图解分布式系统架构演进之路
| 编辑推荐: |
| 本文主要通过以下几个方面介绍单应用架构、应用服务器和数据服务器分离、应用服务器做集群、数据库读写分离、引入搜索引擎来查询、增加缓存等相关内容。 来自于博客园,,由火龙果软件Anna编辑、推荐。 |
0、介绍
以架构演变为主线,梳理了一下演变过程中出现的问题以及解决方案,文章中引用了这本书的一些内容和图片
分布式和集群的概念经常被搞混,现在一句话让你明白两者的区别。
分布式:一个业务拆分成多个子业务,部署在不同的服务器上
集群:同一个业务,部署在多个服务器上
例如:电商系统可以拆分成商品,订单,用户等子系统。这就是分布式,而为了应对并发,同时部署好几个用户系统,这就是集群
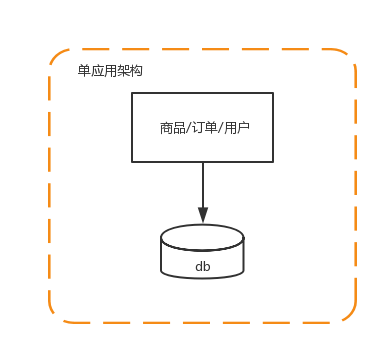
1、单应用架构
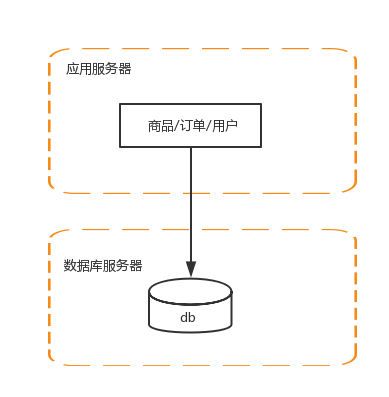
2、应用服务器和数据服务器分离
单机负载越来越来,所以要将应用服务器和数据库服务器分离
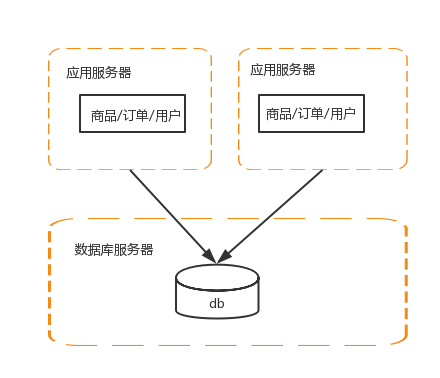
3、应用服务器做集群
每个系统的处理能力是有限的,为了提高并发访问量,需要对应用服务器做集群
这时会涉及到两个问题:
负载均衡
session共享
负载均衡就是将请求均衡地分配到多个系统上,常见的技术有如下几种
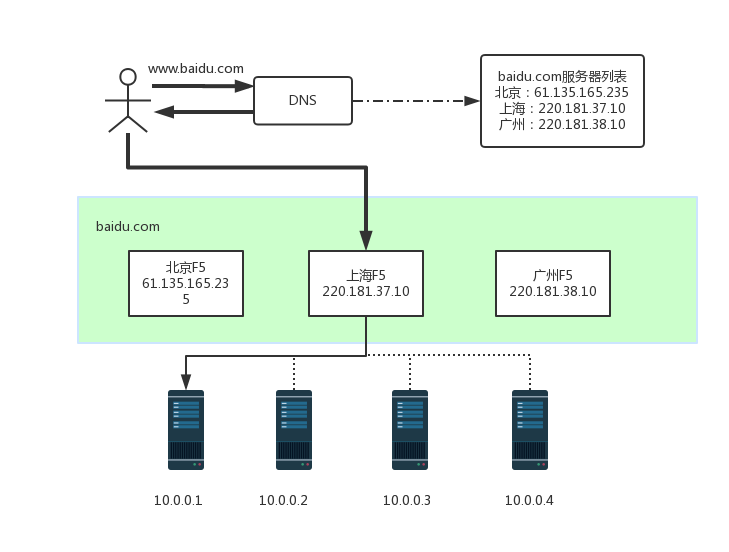
DNS
