故障演练平台开发实践
背景
现状
2015 年开始,酷家乐整体技术架构从早期的单体应用开始向微服务化迈进,经过垂直/水平拆分,再将核心能力下沉抽象,以数字化形式沉淀为业务中台。
架构的演进带来了以下三个突出问题:
- 架构的大规模变更过程导致稳定性故障频发
- 架构的复杂化导致 “流程优化(Code Review/ 上线等)及稳定性盘点” 等形式的保障方式无法满足稳定性保障需求
- 需要验证服务治理、监控警报、DevOps 等基础设施在故障出现时能有效工作,协助团队快速消灭问题
近2年来,酷家乐因故障导致的直接或间接资损高达百万+,更是对公司企业形象无形损害。
分析
在复杂的分布式系统中,我们无法阻止这些故障的发生,所以我们应该致力于在这些异常行为被触发之前,尽可能多地识别风险。
故障演练平台从故障驱动的角度出发,提前挖掘当前架构、链路、系统存在的隐患,验证基础设施的完备性,控制故障影响的范围,将故障前置,更好的做好事前防范,事中止血。
平台目标:
- 提高系统架构的容错能力与健壮性
- 提高开发和运维的故障应急效率
- 提早暴露问题,降低线上故障发生率与复发率
- 提高用户使用体验
酷家乐的混沌实践
选型
酷家乐的技术架构已经开始向微服务化,容器化,中台化等方向演进,主体开发语言为Java,本着满足低成本、高收益、可复用三个要求,所以酷家乐的实施主要以开源和自研相结合的方式。
对市面上的开源产品进行一轮对比筛选之后,我们最终选择了ChaosBlade作为基础设施, 通过自研将混沌工程形成的各种标准和规范,以产品化的形式整合为故障演练平台。
ChaosBlade阿里巴巴开源的一款遵循混沌工程原理和混沌实验模型的实验注入工具,具有以下特点:
