再看 JVM
这不是我第一次学习 JVM 的知识了,从开始学习 java 语法开始,老师就告诉我们堆啊、栈啊的,那会真是不理解啊,狗捉耗子多管闲事,知道怎么写代码不就行了嘛~
后来逐渐的知道了,java 内存分配的意思,不了解关于 java 内存的部分,你都不知道你的变量什么时候就不是你想要的那个值了
因此专门去看了 java 的 内存分配 ,为了性能优化又去看了 GC 垃圾回收 ,这其中反复看了好几次
这次应该是我第5次看 JVM 的内容,也是第2次写 JVM 的博客,上次那篇已经作废了。以前即便学习 内存分配 和 GC 垃圾回收 那也是单独的看,从没有站在 JVM 总体设计的角度一起看思考,这次站在 JVM 总体设计的角度 ,我发现了更多的知识点,比如: 类的加载机制 ,也发展其实诸如这些其实都是紧密相互关联的,只要我们能理解 JVM 设计的初衷,理解这些其实也没有多大难度了,单个内容理解起来有的真的挺费劲的
学习资料
web 上的博文基本都是说 JVM 单个知识点的,随着 java 版本的变迁,其中有太多的错误,让我们理解起来既费劲,也搞不明白
JVM 的书倒是有基本不错的,但是阅读门槛比较高,强读很多都理解不了
这里我推荐B站尚硅谷的JVM视频,讲的非常好,不光有理论,还有严谨的推导过程,使用转用工具一步步验证,而不是胡说白咧、胡讲,很多内容也是引用自学习JVM的经典书籍: 《深入理解 JVM》
- 2020最新版 Java虚拟机从入门到精通【全203集】
这一个视频+这本书,学习 JVM 的不二法宝,大家不用再找其他资料了,你想知道的,你想不到的这里都有,尤其是视频,即便小白都能看的懂,感谢尚硅谷
简单说下 java 发展历程


java 最重要的3个虚拟机: hotspot,JRockit,J9 IBM的
10年 Oracle 收购了 REA 之后,致力于融合 hotspot 和 JRockit 这2个知名的虚拟机,但是2者之间差异太大,hotspot 可以借鉴的比较少,这个成果在 JDK 8 中得以体现,JDK 8的虚拟机虽然还叫 hotspot,但这个 hotspot 是大量借鉴 JRockit 技术之后的成果了,不可同日而语
JDK 11时,革命性的垃圾回收器 ZGC 出来了,目前 ZGC 还是实验性的,但是实验来看性能远超 G1,虽然 G1 垃圾回收器还是主流,但是未来一定会被 ZGC 替代
JDK 11 开始,Oracle 每3个版本发布一个长期稳定支持版本,其他版本都支持半年,并且更新内容有限,只有大版本才有大的变化。但是也是从11开始,Oracle 每次都发布2个版本,一个免费 OpenJDK,一个商业收费 OracleJDK

所以 JDK8 是目前使用最多的版本,也是目前我们学习的基准,另外阿里巴巴有自己的虚拟机 Taobao JVM,这里不得不赞一个,阿里真是国内互联网的基石啊
JVM 我们学习什么呢
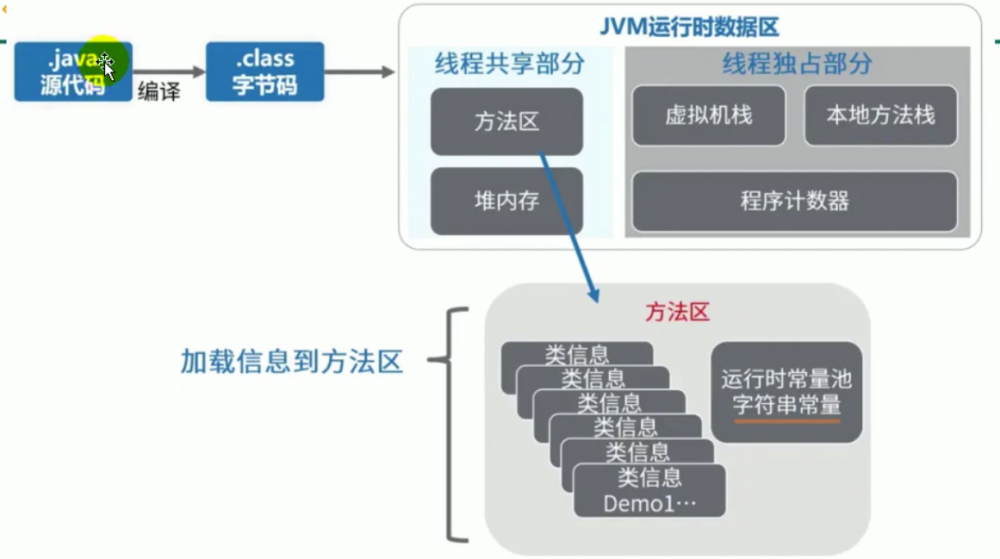
