效的 SQL 数据得来的.
听不大懂不要紧,我们马上就会一一了解这些实现.
还是 XMLLanguageDriver 的 createSqlSource() 方法,在创建了 XMLScriptBuilder 实例之后,就会调用其 parseScriptNode() 方法来获取 SqlSource 对象了:
public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
// 动态元素解析器
XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
// 构架SQL源
return builder.parseScriptNode();
}
复制代码
XMLScriptBuilder 的 parseScriptNode() 方法的实现有些像前面讲的 解析注解配置的常规SQL 的实现,先根据 用户配置 生成 SqlNode 对象,之后根据 SqlNode 对象是否是 动态SqlNode 来创建相应的 DynamicSqlSource 或者 RawSqlSource .
public SqlSource parseScriptNode() {
// 解析动态标签
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource = null;
if (isDynamic) {
// 配置动态SQL源
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
// 配置静态SQL源
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}
复制代码
唯一的不同就在于这里创建的 SqlNode 对象是 MixedSqlNode ,而不是 TextSqlNode .
前面说了 MixedSqlNode 本身并不直接维护 SQL 配置,而是通过维护一组 SqlNode 集合来间接管理 SQL 配置.
他的实现格外简单,创建 MixedSqlNode 实例时,需要为其构造方法传入所维护的 SqlNode 集合,这样在调用其 apply() 方法时, MixedSqlNode 将会依次调用其维护的每个 SqlNode 对象的 apply() 方法来得到最终的 SQL 数据.
public class MixedSqlNode implements SqlNode {
/**
* 包含的Sql节点集合
*/
private final List<SqlNode> contents;
public MixedSqlNode(List<SqlNode> contents) {
this.contents = contents;
}
@Override
public boolean apply(DynamicContext context) {
for (SqlNode sqlNode : contents) {
sqlNode.apply(context);
}
return true;
}
}
复制代码
负责创建 MixedSqlNode 对象的 parseDynamicTags() 方法从逻辑上来看,可以分为两类,一类负责处理 动态SQL元素 ,一类是负责处理 普通文本配置的SQL .
下面是一个简单的 select 语句的 SQL 配置:
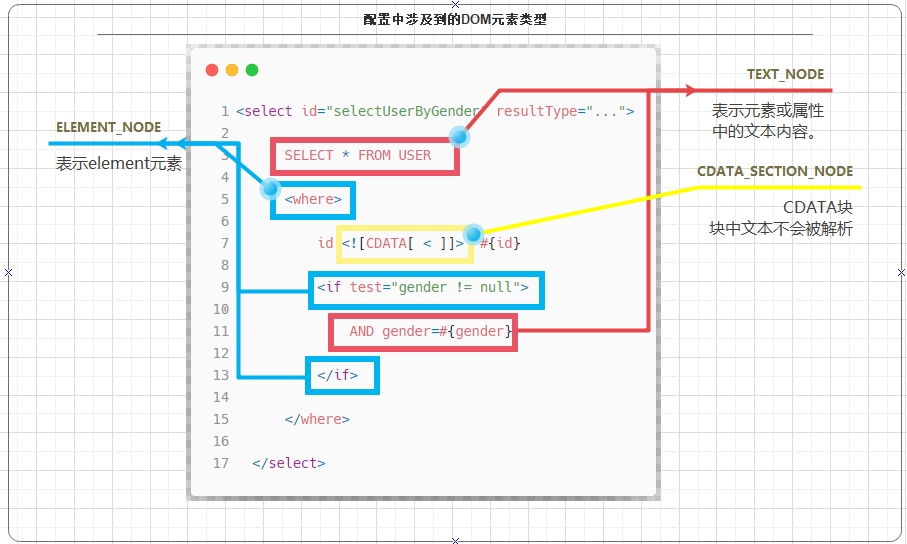
通过上图可以看到,一个简单的 CRUD 配置会涉及到三种不同类型的元素: ELEMENT_NODE , TEXT_NODE 以及 CDATA .
其中,针对 TEXT_NODE 和 CDATA 块中包裹的数据,解析器不需要额外的处理,保持数据原样即可, ELEMENT_NODE 元素的配置则需要进一步的解析才能使用.
负责解析用户配置的 parseDynamicTags() 方法,遵循的就是这个道理,针对每一个用户配置,如果子元素的类型是 TEXT_NODE 或者 CDATA 块, parseDynamicTags() 方法会将其转换成 TextSqlNode 对象,如果通过 TextSqlNode 对象的 isDynamic() 方法判断用户配置的 SQL 不是动态 SQL (即:不包含 ${} 占位符),那么 parseDynamicTags() 方法会使用用户配置的 SQL 重新生成 StaticTextSqlNode 对象来取代 TextSqlNode 对象.
如果子元素的类型是 ELEMENT_NODE , parseDynamicTags() 方法就会为该元素寻找相应的 NodeHandler 来处理该元素配置.
protected MixedSqlNode parseDynamicTags(XNode node) {
// 用于维护最终所有的SQL节点对象
List<SqlNode> contents = new ArrayList<>();
// 获取内部的所有子节点,其实就是七种动态标签。
NodeList children = node.getNode().getChildNodes();
// 循环处理每一个动态标签
for (int i = 0; i < children.getLength(); i++) {
// 生成一个新的XNode对象
XNode child = node.newXNode(children.item(i));
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE /*子节点一定为TextNode*/
|| child.getNode().getNodeType() == Node.TEXT_NODE /*<![CDATA[]]>中括着的纯文本,它没有子节点*/
) {
// 获取子节点中的文本内容
String data = child.getStringBody("");
// 使用文本内容生成一个文件Sql节点
TextSqlNode textSqlNode = new TextSqlNode(data);
// 只要文本中包含了${},就是动态节点
if (textSqlNode.isDynamic()) {
// 添加动态SQL节点
contents.add(textSqlNode);
isDynamic = true;
} else {
// 添加静态SQl节点
contents.add(new StaticTextSqlNode(data));
}
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE/*DTD实体定义,无子节点*/
) {
// 进入该方法,则表示该子节点是动态节点
// issue #628
// 获取动态节点的名称
String nodeName = child.getNode().getNodeName();
/*获取动态节点处理器*/
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
/*委托给动态节点处理器来处理动态节点*/
handler.handleNode(child, contents);
/*重置动态节点标志*/
isDynamic = true;
}
}
/*返回一个混合SQL节点对象*/
return new MixedSqlNode(contents);
}
复制代码
认真看上述方法实现, parseDynamicTags() 方法会遍历用户配置的 CRUD 语句中的每一个子元素,并为每个子元素合理的创建相应的 SqlNode 对象,并将得到的 SqlNode 对象放入有序集合 contents 中,最后利用有序集合作为构造参数,创建一个 MixedSqlNode 对象返回给调用方, 这就证明无论用户配置如何,通过 XML 进行的 CRUD 配置最终一定会被转换成 MixedSqlNode 对象来使用.
关于 MixedSqlNode 的实现我们前面已经做了了解,现在让我们看一下负责维护 静态SQL配置 (即:配置中不包含 ${} 占位符)的 StaticTextSqlNode 的实现.
StaticTextSqlNode 的实现更为简单,他只有一个 String 的 text 属性用来维护对应的 SQL 配置,当用户调用他的 apply() 方法时,他就简单的将该 SQL 追加到 DynamicContext 中即可.
public class StaticTextSqlNode implements SqlNode {
private final String text;
public StaticTextSqlNode(String text) {
this.text = text;
}
@Override
public boolean apply(DynamicContext context) {
context.appendSql(text);
return true;
}
}
复制代码
DynamicContext 对象本身维护了一个 StringBuilder 类型的 sqlBuilder 参数:
/**
* 维护最终生成的SQL数据
*/
private final StringBuilder sqlBuilder = new StringBuilder();
复制代码
并为该参数暴露了一个 appendSql() 方法用来往 sqlBuilder 中追加 SQL 内容:
public void appendSql(String sql) {
sqlBuilder.append(sql);
sqlBuilder.append(" ");
}
复制代码
以及一个 getSql() 方法用来获取当前维护的 SQL 内容:
public String getSql() {
return sqlBuilder.toString().trim();
}
复制代码
我们继续回到 parseDynamicTags() 方法的实现上来,针对用户 CURD 配置中的元素配置( ELEMENT_NODE ), parseDynamicTags() 方法会根据元素的名称从 nodeHandlerMap 中获取相应的 NodeHandler ,并利用得到的 NodeHandler 来完成元素的处理操作.
前面我们讲过 nodeHandlerMap 集合的初始化过程是在构造方法中完成的,并提供了一张图来描述不同 NodeHandler 实现类处理的元素,以及最终对应的 SqlNode 对象类型.

NodeHandler 接口只对外暴露了一个 handleNode() 方法,该方法有两个入参,一个是 XNode 类型的 nodeToHandle 参数,该参数表示当前处理的子元素.另一个是 List<SqlNode> 类型的 targetContents 集合参数, targetContents 中有序的存放在当前已解析出的 SQL 配置.
private interface NodeHandler {
void handleNode(XNode nodeToHandle, List<SqlNode> targetContents);
}
复制代码
下面按照上图的顺序,我们来一次了解每一个 NodeHandler 子类的实现.
首先我们看一下 TrimHandler , TrimHandler 是 XMLScriptBuilder 的内部类定义:
private class TrimHandler implements NodeHandler {
public TrimHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
// 包含的子节点在解析后SQL文本不为空时需要添加的前缀内容
String prefix = nodeToHandle.getStringAttribute("prefix");
// 需要覆盖掉的子节点解析后的SQL文本的前缀内容
String prefixOverrides = nodeToHandle.getStringAttribute("prefixOverrides");
// 包含的子节点在解析后SQL文本不为空时需要添加的后缀内容
String suffix = nodeToHandle.getStringAttribute("suffix");
// 需要覆盖掉的子节点解析后的SQL文本的后缀内容
String suffixOverrides = nodeToHandle.getStringAttribute("suffixOverrides");
// 构建trimSQl节点
TrimSqlNode trim = new TrimSqlNode(configuration, mixedSqlNode, prefix, prefixOverrides, suffix, suffixOverrides);
targetContents.add(trim);
}
}
复制代码
根据 trim 元素的 DTD 定义来看, trim 元素下是可以继续嵌套其他动态 SQL 元素配置的:
<!ELEMENT trim (#PCDATA | include | trim | where | set | foreach | choose | if | bind)*> 复制代码
因此在实现上, TrimHandler 会调用 XMLScriptBuilder 方法来 递归 解析子元素配置并获取对应的 MixedSqlNode 对象.