DNS是最简单也是最常见的负载均衡方式,一般用来实现地理级别的均衡。例如,北方的用户访问北京的机房,南方的用户访问广州的机房。一般不会使用DNS来做机器级别的负载均衡,因为太耗费IP资源了。例如,百度搜索可能要10000台以上的机器,不可能将这么多机器全部配置公网IP,然后用DNS来做负载均衡。
Nginx&LVS&F5
DNS是用于实现地理级别的负载均衡,而Nginx&LVS&F5用于同一地点内机器级别的负载均衡。其中Nginx是软件的7层负载均衡,LVS是内核的4层负载均衡,F5是硬件做4层负载均衡,性能从低到高位Nginx<LVS<F5

下图形象的展示了一个实际请求过程中,地理级别的负载均衡和机器级别的负载均衡是如何分工和结合的,其中粗线是地理级别的负载均衡,细线是机器级别的负载均衡,实线代表最终的路由路径
session共享
session共享就是用户在A服务器登录,结果查看购物车时,请求发送到了B服务器,因此用户的session存在A服务器上,所以当请求发送到B服务器上时,会认为用户没有登录
目前解决session跨域共享问题有如下几种方式
session sticky
将请求都落到同一个服务器上,如Nginx的url hash
session replication
session复制,每台服务器都保存一份相同的session
session 集中存储
存储在db、 存储在缓存服务器 (redis)
cookie (主流)
将信息存在加密后的cookie中
4、数据库读写分离
搭建数据库主从集群,实现数据库读写分离,改善数据库负载压力
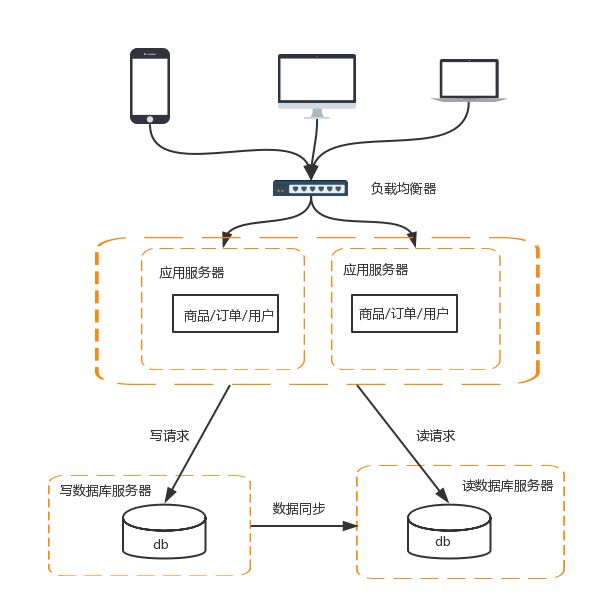
数据库读写分离的基本实现如下:
数据库服务器搭建主从集群,一主一从,一主多从都可以
数据库主机负责读写操作,从机只负责读操作