学习 JVM,我们当然要学习 JVM 的3大组成部分了: 类加载器 、 运行时数据区 、 执行引擎
但是我们之前都是每个点学每个点的,从没有站在 JVM 总体的角度上串起来看,这就是这次我要展示给大家的,从总体上看,从总体上理解,其实每个点都是相互关联的
1. JVM 和硬件紧密相联,站在全局的角度去理解 JVM
任何代码都是跑在硬件上的,我们之前学习 JVM 的内容都是学习的 API,从没有考虑硬件上的内容,其实我们若是把 JVM 和硬件上的关联搞清楚,很多晦涩难懂的知识点迎刃而解。比如多线程,难倒不是因为内存的原因而设计的吗,难倒 java 的多线程不是 JVM 决定、管理的嘛,归根结底,多线程就是内存、字节码、指令的运作
java 相比 c 多了什么,多的就是 JVM,就是今天我们研究的东西。java 里我们只要关系逻辑代码怎么写就行了,内存分配不用我们管,内存回收不用我们管,和操作系统的交互不用我们管。经典的 Thread 就是 JVM 代我们去和操作系统内核交互
C++ 需要我们自己分配内存,自己回收,你 C++ 要是技术很好,内存可以使用的非常高效,也不会出现涌余。但要是你技术不高的话,内存可能会非常混乱,从语言发展的角度说自动管理也是大的趋势
有人说: JVM 已经是一个独立的虚拟的计算机了,一台新的机器只要安转了 java 运行环境,立马就行跑 java 代码,但是 C 行吗... 在C 里面我们要自己操作内存,要自己和操作系统交互
这就是为什么 JVM 在现在越来越受欢迎的原理,封装了底层操作,让我们专心于逻辑,这点也是高级语法发展的趋势,就算不是 JVM,也会有自己的 VM,让代码越来越简单
不光如此,JVM 不仅仅是对开发者屏蔽了硬件和操作系统层面的操作,JVM 更是有自己的指令系统: 字节码 ,就是这么个东西,我们知道 CPU 硬件实际执行的是 010101 这样的二进制指令代码。而 JVM 有自己的指令代码,就是编译完成的 .class 里面的内容
这里是一个反编译出来的方法,大家看看用自己码是怎么写的
public void speak();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=3, args_size=1
0: bipush 10
2: istore_1
3: bipush 20
5: istore_2
6: return
LineNumberTable:
line 12: 0
line 13: 3
line 15: 6
复制代码
bipush 10 、 istore_1 这些大家认识吗,看着是不是和汇编多少优点像啊,这就是 JVM 自己设计的,专属于自己的指令集。所以说 JVM 更像是一个虚拟的计算机,只要有一个硬件设备,上面安装有一个内核,JVM 就能顺利的运行,甚至不需要完整的操作系统支持
什么是虚拟机:就是一套用来执行特定虚拟指令的软件。比如要在 mac 上跑 wins 就需要一个虚拟机,要不 mac 怎么认识 X86 指令呢...
