一个线上问题的思考:Eureka注册中心集群如何实现客户端请求负载及故障转移?
先抛一个问题给我聪明的读者,如果你们使用微服务 SpringCloud-Netflix 进行业务开发,那么线上注册中心肯定也是用了集群部署,问题来了:
你了解Eureka注册中心集群如何实现客户端请求负载及故障转移吗?
可以先思考一分钟,我希望你能够带着问题来阅读此篇文章,也希望你看完文章后会有所收获!
背景
前段时间线上 Sentry 平台报警,多个业务服务在和注册中心交互时,例如 续约 和 注册表增量拉取 等都报了 Request execution failed with message : Connection refused 的警告:
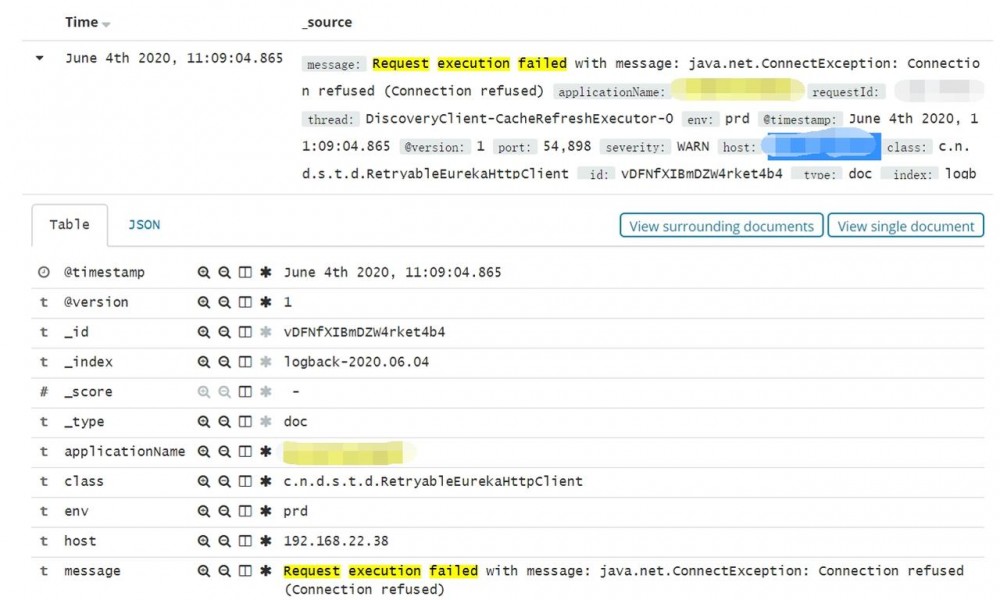
紧接着又看到 Request execution succeeded on retry #2 的日志。
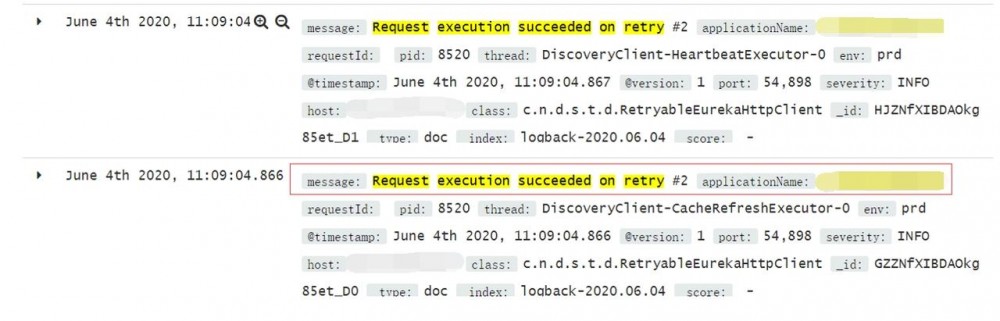
看到这里,表明我们的服务在尝试两次重连后和注册中心交互正常了。
一切都显得那么有惊无险,这里报 Connection refused 是注册中心网络抖动导致的,接着触发了我们服务的重连,重连成功后一切又恢复正常。
这次的报警虽然没有对我们线上业务造成影响,并且也在第一时间恢复了正常,但作为一个爱思考的小火鸡,我很好奇这背后的一系列逻辑: Eureka注册中心集群如何实现客户端请求负载及故障转移?