数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据
业务服务器将写操作分给数据库主机,将读操作分给数据库从机
实现方式
读写分离需要将读/写操作区分开来,然后访问不同的数据库服务器;分库分表需要根据不同的数据访问不同的数据库服务器,两者本质上都是一种分配机制,即将不同的SQL语句发送到不同的数据库服务器。
读写分离,包括后面要提到的分库分表的实现方式有两种:
程序代码封装
中间件封装
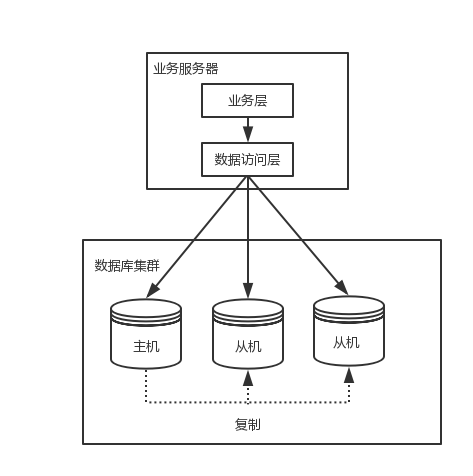
程序代码封装指在代码中抽象一个数据访问层来实现读写分离,分库分表
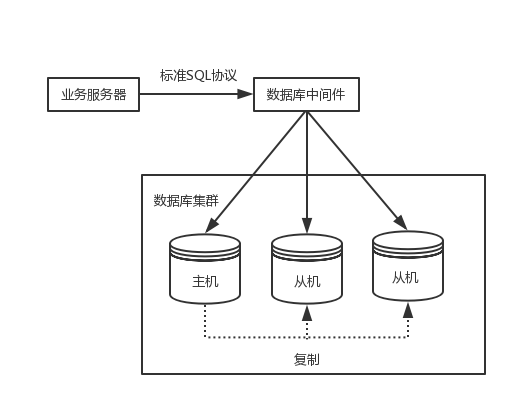
中间件封装指的是独立一套系统出来,实现读写分离和分库分表操作,如我们熟悉的MySQL Router和Mycat等
5、引入搜索引擎来查询
传统的关系型数据库通过索引来达到快速查询的目的,但是在全文搜索的业务场景下,索引也无能为力,主要体现在如下几点:
全文搜索的条件可以随意排列组合,如果通过索引来满足,则索引的数量会非常多
全文搜索的模糊匹配方式,索引无法满足,只能用like查询,而like查询是整表扫描,效率非常低
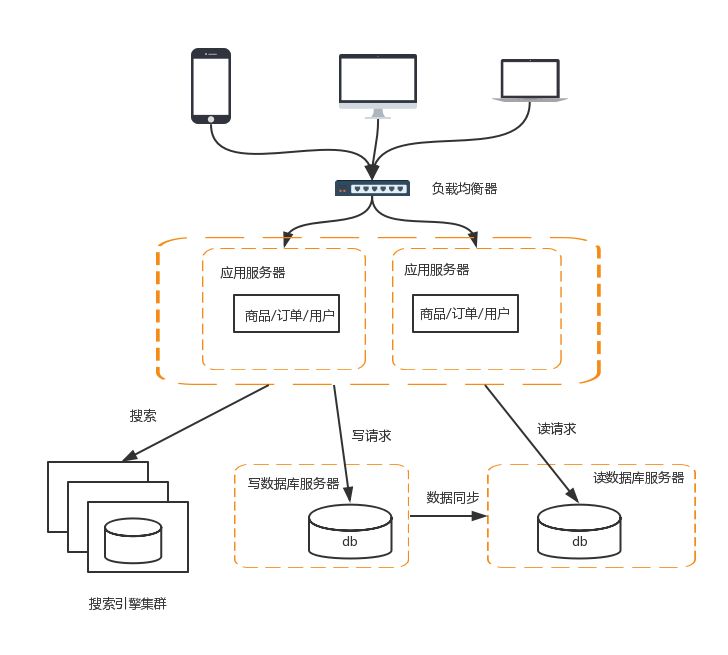
目前主要有Elasticsearch与Solr。Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
6、增加缓存
为了应对流量持续增加,必须增加缓存