2. JVM 已经超脱 java 了
如果说 java 是跨平台的语言:
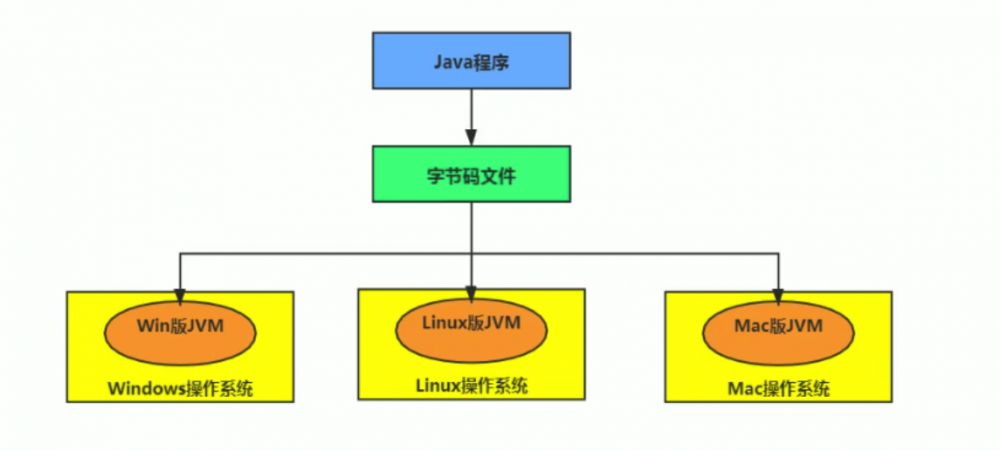
那么 JVM 就是跨语言的平台:
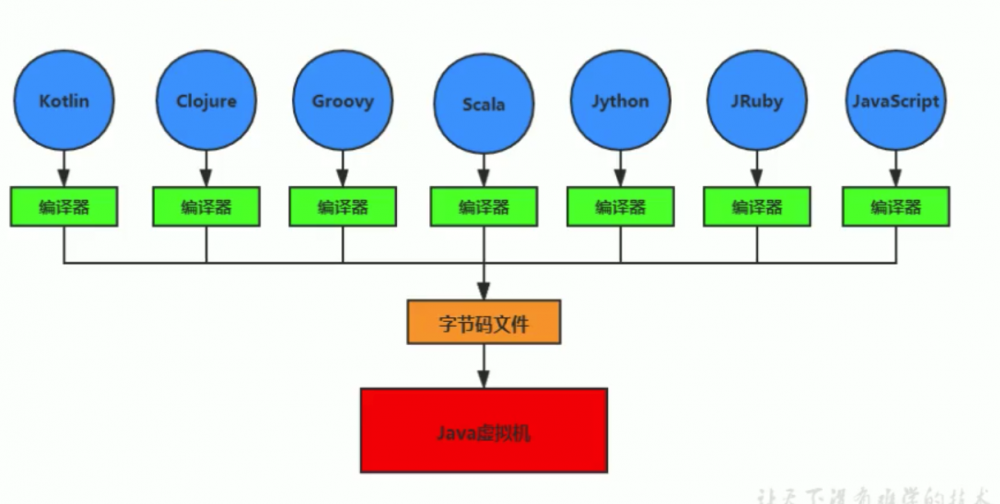
越来越多的语言选择运行在 JVM 环境上,不管这个语言怎么写的,主要该语言的编译器把代码最终编译成 .class 标准字节码文件,那么就都能在 JVM 上运行。像上图中的,这些永远都可以在 JVM 上运行
JVM 已经变成一个生态了,这不能不让我们去思考,我觉得大家看到这里都思考一下是有好处的,感慨下,这就是一种趋势
总体来说JVM就一句话:从软件层面屏蔽不同操作系统在底层硬件个指令上的区别,也包括顶层的高级语言
3. 理解学习 JVM 的好处
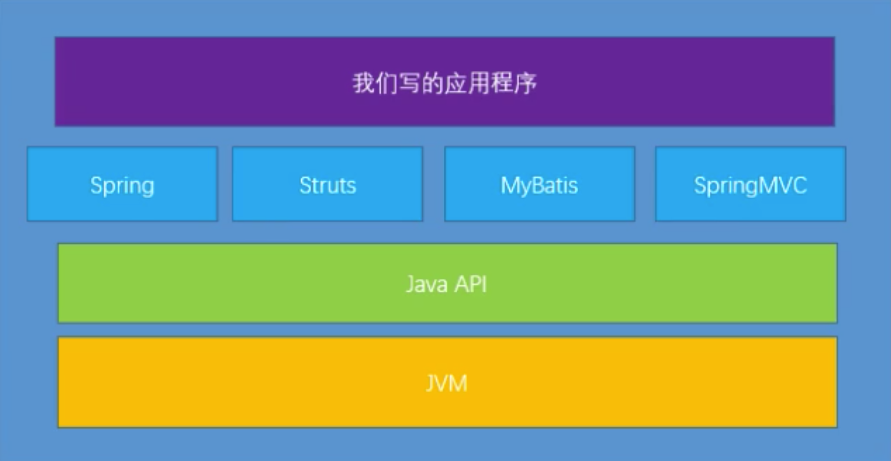
这是 java 程序的结构,JVM 提供最底层运行支持,使用 java 提供的 API 开发了很多框架,我们使用这些框架开发出最终的服务,app等
JVM 是最终承载我们代码的地方,你的服务运行的好不好,卡不卡不都看 JVM 的反馈嘛。单从性能优化的角度看,我们都得对最底层的知识体系有足够了解
懂得 JVM 内存结构,工作机制,是设计高扩展性应用和优化性能的基础,阻碍程序运行的永远是我们对硬件使用的效率,对硬件使用效率的高低决定了我们程序执行的效率
下面这些问题我想大家都会遇到吧:
线上系统突然卡死,OOM 内存抖动 线上 GC 问题,无从下手 新项目上线,JVM 参数配置一脸懵逼 面试 JVM 直接被拍晕在地上,JVM 如何调优,如何解决 GC,OOM
JVM 玩不转别想吧上面这些搞顺溜了...
