有关 HashMap 面试会问的一切
前言
HashMap 是无论在工作还是面试中都非常常见常考的数据结构。
比如 Leetcode 第一题 Two Sum 的某种变种的最优解就是需要用到 HashMap 的,高频考题 LRU Cache 是需要用到 LinkedHashMap 的。
HashMap 用起来很简单,底层实现也不复杂,先来看几道常见的面试题吧。相信大家多多少少都能回答上来一点,不清楚的地方就仔细阅读本文啦~这篇文章带你深挖到 HashMap 的老祖宗,保证吊打面试官
- == 和 equals() 的区别?
- 为什么重写 equals() 就必须要重写 hashCode()?
- Hashtable, HashSet 和 HashMap 的区别和联系
- 处理 hash 冲突有哪些方法?Java 中用的哪一种?为什么?另一种方法你在工作中用过吗?在什么情 况下用得多?
- 徒手实现一个 HashMap 吧
本文分以下章节:
- Set 和 Map 家族简介
- HashMap 实现原理
- 关于 hashCode() 和 equals()
- 哈希冲突详解
- HashMap 基本操作
- 高频面试考题分析
Set 家族
在讲 Map 之前,我们先来看看 Set。
集合的概念我们初中数学就学过了,就是里面不能有重复元素,这里也是一样。
Set 在 Java 中是一个接口,可以看到它是 java.util 包中的一个集合框架类,具体的实现类有很多:
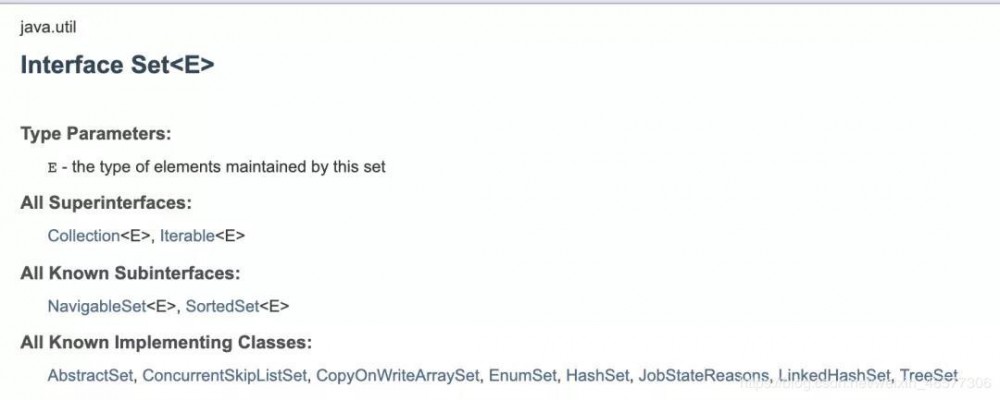
其中比较常用的有三种:
HashSet: 采用 Hashmap 的 key 来储存元素,主要特点是无序的,基本操作都是 O(1) 的时间复杂度,很快。
LinkedHashSet: 这个是一个 HashSet + LinkedList 的结构,特点就是既拥有了 O(1) 的时间复杂度,又能够保留插入的顺序。
TreeSet: 采用红黑树结构,特点是可以有序,可以用自然排序或者自定义比较器来排序;缺点就是查询速度没有 HashSet 快。
Map 家族
Map 是一个键值对 (Key - Value pairs),其中 key 是不可以重复的,毕竟 set 中的 key 要存在这里面。
那么与 Set 相对应的,Map 也有这三个实现类:
HashMap: 与 HashSet 对应,也是无序的,O(1)。
LinkedHashMap: 这是一个「HashMap + 双向链表」的结构,落脚点是 HashMap,所以既拥有 HashMap 的所有特性还能有顺序。
TreeMap: 是有序的,本质是用二叉搜索树来实现的。
HashMap 实现原理
对于 HashMap 中的每个 key,首先通过 hash function 计算出一个 hash 值,这个hash值就代表了在 buckets 里的编号,而 buckets 实际上是用数组来实现的,所以把这个数值模上数组的长度得到它在数组的 index,就这样把它放在了数组里。
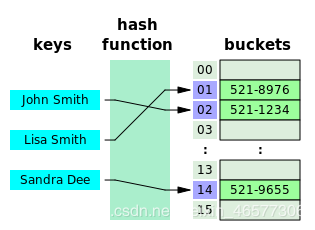
那么这里有几个问题:
如果不同的元素算出了相同的哈希值,那么该怎么存放呢?