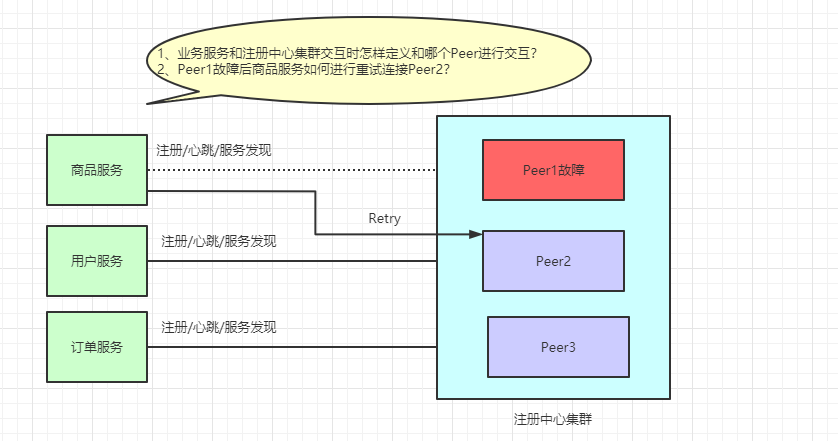
注册中心集群负载测试
线上注册中心是由三台机器组成的集群,都是 4c8g 的配置,业务端配置注册中心地址如下( 这里的peer来代替具体的ip地址 ):
eureka.client.serviceUrl.defaultZone=http://peer1:8080/eureka/,http://peer2:8080/eureka/,http://peer3:8080/eureka/ 复制代码
我们可以写了一个 Demo 进行测试:
注册中心集群负载测试
1、本地通过修改 EurekaServer 服务的端口号来模拟注册中心集群部署,分别以 8761 和 8762 两个端口进行启动 2、启动客户端 SeviceA ,配置注册中心地址为: http://localhost:8761/eureka,http://localhost:8762/eureka
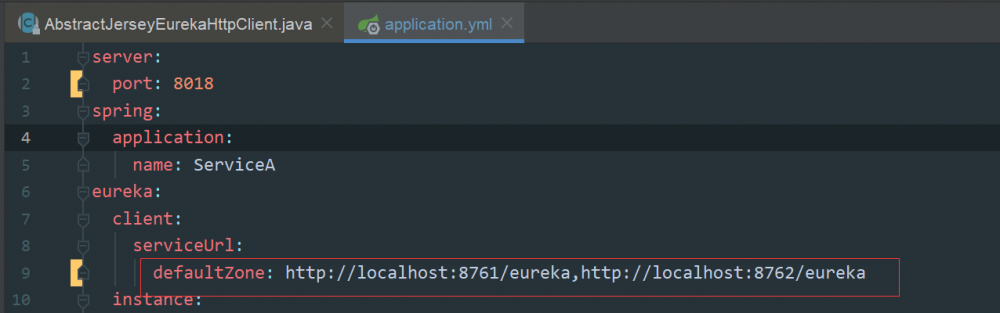
3、启动 SeviceA 时在发送注册请求的地方打断点: AbstractJerseyEurekaHttpClient.register() ,如下图所示:

这里看到请求注册中心时,连接的是 8761 这个端口的服务。
4、更改 ServiceA 中注册中心的配置: http://localhost:8762/eureka,http://localhost:8761/eureka 5、重新启动 SeviceA 然后查看端口,如下图所示:
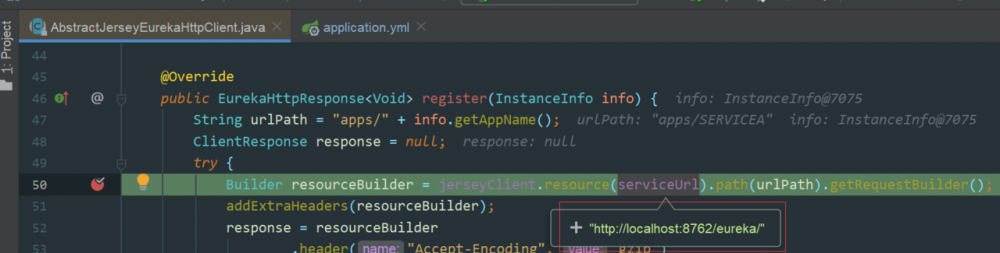
8762
这个端口的服务。
注册中心故障转移测试