- 适用场景丰富 (基础资源,Docker 容器,云原生平台,Java 应用等)
- 社区活跃,文档丰富
- 上手成本低
| chaos-mesh | chaosmonkey | chaosblade | chaoskube | litmus | |
|---|---|---|---|---|---|
| 平台支持 | K8S | VM/容器 | JVM/容器/K8S | K8S | K8S |
| CPU | 否 | 否 | 是 | 否 | 否 |
| MEM | 否 | 否 | 是 | 否 | 否 |
| 容器 | 否 | 是 | 是 | 否 | 否 |
| K8S Pod | 是 | 否 | 是 | 否 | 否 |
| 网络 | 是 | 否 | 是 | 否 | 否 |
| 磁盘 | 是 | 否 | 是 | 否 | 否 |
故障演练平台设计
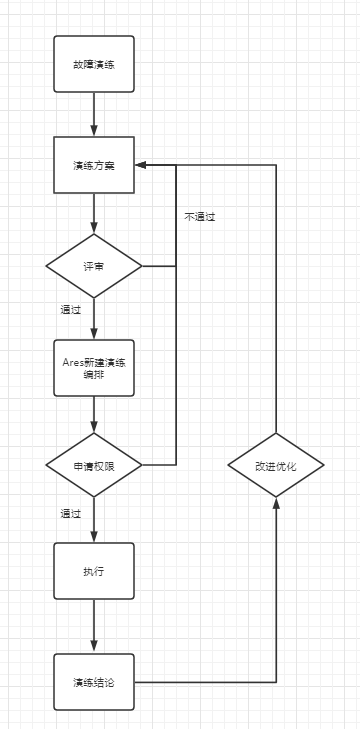
故障演练业务流程
故障演练流程大致可分为3个大阶段:
- 演练评审
- 演练执行
- 演练复盘改进
架构设计
一个合格故障演练需要一套完整配套的实验执行流程。在架构设计方面,我们以故障演练平台Ares为中心,横向打通公司内部的CMDB平台(执行用户鉴权), 工单系统(演练流程审批),运维系统的SaltStack执行平台(故障注入执行),监控报警平台(对整体过程资源的监控告警)来构建故障演练平台的架构模式,以产品化、平台化思路来沉淀演练成果。

平台可分为以下几个模块:
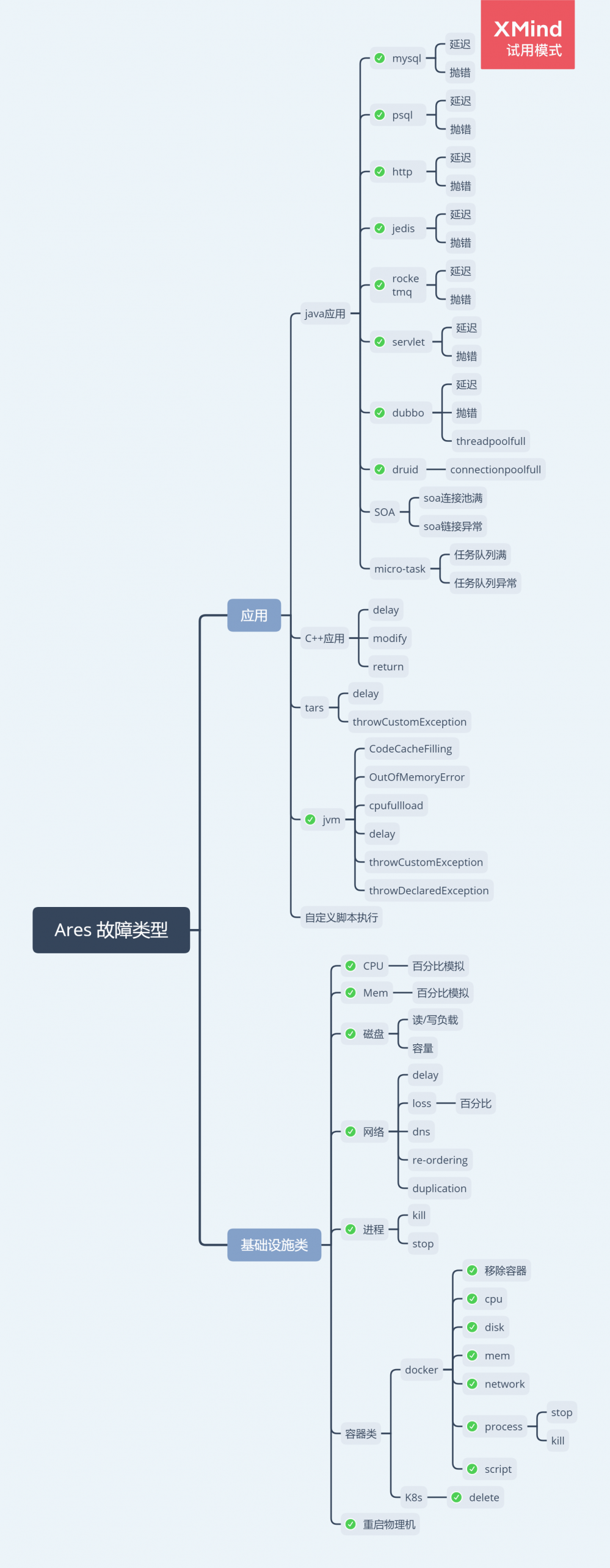
故障类型
我们结合ChaosBlade的能力和酷家乐的历史故障总结出两大类型: 1. 应用类 2. 基础资源类型。其中SOA和MicroTask为酷家乐自定义故障。