答:这就是哈希碰撞,即多个 key 对应了同一个桶。
HashMap 中是如何保证元素的唯一性的呢?即相同的元素会不会算出不同的哈希值呢?
答:通过 hashCode() 和 equals() 方法来保证元素的唯一性。
如果 pairs 太多,buckets 太少怎么破?
答:Rehasing. 也就是碰撞太多的时候,会把数组扩容至两倍(默认)。所以这样虽然 hash 值没有变,但是因为数组的长度变了,所以算出来的 index 就变了,就会被分配到不同的位置上了,就不用挤在一起了,小伙伴们我们江湖再见~
那什么时候会 rehashing 呢?也就是怎么衡量桶里是不是足够拥挤要扩容了呢?
答:load factor. 即用 pair 的数量除以 buckets 的数量,也就是平均每个桶里装几对。Java 中默认值是 0.75f,如果超过了这个值就会 rehashing.
关于 hashCode() 和 equals()
如果 key 的 hashCode() 值相同,那么有可能是要发生 hash collision 了,也有可能是真的遇到了另一个自己。那么如何判断呢?继续用 equals() 来比较。
也就是说,
hashCode() 决定了 key 放在这个桶里的编号,也就是在数组里的 index;
equals() 是用来比较两个 object 是否相同的。
那么该如何回答这道 经典面试题 :
为什么重写 equals() 方法,一定要重写 hashCode() 呢?
答:首先我们有一个假设:任何两个 object 的 hashCode 都是不同的。
那么在这个条件下,有两个 object 是相等的,那如果不重写 hashCode(),算出来的哈希值都不一样,就会去到不同的 buckets 了,就迷失在茫茫人海中了,再也无法相认,就和 equals() 条件矛盾了,证毕。
撒花~~:tada::tada::tada:
接下来我们再对这两个方法一探究竟:
其实 hashCode() 和 equals() 方法都是在 Object class 这个老祖宗里定义的,Object 是所有 Java 中的 class 的鼻祖,默认都是有的,甩不掉的。
那既然是白给的,我们先来看看大礼包里有什么,谷歌 Object 的 Oracle 文档:
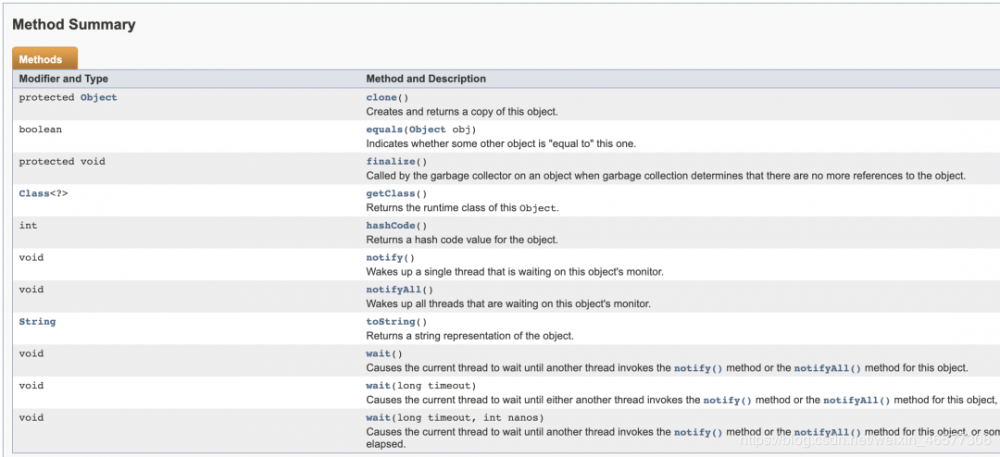
所以这些方法都是可以直接拿来用的呢~
回到 hashCode() 和 equals(),那么如果这个新的 class 里没有重写 (override) 这两个方法,就是默认继承 Object class 里的定义了。
那我们点进去来看看 equals() 是怎么定义的:
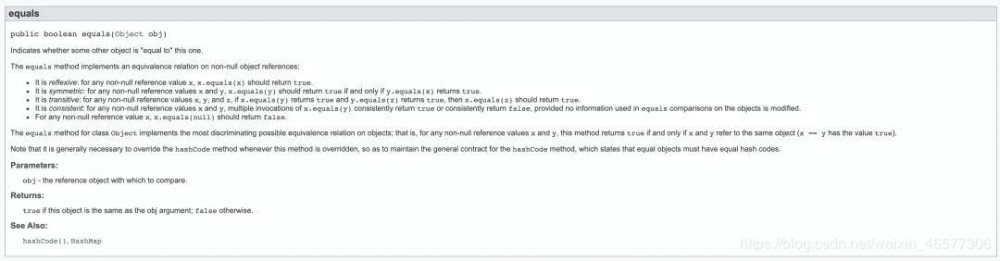
记笔记:
equals() 方法就是比较这两个 references 是否指向了同一个 object.