之后依次读取 trim 元素的属性配置:
<!ATTLIST trim prefix CDATA #IMPLIED prefixOverrides CDATA #IMPLIED suffix CDATA #IMPLIED suffixOverrides CDATA #IMPLIED > 复制代码
并利用这些属性创建 TrimSqlNode 对象,将其添加到 targetContents 集合中.
TrimSqlNode 的实现看起来略显复杂,但原理相对比较简单,他现有的六个属性定义,除了 Configuration 对象之外,基本都和 trim 元素的 DTD 定义息息相关:
/**
* Sql节点的内容
*/
private final SqlNode contents;
/**
* 前缀
*/
private final String prefix;
/**
* 后缀
*/
private final String suffix;
/**
* 需要被覆盖的前缀(多个需要被覆盖的前缀之间可以通过|来分割)
*/
private final List<String> prefixesToOverride;
/**
* 需要被覆盖的后缀(多个需要被覆盖的后缀之间可以通过|来分割)
*/
private final List<String> suffixesToOverride;
/**
* Mybatis配置
*/
private final Configuration configuration;
复制代码
这些属性中,比较值得注意的是 prefixesToOverride 和 suffixesToOverride 这两个属性,他们是集合类型的,因为在配置这两个属性时,可以通过 | 作为分隔符来得到多个子字符串.
TrimSqlNode 的对外提供的构造方法中针对 prefixesToOverride 和 suffixesToOverride 这两个属性做了额外的处理:
public TrimSqlNode(Configuration configuration, SqlNode contents, String prefix, String prefixesToOverride, String suffix, String suffixesToOverride) {
this(configuration, contents, prefix, parseOverrides(prefixesToOverride), suffix, parseOverrides(suffixesToOverride));
}
复制代码
其实现就是借助于 parseOverrides() 方法,处理字符串中的 | 分隔符,将这两个属性转换为集合类型,并调用另一个构造方法,完成基本属性的赋值工作:
/**
* 解析要被覆盖的(前缀|后缀),处理 | ,生成替换列表
* @param overrides 声明
*/
private static List<String> parseOverrides(String overrides) {
if (overrides != null) {
final StringTokenizer parser = new StringTokenizer(overrides, "|", false);
final List<String> list = new ArrayList<>(parser.countTokens());
while (parser.hasMoreTokens()) {
list.add(parser.nextToken().toUpperCase(Locale.ENGLISH));
}
return list;
}
return Collections.emptyList();
}
复制代码
受保护的构造方法:
protected TrimSqlNode(Configuration configuration, SqlNode contents, String prefix, List<String> prefixesToOverride, String suffix, List<String> suffixesToOverride) {
this.contents = contents;
this.prefix = prefix;
this.prefixesToOverride = prefixesToOverride;
this.suffix = suffix;
this.suffixesToOverride = suffixesToOverride;
this.configuration = configuration;
}
复制代码
TrimSqlNode 的 apply() 方法在实现上,借助于名为 FilteredDynamicContext 的动态参数对象:
@Override
public boolean apply(DynamicContext context) {
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
boolean result = contents.apply(filteredDynamicContext);
filteredDynamicContext.applyAll();
return result;
}
复制代码
仔细看上面的实现,当完成子元素对应的 SqlNode 对象的 apply() 方法的调用之后, TrimHandler 额外的调用了 FilteredDynamicContext 对象的 applyAll() 方法.
FilteredDynamicContext 是 DynamicContext 的子实现,在创建该对象时需要一个 DynamicContext 对象实例, FilteredDynamicContext 对象的大多数方法实现都会委托给现有的 DynamicContext 实例来完成:
FilteredDynamicContext 对象有四个属性定义:
private DynamicContext delegate;
private boolean prefixApplied;
private boolean suffixApplied;
private StringBuilder sqlBuffer;
public FilteredDynamicContext(DynamicContext delegate) {
super(configuration, null);
this.delegate = delegate;
this.prefixApplied = false;
this.suffixApplied = false;
this.sqlBuffer = new StringBuilder();
}
复制代码
其中 prefixApplied 和 suffixApplied 分别用来记录当前是否已经处理了 前缀/后缀 配置, sqlBuffer 则用来缓存 trim 元素中对应的 SQL 数据.
至于 delegate 则是 FilteredDynamicContext 对象的委托对象.
委托者模式虽然不属于常见的 23 中设计模式,但其也是常用的设计模式之一.
FilteredDynamicContext 对象主要重写了父类的 appendSql() 方法,将得到的 SQL 数据,缓存到自身提供的 sqlBuffer 属性中,以此来实现对 SQL 数据额外处理的能力:
@Override
public void appendSql(String sql) {
sqlBuffer.append(sql);
}
复制代码
FilteredDynamicContext 对象额外对外暴露了 applyAll() 方法,该方法负责处理缓存 SQL 的 前/后缀 ,并最终将处理后的 SQL 数据保存到原始 DynamicContext 委托类中:
public void applyAll() {
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
if (trimmedUppercaseSql.length() > 0) {
applyPrefix(sqlBuffer, trimmedUppercaseSql);
applySuffix(sqlBuffer, trimmedUppercaseSql);
}
delegate.appendSql(sqlBuffer.toString());
}
复制代码
仔细看上面的实现, if 判断语句确保了只有在 存在有效SQL配置 的前提下, 前/后缀 配置才会生效.
负责处理 前/后缀 的两个方法的 applyPrefix() 和 applySuffix() 在实现上比较相似:
private void applyPrefix(StringBuilder sql, String trimmedUppercaseSql) {
if (!prefixApplied) {
prefixApplied = true;
if (prefixesToOverride != null) {
for (String toRemove : prefixesToOverride) {
if (trimmedUppercaseSql.startsWith(toRemove)) {
sql.delete(0, toRemove.trim().length());
break;
}
}
}
if (prefix != null) {
sql.insert(0, " ");
sql.insert(0, prefix);
}
}
}
private void applySuffix(StringBuilder sql, String trimmedUppercaseSql) {
if (!suffixApplied) {
suffixApplied = true;
if (suffixesToOverride != null) {
for (String toRemove : suffixesToOverride) {
if (trimmedUppercaseSql.endsWith(toRemove) || trimmedUppercaseSql.endsWith(toRemove.trim())) {
int start = sql.length() - toRemove.trim().length();
int end = sql.length();
sql.delete(start, end);
break;
}
}
}
if (suffix != null) {
sql.append(" ");
sql.append(suffix);
}
}
}
复制代码
值得注意的就是 prefixApplied 和 suffixApplied 这两个属性,理论上这两个属性定义存在的目的是为了避免因为多次调用 applyAll() 方法,导致多次生成前后缀的问题.
但实际上在目前的代码中,并不会重复调用同一个 FilteredDynamicContext 对象的 applyAll() 方法.
WhereHandler 用于解析 where 元素配置,因为 where 元素也可以嵌套配置 动态SQL元素 :
<!ELEMENT where (#PCDATA | include | trim | where | set | foreach | choose | if | bind)*> 复制代码
因此在实现上, WhereHandler 也会调用 XMLScriptBuilder 方法来 递归 解析子元素配置并获取对应的 MixedSqlNode 对象.
private class WhereHandler implements NodeHandler {
public WhereHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
WhereSqlNode where = new WhereSqlNode(configuration, mixedSqlNode);
targetContents.add(where);
}
}
复制代码
WhereSqlNode 是 TrimSqlNode 的子类,他的实现基本依托于 TrimSqlNode ,在他的构造方法中,为 TrimSqlNode 指定了 prefix 属性为 where 字符串,并且指定了需要移除的字符串前缀是: "AND ", "OR ", "AND/n", "OR/n", "AND/r", "OR/r", "AND/t", "OR/t" .
和 WhereHandler 类似, SetHandler 用于将 set 元素处理成 SetSqlNode ;
<!ELEMENT set (#PCDATA | include | trim | where | set | foreach | choose | if | bind)*> 复制代码
/**
* set标签主要用于解决动态更新字段
*/
private class SetHandler implements NodeHandler {
public SetHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
SetSqlNode set = new SetSqlNode(configuration, mixedSqlNode);
targetContents.add(set);
}
}
复制代码
SetSqlNode 也是 TrimSqlNode 的实现类,他指定了 TrimSqlNode 需要添加的前缀为 SET ,并指定了需要移除的 前/后缀 为 , :
public class SetSqlNode extends TrimSqlNode {
private static final List<String> COMMA = Collections.singletonList(",");
public SetSqlNode(Configuration configuration, SqlNode contents) {
// 在字段前添加 SET 并覆盖前置和后置的 【,】符号。
super(configuration, contents, "SET", COMMA, null, COMMA);
}
}
复制代码
ForEachHandler 用于处理 foreach 元素,基于同样的原因, ForEachHandler 同样会借助于 parseDynamicTags() 反方解析 foreach 元素中嵌套的配置:
<!ELEMENT foreach (#PCDATA | include | trim | where | set | foreach | choose | if | bind)*> <!ATTLIST foreach collection CDATA #REQUIRED item CDATA #IMPLIED index CDATA #IMPLIED open CDATA #IMPLIED close CDATA #IMPLIED separator CDATA #IMPLIED > 复制代码
并获取 foreach 元素的属性配置来创建 ForEachSqlNode 对象:
private class ForEachHandler implements NodeHandler {
public ForEachHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
String collection = nodeToHandle.getStringAttribute("collection");
String item = nodeToHandle.getStringAttribute("item");
String index = nodeToHandle.getStringAttribute("index");
String open = nodeToHandle.getStringAttribute("open");
String close = nodeToHandle.getStringAttribute("close");
String separator = nodeToHandle.getStringAttribute("separator");
ForEachSqlNode forEachSqlNode = new ForEachSqlNode(configuration, mixedSqlNode, collection, index, item, open, close, separator);
targetContents.add(forEachSqlNode);
}
}
复制代码
ForEachSqlNode 对象的属性定义中,除了 Configuration 和 ExpressionEvaluator 之外,基本都和 foreach 元素的配置息息相关:
/**
* OGNL表达式解析器
*/
private final ExpressionEvaluator evaluator;
/**
* collection对应的OGNL表达式
*/
private final String collectionExpression;
/**
* 对应的Sql节点
*/
private final SqlNode contents;
/**
* 在开始部分添加的标签
*/
private final String open;
/**
* 在结束部分添加的标签
*/
private final String close;
/**
* 分隔符
*/
private final String separator;
/**
* 子名称
*/
private final String item;
/**
* 索引
*/
private final String index;
/**
* Mybatis配置
*/
private final Configuration configuration;
复制代码
ExpressionEvaluator 是 mybatis 提供的 OGNL 表达式解析器,用于解析 OGNL 表达式,这里就不展开了.
