图解Java常用数据结构
[TOC]
转载地址: https://cloud.tencent.com/developer/article/1176391
常用数据结构
最近在整理数据结构方面的知识, 系统化看了下Java中常用数据结构, 突发奇想用动画来绘制数据流转过程.主要基于jdk8, 可能会有些特性与jdk7之前不相同, 例如LinkedList LinkedHashMap中的双向列表不再是回环的.HashMap中的单链表是尾插, 而不是头插入等等, 后文不再赘叙这些差异, 本文目录结构如下:
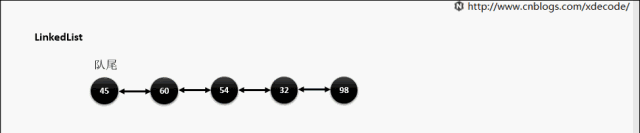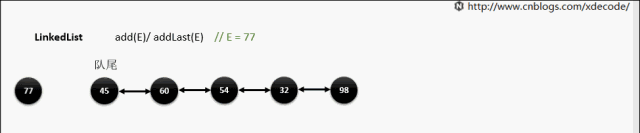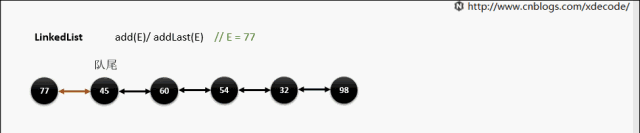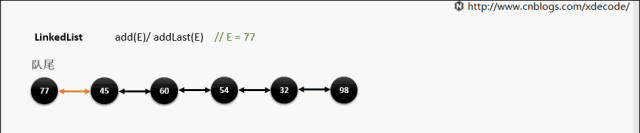
LinkedList
经典的双链表结构, 适用于乱序插入, 删除. 指定序列操作则性能不如ArrayList, 这也是其数据结构决定的.
add(E) / addLast(E)
add(index, E)
这边有个小的优化, 他会先判断index是靠近队头还是队尾, 来确定从哪个方向遍历链入.
1 if (index < (size >> 1)) {
2 Node<E> x = first;
3 for (int i = 0; i < index; i++)
4 x = x.next;
5 return x;
6 } else {
7 Node<E> x = last;
8 for (int i = size - 1; i > index; i--)
9 x = x.prev;
10 return x;
11 }

靠队尾

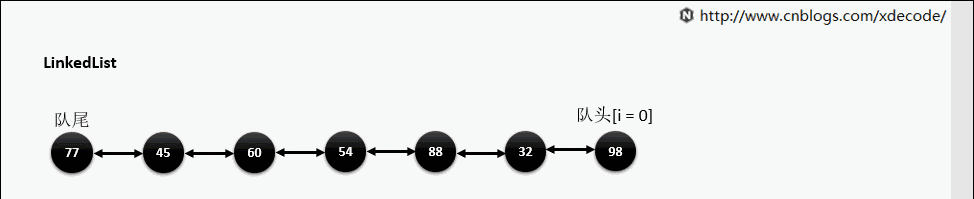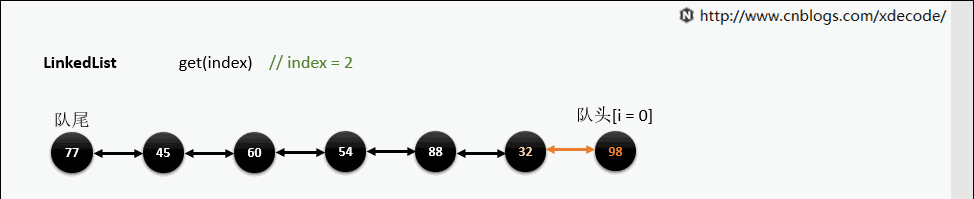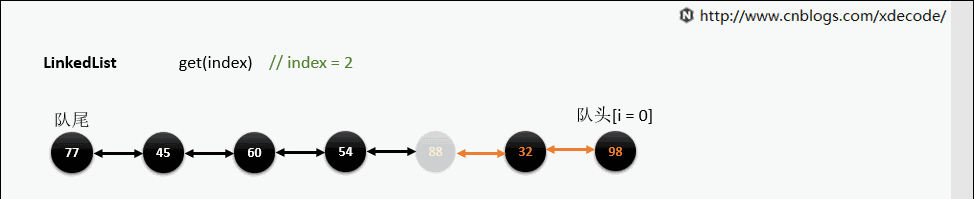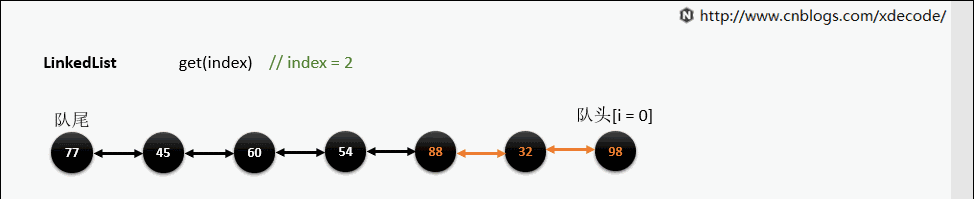
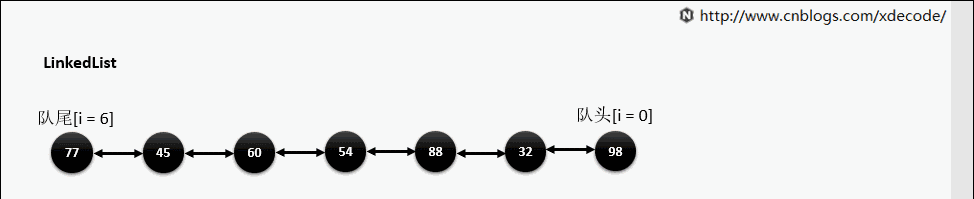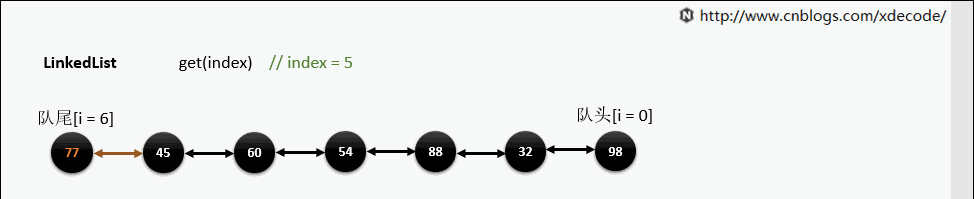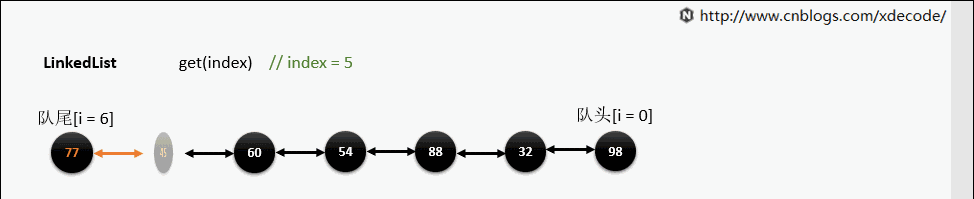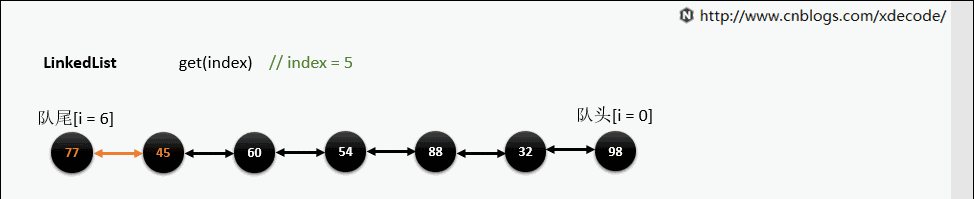
get(index)
也是会先判断index, 不过性能依然不好, 这也是为什么 不推荐用for(int i = 0; i < lengh; i++)的方式遍历linkedlist , 而是使用iterator的方式遍历.