以两个端口分别启动 EurekaServer 服务,再启动一个客户端 ServiceA 。启动成功后,关闭一个 8761 端口对应的服务,查看此时客户端是否会自动迁移请求到 8762 端口对应的服务:
1、以 8761 和 8762 两个端口号启动 EurekaServer 2、启动 ServiceA ,配置注册中心地址为: http://localhost:8761/eureka,http://localhost:8762/eureka 3、启动成功后,关闭 8761 端口的 EurekaServer 4、在 EurekaClient 端 发送心跳请求 的地方打上断点: AbstractJerseyEurekaHttpClient.sendHeartBeat() 5、查看断点处数据,第一次请求的 EurekaServer 是 8761 端口的服务,因为该服务已经关闭,所以返回的 response 是 null
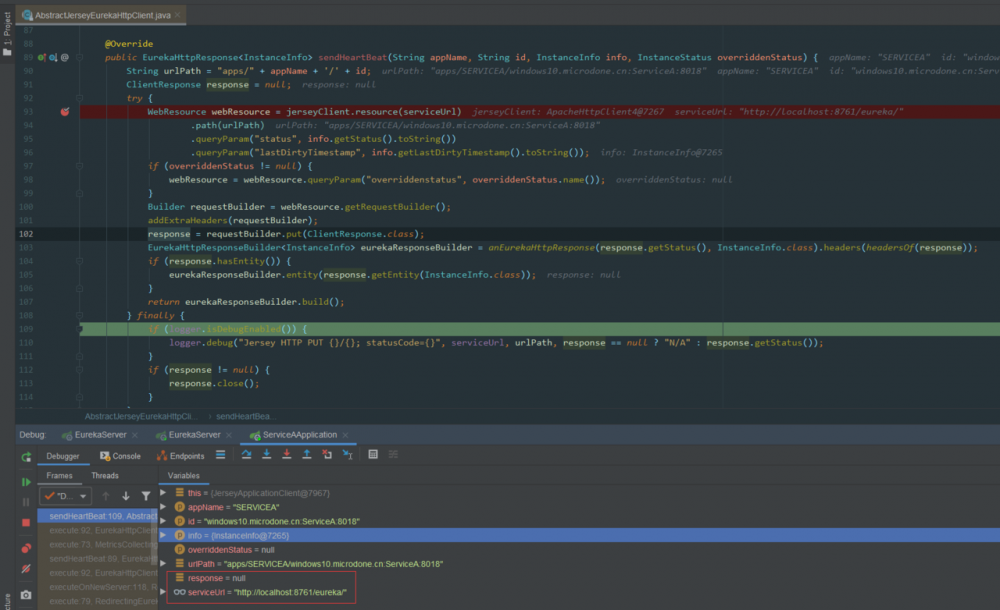
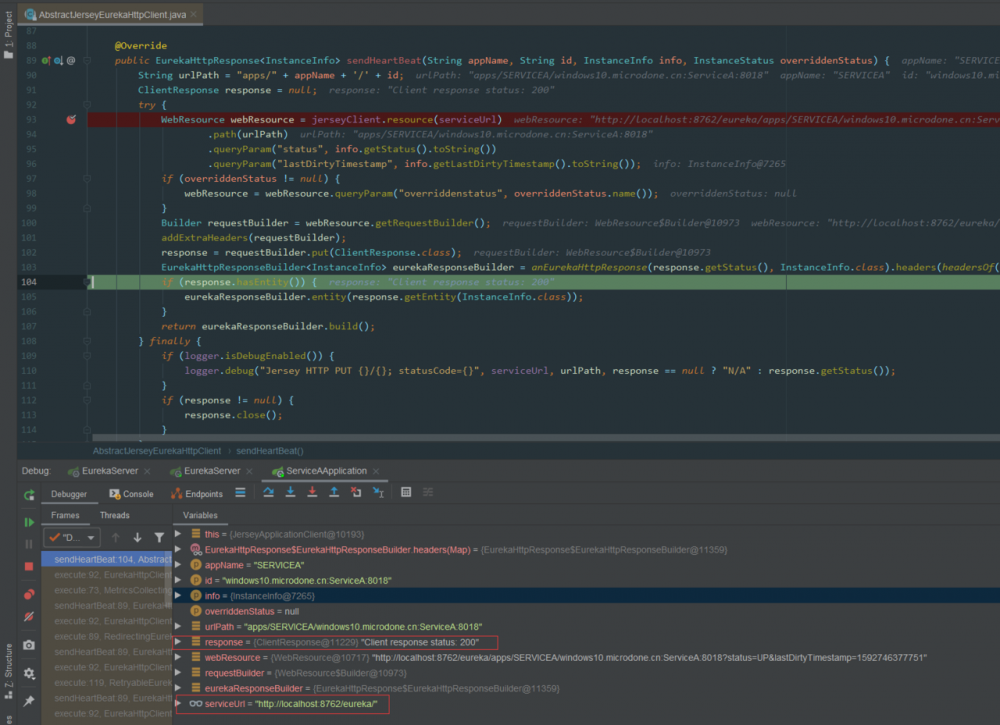
8762 端口的服务,返回的
response 为状态为
200
,故障转移成功,如下图:
思考
通过这两个测试 Demo ,我以为 EurekaClient 每次都会取 defaultZone 配置的第一个 host 作为请求 EurekaServer 的请求的地址,如果该节点故障时,会自动切换配置中的下一个 EurekaServer 进行重新请求。
那么疑问来了, EurekaClient 每次请求真的是以配置的 defaultZone 配置的第一个服务节点作为请求的吗?这似乎也太弱了!!?