除此之外, ForEachSqlNode 还提供了一个取值为 __frch_ 的常量 ITEM_PREFIX ,该常量用于修饰 集合元素中的下标 .
在 ForEachSqlNode 的构造方法中,完成了上述属性的赋值工作:
public ForEachSqlNode(Configuration configuration, SqlNode contents, String collectionExpression, String index, String item, String open, String close, String separator) {
this.evaluator = new ExpressionEvaluator();
this.collectionExpression = collectionExpression;
this.contents = contents;
this.open = open;
this.close = close;
this.separator = separator;
this.index = index;
this.item = item;
this.configuration = configuration;
}
复制代码
ForEachSqlNode 的 apply() 看起来比较复杂,但是逻辑相对比较简单:
public boolean apply(DynamicContext context) {
Map<String, Object> bindings = context.getBindings();
// 解析迭代器对象
final Iterable<?> iterable = evaluator.evaluateIterable(collectionExpression, bindings);
if (!iterable.iterator().hasNext()) {
return true;
}
boolean first = true;
// 添加开始标签
applyOpen(context);
int i = 0;
for (Object o : iterable) {
DynamicContext oldContext = context;
if (first || separator == null) {
// 第一个不需要添加分隔符
context = new PrefixedContext(context, "");
} else {
// 在每项里面添加分隔符
context = new PrefixedContext(context, separator);
}
// 获取唯一标记
int uniqueNumber = context.getUniqueNumber();
// Issue #709
if (o instanceof Map.Entry) {
@SuppressWarnings("unchecked")
Map.Entry<Object, Object> mapEntry = (Map.Entry<Object, Object>) o;
// 绑定索引
applyIndex(context, mapEntry.getKey(), uniqueNumber);
// 绑定至
applyItem(context, mapEntry.getValue(), uniqueNumber);
} else {
// 非MAP 直接绑定索引
applyIndex(context, i, uniqueNumber);
// 非MAP 直接绑定值
applyItem(context, o, uniqueNumber);
}
// 解析出具体的SQL
contents.apply(new FilteredDynamicContext(configuration, context, index, item, uniqueNumber));
if (first) {
first = !((PrefixedContext) context).isPrefixApplied();
}
context = oldContext;
i++;
}
// 添加结束标签
applyClose(context);
// 移除条目
context.getBindings().remove(item);
// 移除索引
context.getBindings().remove(index);
return true;
}
复制代码
首先借助于 OGNL解析器 获取用户通过 foreach 元素的 collection 属性配置的集合,之后依次处理集合中的每一个元素,在处理集合前后,会分别调用 applyOpen() 和 applyClose() 方法完成前后标签的插入工作:
private void applyOpen(DynamicContext context) {
if (open != null) {
context.appendSql(open);
}
}
private void applyClose(DynamicContext context) {
if (close != null) {
context.appendSql(close);
}
}
复制代码
具体到处理每一个元素的过程中,首先将现有的 DynamicContext 对象包装成 PrefixedContext 实例, PrefixedContext 也是 DynamicContext 的实现类,他的构造方法除了需要一个 DynamicContext 实例作为委托类之外,还需要一个 prefix 参数, prefix 参数对应的是 foreach 元素的 separator 属性.
在创建 PrefixedContext 对象时,针对集合中的第一个元素是不需要指定 prefix 参数的取值的,如果用户没有为 foreach 元素配置 separator 属性,默认使用空字符串 "" ;
PrefixedContext 有三个属性定义,分别是委托类 delegate ,需要添加的前缀 prefix ,以及是否应用了前缀的标志符 prefixApplied .
/**
* 动态上下文委托处理类
*/
private final DynamicContext delegate;
/**
* 前缀
*/
private final String prefix;
/**
* 是否应用了前缀
*/
private boolean prefixApplied;
复制代码
PrefixedContext 的大部分方法都交给了委托类来完成,他只重写了 appendSql() 方法,在该方法中, PrefixedContext 会为 原始SQL 添加统一的前缀:
@Override
public void appendSql(String sql) {
// 尚未处理
if (!prefixApplied && sql != null && sql.trim().length() > 0) {
// 添加前缀
delegate.appendSql(prefix);
prefixApplied = true;
}
// 添加Sql内容
delegate.appendSql(sql);
}
复制代码
除此之外, PrefixedContext 还额外暴露了用于判断是否应用了前缀的 isPrefixApplied() 方法:
public boolean isPrefixApplied() {
return prefixApplied;
}
复制代码
回到 ForEachSqlNode 的 apply() 方法上来,在将 DynamicContext 对象包装成 PrefixedContext 之后, ForEachSqlNode 开始处理每一个集合元素.
首先调用 DynamicContext 的 getUniqueNumber() 方法,来获取当前处理的元素在集合中的位置:
private int uniqueNumber = 0;
public int getUniqueNumber() {
return uniqueNumber++;
}
复制代码
之后分别调用 applyIndex() 和 applyItem() 方法来处理用户配置的 index 属性和 item 属性.
private void applyIndex(DynamicContext context, Object o, int i) {
if (index != null) {
context.bind(index, o);
context.bind(itemizeItem(index, i), o);
}
}
private void applyItem(DynamicContext context, Object o, int i) {
if (item != null) {
context.bind(item, o);
context.bind(itemizeItem(item, i), o);
}
}
复制代码
上面代码中涉及到的 itemizeItem 方法用于为当前处理的元素生成唯一标志,并保存到 DynamicContext 中:
private static String itemizeItem(String item, int i) {
return ITEM_PREFIX + item + "_" + i;
}
复制代码
后续该标志将被用来获取实际数据.
applyIndex() 和 applyItem() 方法的入参基本一致,都是 (DynamicContext context, Object o, int i) ,其中第二个 Object 类型的参数表示的是 当前元素在集合中的下标 ,第三个 int 类型的元素表示的是 当前元素在整个集合中的位置 .
针对第二个参数,当集合的类型不同时,取值的方式也略有不同,针对 Map 集合,第二个参数的取值是 Map.Entry 的 key 值,普通集合对应的取值则是元素在集合中索引位置.
在处理元素的 index 和 item 配置之后, ForEachSqlNode 就会将 DynamicContext 包装成 FilteredDynamicContext 对象来处理 SQL配置 获取所需的 SqlNode 实例,需要注意的是,这里的 FilteredDynamicContext 对象时 ForEachSqlNode 的内部类,和前面提到的 FilteredDynamicContext 不是同一个对象.
当前 FilteredDynamicContext 对象,缓存了 foreach 的几个属性配置,并重写了 DynamicContext 对象的 appendSql() 方法:
private final DynamicContext delegate;
private final int index;
private final String itemIndex;
private final String item;
public FilteredDynamicContext(Configuration configuration, DynamicContext delegate, String itemIndex, String item, int i) {
super(configuration, null);
this.delegate = delegate;
this.index = i;
this.itemIndex = itemIndex;
this.item = item;
}
复制代码
appendSql() 方法的作用主要是借助于 GenericTokenParser 对象将用户配置通过 #{} 占位符配置的 item 和 index 转换为 运行时的唯一标志 :
@Override
public void appendSql(String sql) {
// 解析#{}标签
GenericTokenParser parser = new GenericTokenParser("#{", "}", content -> {
// 新内容
String newContent = content.replaceFirst("^//s*" + item + "(?![^.,://s])", itemizeItem(item, index));
if (itemIndex != null && newContent.equals(content)) {
newContent = content.replaceFirst("^//s*" + itemIndex + "(?![^.,://s])", itemizeItem(itemIndex, index));
}
// 生成占位符
return "#{" + newContent + "}";
});
// 解析占位符
delegate.appendSql(parser.parse(sql));
}
复制代码
比如:
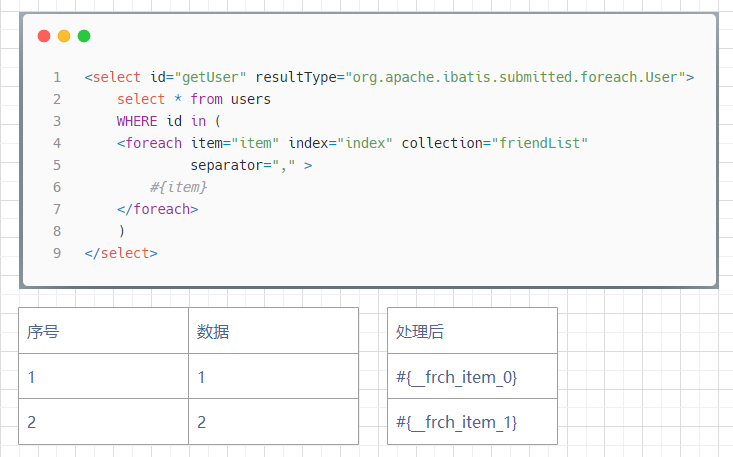
这一步和前面往 DynamicContext 对象中存放数据的操作相对应.