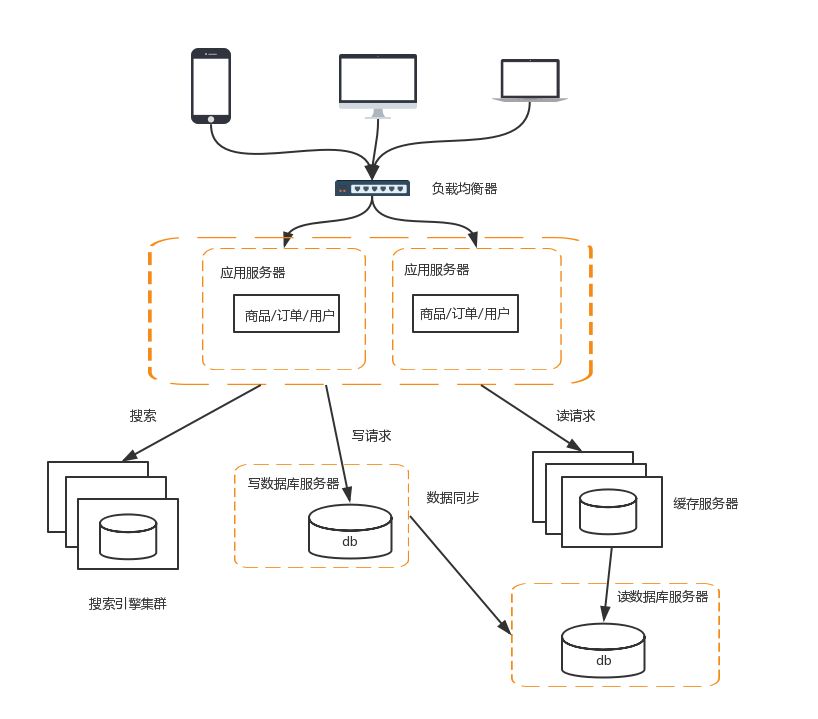
常见的方式有如下几种:
Redis与Memcached
以我们常见的Mybatis为例,很容易和Redis与Memcached整合起来,缓存已经查询过的SQL,因为Mybatis知道自己不擅长缓存,所以提供了接口让这些缓存工具进行整合
CDN
CDN是为了解决用户网络访问时的“最后一公里”效应,本质上是一种“以空间换空间”的加速策略,即将内容缓存在离用户最近的地方,用户访问的是缓存的内容,而不是站点实时的内容。
7、分库分表
读写分离分散了数据库读写操作的压力,但没有分散存储压力,当数据量达到千万甚至上亿条的时候,单台服务器的存储能力会成为系统的瓶颈。常见的分散存储的方法有分库和分表两大类
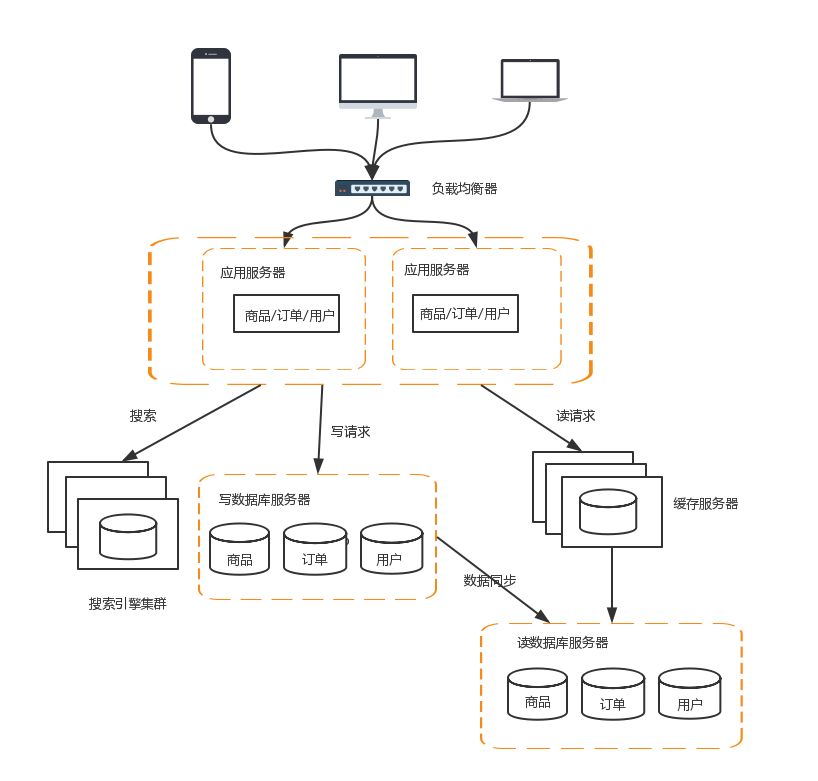
业务分库
业务分库指的是按照业务模块将数据分散到不同的数据库服务器。例如,一个简单的电商网站,包括商品,订单,用户三个业务模块,我们可以将商品数据,订单数据,用户数据,分开放到3台不同的数据库服务器上,而不是将所有数据都放在一台数据库服务器上
当然业务分库也会带来新的问题:
join操作问题:业务分库后,原本在同一个数据库中的表分散到不同数据库中,导致无法使用SQL的join查询
事务问题:原本在同一个数据库中不同的表可以在同一个事务中修改,业务分库后,表分散到不同数据库中,无法通过事务统一修改
成本问题:业务分库同时也带来了成本的代价,本来1台服务器搞定的事情,现在要3台,如果考虑备份,那就是2台变成6台
分表
表单数据拆分有两种方式,垂直分表和水平分表

