HashMap 源码解读
HashMap 源码解读
傻瓜源码-内容简介
| 傻瓜源码-内容简介 |
|---|
|
【职场经验】(持续更新) 如何日常学习、如何书写简历、引导面试官、系统准备面试、选择offer、提高绩效、晋升TeamLeader..... |
| 【源码解读】(持续更新)<br/> 1. 源码选材:Java架构师必须掌握的所有框架和类库源码 <br/> 2. 内容大纲:按照“企业应用Demo”讲解执行源码:总纲“阅读指南”、第一章“源码基础”、第二章“相关Java基础”、第三章“白话讲源码”、第四章“代码解读”、第五章“设计模式”、第六章“附录-面试习题、相关JDK方法、中文注释可运行源码项目” 3. 读后问题:粉丝群答疑解惑 |
| 已收录: HashMap 、 ReentrantLock 、 ThreadPoolExecutor 、 《Spring源码解读》 、 《Dubbo源码解读》 ..... |
| 【面试题集】(持续更新)<br/>1. 面试题选材:Java面试常问的所有面试题和必会知识点<br/>2. 内容大纲:第一部分”注意事项“、第二部分“面试题解读”(包括:”面试题“、”答案“、”答案详解“、“实际开发解说”) 3. 深度/广度:面试题集中的答案和答案详解,都是对齐一般面试要求的深度和广度 4. 读后问题:粉丝群答疑解惑 |
| 已收录: Java基础面试题集 、 Java并发面试题集 、 JVM面试题集 、 数据库(Mysql)面试题集 、 缓存(Redis)面试题集 ..... |
| 【粉丝群】(持续更新) <br/> 收录:阿里、字节跳动、京东、小米、美团、哔哩哔哩等大厂内推 |
| :stuck_out_tongue: 作者介绍:Spring系源码贡献者、世界五百强互联网公司、TeamLeader、Github开源产品作者 :stuck_out_tongue: 作者微信:wowangle03 (企业内推联系我) |
加入我的粉丝社群,阅读更多内容。从学习到面试,从面试到工作,从 coder 到 TeamLeader,每天给你答疑解惑,还能有第二份收入!

第 1 章 阅读指南
- 本文基于 open-jdk 1.8 版本。
- 本文按照” Demo “解读。
-
本文建议分为两个学习阶段,掌握了第一阶段,再进行第二阶段;
- 第一阶段,理解章节“源码解读”前的所有内容。即掌握 IT 技能:熟悉 HashMap 原理。
- 第二阶段,理解章节“源码解读”(包括源码解读)之后的内容。即掌握 IT 技能:精读 HashMap 源码。
- 建议按照本文内容顺序阅读(内容前后顺序存在依赖关系)。
- 阅读过程中,如果遇到问题,记下来,后面不远的地方肯定有解答。
- 阅读章节“源码解读”时,建议获得中文注释源码项目配合本文,Debug 进行阅读学习。
-
源码项目中的注释含义
- “ Demo ”在源码中,会标注“ // HashMap Demo ”。
- 在源码中的不易定位到的主线源码,会标注 “ // tofix 主线 ”。
-
以下注释的源码,暂时不深入讲解:
- 在执行“ Demo ”过程中,没有被执行到的源码(由于遍历空集合、 if 判断),会标注“ / * Demo不涉及 / ”;
- 空实现的源码,会标注 / * 空实现 /。
- 不是核心逻辑,并且不影响源码理解,会标注” / * 非主要逻辑 / “。
- 有被赋值的变量,但“ Demo ”运行过程中没有使用到该变量,会标注” / * 无用逻辑 / “。
- 锁、异常处理逻辑、变量的判空校验、日志打印的源码中没有标注注释;
第 2 章 HashMap 简介
HashMap 采用 key/value 存储结构,每个 key 对应唯一的 value,允许 key 为 null,非线程安全,且不保证元素存储的顺序。
第 3 章 Demo
@Test
public void testHashMap() {
// 初始化 HashMap
HashMap<String, String> map = new HashMap();
// 添加键值对,如果 HashMap 已包含相同的 key,则覆盖之前的 value 值
map.put("测试key", "测试value");
// 添加键值对,如果 HashMap 已包含相同的 key,则不覆盖原 value 值,并返回原 value 值
map.putIfAbsent("测试key", "测试value-2");
// 获取键值对
// 打印结果:测试value
System.out.println(map.get("测试key"));
}
第 4 章 相关 Java 基础
4.1 二进制数
在计算机中,所有的数字都是以二进制的形式存在,只用 0 和 1 两个数码来表示。为了区分正数和负数的二进制数,用最高位表示符号位(0 代表正数/1 代表负数)。
以 int 类型的二进制为例;int 类型的十进制整数转换成二进制,最多能够转换成 32 位的二进制数(前 16 位称为高 16 位,后 16 位称为低 16 位);正整数二进制数第 32 位为 0;负整数二进制数第 32 位为 1。
在后文的讲解中,遇到类似这种的 int 二进制数: 0000 0000 0000 0000 0000 0000 0010 1010 ,就直接省略为 0010 1010。
4.2 整数十进制转换为二进制
以 42 为例,转化为二进制等于 0010 1010。

4.3 二进制转换为整数十进制
以 0001 0100 为例,转换为整数十进制等于 20。

4.4 二进制加法
把二进制数从右对齐,根据“逢二进一”规则计算;二进制数加法的法则:
0+0=0 0+1=1+0=1 1+1=0 (进位为1) 1+1+1=1 (进位为1)
例如:1110 和 1011 相加过程如下:
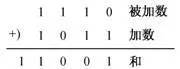
4.5 二进制减法
把二进制数从右对齐,根据“借一有二”的规则计算;二进制数减法的法则:
0-0=0 1-1=0 1-0=1 0-1=1 (借位为1)
例如:1101 和 1011 相减过程如下:

4.6 n<<w(有符号左移)
以 5<<2 为例;就是把 5 的二进制位往左移两位,右边补 0 ,得出的十进制结果为 20。(符号位也会跟着左移运算移动)