在处理完集合元素之后, appendSql() 方法就会移除掉前面通过 applyIndex() 和 applyItem() 方法存储的部分数据,只保留通过 itemizeItem() 生成数据映射即可:
// 移除条目 context.getBindings().remove(item); // 移除索引 context.getBindings().remove(index); 复制代码
ChooseHandler 负责处理的是 choose 元素,根据 choose 元素的子元素定义, ChooseHandler 的 handleNode() 方法提供了两个集合分别用于存储 when 元素配置和 otherwise 元素配置,并利用这两个集合创建对应的 ChooseSqlNode 对象存放到 targetContents 集合中.
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// When节点集合
List<SqlNode> whenSqlNodes = new ArrayList<>();
// otherwise节点集合
List<SqlNode> otherwiseSqlNodes = new ArrayList<>();
handleWhenOtherwiseNodes(nodeToHandle, whenSqlNodes, otherwiseSqlNodes);
// 获取otherwise节点,只能有一个
SqlNode defaultSqlNode = getDefaultSqlNode(otherwiseSqlNodes);
// 构造ChooseSql节点
ChooseSqlNode chooseSqlNode = new ChooseSqlNode(whenSqlNodes, defaultSqlNode);
targetContents.add(chooseSqlNode);
}
复制代码
在获取到 when 和 otherwise 配置对应的集合之后, ChooseHandler 还调用了 getDefaultSqlNode() 方法对 otherwise 配置的唯一性做了校验:
private SqlNode getDefaultSqlNode(List<SqlNode> defaultSqlNodes) {
SqlNode defaultSqlNode = null;
if (defaultSqlNodes.size() == 1) {
defaultSqlNode = defaultSqlNodes.get(0);
} else if (defaultSqlNodes.size() > 1) {
throw new BuilderException("Too many default (otherwise) elements in choose statement.");
}
return defaultSqlNode;
}
复制代码
不过,根据 choose 元素的 DTD 定义,该校验在大多数下是可以省略的:
<!ELEMENT choose (when* , otherwise?)> 复制代码
因为,通常我们在使用 mybtais 都会启用 DTD 校验.
负责解析 when 子元素和 otherwise 子元素的方法是 handleWhenOtherwiseNodes() ,该方法将具体元素的解析处理工作交给了相应的 NodeHandler 来处理.
private void handleWhenOtherwiseNodes(XNode chooseSqlNode, List<SqlNode> ifSqlNodes, List<SqlNode> defaultSqlNodes) {
List<XNode> children = chooseSqlNode.getChildren();
for (XNode child : children) {
String nodeName = child.getNode().getNodeName();
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler instanceof IfHandler) {
handler.handleNode(child, ifSqlNodes);
} else if (handler instanceof OtherwiseHandler) {
handler.handleNode(child, defaultSqlNodes);
}
}
}
复制代码
需要 注意 的是,在调用 NodeHandler 对象的 handleNode() 方法时,第二个入参分别是 ifSqlNodes 集合和 otherwiseSqlNodes 集合.
下面我们就来分别看一下负责处理 when 和 otherwise 元素的 IfHandler 和 OtherWiseHandler 的实现,之后再回头看 ChooseSqlNode 的实现.
IfHandler 本意上是用来处理 if 元素配置将其转换为 IfSqlNode ,但是鉴于 if 元素和 when 元素的作用和属性定义基本一致,因此 IfHandler 也被用来处理 when 元素.
<!ELEMENT if (#PCDATA | include | trim | where | set | foreach | choose | if | bind)*> <!ATTLIST if test CDATA #REQUIRED > <!ATTLIST when test CDATA #REQUIRED > 复制代码
IfHandler 实现比较简单,他借助与 parseDynamicTags() 方法完成子元素的解析,同时获取 if/when 的 test 属性配置,以此来生成相应的 IfSqlNode 对象,添加到 targetContents 集合中(这里的 targetContents 集合是 ifSqlNodes 集合):
private class IfHandler implements NodeHandler {
public IfHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 解析动态标签
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
// 获取IF语句的值
String test = nodeToHandle.getStringAttribute("test");
// 作为IfSqlNode节点
IfSqlNode ifSqlNode = new IfSqlNode(mixedSqlNode, test);
targetContents.add(ifSqlNode);
}
}
复制代码
IfSqlNode 对象有三个属性定义: OGNL 表达式解析器 evaluator ,通过 test 属性配置的 OGNL 表达式,以及 if/when 中子元素对应的 SqlNode 对象,这三个属性是在构造方法中完成赋值的:
/**
* 表达式解析器
*/
private final ExpressionEvaluator evaluator;
/**
* 表达式
*/
private final String test;
/**
* SQL节点
*/
private final SqlNode contents;
public IfSqlNode(SqlNode contents, String test) {
this.test = test;
this.contents = contents;
this.evaluator = new ExpressionEvaluator();
}
复制代码
他的 apply() 方法借助于 ExpressionEvaluator 对象的 evaluateBoolean 来获取在运行时 test 条件能否被满足,并执行相应的处理操作:
@Override
public boolean apply(DynamicContext context) {
// 解析内容
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}
复制代码
看上面的实现,在条件不满足时,返回的 false ,该返回值在 choose 元素中将决定是否继续执行下一个 when 或者 otherwise 配置.
OtherwiseHandler 的实现更为简单,他借助与 parseDynamicTags() 将 otherwise 的子元素配置解析成 MixedSqlNode 节点,并将其添加到 targetContents 集合中(这里的 targetContents 集合是 otherwiseSqlNodes 集合).
private class OtherwiseHandler implements NodeHandler {
public OtherwiseHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
targetContents.add(mixedSqlNode);
}
}
复制代码
了解了 if/when 元素和 otherwise 元素涉及到的内容之后,我们回过头来继续看 ChooseSqlNode .
ChooseSqlNode 只有两个属性定义,一个是 SqlNode 类型的 defaultSqlNode ,它用来存储 otherwise 元素对应的 SqlNode ,另一个是 List<SqlNode> 类型的 ifSqlNodes 属性,它用来存储所有 when 元素对应的 SqlNode 集合,这两个属性的初始化工作也是在构造方法中完成的:
/**
* 默认分支节点
*/
private final SqlNode defaultSqlNode;
/**
* 条件语分支节点
*/
private final List<SqlNode> ifSqlNodes;
public ChooseSqlNode(List<SqlNode> ifSqlNodes, SqlNode defaultSqlNode) {
this.ifSqlNodes = ifSqlNodes;
this.defaultSqlNode = defaultSqlNode;
}
复制代码
ChooseSqlNode 方法的实现原理很简单,优先校验 when 元素的配置,如果其 test 条件能够满足,则相应的 SqlNode 生效,否则继续校验下一个 when 元素配置,如果所有的 when 元素的条件都不能够满足,在配置了 otherwise 的前提下, otherwise 配置生效.
@Override
public boolean apply(DynamicContext context) {
// 遍历所有的分支节点,当遇到第一个满足条件的就返回
for (SqlNode sqlNode : ifSqlNodes) {
if (sqlNode.apply(context)) {
return true;
}
}
// 如果没有满足条件的分支节点,则处理默认分支节点
if (defaultSqlNode != null) {
defaultSqlNode.apply(context);
return true;
}
return false;
}
复制代码
现在,我们最后还剩下负责将 bind 元素配置解析成 VarDecSqlNode 的 BindHandler 还没有了解.
BindHandler 的实现也比较简单,根据 bind 元素的 DTD 定义:
<!ELEMENT bind EMPTY> <!ATTLIST bind name CDATA #REQUIRED value CDATA #REQUIRED > 复制代码
BindHandler 将会读取 bind 元素的 name 和 value 属性的配置来生成的 VarDeclSqlNode 对象,并将其添加到 targetContents 集合中:
private class BindHandler implements NodeHandler {
public BindHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 定义的变量名称
final String name = nodeToHandle.getStringAttribute("name");
// 定义的OGNL表达式
final String expression = nodeToHandle.getStringAttribute("value");
final VarDeclSqlNode node = new VarDeclSqlNode(name, expression);
targetContents.add(node);
}
}
复制代码
VarDeclSqlNode 有 name 和 expression 两个属性定义,他们分别用来存储 参数名称 和 值的OGNL表达式 ,这两个属性的赋值工作也是在构造方法中完成的:
private final String name;
private final String expression;
public VarDeclSqlNode(String var, String exp) {
/**
* 属性名称
*/
name = var;
/**
* 属性值
*/
expression = exp;
}
复制代码
VarDeclSqlNode 的 apply() 方法的作用实际上是根据用户的 bind 配置往 DynamicContext 中赋值.
@Override
public boolean apply(DynamicContext context) {
// 解析表达式并获取值
final Object value = OgnlCache.getValue(expression, context.getBindings());
// 绑定值
context.bind(name, value);
return true;
}
复制代码
注意看上面的实现, expression 属性是通过 OgnlCache 的 getValue() 方法来取值的,因此 bind 元素的 value 属性是支持 OGNL 语法表达式的.
至此,我们算是了解了所有的 NodeHandler 以及 SqlNode 的实现与应用.
回到 XMLScriptBuilder 的 parseScriptNode() 方法中:
public SqlSource parseScriptNode() {
// 解析动态标签
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource = null;
if (isDynamic) {
// 配置动态SQL源
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
// 配置静态SQL源
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}
复制代码
通过上面的代码我们可以看到 SqlNode 对象最终会被转换成 SqlSource 的实现类来对外提供服务.
前面我们简单的提到过 SqlSource 定义了 getBoundSql() 方法用来获取 BoundSql 对象.
现在我们先来看一下 BoundSql 对象的具体实现,之后再看一下 SqlSource 接口相关的实现.
BoundSql 维护了 mybatis 执行一条 SQL 语句所必需的数据,他在维护真正待执行的 SQL 语句的同时,还保留了用于执行该 SQL 语句的参数配置和参数对象.