垂直分表:垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。如上图的nickname和description字段不常用,就可以将这个字段独立到另外一张表中,这样在查询name时,就能带来一定的性能提升
水平分表:水平分表适合表行数特别大的表,如果单表行数超过5000万就必须进行分表,这个数字可以作为参考,但并不是绝对标准,关键还是要看表的访问性能
水平分表后,某条数据具体属于哪个切分后的子表,需要增加路由算法进行计算,常见的路由算法有
范围路由:选取有序的数据列(例如,整型,时间戳等)作为路由条件,不同分段分散到不同的数据库表中。以最常见的用户ID为例,路由算法可以按照1000000的范围大小进行分段,1-999999放到数据库1的表中,1000000-1999999放到数据库2的表中,以此类推
Hash路由:选取某个列(或者某几个列组合也可以)的值进行Hash运算,然后根据Hash结果分散到不同的数据库表中。同样以用户Id为例,假如我们一开始就规划了10个数据库表,路由算法可以简单地用user_id%10的值来表示数据所属的数据库表编号,ID为985的用户放到编号为5的子表中,ID为10086的用户放到编号为6的子表中。
配置路由:配置路由就是路由表,用一张独立的表来记录路由信息,同样以用户ID为例,我们新增一张user_router表,这个表包含user_id和table_id两列,根据user_id就可以查询对应的table_id
8、应用拆分/微服务
随着业务的发展,业务越来越多,应用的压力越来越大。工程规模也越来越庞大。这个时候就可以考虑将应用拆分,按照领域模型将我们的商品,订单,用户分拆成子系统。
