【Java 并发编程】Java 创建线程池的正确姿势: Executors 和 ThreadPoolExecutor 详解
我们先看 Java 开发手册上说的:

我们可以看一下源码:
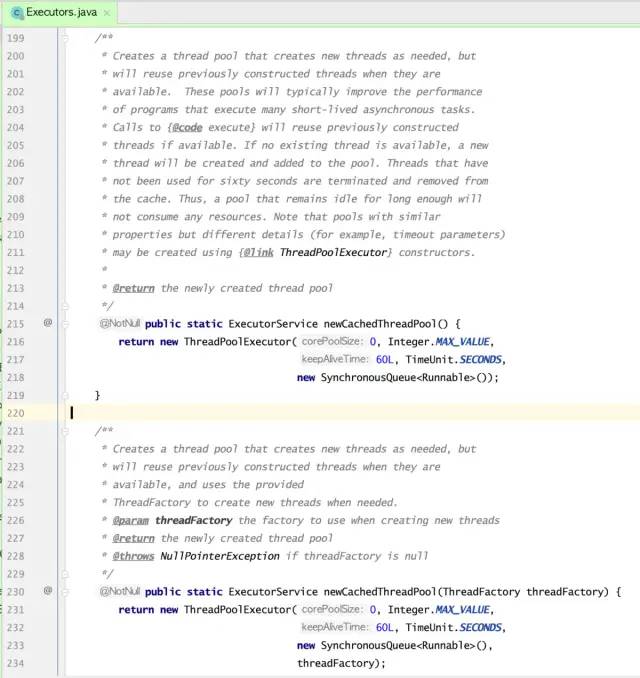
这里的 ThreadPoolExecutor 的构造函数如下:
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters and default thread factory and rejected execution handler.
* It may be more convenient to use one of the {@link Executors} factory
* methods instead of this general purpose constructor.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
参数说明:
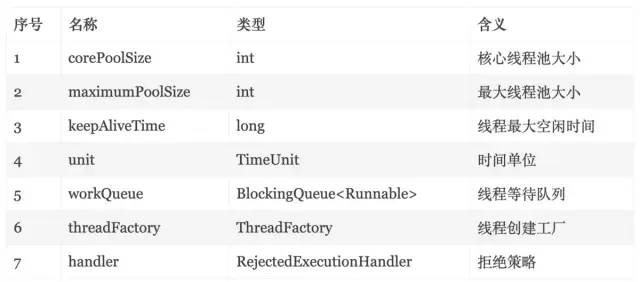
RejectedExecutionHandler
其中,RejectedExecutionHandler(拒绝策略)指的是当阻塞队列满了之后,线程数量也达到最大值,无法再接受新任务的时候,可以根据饱和策略对新任务作出相应的处理。原生JDK线程池提供了4种饱和策略:
AbortPolicy:直接抛出异常。
CallerRunsPolicy:只用调用者所在线程来运行任务。
DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
DiscardPolicy:不处理,丢弃掉
除此之外,我们还可以自定义饱和策略满足业务场景的需求,比如:
public class LogPolicy implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
if (!executor.isShutdown()) {
// 持久化不能处理的任务
insertToDB(r);
}
}
}
以上是ThreadPoolExecutor构造函数的参数详细解析和作用。
类图结构:
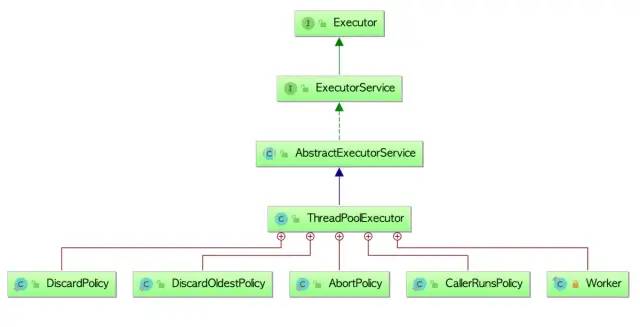
Executors的创建线程池的方法,创建出来的线程池都实现了ExecutorService接口。常用方法有以下几个:
newFiexedThreadPool(int Threads):创建固定数目线程的线程池。
newCachedThreadPool():创建一个可缓存的线程池,调用execute 将重用以前构造的线程(如果线程可用)。如果没有可用的线程,则创建一个新线程并添加到池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。
newSingleThreadExecutor()创建一个单线程化的Executor。
newScheduledThreadPool(int corePoolSize) 创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代Timer类。
类看起来功能还是比较强大的,又用到了工厂模式、又有比较强的扩展性,重要的是用起来还比较方便,如:
ExecutorService executor = Executors.newFixedThreadPool(nThreads) ;
即可创建一个固定大小的线程池。
执行原理
线程池执行器将会根据corePoolSize和maximumPoolSize自动地调整线程池大小。
当在execute(Runnable)方法中提交新任务并且少于corePoolSize线程正在运行时,即使其他工作线程处于空闲状态,也会创建一个新线程来处理该请求。如果有多于corePoolSize但小于maximumPoolSize线程正在运行,则仅当队列已满时才会创建新线程。通过设置corePoolSize和maximumPoolSize相同,您可以创建一个固定大小的线程池。通过将maximumPoolSize设置为基本上无界的值,例如Integer.MAX_VALUE,您可以允许池容纳任意数量的并发任务。通常,核心和最大池大小仅在构建时设置,但也可以使用setCorePoolSize和setMaximumPoolSize进行动态更改。
这段话详细了描述了线程池对任务的处理流程,这里用个图总结一下
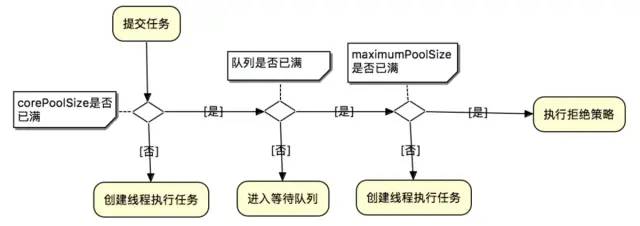
使用 Executors 创建四种类型的线程池
newCachedThreadPool是Executors工厂类的一个静态函数,用来创建一个可以无限扩大的线程池。