BoundSql 有 5 个属性定义:
/** * 传递给JDBC的SQL文本 */ private final String sql; /** * 静态参数说明 */ private final List<ParameterMapping> parameterMappings; /** * 运行时的参数对象 */ private final Object parameterObject; /** * 额外的参数对象,也就是for loops、bind生成的 */ private final Map<String, Object> additionalParameters; /** * 额外参数的facade模式包装 */ private final MetaObject metaParameters; 复制代码
其中 String 类型的 sql 属性用于维护真正传递给数据库执行的 SQL 语句, List<ParameterMapping> 类型的 parameterMappings 集合则维护了用于执行该语句的参数映射配置,集合中的每一条配置都和待执行 SQL 语句中的 ? 按顺序一一对应.
Object 类型的 parameterObject 参数,表示用户调用 CRUD 方法时传入的 方法入参 ,该 方法入参 是经过特殊处理的,因此可以用一个 Object 类型的参数来表示多个 方法入参 .
关于方法入参的特殊处理,会在后面的文章中展开.
Map<String, Object> 类型的 additionalParameters 集合负责存储除方法入参之外的参数映射关系,比如通过 bind , for 元素生成的临时参数,还有默认添加的 _parameter 和 _databaseId 参数.
最后一个 MetaObject 类型的 metaParameters 属性是 additionalParameters 的包装对象.
上述这 5 个属性的赋值操作都是在构造方法中完成的:
public BoundSql(Configuration configuration, String sql, List<ParameterMapping> parameterMappings, Object parameterObject) {
this.sql = sql;
this.parameterMappings = parameterMappings;
this.parameterObject = parameterObject;
this.additionalParameters = new HashMap<>();
this.metaParameters = configuration.newMetaObject(additionalParameters);
}
复制代码
除此之外, BoundSql 还对外暴露了一些方法用来操作这些属性:
比如,用来获取需要执行的 sql 语句的 getSql() 方法:
public String getSql() {
return sql;
}
复制代码
获取方法参数映射配置的 getParameterMappings() 方法:
public List<ParameterMapping> getParameterMappings() {
return parameterMappings;
}
复制代码
获取方法入参对象的 getParameterObject() 方法:
public Object getParameterObject() {
return parameterObject;
}
复制代码
上述的三个方法都是简单的赋值操作,除此之外,还有三个用来操作 额外参数配置的 方法:
public boolean hasAdditionalParameter(String name) {
String paramName = new PropertyTokenizer(name).getName();
return additionalParameters.containsKey(paramName);
}
public void setAdditionalParameter(String name, Object value) {
metaParameters.setValue(name, value);
}
public Object getAdditionalParameter(String name) {
return metaParameters.getValue(name);
}
复制代码
这三个方法用来分别用来 判断是否存在某参数 , 添加参数映射 ,和 获取参数值 ,需要注意的是,这里操作的参数名称是支持 点式分隔形式 的.
看完了 BoundSql 对象,我们回头继续看 SqlSource 相关的内容.
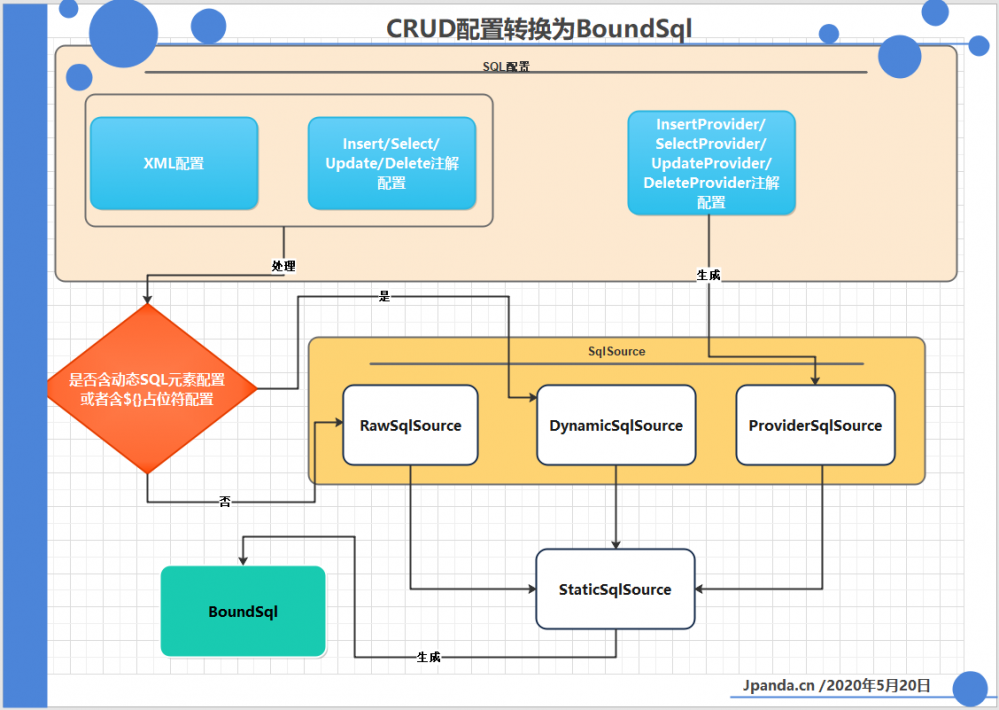
在 mybatis 中默认为 SqlSource 对象提供了四种实现: DynamicSqlSource , ProviderSqlSource , RawSqlSource 以及 StaticSqlSource .
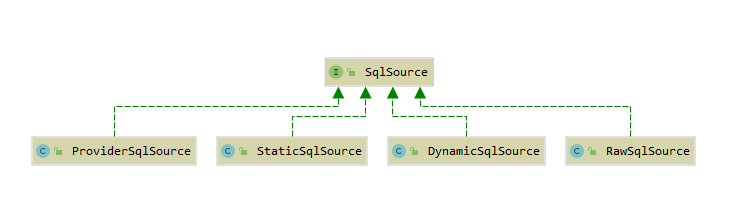
通过前面的学习,我们了解到可以将 SQL 配置分为 动态SQL配置 和 静态SQL配置 两种.
如果 SQL 配置中包含 ${} 占位符或者使用了 动态SQL元素 ,那么该配置就是 动态SQL配置 ,反之就是 静态SQL配置 :
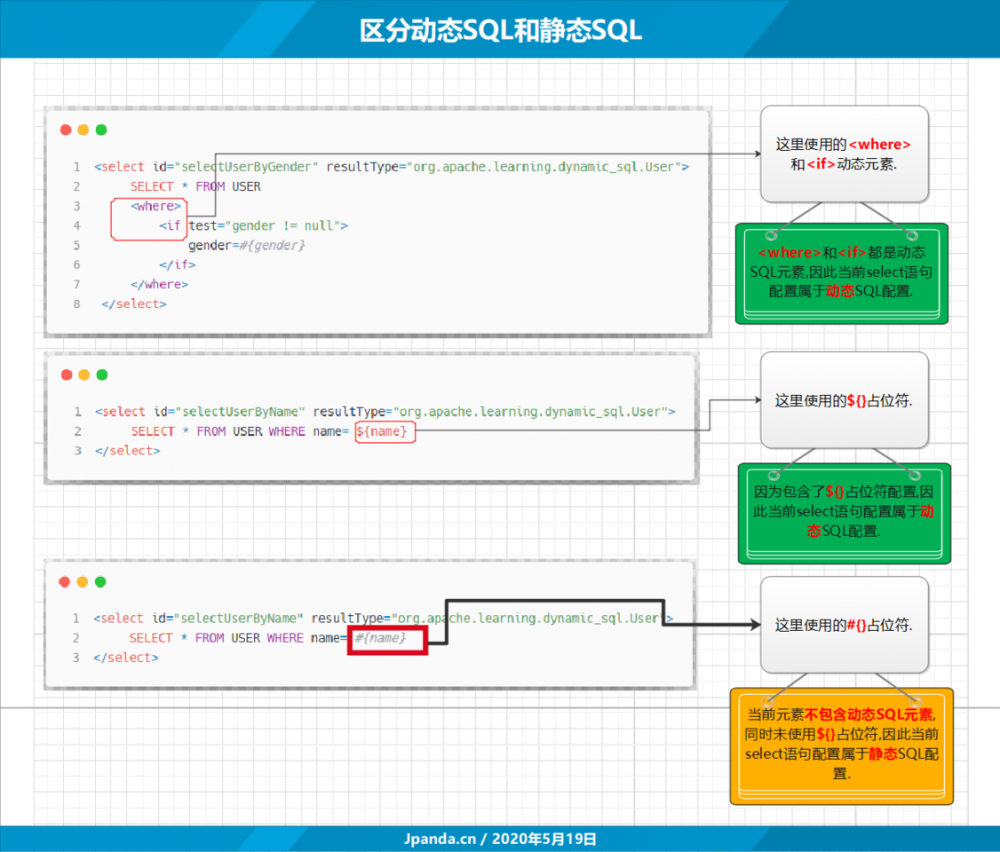
DynamicSqlSource 对应的就是 动态SQL配置 , RawSqlSource 则对应着 静态SQL配置 .
无论是 动态SQL配置 还是 静态SQL配置 ,所对应的 SQL 语句中都允许使用 #{} 占位符,因此在实际使用时还需要进一步解析其中的 #{} 占位符,得到最终用于数据库执行的 SQL 语句.
这里所得到的最终的 SQL配置 对应的就是 StaticSqlSource ,还剩下一个 ProviderSqlSource ,是用来处理通过 InsertProvider , SelectProvider , UpdateProvider 以及 DeleteProvider 四个注解提供的 SQL配置 的.
我们先来看一下负责维护 动态SQL配置 的 DynamicSqlSource 的实现.
DynamicSqlSource 定义了两个属性,分别是 configuration 和 rootSqlNode .