- 0000 0101(5 的二进制数)
- 0001 0100(5 的二进制数向往左移动两位,右边补 0,得出的十进制结果为 20)
HashMap 不涉及 n 是负数的情况,暂不讲解。
4.7 n>>w(有符号右移)
以 5>>2 为例;就是把 5 的二进制位往右移两位,左边补 0 ,得出的十进制结果为 1。
- 0000 0101(5 的二进制数)
- 0000 0001(5 的二进制数向往右移动两位,左边补 0,得出的十进制结果为 1)
HashMap 不涉及 n 是负数的情况,暂不讲解。
4.8 n>>>w(无符号右移)
不管 n 是正数还是负数,操作都和 n 为正数时的有符号右移相同。(注:不存在无符号左移运算。)
4.9 newCap = oldCap << 1
先计算等号右边的,再计算等号左边的。
4.10 a&b(按位与)
就是将 a 和 b 先转换为二进制数,然后相同位比较,只有两个都为1,结果才为 1,否则为 0。
以 3&5=1 为例:
- 0000 0011(3 的二进制数)
- 0000 0101(5 的二进制数)
- 0000 0001( 011 & 101 的结果,得出的十进制结果是 1)
4.11 a|b(按位或)
就是将 a 和 b 先转换为二进制数,然后相同位比较,只要一个为 1 ,结果即为 1,否则为 0 。
以 6|2=6 为例:
- 0000 0110(6 的二进制数)
- 0000 0010(2 的二进制数)
- 0000 0110( 110|010 的结果,得出的十进制结果是 6)
4.12 n |= n >>> 1 等价于 n=n|n>>>1
先计算 n>>>1,然后再计算 n|n>>>1 的结果
4.13 n^w(异或运算符)
就是将 n 和 w 转换为二进制数,然后相同位比较,只要相同,结果就为 0,不同则为 1。
以 5^9=12 为例:
- 0000 0101(5 的二进制数)
- 0000 1001(9 的二进制数)
- 0000 1100(0101 ^ 1001 的结果,得出的十进制结果是 12)
第 5 章 源码基础
5.1 HashMap
HashMap 是由数组(table)和 Node 节点对象组成。
1. Node
Node 是 HashMap 自己定义的类,封装了键值对的 key 和 value 值。
2. table
table 中的每个下标位置,称之为桶;每个桶用来装载 Node 节点(可能是一个 Node 节点、也可能是由 Node 节点组成的链表、也可能是由 Node 节点组成的红黑树)。
table 数组的长度(length),称为容量;HashMap 通过算法,保证了容量一定是 2 的 n 次幂(默认为 16)。
HashMap (table)能够装载的 Node 节点的数量,称为阀值(threshold);是通过公式:【容量(默认16)*负载因子(默认 0.75f)】计算得出的(即默认可以装载 12 个 Node 节点)。当 table 存储的 Node 节点数量超过 threshold 时,HashMap 就会将 table 数组的长度扩大一倍,阀值 threshold 可以简单理解为也会随之扩大一倍,每个 Node 节点在桶的位置可能也会随之变化,这个过程是在 resize() 方法实现的,称之为“扩容”。