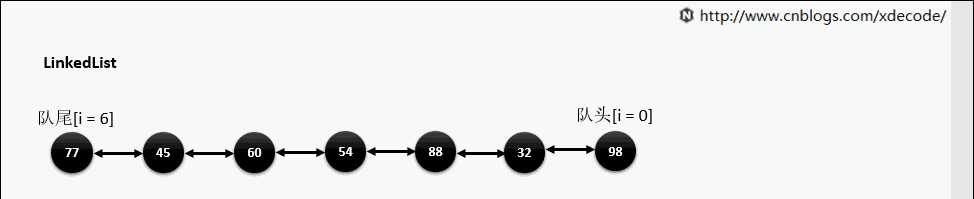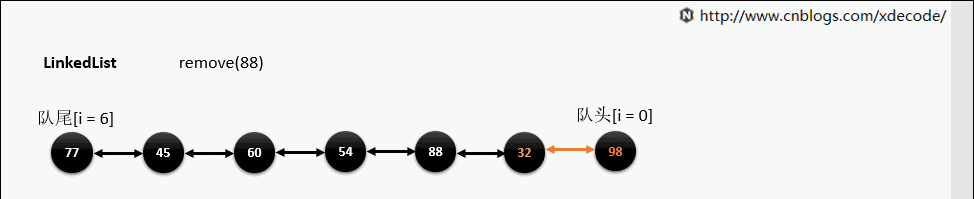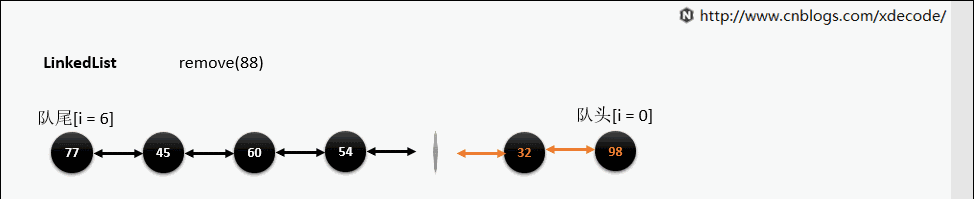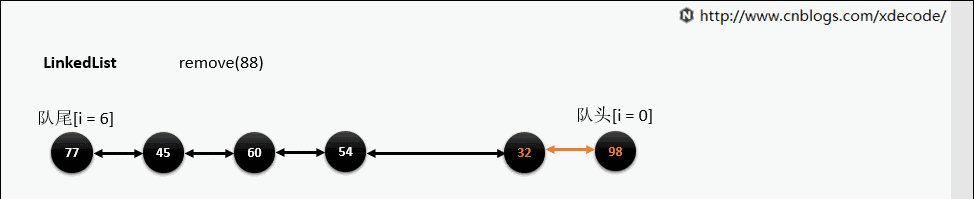
remove(E)
ArrayList
底层就是一个数组, 因此按序查找快, 乱序插入, 删除因为涉及到后面元素移位所以性能慢.
add(index, E)
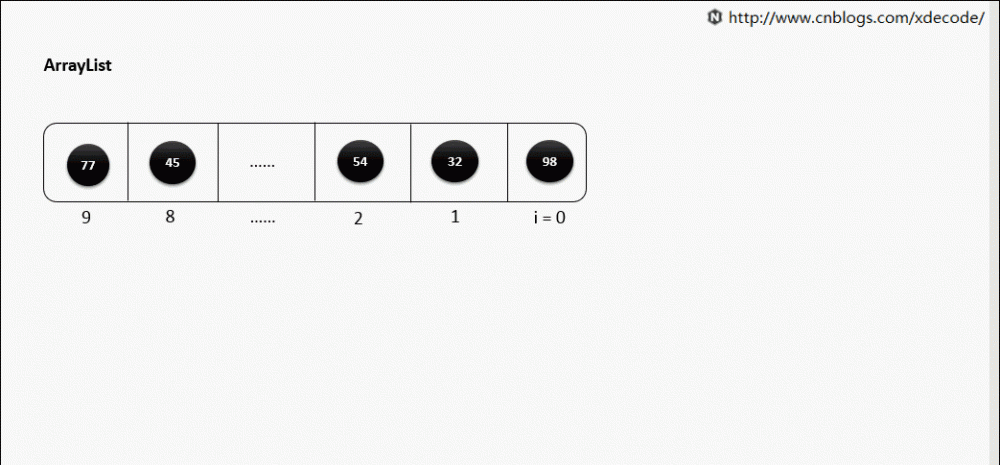
扩容
一般默认容量是10, 扩容后, 会length*1.5.