// Mybatis配置 private final Configuration configuration; // Sql节点 private final SqlNode rootSqlNode; 复制代码
其中 configuration 是 mybatis 的配置类, rootSqlNode 则是当前 SQL配置 对应的 SqlNode 对象,这两个属性是在构造方法中被赋值的:
public DynamicSqlSource(Configuration configuration, SqlNode rootSqlNode) {
this.configuration = configuration;
this.rootSqlNode = rootSqlNode;
}
复制代码
DynamicSqlSource 的 getBoundSql() 方法的实现不算复杂,从理论上来讲,该方法只需要根据 当前运行上下文 筛选出 SQL配置 中的 生效部分 ,在处理了其中的 #{} 占位符之后,创建相对应的 BoundSql 实例并返回即可.
public BoundSql getBoundSql(Object parameterObject) {
// 生成动态内容解析器
DynamicContext context = new DynamicContext(configuration, parameterObject);
// 处理动态标签节点
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
// 解析Sql占位符内容
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
for (Map.Entry<String, Object> entry : context.getBindings().entrySet()) {
// 添加当前上下文动态绑定的内容
boundSql.setAdditionalParameter(entry.getKey(), entry.getValue());
}
return boundSql;
}
复制代码
在实现上,该方法首先会利用 mybatis 的 Configuration 实例和用户调用 CRUD 方法时传入的方法入参创建一个 DynamicContext 实例,并以此来调用 SqlNode 的 apply() 方法,完成 有效SQL 的筛选获取工作.
之后利用 SqlSourceBuilder 处理 有效SQL 中的 #{} 占位符,并以此来获取最终的 BoundSql 实例.
然后将 DynamicContext 中的参数配置添加到 BoundSql 实例中,最后返回 BoundSql 实例.
SqlSourceBuilder 对象的作用是将指定 SQL 中的 #{} 占位符替换为 ? ,同时将该占位符对应的参数信息转换为 ParameterMapping 对象供后续使用.
SqlSourceBuilder 对象的实现并不复杂,他的 parse() 方法负责处理 SQL配置 中的 #{} 占位符,并返回相应的 StaticSqlSource 实例.
public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters) {
ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
// 解析 【#{】和【}】直接的内容
GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
String sql = parser.parse(originalSql);
return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
}
复制代码
在实现上,该方法借助于 GenericTokenParser 来获取所有匹配的 #{} 占位符,并将占位符内容交给 ParameterMappingTokenHandler 来处理.
ParameterMappingTokenHandler 将指定 SQL 中的 #{} 占位符替换为 ? ,同时将该占位符对应的参数信息转换为 ParameterMapping 缓存起来.
最后 SqlSourceBuilder 利用处理后的 SQL 内容和缓存起来的 ParameterMapping 集合创建相应的 StaticSqlSource 实例返回给调用方.
有关于 ParameterMappingTokenHandler 的具体实现细节,我们待会会展开.
RawSqlSource 用来表示 静态SQL配置 ,因此不会包含 动态SQL元素配置 也不会包含 ${} 占位符,所以在实现上,他只需要解析 #{} 占位符即可.
需要注意的是 RawSqlSource 提供了一个 SqlSource 类型的 sqlSource 属性,用来缓存当前 静态SQL配置 对应的 StaticSqlSource 对象.
private final SqlSource sqlSource; 复制代码
该属性的赋值工作是在 RawSqlSource 对象的构造方法中完成的:
public RawSqlSource(Configuration configuration, SqlNode rootSqlNode, Class<?> parameterType) {
this(configuration,
getSql(configuration, rootSqlNode)
, parameterType);
}
public RawSqlSource(Configuration configuration, String sql, Class<?> parameterType) {
// SqlSource建造器
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> clazz = parameterType == null ? Object.class : parameterType;
// 解析SQL
sqlSource = sqlSourceParser.parse(sql, clazz, new HashMap<String, Object>());
}
private static String getSql(Configuration configuration, SqlNode rootSqlNode) {
DynamicContext context = new DynamicContext(configuration, null);
rootSqlNode.apply(context);
return context.getSql();
}
复制代码
之后在调用 RawSqlSource 的 getBoundSql() 时,就不会重复创建 StaticSqlSource 对象了:
@Override
public BoundSql getBoundSql(Object parameterObject) {
return sqlSource.getBoundSql(parameterObject);
}
复制代码
因此在多次调用同一个 SqlSource 对象的 getBoundSql() 方法时, RawSqlSource 的效率要高于 DynamicSqlSource .
作为最终进化形态的 StaticSqlSource 对象的实现就更为简单了,他提供了三个属性用来缓存创建 BoundSql 对象所需的数据:
private final String sql;
private final List<ParameterMapping> parameterMappings;
private final Configuration configuration;
public StaticSqlSource(Configuration configuration, String sql) {
this(configuration, sql, null);
}
public StaticSqlSource(Configuration configuration, String sql, List<ParameterMapping> parameterMappings) {
this.sql = sql;
this.parameterMappings = parameterMappings;
this.configuration = configuration;
}
复制代码
在调用其 getBoundSql() 方法时直接利用现有参数创建 BoundSql 实例并返回即可:
@Override
public BoundSql getBoundSql(Object parameterObject) {
return new BoundSql(configuration, sql, parameterMappings, parameterObject);
}
复制代码
最后,还剩下一个 ProviderSqlSource 对象,因为该对象负责处理的是 基于注解提供的SQL配置 ,因此我们需要简单了解一下 Provider注解配置 的使用.
除了通过 XML 文件和 XML元素同名注解 配置 SQL 之外, mybatis 还允许通过 provider 系列注解指定一个 java方法 来更灵活的配置 SQL .
provider 系列注解一共有四个,它们分别是: InsertProvider , SelectProvider , UpdateProvider 以及 DeleteProvider ,这四个注解分别对应着 CRUD 四种数据库操作.
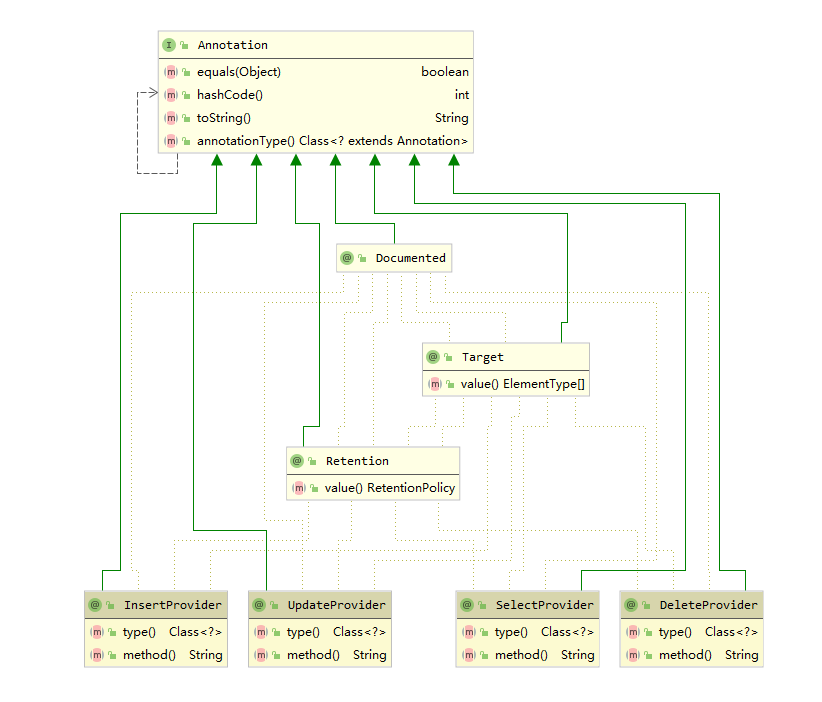
provider 系列注解对外暴露了相同的两个方法: type() 和 method() .
其中 type() 方法返回 负责提供SQL语句的类定义 , method() 则负责返回 具体的方法名称 .
我们以查询语句为例,简单感受一下三种配置方式的使用:
UserMapper.java :
public interface UserMapper {
@SelectProvider(type = SqlProvider.class, method = "selectUserByName")
List<User> selectUserByNameWithProvider(@Param("name") String name);
class SqlProvider {
public String selectUserByName() {
return "SELECT * FROM USER WHERE name= #{name}";
}
}
@Select("SELECT * FROM USER WHERE name= #{name}")
List<User> selectUserByNameWithSimpleAnnotation(@Param("name") String name);
List<User> selectUserByNameWithXML(@Param("name") String name);
}
复制代码
UserMapper.xml :
<mapper namespace="org.apache.learning.provider.UserMapper">
<select id="selectUserByNameWithXML" resultType="org.apache.learning.provider.User">
SELECT *
FROM USER
WHERE name = #{name}
</select>
</mapper>
复制代码
单元测试:
@Test
public void selectProviderTest() {
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
log.info("使用SelectProvider注解查询.结果为:{}", userMapper.selectUserByNameWithProvider("Panda"));
log.info("使用Select注解查询.结果为:{}", userMapper.selectUserByNameWithSimpleAnnotation("Panda"));
log.info("使用XML配置查询.结果为:{}", userMapper.selectUserByNameWithXML("Panda"));
}
复制代码
运行结果日志(关键):
...省略... DEBUG [main] - ==> Preparing: SELECT * FROM USER WHERE name= ? DEBUG [main] - ==> Parameters: Panda(String) DEBUG [main] - <== Total: 1 INFO [main] - 使用SelectProvider注解查询.结果为:[User(id=38400000-8cf0-11bd-b23e-10b96e4ef00d, name=Panda, gender=男)] DEBUG [main] - ==> Preparing: SELECT * FROM USER WHERE name= ? DEBUG [main] - ==> Parameters: Panda(String) DEBUG [main] - <== Total: 1 INFO [main] - 使用Select注解查询.结果为:[User(id=38400000-8cf0-11bd-b23e-10b96e4ef00d, name=Panda, gender=男)] DEBUG [main] - ==> Preparing: SELECT * FROM USER WHERE name = ? DEBUG [main] - ==> Parameters: Panda(String) DEBUG [main] - <== Total: 1 INFO [main] - 使用XML配置查询.结果为:[User(id=38400000-8cf0-11bd-b23e-10b96e4ef00d, name=Panda, gender=男)] ...省略... 复制代码
仔细看上面的日志,我们会发现三种配置的最终效果是一致的.
查看详细单元测试 SqlProviderTest
或者访问链接: gitee.com/topanda/myb…
在了解了 SelectProvider 的简单用法之后,我们来看一下 ProviderSqlSource 对象的实现.