EurekaServer 集群不就成了 伪集群 !!?除了客户端配置的第一个节点,其它注册中心的节点都只能作为备份和故障转移来使用!!?
真相是这样吗?NO!我们眼见也不一定为实,源码面前毫无秘密!
翠花,上干货!
客户端请求负载原理
原理图解
还是先上结论,负载原理如图所示:
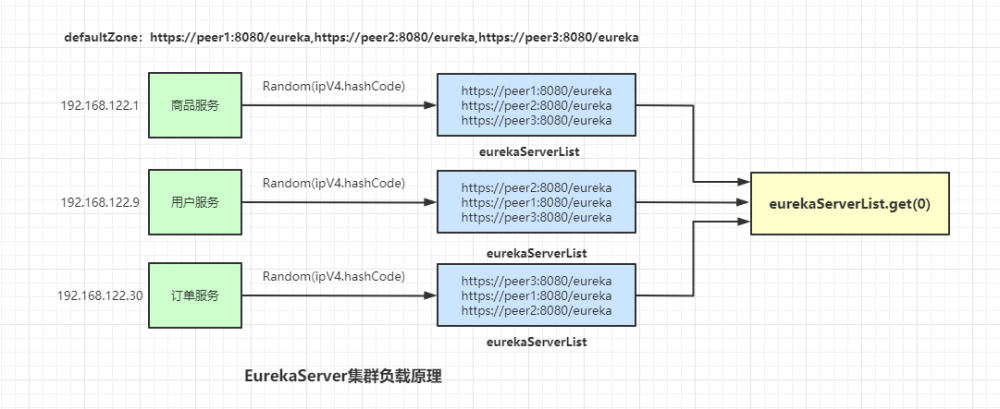
这里会以 EurekaClient 端的 IP 作为随机的种子,然后随机打乱 serverList ,例如我们在**商品服务(192.168.10.56)**中配置的注册中心集群地址为: peer1,peer2,peer3 ,打乱后的地址可能变成 peer3,peer2,peer1 。
**用户服务(192.168.22.31)**中配置的注册中心集群地址为: peer1,peer2,peer3 ,打乱后的地址可能变成 peer2,peer1,peer3 。
EurekaClient 每次请求 serverList 中的第一个服务,从而达到负载的目的。
代码实现
我们直接看最底层负载代码的实现,具体代码在 com.netflix.discovery.shared.resolver.ResolverUtils.randomize() 中:
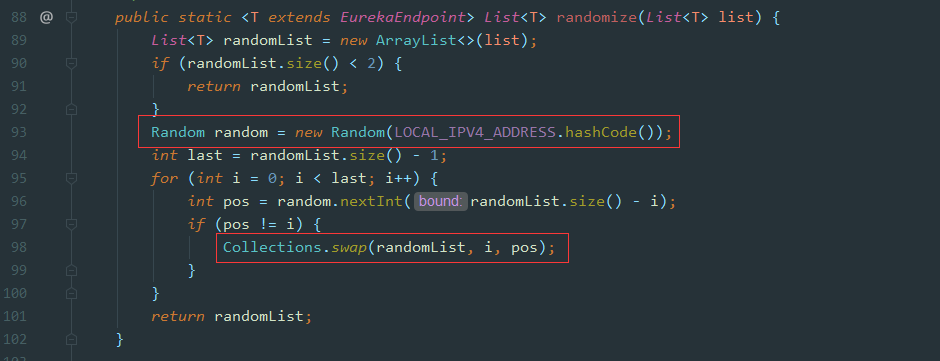
这里面 random 是通过我们 EurekaClient 端的 ipv4 做为随机的种子,生成一个重新排序的 serverList ,也就是对应代码中的 randomList ,所以每个 EurekaClient 获取到的 serverList 顺序可能不同,在使用过程中,取列表的第一个元素作为 server 端 host ,从而达到负载的目的。
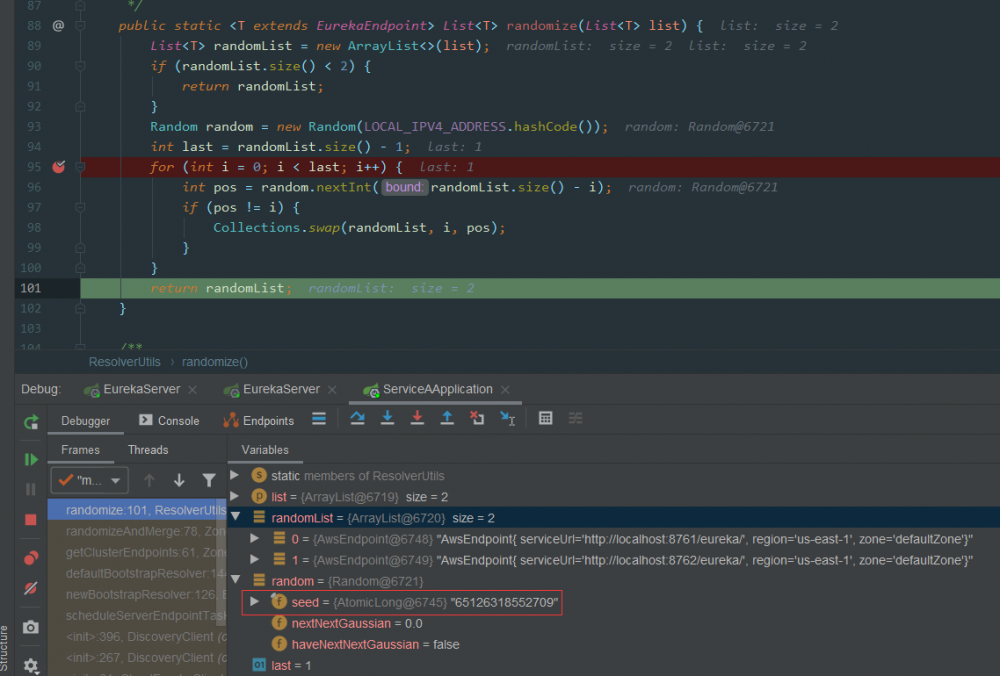
思考
原来代码是通过 EurekaClient 的 IP 进行负载的,所以刚才通过 DEMO 程序结果就能解释的通了,因为我们做实验都是用的同一个 IP ,所以每次都是会访问同一个 Server 节点。
既然说到了负载,这里肯定会有另一个疑问:
通过IP进行的负载均衡,每次请求都会均匀分散到每一个 Server 节点吗?
比如第一次访问 Peer1 ,第二次访问 Peer2 ,第三次访问 Peer3 ,第四次继续访问 Peer1 等,循环往复......