每个 Node 节点在 table 中的桶位置是通过公式:【key 的 hash &(length-1)】(length 即容量)计算得出的。虽然业界为了元素能够在存储容器中均匀分布,一般都采用取模的方式【hash%length】;但在计算机中,按位与运算运算效率要比取余的快,所以 HashMap 为了更快的运算效率,用【hash&(length-1)】代替了【hash%length】(【hash&(length-1)】在 length 等于 2 的 n 次幂(n 表示任意整数)的时候,才等价于【hash%length】)。
代码示例 HashMap 重要成员变量
public class HashMap<K, V> extends AbstractMap<K, V>
implements Map<K, V>, Cloneable, Serializable {
// table 是用来装载 Node 节点的数组(每个Node节点封装了key和value);是在调用 put 方法(第一次调用put方法,会调用resize方法),进而调用 resize 方法进行的初始化
transient Node<K,V>[] table;
// threshold 代表阀值,HashMap 实际能够装载 Node 元素的数量,当装载元素数量超过阀值就会进行扩容;默认是跟 HashMap 一起初始化的
int threshold;
// loadFactor 表示负载因子,用来计算 threshold 的;是在调用 HashMap 构造函数一起初始化的
final float loadFactor;
// size 表示 HashMap 中已经存储 Node 的数量
transient int size;
// MAXIMUM_CAPACITY 表示 table 允许的最大长度,值为 2 的 30 次幂
static final int MAXIMUM_CAPACITY = 1 << 30;
5.2 Node
代码示例 Node 重要成员变量
static class Node<K, V> implements Entry<K, V> {
// key 代表键值对中的key
final K key;
// hash 代表键值对中key的hash值(通过算法得出,不是hashcode值)
final int hash;
// value 代表键值对中的value
V value;
// next 指向下一个节点,Node 是通过 next 属性,和其它 Node 节点构成联系,形成链的
Node<K, V> next;
5.3 HashMap 中的链
HashMap 中的 Node 链,是通过 Node 节点对象持有下一个 Node 节点引用的方式构建的;每个链只有头节点存储在数组的桶位置上;在 JDKdk1.8 版本上,每个链表最长只有 8 个节点,当大于 8 个节点时,就会将链表转化为红黑树了。
5.4 HashMap 中的红黑树