ProviderSqlSource 对象有 8 个属性定义:
/** * Mybatis配置类 */ private final Configuration configuration; /** * SqlSource对象构建器 */ private final SqlSourceBuilder sqlSourceParser; /** * 提供Sql的对象类型 */ private final Class<?> providerType; /** * 提供Sql的方法 */ private Method providerMethod; /** * 提供Sql方法的入参名称集合 */ private String[] providerMethodArgumentNames; /** * 提供Sql方法的入参类型集合 */ private Class<?>[] providerMethodParameterTypes; /** * 用于Provider方法的上下文对象 */ private ProviderContext providerContext; /** * 配置使用Provider方法对应的上下文对象对应的参数位置索引 */ private Integer providerContextIndex; 复制代码
我们来看一下除了 Configuration 和 SqlSourceBuilder 之外的其余 6 个属性定义, providerType 属性对应着 Provider 注解中的 type() 方法的返回值,用来缓存 负责提供SQL的对象类型 .
providerMethod 负责记录 用于提供SQL的方法名称 , providerMethodArgumentNames 和 providerMethodParameterTypes 则负责记录 用于提供SQL的方法的入参名称和类型 .
ProviderContext 类型的 providerContext 属性负责记录调用 Provider 方法的上下文信息.
providerContextIndex 则负责记录 ProviderContext 类型的参数在 Provider 方法参数列表中索引位置.
ProviderContext 的实现十分简单,他定义了两个属性.并为这两个属性提供了相应的 getter 方法:
/**
* 用于Provider方法的上下文对象
*
* @author Kazuki Shimizu
* @since 3.4.5
*/
public final class ProviderContext {
/**
* 对应的映射器类型
*/
private final Class<?> mapperType;
/**
* 对应的映射器方法
*/
private final Method mapperMethod;
/**
* Constructor.
*
* @param mapperType 指定了Provider注解的Mapper接口类型
* @param mapperMethod 指定了Provider注解的Mapper方法
*/
ProviderContext(Class<?> mapperType, Method mapperMethod) {
this.mapperType = mapperType;
this.mapperMethod = mapperMethod;
}
public Class<?> getMapperType() {
return mapperType;
}
public Method getMapperMethod() {
return mapperMethod;
}
}
复制代码
其中 mapperType 属性用于记录指定了 Provider 注解的 Mapper 接口类型, mapperMethod 则负责记录指定了 Provider 注解的 Mapper 方法.
我们来看一下,在实际应用在 ProviderContext 中的属性对应的具体数据来源:
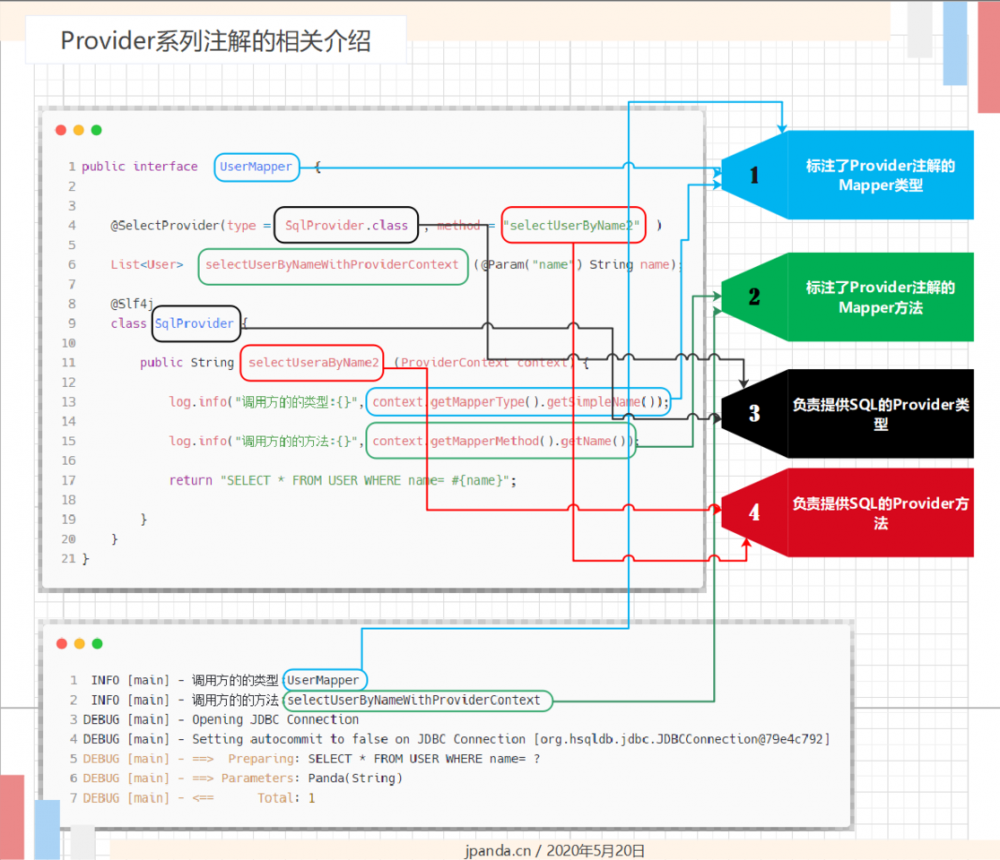
(同一组数据使用相同颜色进行标注和连接)
回到 ProviderSqlSource 的源码解析上来, ProviderSqlSource 提供了两个构造方法,这两个构造方法的主要作用就是为上述的 8 个属性赋值.
其中一个构造方法的实现是通过调用另一个构造方法来完成的:
@Deprecated
public ProviderSqlSource(Configuration configuration, Object provider) {
this(configuration, provider, null, null);
}
复制代码
需要注意的是,上述的这个构造方法已经被弃用,因为该构造不需要传入标注了 Provider 注解的 Mapper接口 和 Mapper方法 ,因此,也就导致通过该构造方法构建的 ProviderSqlSource 对象无法创建所需的 ProviderContext 属性.
ProviderSqlSource 另一个构造方法的实现不算复杂,其主要的作用就是处理 Provider 注解和标注了 Provider 注解的 Mapper接口 和 Mapper方法 ,并初始化 ProviderSqlSource 所需的属性定义.
public ProviderSqlSource(Configuration configuration, Object provider, Class<?> mapperType, Method mapperMethod) {
String providerMethodName;
try {
// 初始化Mybatis全局配置
this.configuration = configuration;
// SqlSource对象的构建器
this.sqlSourceParser = new SqlSourceBuilder(configuration);
// 通过注解获取提供Sql内容的对象类型
this.providerType = (Class<?>) provider.getClass().getMethod("type").invoke(provider);
// 通过注解获取提供Sql内容的方法名称
providerMethodName = (String) provider.getClass().getMethod("method").invoke(provider);
for (Method m : this.providerType.getMethods()) {
if (providerMethodName.equals(m.getName()) && CharSequence.class.isAssignableFrom(m.getReturnType())) {
// 方法名称匹配,同时返回内容是可读序列的子类,其实简单来讲就是看看方法的返回对象是不是能转成字符串
if (providerMethod != null) {
throw new BuilderException("Error creating SqlSource for SqlProvider. Method '"
+ providerMethodName + "' is found multiple in SqlProvider '" + this.providerType.getName()
+ "'. Sql provider method can not overload.");
}
// 配置提供Sql的方法
this.providerMethod = m;
// 配置提供Sql方法的入参名称集合
this.providerMethodArgumentNames = new ParamNameResolver(configuration, m).getNames();
// 配置提供Sql方法的入参类型集合
this.providerMethodParameterTypes = m.getParameterTypes();
}
}
} catch (BuilderException e) {
throw e;
} catch (Exception e) {
throw new BuilderException("Error creating SqlSource for SqlProvider. Cause: " + e, e);
}
if (this.providerMethod == null) {
throw new BuilderException("Error creating SqlSource for SqlProvider. Method '"
+ providerMethodName + "' not found in SqlProvider '" + this.providerType.getName() + "'.");
}
// 解析参数类型
for (int i = 0; i < this.providerMethodParameterTypes.length; i++) {
// 获取方法入参类型
Class<?> parameterType = this.providerMethodParameterTypes[i];
if (parameterType == ProviderContext.class) {
// 查找ProviderContext类型的参数
if (this.providerContext != null) {
throw new BuilderException("Error creating SqlSource for SqlProvider. ProviderContext found multiple in SqlProvider method ("
+ this.providerType.getName() + "." + providerMethod.getName()
+ "). ProviderContext can not define multiple in SqlProvider method argument.");
}
// 构建用于Provider方法的上下文对象
this.providerContext = new ProviderContext(mapperType, mapperMethod);
// 配置使用Provider方法对应的上下文对象对应的参数位置索引
this.providerContextIndex = i;
}
}
}
复制代码
在实现上,该方法会通过反射调用 Provider 注解的 type() 和 method() 方法以此来获取 Provider 对象的类型和具体方法名称.
鉴于 java 方法是允许重载的,所以就可能会出现 同时拥有多个同名不同参的重载方法 的场景,因此还需要进一步的对方法名称的唯一性做校验
因为 Provider方法 的作用是返回合适的 SQL 语句,因此 mybatis 会忽略掉所有返回类型非 CharSequence 类型及其子类型的方法.
在得到唯一有效的 Provider方法 之后, mybatis 通过反射获取其形参名称列表和形参类型列表,并记录可能存在的 ProviderContext 类型的参数在形参列表中的位置和创建相应的 ProviderContext 对象.
在这个构造方法的处理过程中,借用了 ParamNameResolver 对象来获取方法的形参名称列表:
// 配置提供Sql方法的入参名称集合 this.providerMethodArgumentNames = new ParamNameResolver(configuration, m).getNames(); 复制代码
该对象的作用我们在 Mybatis源码之美:3.5.5.配置构造方法的constructor元素 一文中稍作提及,限于篇幅,具体的实现我们会在后面的文章中展开.