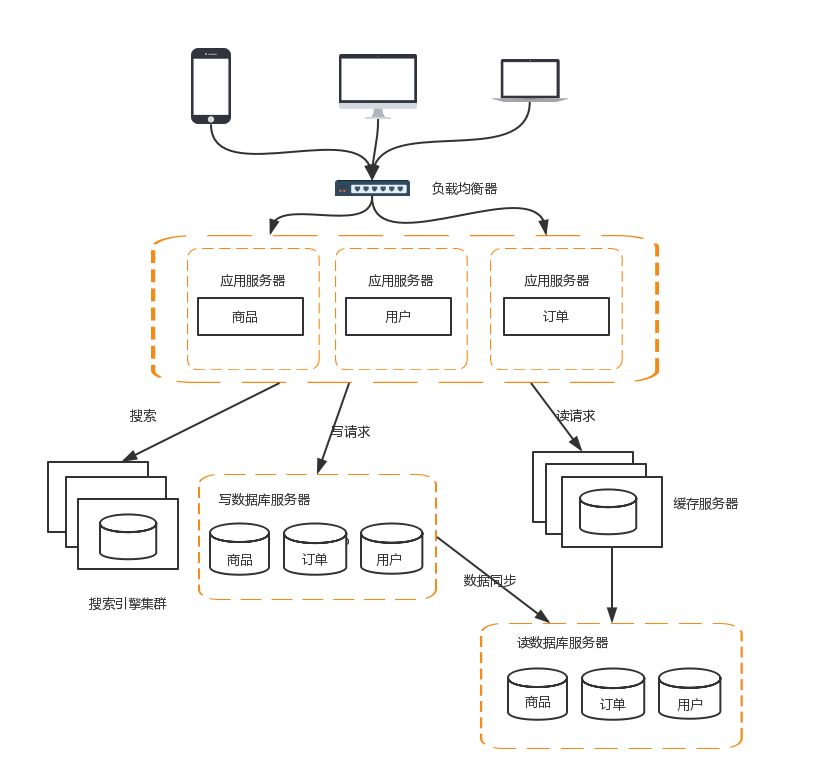
这样拆分以后,可能会有一些相同的代码,比如订单模块有对用户数据的查询,用户模块中肯定也有对用户数据的查询。这些相同的代码和模块一定要抽象出来。这样有利于维护和管理。这时可以将模块变为一个个服务,模块之间互相调用来获取数据,系统就变成一个微服务了。
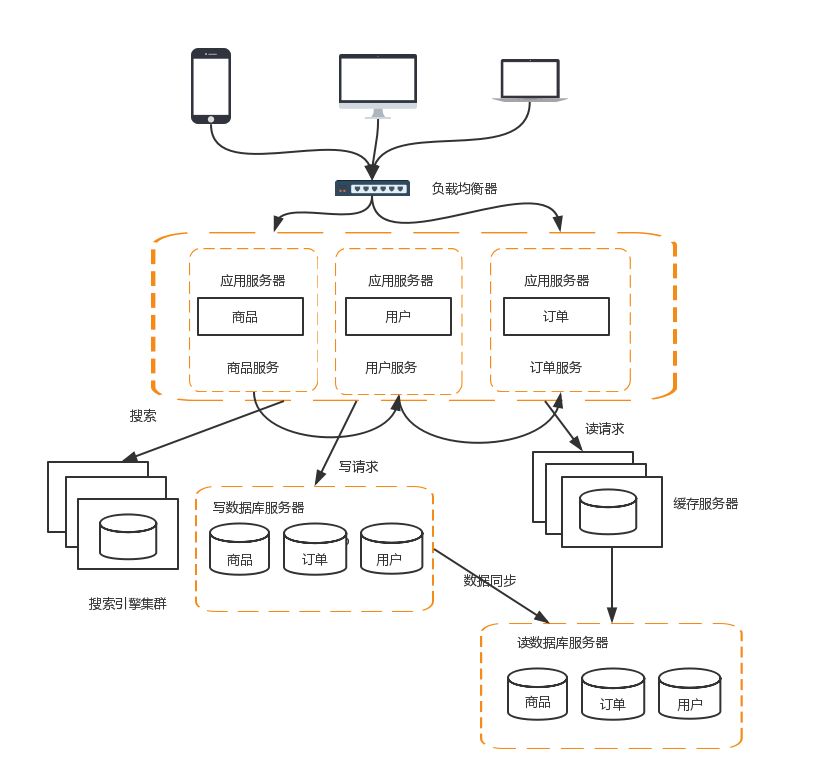
服务拆分以后,服务之间的通信可以通过RPC技术,比较典型的有:Webservice、Hessian、HTTP、RMI等。如当前的Dubbo和Spring Cloud都是目前比较流行的微服务框架。
正文到此结束
- 本文标签: 本质 部署 备份 DNS 网站 redis 电商网站 公网IP WebService 模型 加密 Nginx js cat 数据 mybatis 主机 IO 分布式系统 并发 web https 压力 UI 软件 src 图片 Elasticsearch 微服务 spring ip 数据库 系统架构 架构演进 solr cache 高并发 缓存 rmi db description 配置 空间 同步 Service 索引 mysql tab sql 时间 dubbo 文章 分布式 session 服务器 CDN 集群 代码 博客 id Spring cloud 站点 负载均衡 搜索引擎 管理 百度 http 应用架构
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