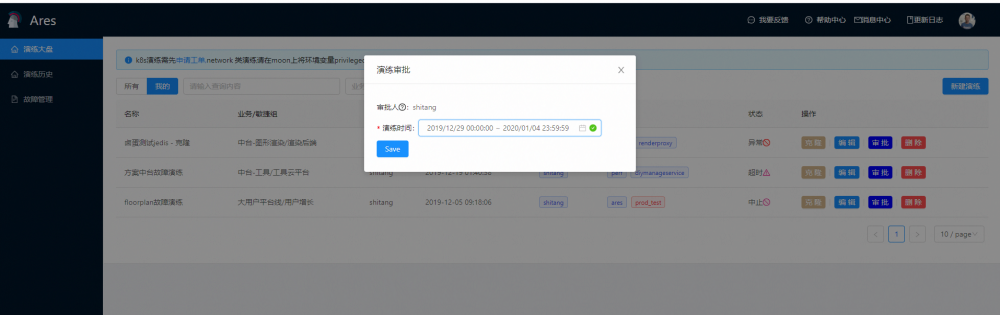
权限管理模块
- 实验主机权限:主机权限校验结合公司的CMDB系统进行鉴权
- 执行人权限:权限审批通过企业微信进行
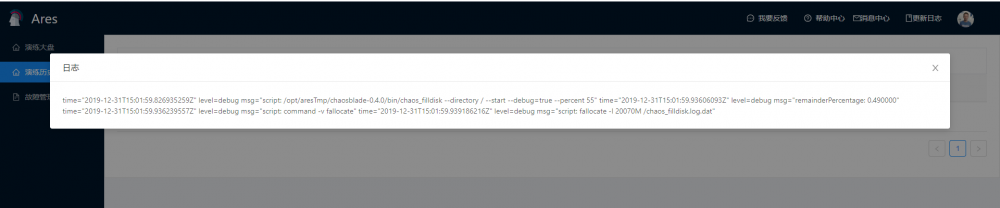
演练审计
记录演练执行日志,安全审计

任务编排
我们通常所说的编排是指一次性自动执行多项任务。一个完备的故障演练需要经历无数的步骤,通常会跨越多个应用程序、设备和数据库 . 因此,故障演练此类规模更大、结构更复杂的场景无疑需要进行编排。
故障演练编排旨在简化并优化故障演练场景设计与演练目标,以确保准确、快速的模拟真实故障场景,并达到可重复,可重现的演练目的。
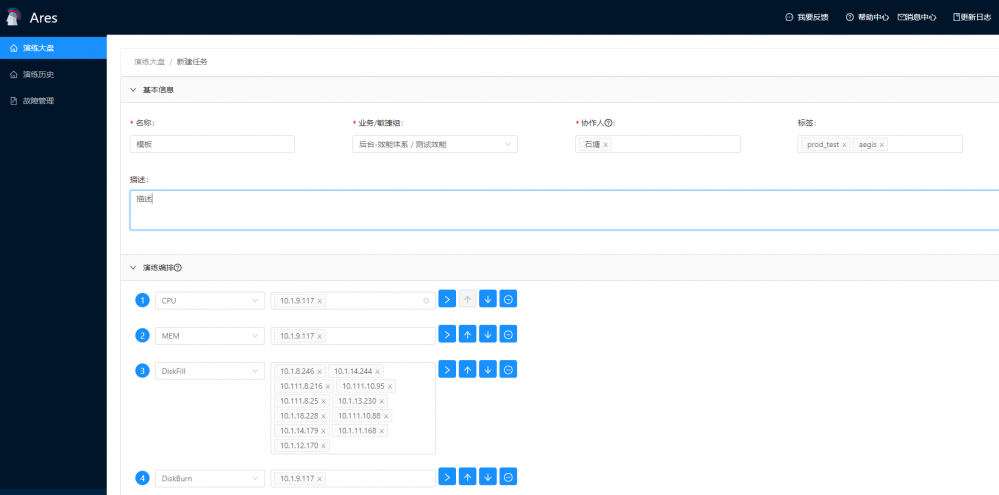
产品展示
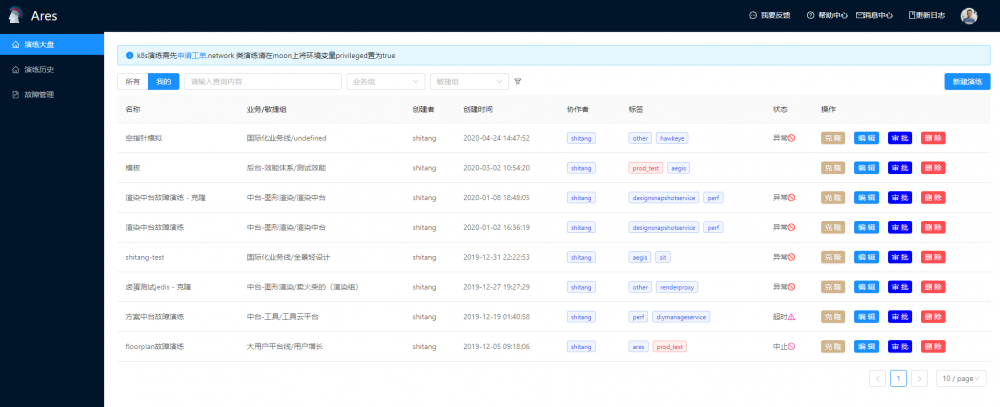
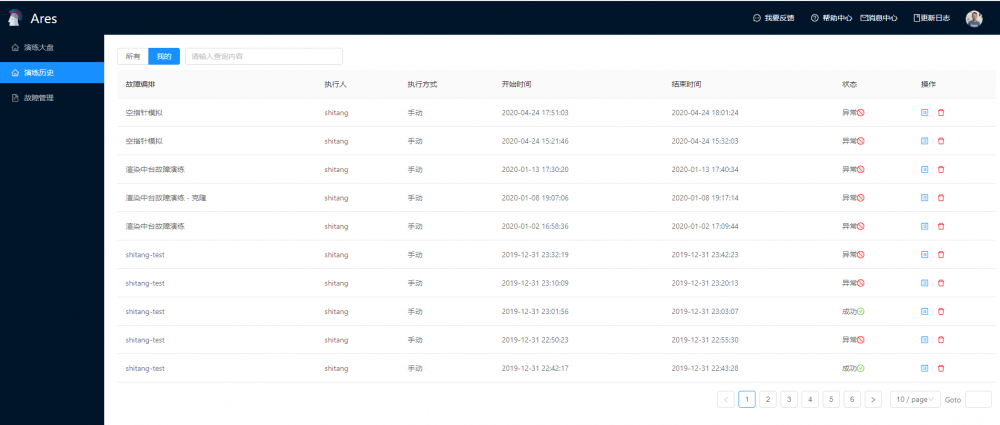
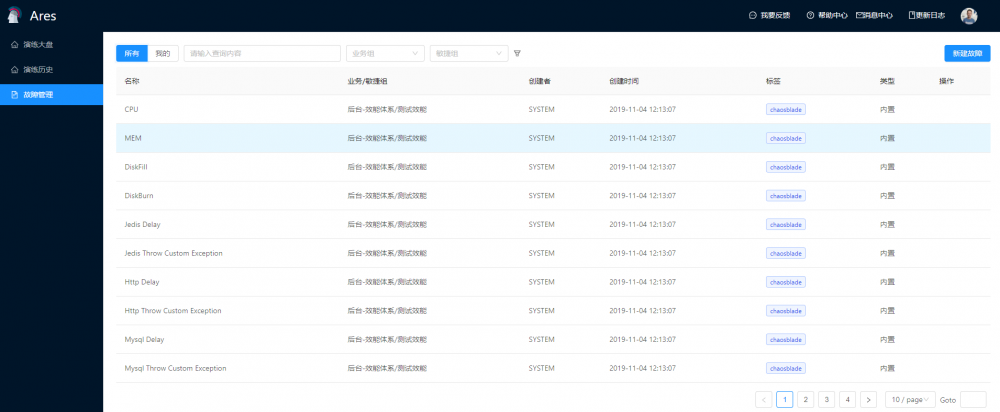
落地与实践
落地策略
单服务/单主机/单集群/单机房
技术人员对新技术引入总是谨小慎微的,如何在实施初期,能更好让团队成员接受?我们决定采取单点爆破的策略,即控制破坏实验在最小范围: 单服务/单主机/单集群/单机房。
以集群选主机制为例,如果master主机在某些场景异常后,集群无法选主,进而就会导致系统整体不可用,从而引起线上故障。而且单机破坏能够在测试环境中发现绝大多数问题,并能扫清后续故障演练阶段的阻塞点,因此单服务/单主机/单集群/单机房的演练被我们排在首位。
依赖治理