5.4.1 查找二叉树
红黑树是一种平衡二叉查找树,那什么是二叉查找树呢?二叉树就是每个节点最多有两个子树的树结构,如下图;最顶端的节点称为根节点;每个节点的左子节点所代表的值比父节点的值要小,右节点所代表的的值比父节点的值要大,它的查找效率取决于它的高度。
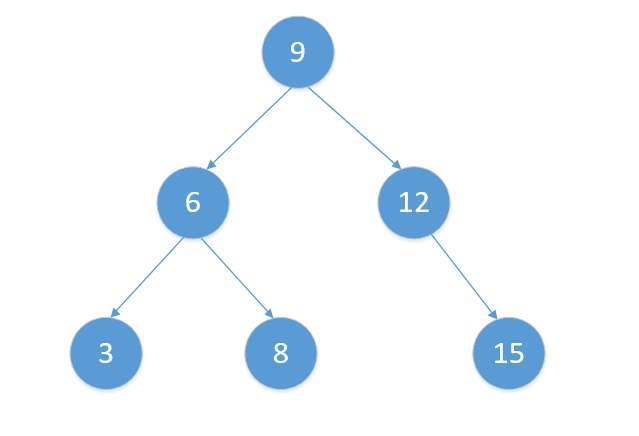
在理想的情况下,二叉查找树增删改查的时间复杂度为 O(logN)(O(logN) 代表如果数据量增大 2 倍,耗时只会增大 1 倍)(log 是以 2 为底);但是在极端场景下,如果所有的节点都在一条斜线上,这样树的高度为 N,增删改查的时间复杂度就变为了 O(N)。所以为了优化这个问题,红黑树诞生了。
5.4.2 红黑树
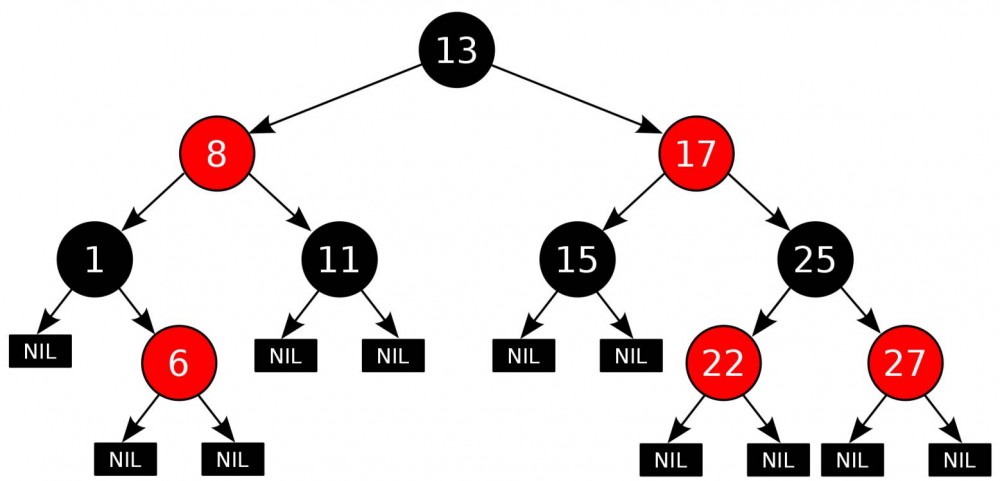
1. 简介
在二叉查找树的基础上,红黑树还增加了以下五大特性,以保证增删改查的时间复杂度总是 O(logN):
- 任何一个节点的颜色非黑即红;
- 根节点只能是黑色;
- 每个红色节点的两个子节点必须是黑色的;
- 叶子节点是黑色的。(叶子节点就是上图中的 NIL)
- 任何一个节点向下遍历到任意一个叶子节点,所经过的黑节点个数必须相等;
在 HashMap 的实现中,没有实现叶子节点,而是直接使用 null 代替。
2. 平衡
如果向红黑树中插入或删除节点时,不满足红黑树的 5 个特性中的任意一个,则会通过变色(黑色节点变成红色、红色节点变为黑色)、左旋转(将某一节点视为轴,向左旋转)、右旋转的方法,将树的高度保持在 logN,此方法称之为平衡。
为了在插入节点,满足五大特性的可能性更高,需要平衡的几率更小;HashMap 在向红黑树插入节点时,默认使用红色。
这是因为如果默认插入黑色节点:每次肯定会破坏性质 4,都得平衡红黑树;如果默认插入红色节点:只是可能破坏性质 1 和性质 3。
5.4.3 TreeNode
在 HashMap 中的红黑树是由若干个 TreeNode 节点对象组成。
代码示例 TreeNode 重要成员变量
static final class TreeNode<K, V> extends LinkedHashMap.Entry<K, V> {
// parent 表示当前节点的父节点
TreeNode<K, V> parent;
// left 表示当前节点的左子节点
TreeNode<K, V> left;
// right 表示当前节点的右子节点
TreeNode<K, V> right;
// red 表示当前的节点的颜色,true为红色,false为黑色
boolean red;
/**
* 继承自 Node
*/
final K key;
final int hash;
V value;
Node<K, V> next;
5.4.4 红黑树图解
1. 颜色
- 实心圆意味黑色节点
- 空心圆意味红色节点
2. 箭头
- 图一中箭头的含义:1 节点的 left 没有指向节点 2,但是 2 节点的 parent 指向了1节点。