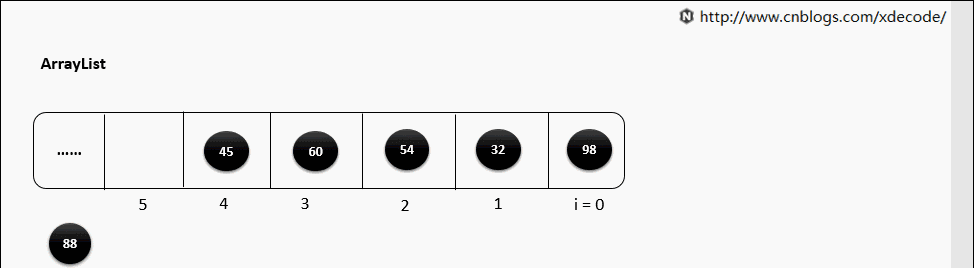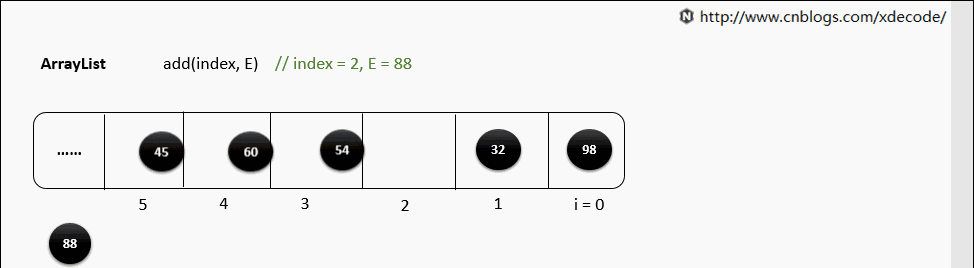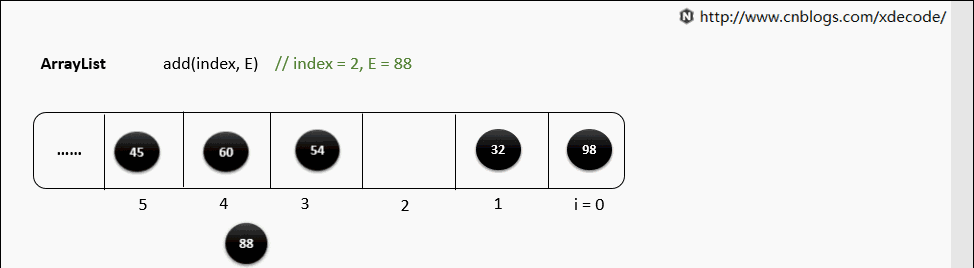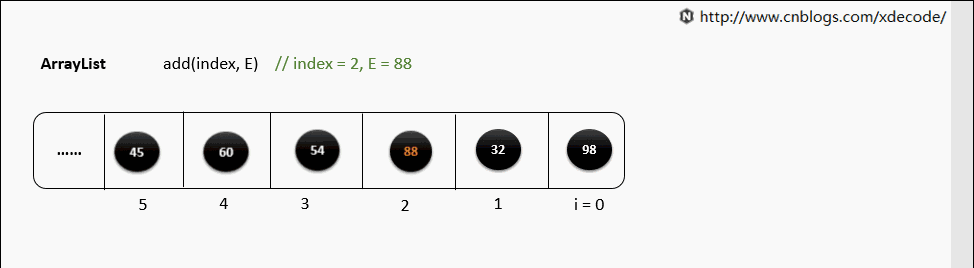
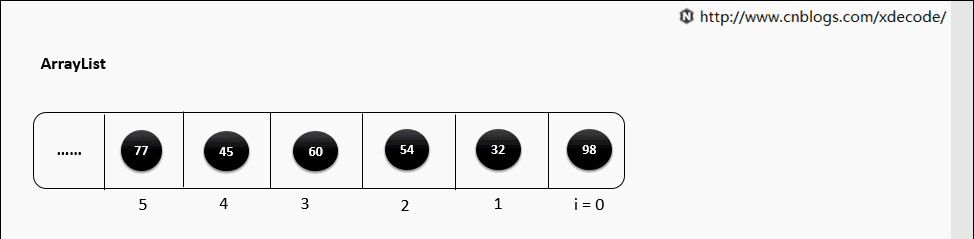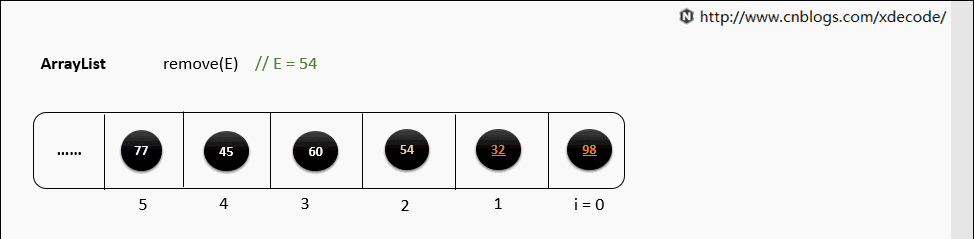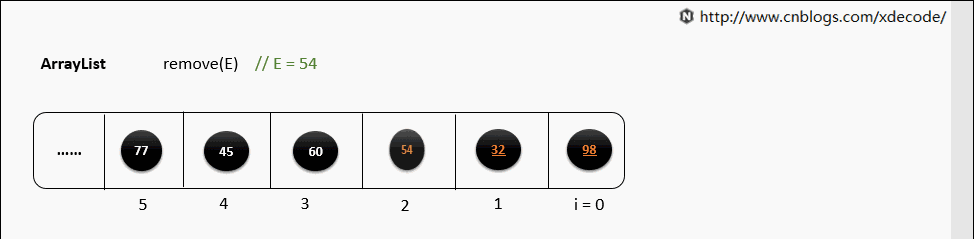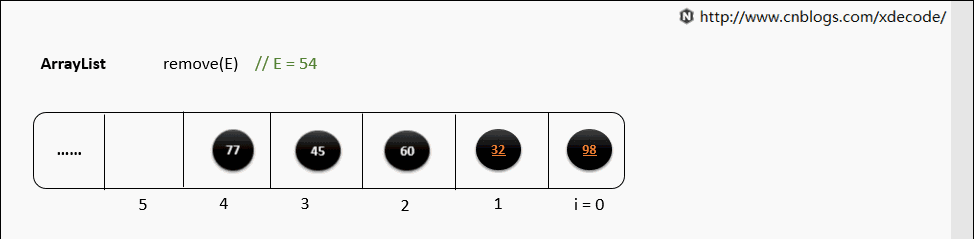
remove(E)
循环遍历数组, 判断E是否equals当前元素, 删除性能不如LinkedList.