而Executors工厂类一共可以创建四种类型的线程池,通过Executors.newXXX即可创建。下面就分别都介绍一下。
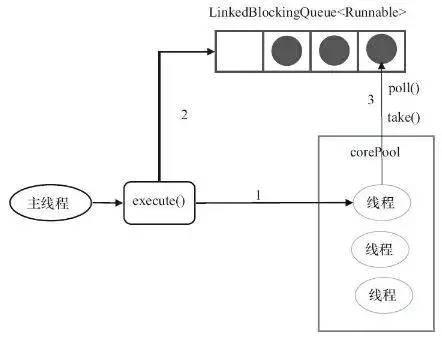
1. FixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads){
return new ThreadPoolExecutor(nThreads,nThreads,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
}
-
它是一种固定大小的线程池;
-
corePoolSize和maximunPoolSize都为用户设定的线程数量nThreads;
-
keepAliveTime为0,意味着一旦有多余的空闲线程,就会被立即停止掉;但这里keepAliveTime无效;
-
阻塞队列采用了LinkedBlockingQueue,它是一个无界队列;
-
由于阻塞队列是一个无界队列,因此永远不可能拒绝任务;
-
由于采用了无界队列,实际线程数量将永远维持在nThreads,因此maximumPoolSize和keepAliveTime将无效。
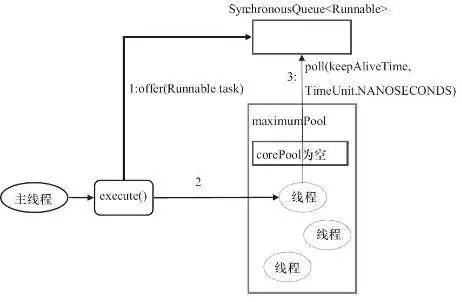
2. CachedThreadPool
public static ExecutorService newCachedThreadPool(){
return new ThreadPoolExecutor(0,Integer.MAX_VALUE,60L,TimeUnit.MILLISECONDS,new SynchronousQueue<Runnable>());
}
-
它是一个可以无限扩大的线程池;
-
它比较适合处理执行时间比较小的任务;
-
corePoolSize为0,maximumPoolSize为无限大,意味着线程数量可以无限大;
-
keepAliveTime为60S,意味着线程空闲时间超过60S就会被杀死;
-
采用SynchronousQueue装等待的任务,这个阻塞队列没有存储空间,这意味着只要有请求到来,就必须要找到一条工作线程处理他,如果当前没有空闲的线程,那么就会再创建一条新的线程。
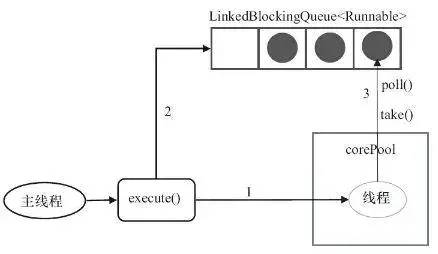
3. SingleThreadExecutor
public static ExecutorService newSingleThreadExecutor(){
return new ThreadPoolExecutor(1,1,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
}
-
它只会创建一条工作线程处理任务;
-
采用的阻塞队列为LinkedBlockingQueue;
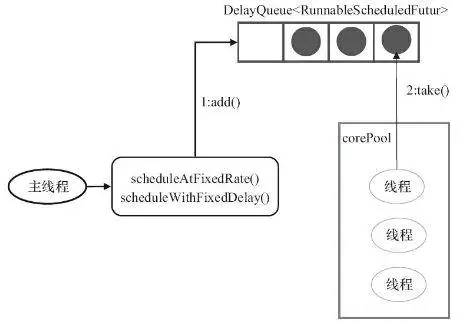
4. ScheduledThreadPool
它用来处理延时任务或定时任务。
-
它接收SchduledFutureTask类型的任务,有两种提交任务的方式:
-
scheduledAtFixedRate
-
scheduledWithFixedDelay
-
SchduledFutureTask接收的参数:
-
time:任务开始的时间
-
sequenceNumber:任务的序号
-
period:任务执行的时间间隔
-
它采用DelayQueue存储等待的任务
-
DelayQueue内部封装了一个PriorityQueue,它会根据time的先后时间排序,若time相同则根据sequenceNumber排序;
-
DelayQueue也是一个无界队列;
-
工作线程的执行过程:
-
工作线程会从DelayQueue取已经到期的任务去执行;
-
执行结束后重新设置任务的到期时间,再次放回DelayQueue
Executors存在什么问题
在阿里巴巴Java开发手册中提到,使用Executors创建线程池可能会导致OOM(OutOfMemory ,内存溢出),但是并没有说明为什么,那么接下来我们就来看一下到底为什么不允许使用Executors?
我们先来一个简单的例子,模拟一下使用Executors导致OOM的情况。
/**
* @author Hollis
*/
public class ExecutorsDemo {
private static ExecutorService executor = Executors.newFixedThreadPool(15);
public static void main(String[] args) {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executor.execute(new SubThread());