最后是 ProviderSqlSource 用于获取 BoundSql 的 getBoundSql() 方法:
public BoundSql getBoundSql(Object parameterObject) {
SqlSource sqlSource = createSqlSource(parameterObject);
return sqlSource.getBoundSql(parameterObject);
}
复制代码
该方法在实现通过 createSqlSource() 方法得到 StaticSqlSource 对象,并借助于 StaticSqlSource 对象的 getBoundSql() 方法返回最终 BoundSql 实例.
createSqlSource() 方法的实现理论来讲就是通过前面获取到的 Provider类型 和 Provider方法 利用反射得到 SQL 内容,传递给 SqlSourceBuilder 来获取 StaticSqlSource 实例:
private SqlSource createSqlSource(Object parameterObject) {
try {
// 计算除ProviderContext类型的参数之外的形参数量.
int bindParameterCount = providerMethodParameterTypes.length - (providerContext == null ? 0 : 1);
// 获取SQL
String sql;
if (providerMethodParameterTypes.length == 0) {
sql = invokeProviderMethod();
} else if (bindParameterCount == 0) {
sql = invokeProviderMethod(providerContext);
} else if (bindParameterCount == 1 &&
(parameterObject == null || providerMethodParameterTypes[providerContextIndex == null || providerContextIndex == 1 ? 0 : 1].isAssignableFrom(parameterObject.getClass()))) {
sql = invokeProviderMethod(extractProviderMethodArguments(parameterObject));
} else if (parameterObject instanceof Map) {
@SuppressWarnings("unchecked")
Map<String, Object> params = (Map<String, Object>) parameterObject;
sql = invokeProviderMethod(extractProviderMethodArguments(params, providerMethodArgumentNames));
} else {
throw new BuilderException("Error invoking SqlProvider method ("
+ providerType.getName() + "." + providerMethod.getName()
+ "). Cannot invoke a method that holds "
+ (bindParameterCount == 1 ? "named argument(@Param)" : "multiple arguments")
+ " using a specifying parameterObject. In this case, please specify a 'java.util.Map' object.");
}
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
// 创建并返回SqlSource
return sqlSourceParser.parse(replacePlaceholder(sql), parameterType, new HashMap<String, Object>());
} catch (BuilderException e) {
throw e;
} catch (Exception e) {
throw new BuilderException("Error invoking SqlProvider method ("
+ providerType.getName() + "." + providerMethod.getName()
+ "). Cause: " + e, e);
}
}
复制代码
实际实现可能要稍显复杂一些,主要是在执行反射调用时需要考虑到不同的入参场景,以及填充额外的 ProviderContext 类型的参数.
实际负责获取方法实际入参的方法是 extractProviderMethodArguments() 方法的两个重载形式,该方法除了负责根据形参列表加载实际参数之外,还会额外处理 ProviderContext 类型的参数.
private Object[] extractProviderMethodArguments(Object parameterObject) {
if (providerContext != null) {
Object[] args = new Object[2];
args[providerContextIndex == 0 ? 1 : 0] = parameterObject;
args[providerContextIndex] = providerContext;
return args;
} else {
return new Object[]{parameterObject};
}
}
private Object[] extractProviderMethodArguments(Map<String, Object> params, String[] argumentNames) {
Object[] args = new Object[argumentNames.length];
for (int i = 0; i < args.length; i++) {
if (providerContextIndex != null && providerContextIndex == i) {
args[i] = providerContext;
} else {
args[i] = params.get(argumentNames[i]);
}
}
return args;
}
复制代码
实际负责完成方法调用,并获取 SQL 内容的是 invokeProviderMethod() 方法:
private String invokeProviderMethod(Object... args) throws Exception {
Object targetObject = null;
if (!Modifier.isStatic(providerMethod.getModifiers())) {
targetObject = providerType.newInstance();
}
CharSequence sql = (CharSequence) providerMethod.invoke(targetObject, args);
return sql != null ? sql.toString() : null;
}
复制代码
方法实现较简单,属于常规的反射操作.
还有一点要注意的是,在 createSqlSource() 返回 SqlSource 对象时,对得到的 SQL 语句进行了 ${} 占位符的处理操作:
return sqlSourceParser.parse(replacePlaceholder(sql), parameterType, new HashMap<String, Object>()); 复制代码
在替换占位符时,使用的 Configuration 对象的 variables 属性作为上下文参数:
private String replacePlaceholder(String sql) {
return PropertyParser.parse(sql, configuration.getVariables());
}
复制代码
到这里,我们基本了解了 ProviderSqlSource 对象的源码实现了.
最后,我们再总结一下 SqlSource 和不同配置之间的关系.
再补充了这么多零碎的知识点之后,再回头看 XMLLanguageDriver 的 createSqlSource() 方法,是不是就好理解了呢?
public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
// 动态元素解析器
XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
// 构架SQL源
return builder.parseScriptNode();
}
复制代码
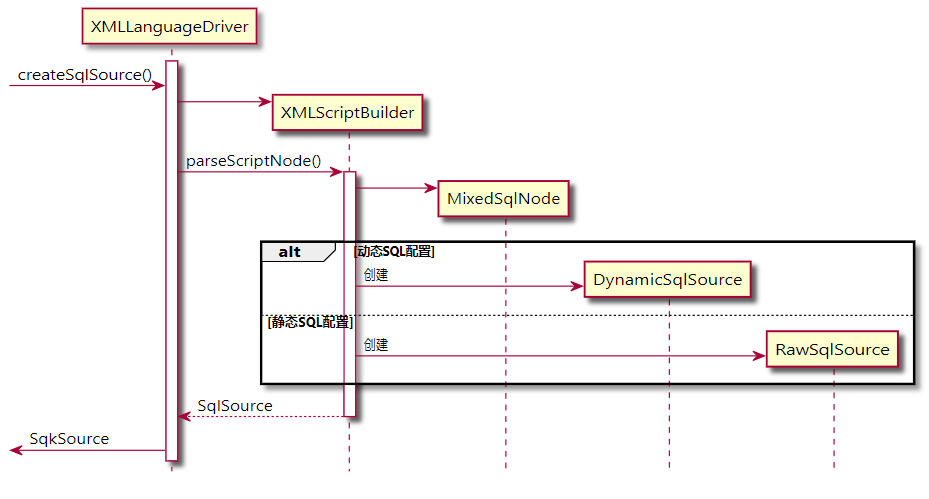
现在我们再回头梳理一下 XMLLanguageDriver 的调用链:
@startuml hide footbox participant XMLLanguageDriver as xld [-> xld ++:createSqlSource() xld -> XMLScriptBuilder** xld -> XMLScriptBuilder++:parseScriptNode() XMLScriptBuilder->MixedSqlNode** alt 动态SQL配置 XMLScriptBuilder -> DynamicSqlSource** else XMLScriptBuilder -> RawSqlSource** end return SqlSource return SqlSource @enduml 复制代码
除了 XMLLanguageDriver 之外, LanguageDriver 还有一种实现: RawLanguageDriver .
RawLanguageDriver 是 XMLLanguageDriver 的子类,他重写了父类的 createSqlSource 方法,限制方法只能返回 RawSqlSource 类型的 SqlSource 对象.
public class RawLanguageDriver extends XMLLanguageDriver {
@Override
public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
// 解析占位符和参数的关系
SqlSource source = super.createSqlSource(configuration, script, parameterType);
checkIsNotDynamic(source);
return source;
}
@Override
public SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType) {
SqlSource source = super.createSqlSource(configuration, script, parameterType);
checkIsNotDynamic(source);
return source;
}
private void checkIsNotDynamic(SqlSource source) {
if (!RawSqlSource.class.equals(source.getClass())) {
throw new BuilderException("Dynamic content is not allowed when using RAW language");
}
}
}
复制代码
探究主键生成器
了解完了 LanguageDriver 之后,让我们来 简单了解 一下主键生成器.
KeyGenerator 是 mybatis 提供的主键生成器接口定义,它定义了两个方法,分别用来在 CRUD语句 执行前后来完成主键的处理操作.
public interface KeyGenerator {
void processBefore(Executor executor, MappedStatement ms, Statement stmt, Object parameter);
void processAfter(Executor executor, MappedStatement ms, Statement stmt, Object parameter);
}
复制代码
mybatis 默认为 KeyGenerator 提供了 3 个实现:
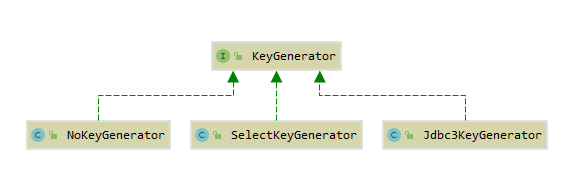
其中 Jdbc3KeyGenerator 的实现依赖于 JDBC3.0 规范中的 Statement#getGeneratedKeys() 方法,他只支持 processAfter() 方法.
自JDBC3.0开始,Statement对象的getGeneratedKeys()可以获取因为执行当前 Statement对象而生成的主键,如果Statement没有生成主键,则返回空的ResultSet对象
关于 Statement#getGeneratedKeys() 的内容,可以参见文章 Mybatis源码之美:3.8.探究insert,update以及delete元素的用法 中关于 useGeneratedKeys属性 的相关内容.
SelectKeyGenerator 的实现则对应着 SelectKey 元素的配置,他可以根据用户配置的 SelectKey 元素在执行目标 CRUD 语句的前后来完成主键的获取操作.
至于 NoKeyGenerator 是 mybatis 为 KeyGenerator 提供的一个空实现.
在这里,我们只是简单的了解一下 KeyGenerator 相关的内容,至于更详细的源码实现,我们会在后面的文章中一一展开.
正文到此结束
- 本文标签: 遍历 list entity mapper Collection session ResultSet 正则表达式 db2 tar IDE 解析 value src ORM IO HashMap Statement tab 数据 App key build Property executor 集合类 JDBC 源码 https UI CTO XML provider 处理器 cache token 构造方法 tk 测试 git 配置 CEO Collections 总结 文章 sqlsession Lua 静态方法 递归 root struct map 实例 final ACE 动态SQL bug equals tag apache ip sql 设计模式 Select 参数 http XMLStatementBuilder 一致性 ArrayList 单元测试 update db cat 代码 parse mybatis ECS myabtis id 索引 缓存 java node 数据库 管理
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