Stack
经典的数据结构, 底层也是数组, 继承自Vector, 先进后出FILO, 默认new Stack()容量为10, 超出自动扩容.
push(E)

pop()

后缀表达式
Stack的一个典型应用就是计算表达式如 9 + (3 - 1) * 3 + 10 / 2, 计算机将中缀表达式转为后缀表达式, 再对后缀表达式进行计算.
中缀转后缀
- 数字直接输出
- 栈为空时,遇到运算符,直接入栈
- 遇到左括号, 将其入栈
- 遇到右括号, 执行出栈操作,并将出栈的元素输出,直到弹出栈的是左括号,左括号不输出。
- 遇到运算符(加减乘除):弹出所有优先级大于或者等于该运算符的栈顶元素,然后将该运算符入栈
- 最终将栈中的元素依次出栈,输出。

计算后缀表达
- 遇到数字时,将数字压入堆栈
- 遇到运算符时,弹出栈顶的两个数,用运算符对它们做相应的计算, 并将结果入栈
- 重复上述过程直到表达式最右端
- 运算得出的值即为表达式的结果

队列
与Stack的区别在于, Stack的删除与添加都在队尾进行, 而Queue删除在队头, 添加在队尾.
ArrayBlockingQueue
生产消费者中常用的阻塞有界队列, FIFO.
put(E)
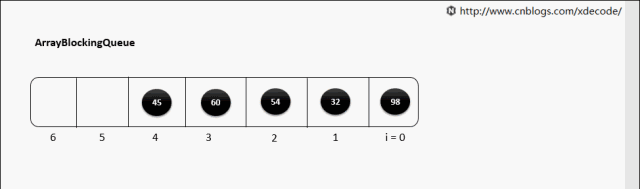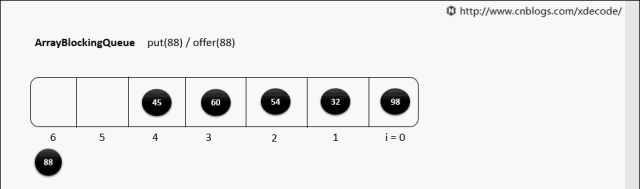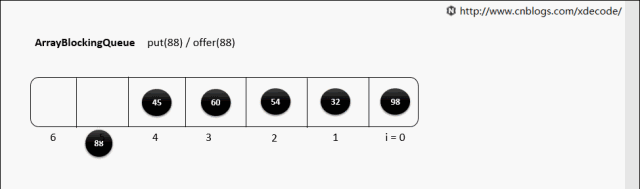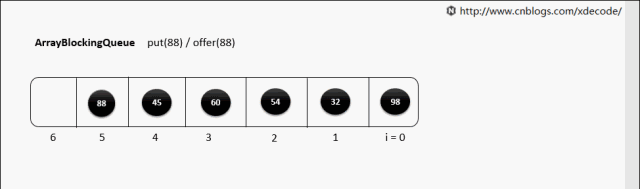
put(E) 队列满了
1 final ReentrantLock lock = this.lock;
2 lock.lockInterruptibly();
3 try {
4 while (count == items.length)
5 notFull.await();
6 enqueue(e);
7 } finally {
8 lock.unlock();
9 }

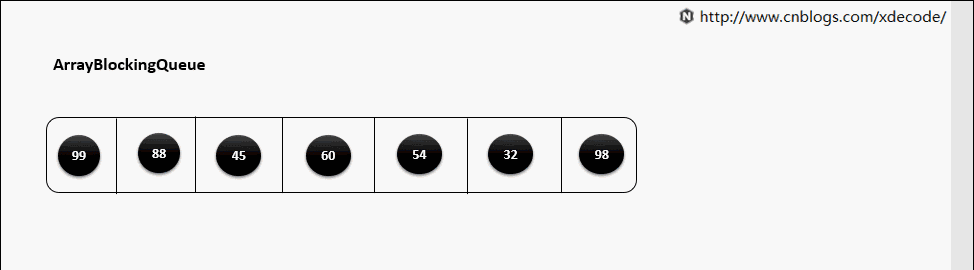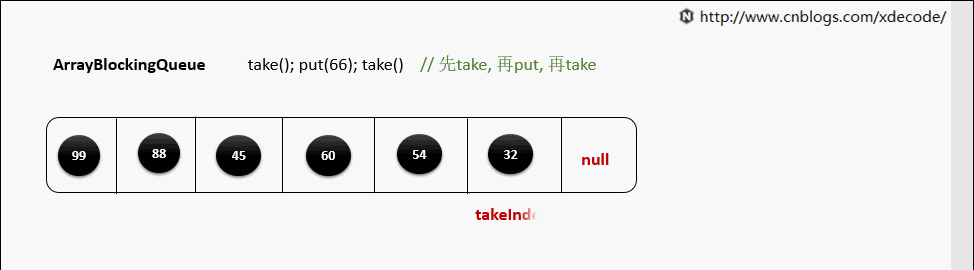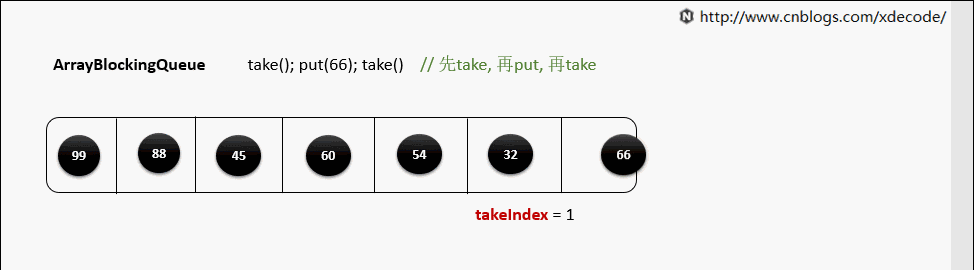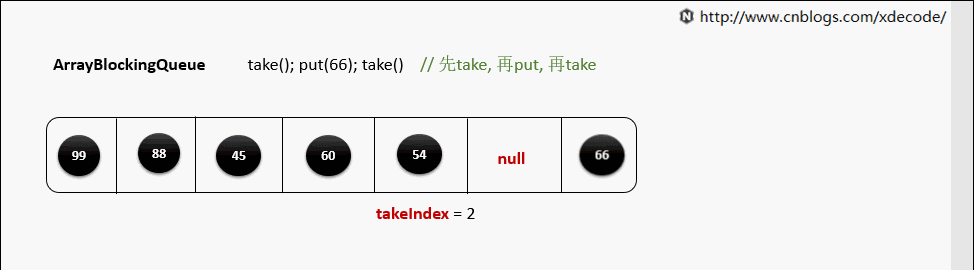
take()
当元素被取出后, 并没有对数组后面的元素位移, 而是更新takeIndex来指向下一个元素.
takeIndex是一个环形的增长, 当移动到队列尾部时, 会指向0, 再次循环.