}
}
}
class SubThread implements Runnable {
@Override
public void run() {
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
//do nothing
}
}
}
通过指定JVM参数:-Xmx8m -Xms8m 运行以上代码,会抛出OOM:
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.util.concurrent.LinkedBlockingQueue.offer(LinkedBlockingQueue.java:416)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1371)
at com.hollis.ExecutorsDemo.main(ExecutorsDemo.java:16)
以上代码指出,ExecutorsDemo.java的第16行,就是代码中的executor.execute(new SubThread());。
Executors为什么存在缺陷
通过上面的例子,我们知道了Executors创建的线程池存在OOM的风险,那么到底是什么原因导致的呢?我们需要深入Executors的源码来分析一下。
其实,在上面的报错信息中,我们是可以看出蛛丝马迹的,在以上的代码中其实已经说了,真正的导致OOM的其实是LinkedBlockingQueue.offer方法。
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.util.concurrent.LinkedBlockingQueue.offer(LinkedBlockingQueue.java:416)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1371)
at com.hollis.ExecutorsDemo.main(ExecutorsDemo.java:16)
如果读者翻看代码的话,也可以发现,其实底层确实是通过LinkedBlockingQueue实现的:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
如果读者对Java中的阻塞队列有所了解的话,看到这里或许就能够明白原因了。
Java中的BlockingQueue主要有两种实现,分别是ArrayBlockingQueue 和 LinkedBlockingQueue。
ArrayBlockingQueue是一个用数组实现的有界阻塞队列,必须设置容量。
LinkedBlockingQueue是一个用链表实现的有界阻塞队列,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列,最大长度为Integer.MAX_VALUE。
这里的问题就出在:不设置的话,将是一个无边界的阻塞队列,最大长度为Integer.MAX_VALUE。也就是说,如果我们不设置LinkedBlockingQueue的容量的话,其默认容量将会是Integer.MAX_VALUE。
而newFixedThreadPool中创建LinkedBlockingQueue时,并未指定容量。此时,LinkedBlockingQueue就是一个无边界队列,对于一个无边界队列来说,是可以不断的向队列中加入任务的,这种情况下就有可能因为任务过多而导致内存溢出问题。
上面提到的问题主要体现在newFixedThreadPool和newSingleThreadExecutor两个工厂方法上,并不是说newCachedThreadPool和newScheduledThreadPool这两个方法就安全了,这两种方式创建的最大线程数可能是Integer.MAX_VALUE,而创建这么多线程,必然就有可能导致OOM。
创建线程池的正确姿势
避免使用Executors创建线程池,主要是避免使用其中的默认实现,那么我们可以自己直接调用ThreadPoolExecutor的构造函数来自己创建线程池。在创建的同时,给BlockQueue指定容量就可以了。
private static ExecutorService executor = new ThreadPoolExecutor(10, 10,
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue(10));
这种情况下,一旦提交的线程数超过当前可用线程数时,就会抛出java.util.concurrent.RejectedExecutionException,这是因为当前线程池使用的队列是有边界队列,队列已经满了便无法继续处理新的请求。但是异常(Exception)总比发生错误(Error)要好。
