面试难题:为什么 HashMap 的加载因子是0.75?
点击上方“ 搜云库技术团队 ”关注,选择“ 设为星标 ”
回复“ 面试题 ”领 《96份:3265页面试题》
前言
有很多东西之前在学的时候没怎么注意,笔者也是在重温HashMap的时候发现有很多可以去细究的问题,最终是会回归于数学的,如HashMap的加载因子为什么是0.75?
本文主要对以下内容进行介绍:
-
为什么HashMap需要加载因子?
-
解决冲突有什么方法?
-
为什么加载因子一定是0.75?而不是0.8,0.6?
(若文章有不正之处,或难以理解的地方,请多多谅解,欢迎指正)
为什么HashMap需要加载因子?
HashMap的底层是哈希表,是存储键值对的结构类型,它需要通过一定的计算才可以确定数据在哈希表中的存储位置:
一般的数据结构,不是查询快就是插入快,HashMap就是一个插入慢、查询快的数据结构。但这种数据结构容易产生两种问题:① 如果空间利用率高,那么经过的哈希算法计算存储位置的时候,会发现很多存储位置已经有数据了( 哈希冲突 );② 如果为了避免发生哈希冲突,增大数组容量,就会导致空间利用率不高。
而加载因子就是表示Hash表中元素的填满程度。
加载因子 = 填入表中的元素个数 / 散列表的长度
加载因子越大,填满的元素越多,空间利用率越高,但发生冲突的机会变大了;
加载因子越小,填满的元素越少,冲突发生的机会减小,但空间浪费了更多了,而且还会提高扩容rehash操作的次数。
冲突的机会越大,说明需要查找的数据还需要通过另一个途径查找,这样查找的成本就越高。因此,必须在“冲突的机会”与“空间利用率”之间,寻找一种平衡与折衷。
所以我们也能知道,影响查找效率的因素主要有这几种:
-
散列函数是否可以将哈希表中的数据均匀地散列?
-
怎么处理冲突?
-
哈希表的加载因子怎么选择?
本文主要对后两个问题进行介绍。
解决冲突有什么方法?
1. 开放定址法
H(key)为哈希函数,m为哈希表表长,di为增量序列,i为已发生冲突的次数。其中,开放定址法根据步长不同可以分为3种:
1.1 线性探查法(Linear Probing):di = 1,2,3,…,m-1
简单地说,就是以当前冲突位置为起点,步长为1循环查找,直到找到一个空的位置,如果循环完了都占不到位置,就说明容器已经满了。举个栗子,就像你在饭点去街上吃饭,挨家去看是否有位置一样。
1.2 平方探测法(Quadratic Probing):di = ±12, ±22,±32,…,±k2(k≤m/2)
相对于线性探查法,这就相当于的步长为di = i2来循环查找,直到找到空的位置。以上面那个例子来看,现在你不是挨家去看有没有位置了,而是拿手机算去第i2家店,然后去问这家店有没有位置。
1.3 伪随机探测法:di = 伪随机数序列
这个就是取随机数来作为步长。还是用上面的例子,这次就是完全按心情去选一家店问有没有位置了。
但开放定址法有这些 缺点 :
-
这种方法建立起来的哈希表,当冲突多的时候数据容易堆集在一起,这时候对查找不友好;
-
删除结点的时候不能简单将结点的空间置空,否则将截断在它填入散列表之后的同义词结点查找路径。因此如果要删除结点,只能在被删结点上添加删除标记,而不能真正删除结点;
-
如果哈希表的空间已经满了,还需要建立一个溢出表,来存入多出来的元素。
2. 再哈希法
RHi()函数是不同于H()的哈希函数, 用于同义词发生地址冲突时,计算出另一个哈希函数地址 ,直到不发生冲突位置。这种方法不容易产生堆集,但是会增加计算时间。