嗯???你在逗我吗??那岂不是和 == 一样了??
补充:
我们常用的比较大小的符号之 ==
如果是 primitive type,那么 == 就是比较数值的大小;
如果是 referencetype,那么就比较的是这两个 reference 是否指向了同一个 object。
再补充:
Java 的数据类型可以分为两种:
Primitive type 有且仅有8种:
byte, short, int, long,float, double, char, boolean. 其他都是 Reference type.
所以虽然 Java 声称 “Everything is object”,但是还是有非 object 数据类型的存在的。
我不信,我要去源码里看看它是怎么实现的。

哈,还真是的,绕了这么半天,equals() 就是用 == 来实现的!
那为什么还弄出来这么个方法呢?
答:为了让你 override~
比如一般来说我们比较字符串就是想比较这两个字符串的内容的,那么:
str1 = “tianxiaoqi”; str2 = new String(“tianxiaoqi”); str1 == str2; // return false str1.equals(str2); // return true
因为 String 里是重写了 equals() 方法的:

老祖宗留给你就是让你自己用的,如果你不用,那人家也提供了默认的方法,也是够意思了。
好了,我们再去看 hashCode() 的介绍:
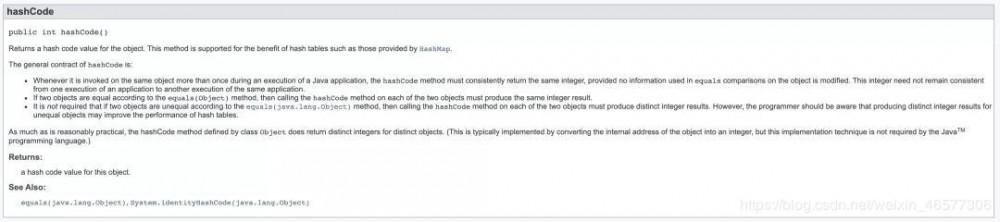
结论就是:
返回的并不一定是对象的(虚拟)内存地址,具体取决于运行时库和JVM的具体实现。 但无论是怎么实现的,都需要遵循文档上的约定,也就是对不同的
object 会返回唯一的哈希值。
哈希冲突详解
一般来说哈希冲突有两大类解决方式[2]
- Separate chaining
- Open addressing
Java 中采用的是第一种 Separate chaining,即在发生碰撞的那个桶后面再加一条“链”来存储,那么这个“链”使用的具体是什么数据结构,不同的版本稍有不同:
在 JDK1.6 和 1.7 中,是用链表存储的,这样如果碰撞很多的话,就变成了在链表上的查找,worst case 就是 O(n);
在 JDK 1.8 进行了优化,当链表长度较大时(超过 8),会采用红黑树来存储,这样大大提高了查找效率。
(话说,这个还真的喜欢考,已经在多次面试中被问过了,还有面试官问为什么是超过“8”才用红黑树 )

第二种方法 open addressing 也是非常重要的思想,因为在真实的分布式系统里,有很多地方会用到 hash 的思想但又不适合用 seprate chaining。
这种方法是顺序查找,如果这个桶里已经被占了,那就按照“某种方式”继续找下一个没有被占的桶,直到找到第一个空的。
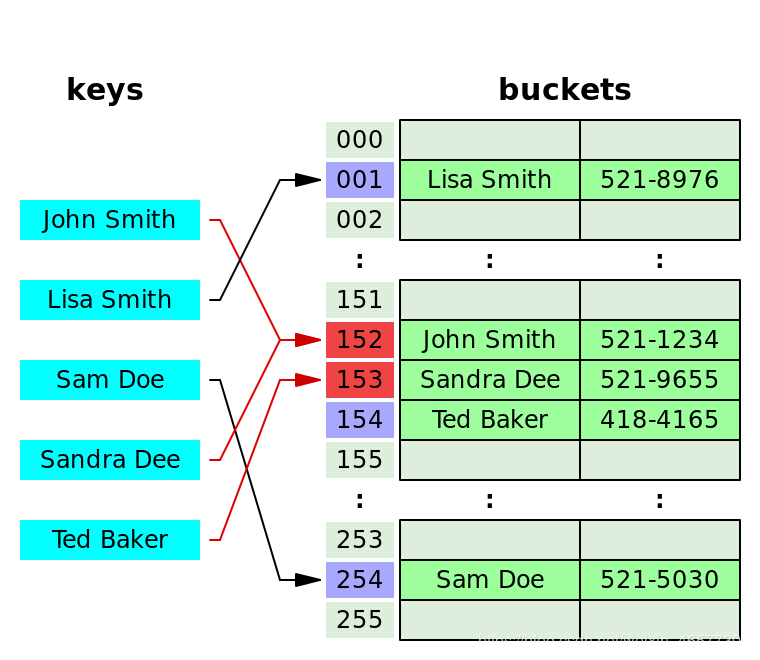
如图所示,John Smith 和 Sandra Dee 发生了哈希冲突,都被计算到 152 号桶,于是 Sandra 就去了下一个空位 - 153 号桶,当然也会对之后的 key 发生影响:Ted Baker 计算结果本应是放在 153 号的,但鉴于已经被 Sandra 占了,就只能再去下一个空位了,所以到了 154 号。
这种方式叫做 Linear probing 线性探查,就像上图所示,一个个的顺着找下一个空位。当然还有其他的方式,比如去找平方数,或者 Double hashing.
HashMap 基本操作
每种数据结构的基本操作都无外乎增删改查这四种,具体到 HashMap 来说,
- 增:put(K key, V value)
- 删:remove(Object key)
- 改:还是用的 put(K key, V value)
- 查:get(Object key) / containsKey(Object key)