除了自己定义ThreadPoolExecutor外。还有其他方法。这个时候第一时间就应该想到开源类库,如apache和guava等。
作者推荐使用guava提供的ThreadFactoryBuilder来创建线程池。
public class ExecutorsDemo {
private static ThreadFactory namedThreadFactory = new ThreadFactoryBuilder()
.setNameFormat("demo-pool-%d").build();
private static ExecutorService pool = new ThreadPoolExecutor(5, 200,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(1024), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy());
public static void main(String[] args) {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
pool.execute(new SubThread());
}
}
}
通过上述方式创建线程时,不仅可以避免OOM的问题,还可以自定义线程名称,更加方便的出错的时候溯源。
参考资料
https://www.zhihu.com/question/23212914
https://www.zhihu.com/question/23212914/answer/245992718
https://www.jianshu.com/p/c41e942bcd64
https://www.jianshu.com/p/5c688d14188a
Kotlin开发者社区

专注分享 Java、 Kotlin、Spring/Spring Boot、MySQL、redis、neo4j、NoSQL、Android、JavaScript、React、Node、函数式编程、编程思想、"高可用,高性能,高实时"大型分布式系统架构设计主题。
High availability, high performance, high real-time large-scale distributed system architecture design 。
分布式框架:Zookeeper、分布式中间件框架等
分布式存储:GridFS、FastDFS、TFS、MemCache、redis等
分布式数据库:Cobar、tddl、Amoeba、Mycat
云计算、大数据、AI算法
虚拟化、云原生技术
分布式计算框架:MapReduce、Hadoop、Storm、Flink等
分布式通信机制:Dubbo、RPC调用、共享远程数据、消息队列等
消息队列MQ:Kafka、MetaQ,RocketMQ
怎样打造高可用系统:基于硬件、软件中间件、系统架构等一些典型方案的实现:HAProxy、基于Corosync+Pacemaker的高可用集群套件中间件系统
Mycat架构分布式演进
大数据Join背后的难题:数据、网络、内存和计算能力的矛盾和调和
Java分布式系统中的高性能难题:AIO,NIO,Netty还是自己开发框架?
高性能事件派发机制:线程池模型、Disruptor模型等等。。。
合抱之木,生于毫末;九层之台,起于垒土;千里之行,始于足下。不积跬步,无以至千里;不积小流,无以成江河。
正文到此结束
- 本文标签: sql IDE CTO 开发 src FAQ NIO 分布式 AIO 虚拟化 Hadoop 数据库 zookeeper redis 空间 参数 dist 线程池 executor Spring Boot JVM mysql 源码 安全 数据 时间 软件 build Architect cache id 架构设计 apache https apr 开发者 需求 value ThreadPoolExecutor ACE ORM Amoeba 专注 并发 ssh struct 阿里巴巴 UI 代码 消息队列 dubbo http Service MQ 模型 类图 java ip 集群 系统架构 多线程 解析 开源 ask 函数式编程 FastDFS 分布式系统 缓存 spring mina cat map Netty Android 总结 DDL JavaScript Haproxy 高可用 Proxy rmi db 线程 NOSQL 大数据 Disruptor 并发编程 core queue IO RocketMQ 拒绝策略 云 node
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