所以再哈希法的 缺点 是:
-
增加了计算时间。
3. 建立一个公共溢出区
假设哈希函数的值域为[0, m-1],设向量HashTable[0,…,m-1]为基本表,每个分量存放一个记录,另外还设置了向量OverTable[0,…,v]为溢出表。基本表中存储的是关键字的记录, 一旦发生冲突,不管他们哈希函数得到的哈希地址是什么,都填入溢出表 。
但这个方法的 缺点 在于:
-
查找冲突数据的时候,需要遍历溢出表才能得到数据。
4. 链地址法(拉链法)
将冲突位置的元素构造成链表。在添加数据的时候,如果哈希地址与哈希表上的元素冲突,就放在这个位置的链表上。
拉链法的 优点 :
-
处理冲突的方式简单,且无堆集现象,非同义词绝不会发生冲突,因此平均查找长度较短;
-
由于拉链法中各链表上的结点空间是动态申请的,所以它更适合造表前无法确定表长的情况;
-
删除结点操作易于实现,只要简单地删除链表上的相应的结点即可。
拉链法的 缺点 :
需要额外的存储空间。
从HashMap的底层结构中我们可以看到,HashMap采用是数组+链表/红黑树的组合来作为底层结构,也就是开放地址法+链地址法的方式来实现HashMap。
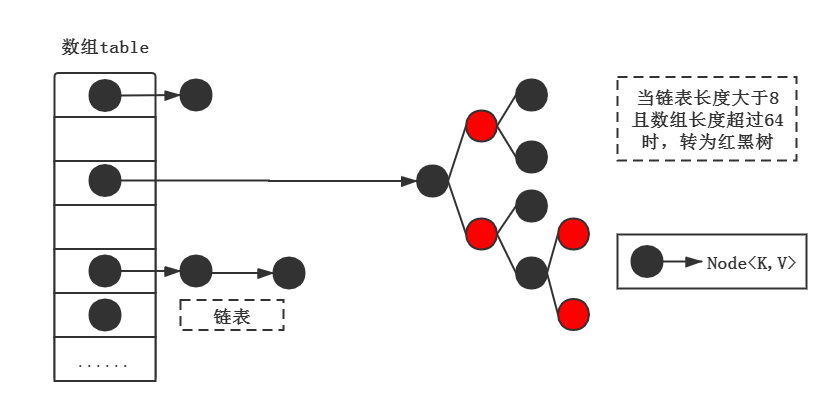
至于为什么在JDK1.8的时候要运用到红黑树,下篇文章会介绍。
为什么HashMap加载因子一定是0.75?而不是0.8,0.6?
从上文我们知道,HashMap的底层其实也是哈希表(散列表),而解决冲突的方式是链地址法。HashMap的初始容量大小默认是16,为了减少冲突发生的概率,当HashMap的数组长度到达一个临界值的时候,就会触发扩容,把所有元素rehash之后再放在扩容后的容器中,这是一个相当耗时的操作。
而这个临界值就是由加载因子和当前容器的容量大小来确定的:
临界值 = DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR
即默认情况下是16x0.75=12时,就会触发扩容操作。
那么为什么选择了0.75作为HashMap的加载因子呢?笔者不才,通过看源码解释和大佬的文章,才知道这个跟一个统计学里很重要的原理—— 泊松分布 有关。
泊松分布是统计学和概率学常见的离散概率分布, 适用于描述单位时间内随机事件发生的次数的概率分布 。有兴趣的读者可以看看维基百科或者阮一峰老师的这篇文章:[泊松分布和指数分布:10分钟教程][10]
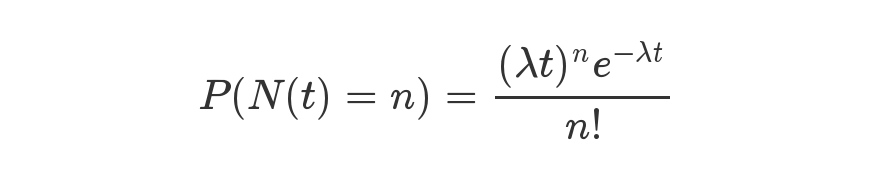
等号的左边,P 表示概率,N表示某种函数关系,t 表示时间,n 表示数量。等号的右边,λ 表示事件的频率。
在HashMap的源码中有这么一段注释:
笔者拙译:在理想情况下,使用随机哈希码, 在扩容阈值(加载因子)为0.75的情况下,节点出现在频率在Hash桶(表)中遵循参数平均为0.5的泊松分布 。忽略方差,即X = λt,P(λt = k),其中λt = 0.5的情况,按公式:
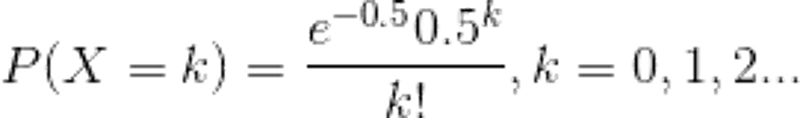
计算结果如上述的列表所示,当一个bin中的链表长度达到8个元素的时候,概率为0.00000006,几乎是一个不可能事件。
所以我们可以知道,其实常数0.5是作为参数代入泊松分布来计算的,而 加载因子0.75是作为一个条件 ,当HashMap长度为length/size ≥ 0.75时就扩容,在这个条件下,冲突后的拉链长度和概率结果为:
那么为什么不可以是0.8或者0.6呢?