就算是不是后台服务的,你搞 android 或者其他就没有 内存抖动 的问题啦,不可能的,只要你语言用的 java 或者跑在 JVM 上,这 JVM 都是你逃不过去的
JVM 了解
知道了这些点之后,有助于我们理解后面 JVM 的内容
1. Java进程之间以及跟JVM关系
java程序是跑在JVM上的,严格来讲,是跑在JVM实例上的,一个JVM实例其实就是JVM跑起来的进程,二者合起来称之为一个JAVA进程
各个JVM实例之间是相互隔离的
一个进程可以拥有多个线程 一个程序可以有多个进程(多次执行,也可以没有进程,不执行) 一台机器上可以有多个JVM实例(也可以没有JVM实例) 进程是指一段正在执行的程序 线程是程序执行的最小单位 通过多次执行一个程序可以有多个进程,通过调用一个进程可以有多个程序
程序运行时,会首先建立一个JVM实例----------所以说,JVM实例是多个的,每个运行的程序对应一个JVM实例。每个java程序都运行在一个单独的JVM实例上,(new创建实例,存放在堆空间),所以说一个java程序的多个线程,共享堆内存
总的来说,操作系统的执行单元是进程,每一个JVM实例就是一个进程,而在该实例上运行的主程序是一个主线程(可以看成一个轻量级的进程),该程序下还存在很多线程
2. java 也是起源自小程序
有意思的是,java 最早是为了在 IE3 浏览器中执行 java applets,原来早先 java 也是小程序出身,但是谁让后来 java 火了呢...
3. Taobao JVM
阿里很NB,自己基于 OpenJDK 深度定制了自己的 alibabaJDK,并且定制了自己的 Taobao JVM,很厉害的
其特点:
- 提出了 GCIH 技术,把生命周期较长的对象放到堆外了,提高了 GC 效率,降低了 GC 频率
- GCIH 中的对象可以在多个 JVM 实例中相互共享
- 使用 crc32 指令降低 JNI 开销
- 针对大数据场景的 ZenGC
缺点是高度依赖 Intel cpu,目前在天猫,淘宝上应用,全面替代 Oracle 官方 JVM
JVM 命令和运行参数调整
JVM 虚拟机的参数可定可以手动调节的,实测可以通过 IDE 设置,android app 设置不了
1. IDE 调节 JVM 运行参数
我们只需要在 VM options 里面写设置即可,比如:
-XX:MetaspaceSize=100m 复制代码
MetaspaceSize 是方法区的大小,这样写就行,想改哪个就用对应的英文单词好了
IDE 设置位置:
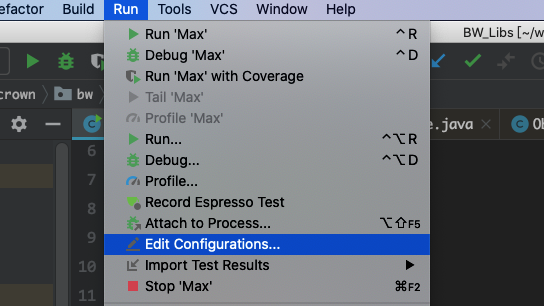
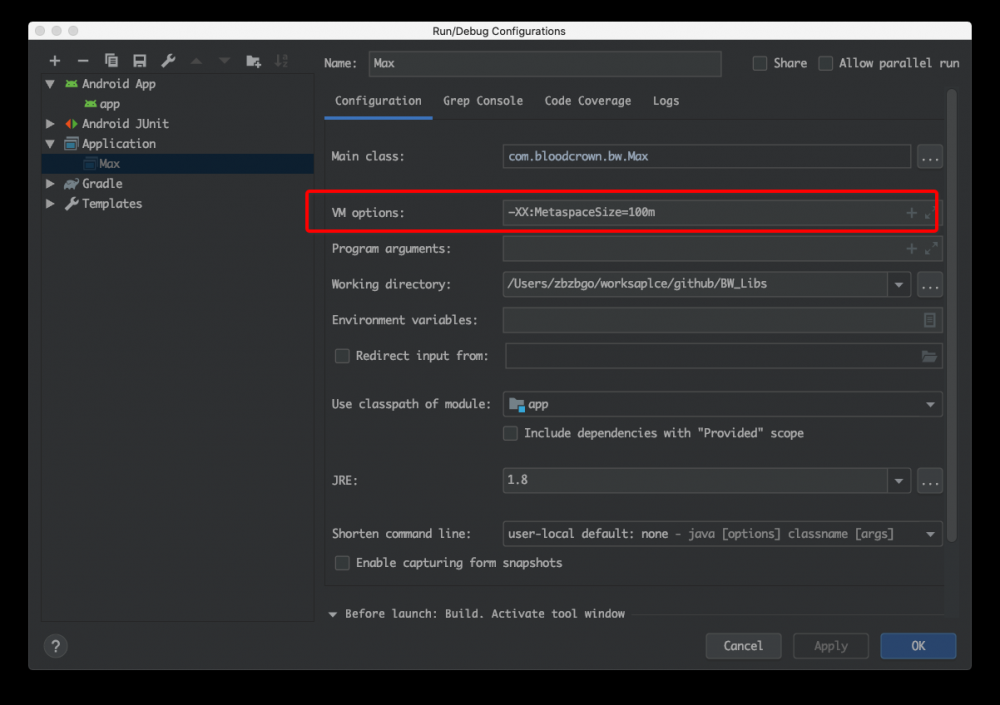
进到第二个图里,我们要选择对应的项目,也就是 main 函数所在的那个方法,我这里是的类是 Max