细心的同学可能发现了,为什么有些 key 的类型是 Object,有些是 K 呢?这还不是因为 equals()...
这是因为,在 get/remove 的时候,不一定是用的同一个 object。
还记得那个 str1 和 str2 都是田小齐的例子吗?那比如我先 put(str1, value),然后用 get(str2) 的时候,也是想要到 tianxiaoqi 对应的 value 呀!不能因为我换了身衣服就不认得我了呀!所以在 get/remove 的时候并没有很限制 key 的类型,方便另一个自己相认。
其实这些 API 的操作流程大同小异,我们以最复杂的 put(K key, V value) 来讲:
1.首先要拿到 array 中要放的位置的 index
-
怎么找 index 呢,这里我们可以单独用 getIndex() method 来做这件事;
-
具体怎么做,就是通过 hash function 算出来的值,模上数组的长度;
2.那拿到了这个位置的 Node,我们开始 traverse 这个 LinkedList,这就是在链表上的操作了,
- 如果找的到,就更新一下 value;
- 如果没找到,就把它放在链表上,可以放头上,也可以放尾上,一般我喜欢放头上,因为新加入的元素用到的概率总是大一些,但并不影响时间复杂度。
代码如下:
public V put(K key, V value) {
int index = getIndex(key);
Node<K, V> node = array[index];
Node<K, V> head = node;
while (node != null) {
// 原来有这个 key,仅更新值
if (checkEquals(key, node)) {
V preValue = node.value;
node.value = value;
return preValue;
}
node = node.next;
}
// 原来没有这个 key,新加这个 node
Node<K, V> newNode = new Node(key, value);
newNode.next = head;
array[index] = newNode;
return null;
}
至于更多的细节比如加一些 rehashing 啊,load factor 啊,大家可以参考源码。
读完源码大家可以做做 Leetcode 706 题练手,so easy~
与 Hashtable 的区别
这是一个年龄暴露贴,HashMap 与 Hashtable 的关系,就像 ArrayList 与 Vector,以及 StringBuilder 与 StringBuffer。
Hashtable 是早期 JDK 提供的接口,HashMap 是新版的;它们之间最显著的区别,就是 Hashtable 是线程安全的,HashMap 并非线程安全。
这是因为 Java 5.0 之后允许数据结构不考虑线程安全的问题,因为实际工作中我们发现没有必要在数据结构的层面上上锁,加锁和放锁在系统中是有开销的,内部锁有时候会成为程序的瓶颈。
所以 HashMap, ArrayList, StringBuilder 不再考虑线程安全的问题,性能提升了很多,当然,线程安全问题也就转移给我们程序员了。
另外一个区别就是:HashMap 允许 key 中有 null 值,Hashtable 是不允许的。这样的好处就是可以给一个默认值。
好了,最后我们看下常考题吧。
Top K 问题
 非常常考的 Top K 问题,也是大厂面试中规中矩的题,这两题大同小异,这里以第一题为例。
非常常考的 Top K 问题,也是大厂面试中规中矩的题,这两题大同小异,这里以第一题为例。

题意:
给一组词,统计出现频率最高的 k 个。
比如说 “I love leetcode, I love coding” 中频率最高的 2
个就是 I 和 love 了。
有同学觉得这题特别简单,但其实这题只是母题,它可以升级到系统设计层面来问:
在某电商网站上,过去的一小时内卖出的最多的 k 种货物。