依赖分为3类: 1. 基础设施依赖(KVM,容器) 2. 基础服务依赖(数据存储,消息队列) 3. 三方依赖(上下游服务,三方服务),上述任何一类服务依赖的故障,对业务影响都极为严重,可谓是牵一发动全身 。
那如何才能获取服务的强弱依赖关系图,这就涉及到另一个概念: 架构感知,简单来讲就是采集和分析操作系统及第三方标准接口,捕捉进程级的调用关系,并使用特征库算法识别进程所使用的技术组件,最后在服务器、容器和进程这三个维度上以可视化的方式展示应用架构。
依托于酷家乐强大的中间件和监控团队,我们在这一步可以轻松的得到我们公司所有服务依赖图,这样就能有针对性的对架构进行健壮容错性对验证,在系统架构层面推进优化。
补图2
从线下到生产
与软件测试刚好相反,混沌工程只有在生产环境发现问题才有意义。但直接上生产环境过于激进,我们认为一种比较温和的实验步骤是从线下逐渐走到生产。这也是综合考虑,从线下开始着手会让各方都比较放心。不过对于分布式系统而言,部署不同、流量不同都会带来不一样的结果,唯有在生产进行实验才能真正验证。酷家乐实践出了一条比较好的路径:
测试环境 -> 预发布环境 -> 预览环境导流特定流量 -> 生产集群生产流量
全链路精准故障注入
前三步的单点演练到链路演练,全系统的架构设计感知图,都是为了全链路的精准故障注入而准备的。全链路精准注入,是指在系统的任意节点注入一个最小可控范围的故障。以酷家乐业务为例,如何注入一个渲染故障,只影响特定的客户 ID、地域、设备类型、接口,并对注入的行为和比例等进行精准控制,从而大幅缩小故障范围,将故障的风险收敛到最小。