1 private E dequeue() {
2 // assert lock.getHoldCount() == 1;
3 // assert items[takeIndex] != null;
4 final Object[] items = this.items;
5 @SuppressWarnings("unchecked")
6 E x = (E) items[takeIndex];
7 items[takeIndex] = null;
8 if (++takeIndex == items.length)
9 takeIndex = 0;
10 count--;
11 if (itrs != null)
12 itrs.elementDequeued();
13 notFull.signal();
14 return x;
15 }
HashMap
最常用的哈希表, 面试的童鞋必备知识了, 内部通过数组 + 单链表的方式实现. jdk8中引入了红黑树对长度 > 8的链表进行优化, 我们另外篇幅再讲.
put(K, V)
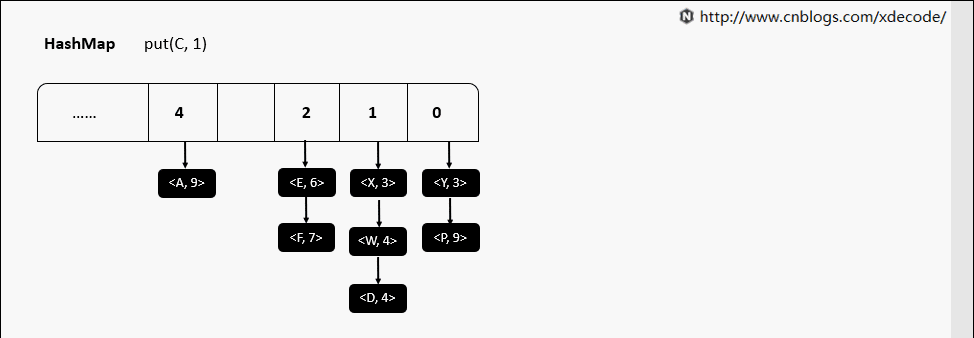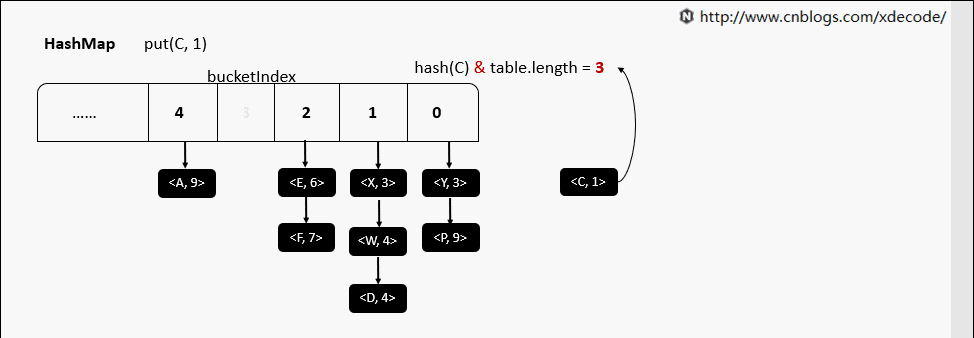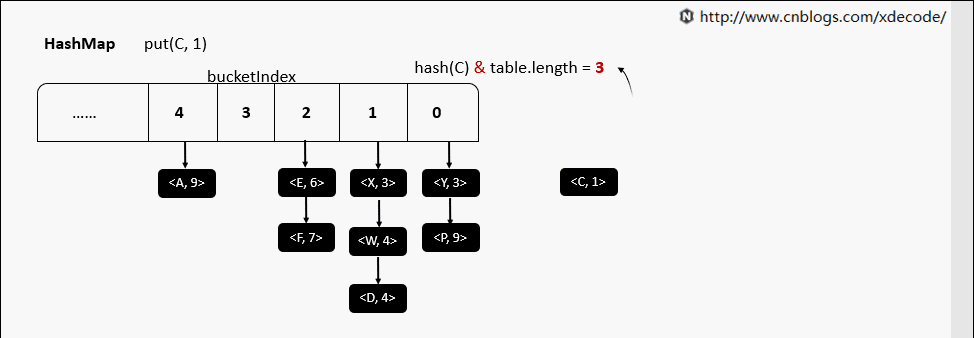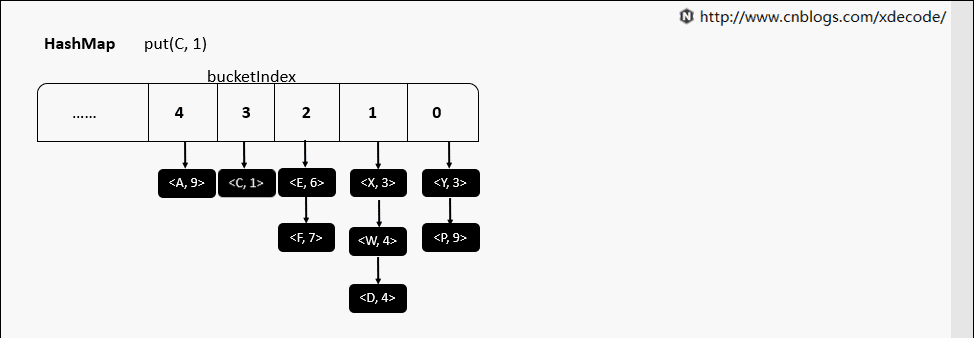
put(K, V) 相同hash值
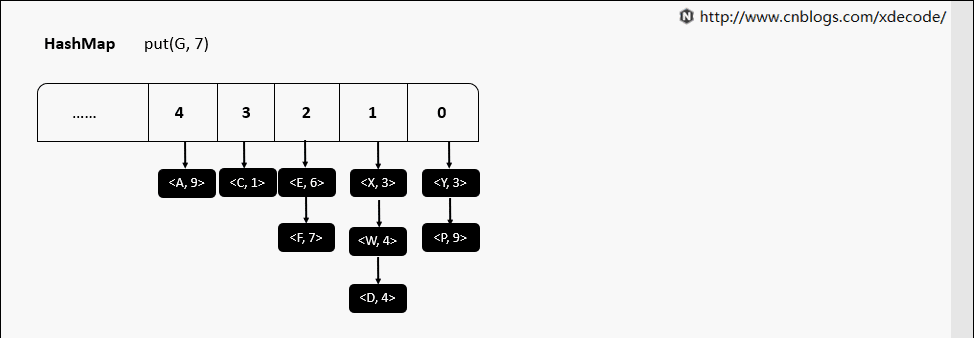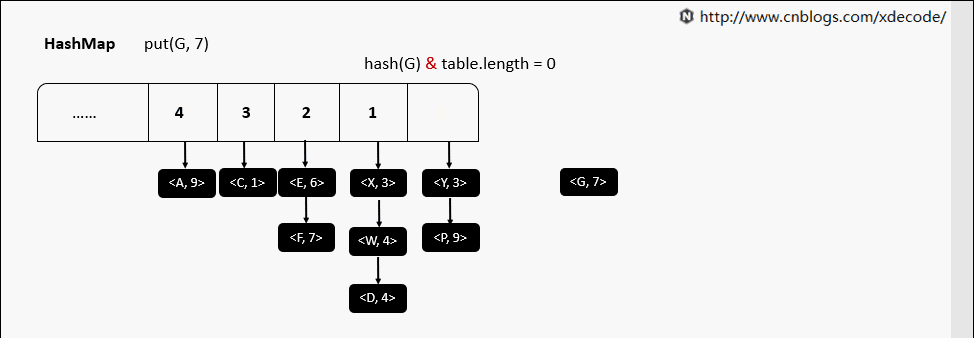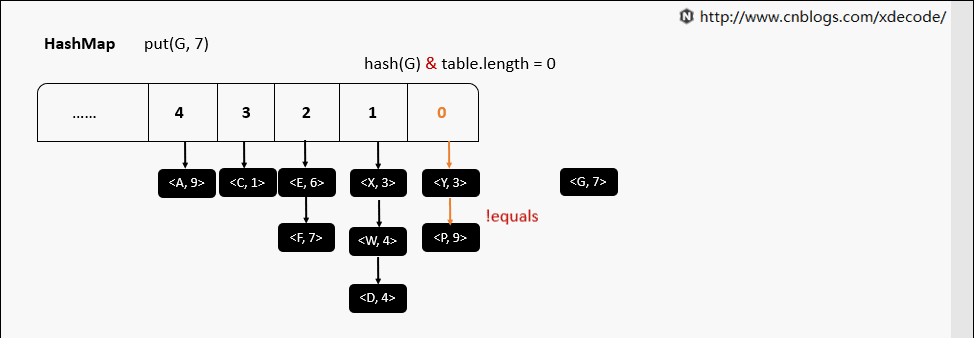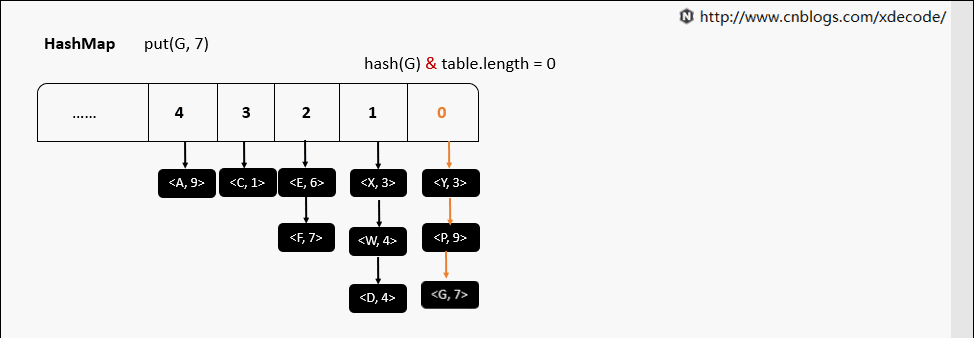
resize 动态扩容
当map中元素超出设定的阈值后, 会进行resize (length * 2)操作, 扩容过程中对元素一通操作, 并放置到新的位置.具体操作如下:
- 在jdk7中对所有元素直接rehash, 并放到新的位置.
- 在jdk8中判断元素原hash值新增的bit位是0还是1, 0则索引不变, 1则索引变成”原索引 + oldTable.length”.
1 //定义两条链
2 //原来的hash值新增的bit为0的链,头部和尾部
3 Node<K,V> loHead = null, loTail = null;
4 //原来的hash值新增的bit为1的链,头部和尾部
5 Node<K,V> hiHead = null, hiTail = null;
6 Node<K,V> next;
7 //循环遍历出链条链
8 do {
9 next = e.next;
10 if ((e.hash & oldCap) == 0) {
11 if (loTail == null)
12 loHead = e;
13 else
14 loTail.next = e;
15 loTail = e;
16 }
17 else {
18 if (hiTail == null)
19 hiHead = e;
20 else
21 hiTail.next = e;
22 hiTail = e;
23 }
24 } while ((e = next) != null);
25 //扩容前后位置不变的链
26 if (loTail != null) {
27 loTail.next = null;
28 newTab[j] = loHead;
29 }
30 //扩容后位置加上原数组长度的链
31 if (hiTail != null) {
32 hiTail.next = null;
33 newTab[j + oldCap] = hiHead;
34 }

LinkedHashMap
继承自HashMap, 底层额外维护了一个双向链表来维持数据有序. 可以通过设置accessOrder来实现FIFO(插入有序)或者LRU(访问有序)缓存.