我们先看算法层面:
思路:
统计下所有词的频率,然后按频率排序取最高的前 k 个呗。
细节:
用 HashMap 存放单词的频率,用 minHeap/maxHeap 来取前 k 个。
实现:
1.建一个 HashMap <key = 单词,value = 出现频率>,遍历整个数组,相应的把这个单词的出现次数 + 1
这一步时间复杂度是 O(n)
.
2.用 size = k 的 minHeap 来存放结果,定义好题目中规定的比较顺序
a. 首先按照出现的频率排序;
b. 频率相同时,按字母顺序。
3.遍历这个 map,如果
a. minHeap 里面的单词数还不到 k 个的时候就加进去;
b. 或者遇到更高频的单词就把它替换掉。
时空复杂度分析:
第一步是 O(n),第三步是 nlog(k),所以加在一起时间复杂度是 O(nlogk).
用了一个额外的 heap 和 map,空间复杂度是 O(n).
代码:
class Solution {
public List<String> topKFrequent(String[] words, int k) {
// Step 1
Map<String, Integer> map = new HashMap<>();
for (String word : words) {
Integer count = map.getOrDefault(word, 0);
count++;
map.put(word, count);
}
// Step 2
PriorityQueue<Map.Entry<String, Integer>> minHeap = new PriorityQueue<>(k+1, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> e1, Map.Entry<String, Integer> e2) {
if(e1.getValue() == e2.getValue()) {
return e2.getKey().compareTo(e1.getKey());
}
return e1.getValue().compareTo(e2.getValue());
}
});
// Step 3
List<String> res = new ArrayList<>();
for(Map.Entry<String, Integer> entry : map.entrySet()) {
minHeap.offer(entry);
if(minHeap.size() > k) {
minHeap.poll();
}
}
while(!minHeap.isEmpty()) {
res.add(minHeap.poll().getKey());
}
Collections.reverse(res);
return res;
}
}
LRU Cache
这真的是不论国内面试还是北美面试都非常喜欢考的一道题了。
但是鉴于本文篇幅以及这个周末还加了会班,没有时间写了,如果有想看的小伙伴就给我留言吧。
这就是本文的全部内容了。
如果觉得写的不错,请记得收藏加转发。
还想跟我看更多数据结构和算法题的小伙伴们,记得关注我公众号:程序零世界,Java 就这么回事。
作者: 小齐本齐

正文到此结束
- 本文标签: tab map CTO 谷歌 文章 本质 zab 源码 安全 空间 list Word 分布式系统 JVM java 网站 时间 value http 分布式 equals 线程 代码 key 统计 id ArrayList Oracle API Collections src Collection LinkedList IDE 遍历 build IO HashTable https 数据 HTML 电商网站 cache HashMap tk node UI 程序员 锁 queue 回答 HashSet
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