这一步也是对我们技术人员业务系统熟悉度最大考验。因为是精准注入,所以我们必须具备全链路的观测感知能力,精确到每个原子业务操作会流经哪些系统,产生哪些变更,只有这样我们才能够将上述的细微的故障注入影响进行描述,否则,你可能很难回答,延时增加了 3s,是哪些模块,哪些业务操作的作用导致的。这一步的通过内部的红蓝对抗实现,打造公司内部的chaos gameday,毕竟自己人才是最了解自己人,下起手来也最狠。
落地实践与收益
故障演练平台已落地1年,共进行演练100+,发现验证问题50+。
实践1: 验证基础设施的完备性(攻击下,监控展示是否正确;相关警报是否发出)
攻击方案: 制造应用Hang
实验结果:
暂停服务期间:
•监控:暂停服务期间,监控看板能清晰展示数据截断
•警报:无警报发出
服务恢复后:
•监控:监控看板无法识别此次异常波动

实践2: 验证应用在攻击下的工作情况
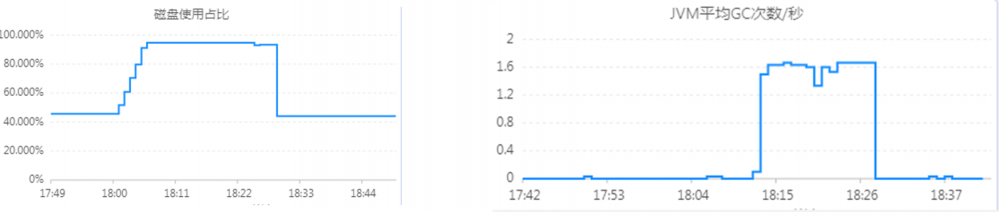
攻击方案: 磁盘填充
观测项:应用QPS、CPU、磁盘使用占比等
实验结果:引起非相关指标异常
愿景
- CI/CD方式在产品发布流程中进行全自动随机的故障演练,并在此过程中积累足够数量级的故障与指标,验证优化故障应急方案,完善架构设计,培养技术人员的混沌文化。
- 自动化梳理强弱依赖:
- 选取服务注入故障,监控全链路上个服务的指标异常情况,根据影响情况,判断强弱依赖
- 模拟多样化真实世界的故障事件:
- 结合历史故障系统, 大数据分析推导出贴合现实场景的链路故障
- 规模化覆盖线上核心业务:
- 全链路精准故障注入
- 红蓝对抗
- 从训练出指标的某种 pattern 特征与故障的对应关系,为以后的故障智能诊断做积累
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