put(K, V)
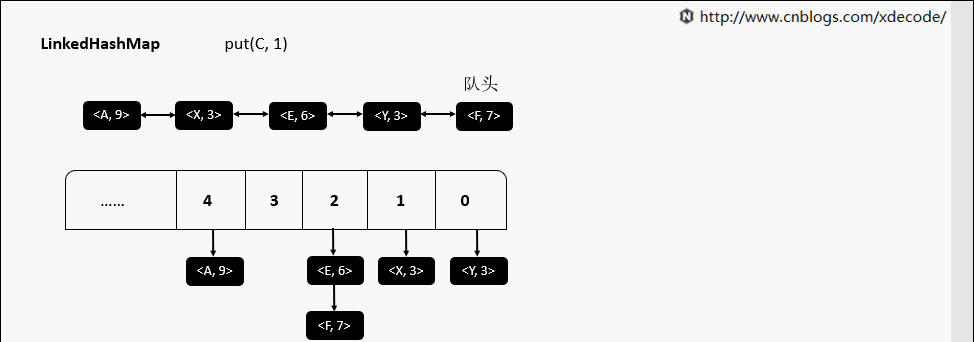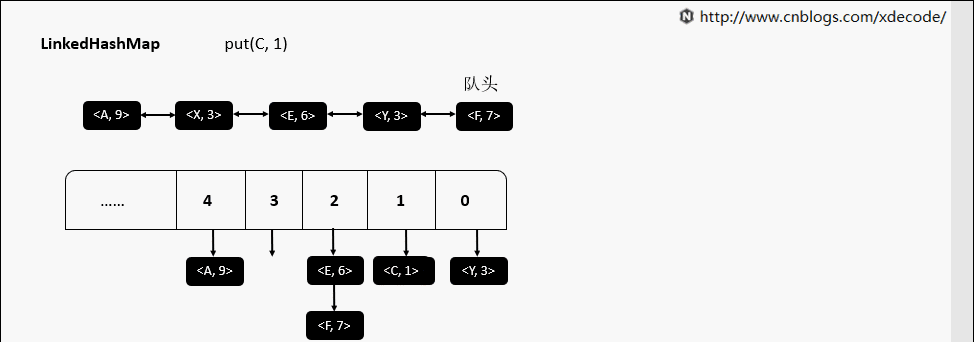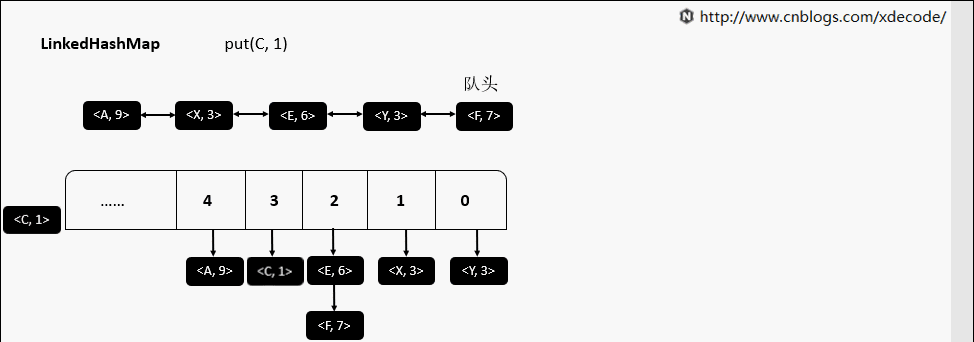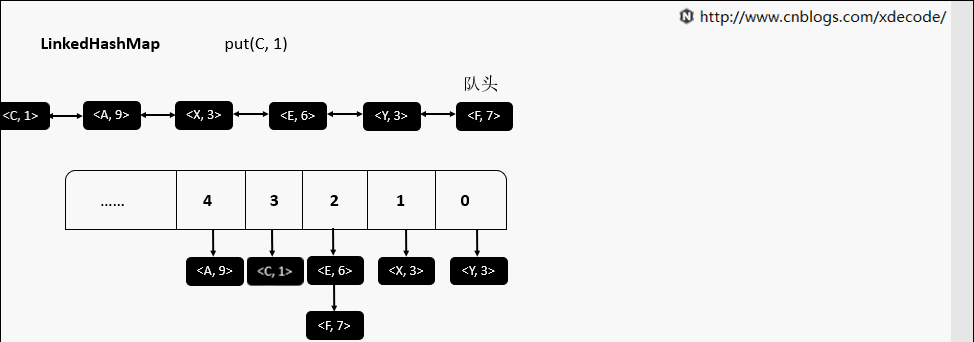
get(K)
accessOrder为false的时候, 直接返回元素就行了, 不需要调整位置.
accessOrder为true的时候, 需要将最近访问的元素, 放置到队尾.
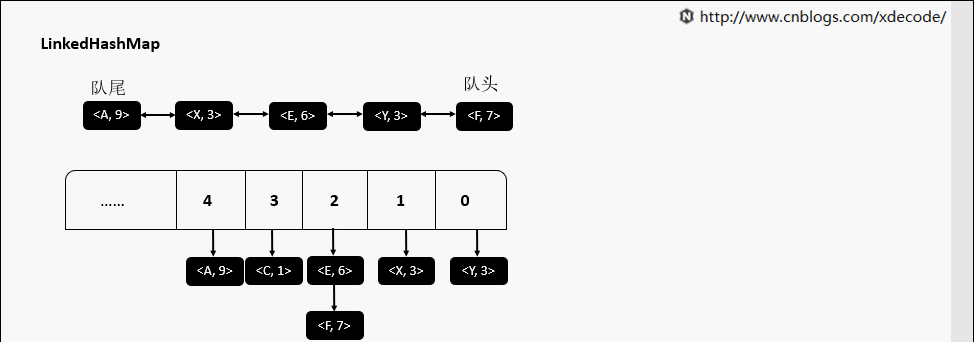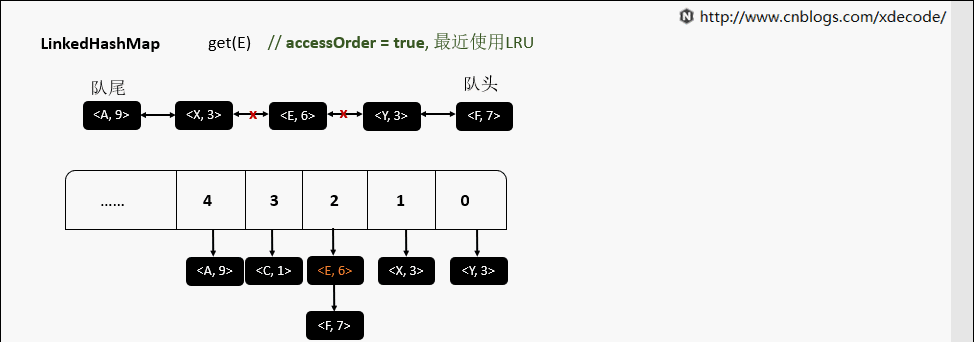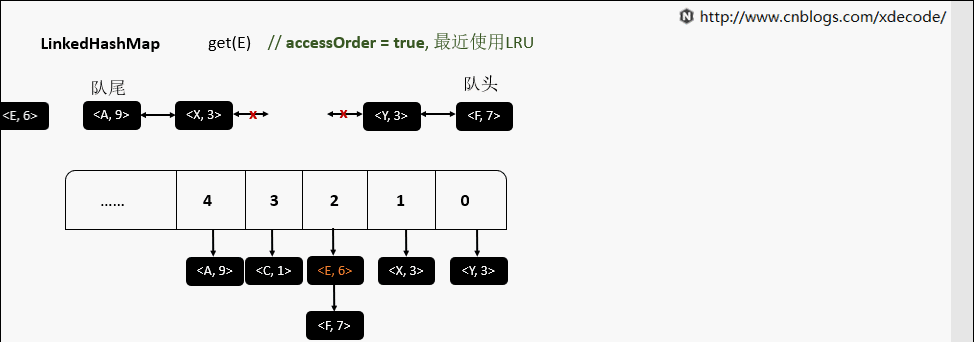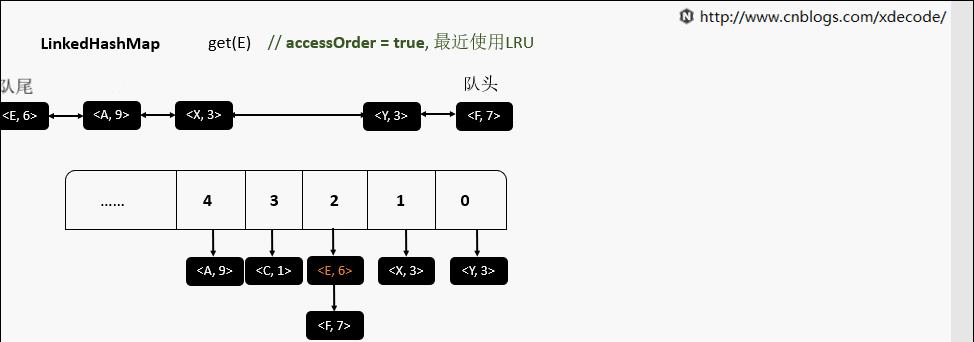
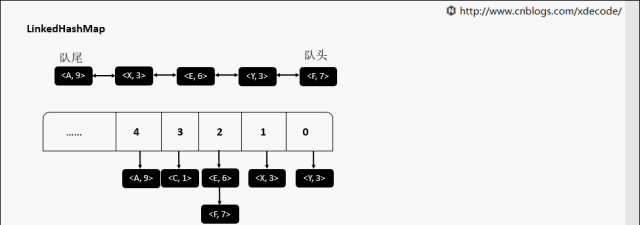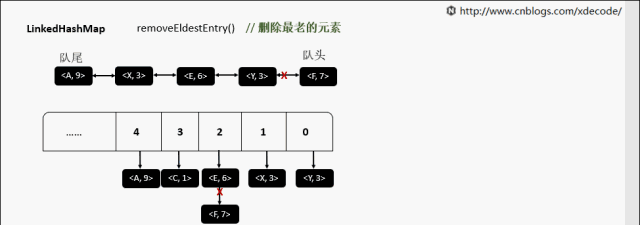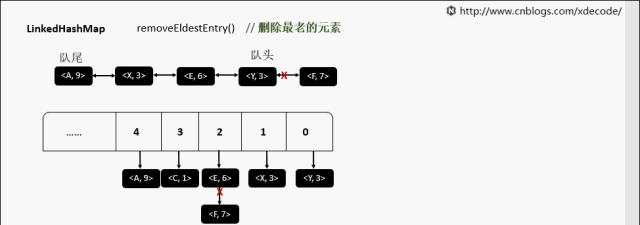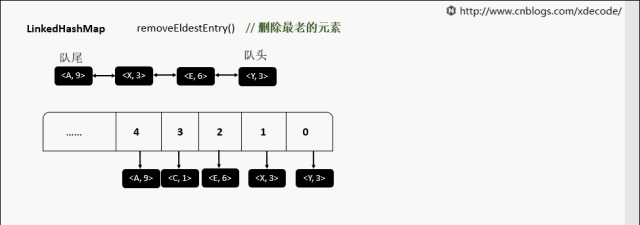
removeEldestEntry 删除最老的元素
集合类相关总结
转载: https://www.jianshu.com/p/0c2d5376fae9
转载: https://blog.csdn.net/u011497622/article/details/81284192
Collection ├─List │ ├─ArrayList │ ├─LinkedList │ ├─Vector │ ├─Set │ ├─HashSet │ ├─TreeSet Map ├─HashMap ├─TreeMap ├─LinkedHashMap ├─ConcurrentHashMap
| 类 | 说明 |
|---|---|
| List | 可存储相同的值(确切讲是a.equals(b)时,二者都可存储)。我们会挑选适宜连续存储的ArrayList和链式存储的LinkedList进行介绍。 |
| Set | 不可存储相同值。挑选线程不安全的HashSet和线程安全的ConcurrentHashSet进行介绍。 |
| Map | 存储key-value形式的数据。挑选线程不安全的HashMap和线程安全的ConcurrentHashMap进行介绍。 |
List
| 类 | 说明 | 说明 |
|---|---|---|