我们可以继续做个试验,假如我们有10000个 EurekaClient 节点,3个 EurekaServer 节点。
Client 节点的 IP 区间为: 192.168.0.0 ~ 192.168.255.255 ,这里面共覆盖6w多个 ip 段,测试代码如下:
/**
* 模拟注册中心集群负载,验证负载散列算法
*
* @author 一枝花算不算浪漫
* @date 2020/6/21 23:36
*/
public class EurekaClusterLoadBalanceTest {
public static void main(String[] args) {
testEurekaClusterBalance();
}
/**
* 模拟ip段测试注册中心负载集群
*/
private static void testEurekaClusterBalance() {
int ipLoopSize = 65000;
String ipFormat = "192.168.%s.%s";
TreeMap<String, Integer> ipMap = Maps.newTreeMap();
int netIndex = 0;
int lastIndex = 0;
for (int i = 0; i < ipLoopSize; i++) {
if (lastIndex == 256) {
netIndex += 1;
lastIndex = 0;
}
String ip = String.format(ipFormat, netIndex, lastIndex);
randomize(ip, ipMap);
System.out.println("IP: " + ip);
lastIndex += 1;
}
printIpResult(ipMap, ipLoopSize);
}
/**
* 模拟指定ip地址获取对应注册中心负载
*/
private static void randomize(String eurekaClientIp, TreeMap<String, Integer> ipMap) {
List<String> eurekaServerUrlList = Lists.newArrayList();
eurekaServerUrlList.add("http://peer1:8080/eureka/");
eurekaServerUrlList.add("http://peer2:8080/eureka/");
eurekaServerUrlList.add("http://peer3:8080/eureka/");
List<String> randomList = new ArrayList<>(eurekaServerUrlList);
Random random = new Random(eurekaClientIp.hashCode());
int last = randomList.size() - 1;
for (int i = 0; i < last; i++) {
int pos = random.nextInt(randomList.size() - i);
if (pos != i) {
Collections.swap(randomList, i, pos);
}
}
for (String eurekaHost : randomList) {
int ipCount = ipMap.get(eurekaHost) == null ? 0 : ipMap.get(eurekaHost);
ipMap.put(eurekaHost, ipCount + 1);
break;
}
}
private static void printIpResult(TreeMap<String, Integer> ipMap, int totalCount) {
for (Map.Entry<String, Integer> entry : ipMap.entrySet()) {
Integer count = entry.getValue();
BigDecimal rate = new BigDecimal(count).divide(new BigDecimal(totalCount), 2, BigDecimal.ROUND_HALF_UP);