- 图二中箭头的含义:1 节点的 left 指向节点 2,但是 2 节点的 parent 没有指向1节点。
- 图三中箭头的含义:1 节点的 left 指向节点 2,2 节点的 parent 指向了1节点。
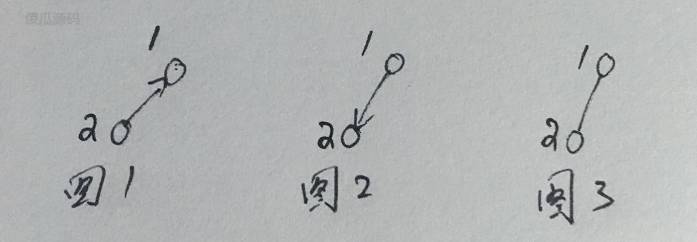
3. 节点插入
HashMap 中,红黑树的节点插入可以简单的分为以下 6 种情况(镜面显示的相反图形同理)。
第一种情况:当插入第一个节点时,因为插入节点默认为红色,所以需要将颜色改为黑色,标记为根节点 root,如下图:
(图一)

第二种情况:插入节点后,红黑树本身就是平衡的,无需平衡,如下图:
(图二)

第三种情况,插入节点 x 后,发现父节点为红色,通过变色进行平衡,如下图:
(图三)
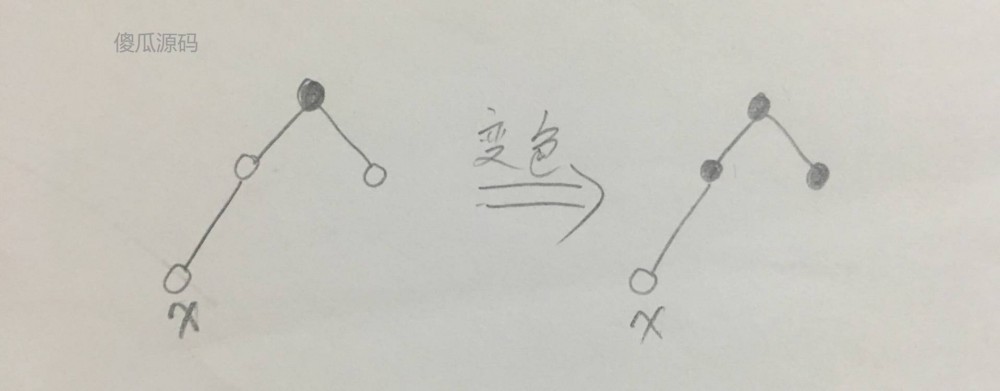
第四种情况,插入节点 x 后,发现父节点为红色,通过变色进行平衡,如下图:
(图四)
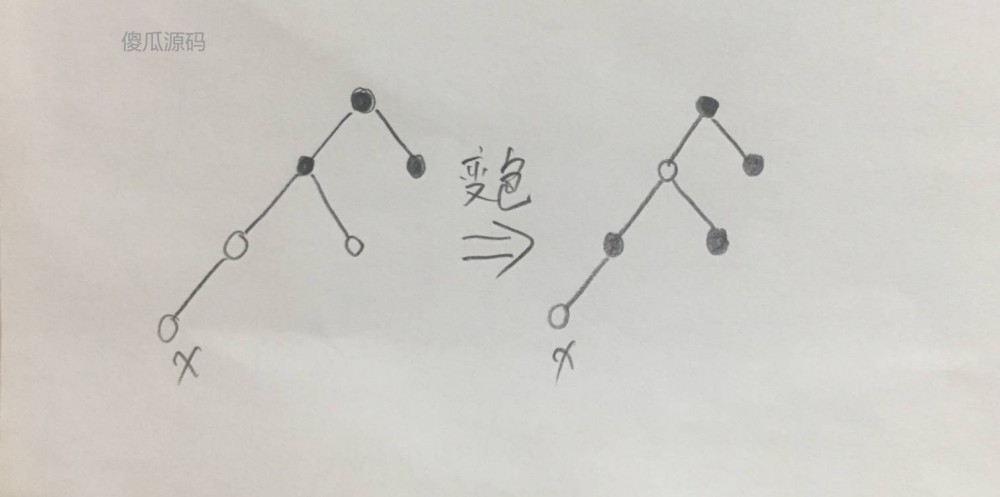
第五种情况,插入节点 x 后,发现父节点为红色,通过变色和右旋转进行平衡,如下图:
(图五)
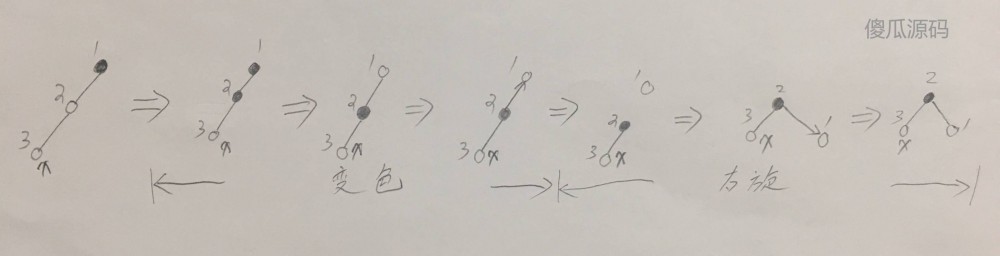
第六种情况,插入节点 x 后,发现父节点为红色,通过左旋变成【第五种情况】,然后再按照【第五种情况】进行平衡,如下图:
(图六)

4. 插入扩展
当红黑树的节点越来越多时,树就会越来越高,平衡操作不尽相同;以下两图+以上六图,就是四层高的 HashMap 红黑树,插入节点 x 后的所有情况了。粉丝不需要掌握以下两种图形的画法,只需要知道红黑树不只是简单地套用六种插入情况即可。
- 插入节点 x 后,发现父节点为红色,通过变色和右旋转进行平衡,如下图:
(图七)
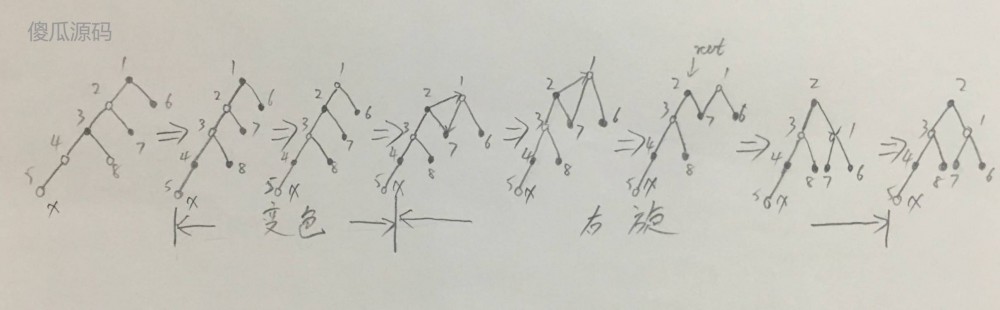
- 插入节点 x 后,发现父节点为红色,通过变色和左旋转和右旋进行平衡,如下图:
(图八)

<br/>
加入我的粉丝社群,阅读全部内容
从学习到面试,从面试到工作,从 coder 到 TeamLeader,每天给你答疑解惑,还能有第二份收入,这样的知识星球,难道你还要犹豫!
加入我的粉丝社群,阅读全部内容
从学习到面试,从面试到工作,从 coder 到 TeamLeader,每天给你答疑解惑,还能有第二份收入,这样的知识星球,难道你还要犹豫!

正文到此结束
- 本文标签: HashMap UI 遍历 开源 源码 executor 产品 代码 并发 美团 mysql 企业 https 架构师 map CTO final 测试 JAVA架构 互联网 GitHub zab 小米 ThreadPoolExecutor git bug sql 设计模式 锁 root 删除 线程 redis 缓存 value dubbo node id 安全 注释 开发 java http 数据库 数据 JVM key java基础 tab MQ 京东 时间 快的 spring src
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