HashMap中除了哈希算法之外,有两个参数影响了性能:初始容量和加载因子。初始容量是哈希表在创建时的容量, 加载因子是哈希表在其容量自动扩容之前可以达到多满的一种度量 。
在维基百科来描述加载因子:
对于开放定址法,加载因子是特别重要因素, 应严格限制在0.7-0.8以下。超过0.8,查表时的CPU缓存不命中(cache missing)按照指数曲线上升 。因此,一些采用开放定址法的hash库,如Java的系统库限制了加载因子为0.75,超过此值将resize散列表。
在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少扩容rehash操作次数,所以,一般在使用HashMap时建议根据预估值设置初始容量,以便减少扩容操作。
选择0、75作为默认的加载因子, 完全是时间和空间成本上寻求的一种折衷选择 。
结语
曾经有一堆高数、线性代数、离散数学摆在我面前,但是我没有珍惜。等到碰到各种数学问题的时候,才后悔莫及。学计算机的时候最痛苦的事,莫过于此。如果老天可以再给我一个,再来一次的机会的话。我会跟当时的我,说三个字——“学数学!”
数学真的太重要。离开大学之后,该怎么学数学啊,有什么好的建议吗?
如果本文对你有帮助,请给一个赞吧,这会是我最大的动力~
作者:NYfor2020
来源:8rr.co/8V9Q
《第2版:互联网大厂面试题》
最近又赶上跳槽的高峰期,好多粉丝,都问我要有没有最新面试题,索性,我就把我看过的和我面试中的真题,及答案都整理好, 整理了 《第2版:互联网大厂面试题》 并 分类 92 份 PDF , 累计 3625页! 我会持续更新中,马上就出第三版,涵盖大厂算法会更多!
第2版:题库非常全面
包括 Java 集合、JVM、多线程、并发编程、设计模式、Spring全家桶、Java、MyBatis、ZooKeeper、Dubbo、Elasticsearch、Memcached、MongoDB、Redis、MySQL、RabbitMQ、Kafka、Linux、Netty、Tomcat、Python、HTML、CSS、Vue、React、JavaScript、Android 大数据、阿里巴巴等大厂面试题等、等技术栈!
第2版:面试题,怎么领取?
扫码关注, 我另一个公众号 , 架构师专栏
(对,就是我小号)
没错,扫码关注,即可下载
(这是神奇的二维码,你不用回复关键字)
正文到此结束
- 本文标签: spring UI 注释 key 统计 MQ JVM 云 https map 时间 遍历 src cache HashTable ip sql 多线程 MongoDB dubbo JavaScript HashMap mysql tomcat zookeeper Netty Android 并发编程 下载 架构师 linux db 阿里巴巴 大数据 HTML 参数 文章 mongo tab cat CSS CTO mybatis python Elasticsearch 并发 源码 互联网 redis 空间 快的 删除 rabbitmq 缓存 java 线程 数据 设计模式 二维码 http id 哈希算法
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