System.out.println(entry.getKey() + ":" + count + ":" + rate.multiply(new BigDecimal(100)).setScale(0, BigDecimal.ROUND_HALF_UP) + "%");
}
}
}
复制代码
负载测试结果如下:

可以看到第二个机器会有**50% 的请求,最后一台机器只有 17%**的请求,负载的情况并不是很均匀,我认为通过 IP 负载并不是一个好的方案。
还记得我们之前讲过 Ribbon 默认的轮询算法 RoundRobinRule , 【一起学源码-微服务】Ribbon 源码四:进一步探究Ribbon的IRule和IPing 。
这种算法就是一个很好的散列算法,可以保证每次请求都很均匀,原理如下图:

故障转移原理
原理图解
还是先上结论,如下图:
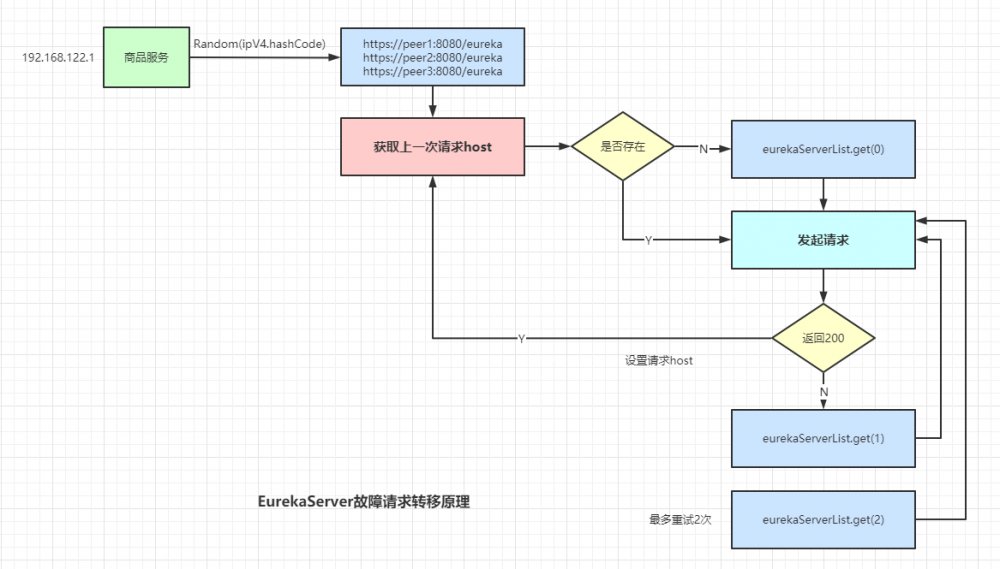
我们的 serverList 按照 client 端的 ip 进行重排序后,每次都会请求第一个元素作为和 Server 端交互的 host ,如果请求失败,会尝试请求 serverList 列表中的第二个元素继续请求,这次请求成功后,会将此次请求的 host 放到全局的一个变量中保存起来,下次 client 端再次请求 就会直接使用这个 host 。
这里最多会重试请求两次。
代码实现
直接看底层交互的代码,位置在 com.netflix.discovery.shared.transport.decorator.RetryableEurekaHttpClient.execute() 中:
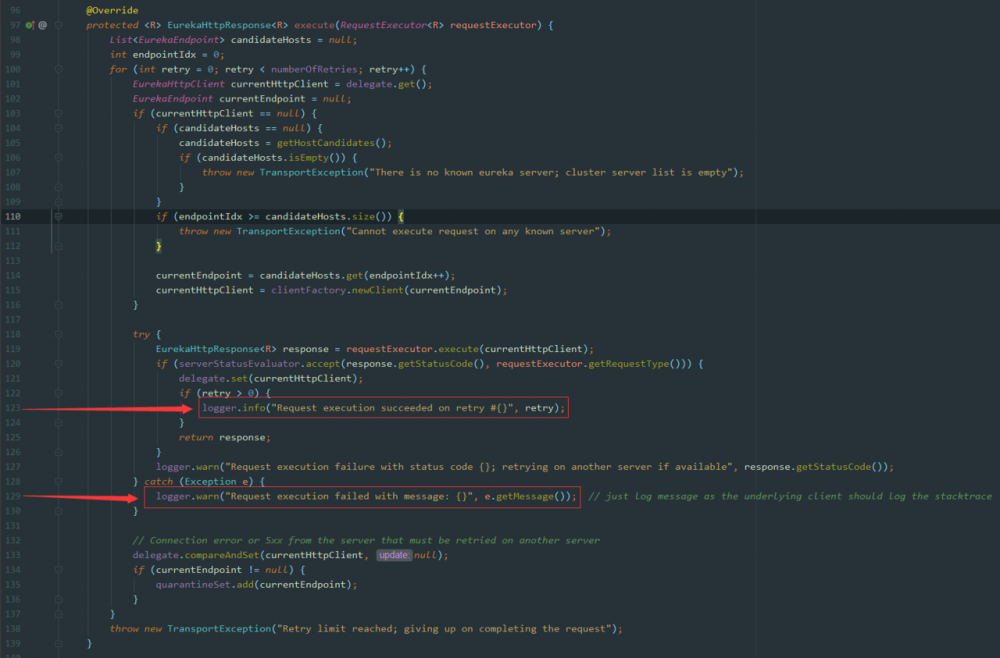
我们来分析下这个代码:
- 第101行,获取
client上次成功server端的host,如果有值则直接使用这个host - 第105行,
getHostCandidates()是获取client端配置的serverList数据,且通过ip进行重排序的列表 - 第114行,
candidateHosts.get(endpointIdx++),初始endpointIdx=0,获取列表中第1个元素作为host请求 - 第120行,获取返回的
response结果,如果返回的状态码是200,则将此次请求的host设置到全局的delegate变量中 - 第133行,执行到这里说明第120行执行的
response返回的状态码不是200,也就是执行失败,将全局变量delegate中的数据清空 - 再次循环第一步,此时
endpointIdx=1,获取列表中的第二个元素作为host请求 - 依次执行,第100行的循环条件
numberOfRetries=3,最多重试2次就会跳出循环
我们还可以第 123和129行 ,这也正是我们业务抛出来的日志信息,所有的一切都对应上了。
总结
感谢你看到这里,相信你已经清楚了开头提问的问题。
上面已经分析完了 Eureka 集群下 Client 端请求时负载均衡的选择以及集群故障时自动重试请求的实现原理。
如果还有不懂的问题,可以添加我的微信或者给我公众号留言,我会单独和你讨论交流。
本文首发自: 一枝花算不算浪漫 公众号,如若转载请在文章开头标明出处,如需开白可直接公众号回复即可。

正文到此结束
- 本文标签: src 希望 https IDE 微服务 开发 Transport 源码 集群 Netflix Collections client Collection ip 数据 retry Eureka message 测试 ribbon swap DOM 部署 Connection IO heartbeat UI ArrayList list 文章 备份 springcloud 时间 rand 总结 ORM db 配置 提问 value http spring id 负载均衡 代码 tk 重排序 Service 端口 map 注册中心 key
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