| ArrayList | 使用数组进行缓存,好处的遍历快,缺点的插入/删除中间元素比较慢 | |
| LinkedList | 使用双链表的结构,LinkedList是双向链表,即同时保有前驱节点和后驱节点,支持正向遍历和反向遍历。 | ArrayList和LinkedList比较**分析,中间插入元素LinkedList较好,因为 ArrayList 使用数组,是连续的内存,所以遍历会比较快。 |
| Vector | Vector**的数据结果和实现跟ArrayList差不多,主要的区别是操作数据的方法都加了synchronized关键字修饰,它是线程安全的,也牺牲了些性能,慎用。 |
Map
| 类 | 说明 | |
|---|---|---|
| LinkedHashMap | LinkedHashMap**继承了HashMap,数据结果和HashMap一样,但增加了双向列表的结果,用来记录插入的顺序,结果如下 | |
| TreeMap | 使用红-黑树结果,具有元素排序功能 | |
| ConcurrentHashMap | ConcurrentHashMap是线程安全的HashMap,在JDK8中,ConcurrentHashMap为进一步优化多线程下的并发性能,不再采用分段锁对分桶进行保护,而是采用CAS操作(Compare And Set)。这个改变在思想上很像是乐观锁与悲观锁。 | 在JDK8之前,ConcurrentHashMap采用分段锁的方式来保证线程安全性,相对于CAS操作,量级更重一些,因为需要做加锁、解锁操作。这很类似于悲观锁的思想,即假设多线程并发操作临界资源的几率比较大,因此采用加锁的方式来应对。 |
SET
| 类 | 说明 | |
|---|---|---|
| HashSet | 使用HashMap来保存对象 | |
| TreeSet | 默认使用TreeMap的key来保存元素,具有排序功能 | |
正文到此结束
- 本文标签: https SDN final IO LinkedList git 多线程 锁 queue 索引 node 数据 list 删除 ConcurrentHashMap HashSet tab UI value http HashMap 并发 java map key DDL 集合类 缓存 目录 安全 遍历 src id synchronized 线程 CTO Developer MQ equals GitHub 总结 Collection ArrayList
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