2. jps 命令
可以查看进程信息
-
jps:打印所有进程
➜ ~ jps 71187 Jps 70867 GradleDaemon 70814 复制代码
-
jps -l:输出完整package整路径,android 进程也能打印出来,但是仅限于自己安装的 app
➜ ~ jps -l 70867 org.gradle.launcher.daemon.bootstrap.GradleDaemon 71193 sun.tools.jps.Jps 70814 复制代码
3. MetaspaceSize 方法区参数
2个参数:
MetaspaceSize MaxMetaspaceSize
// 打印信息,74290 是进程ID,可以用上面 jps -l 命令查看 ➜ ~ jinfo -flag MetaspaceSize 74290 // JVM 配置 -XX:MetaspaceSize=21807104 复制代码
JVM 生命周期
JVM 也是有生命周期的,上文说到我们可以把进程看成一个JVM实例
JVM 生命周期:
启动: 运行: 退出:
// 一般 java 里面我们退出进程就是这2个方法
// System.exit 其实也是调的 Runtime,我们跟进去看看
System.exit(0);
Runtime.getRuntime().exit(0);
------------------------------------------------------------------
// System.exit(0)
public static void exit(int status) {
Runtime.getRuntime().exit(status);
}
// Runtime.getRuntime().exit(0)
public void exit(int status) {
// Make sure we don't try this several times
synchronized(this) {
if (!shuttingDown) {
shuttingDown = true;
........
// Get out of here finally...
nativeExit(status);
}
}
}
// nativeExit 最终是一个本地方法
private static native void nativeExit(int code);
复制代码
可能大家对 Runtime 不熟悉,Runtime 是什么呢,就是整个运行时数据区
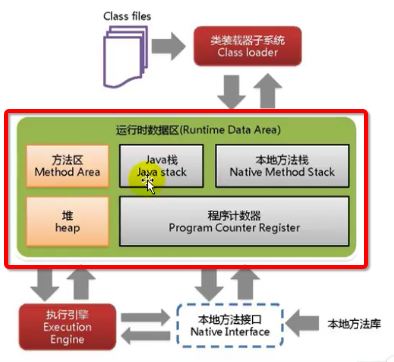
Runtime
了
JVM 整体结构
这里我们以 JDK 为准,以 Hotspot 虚拟机为主
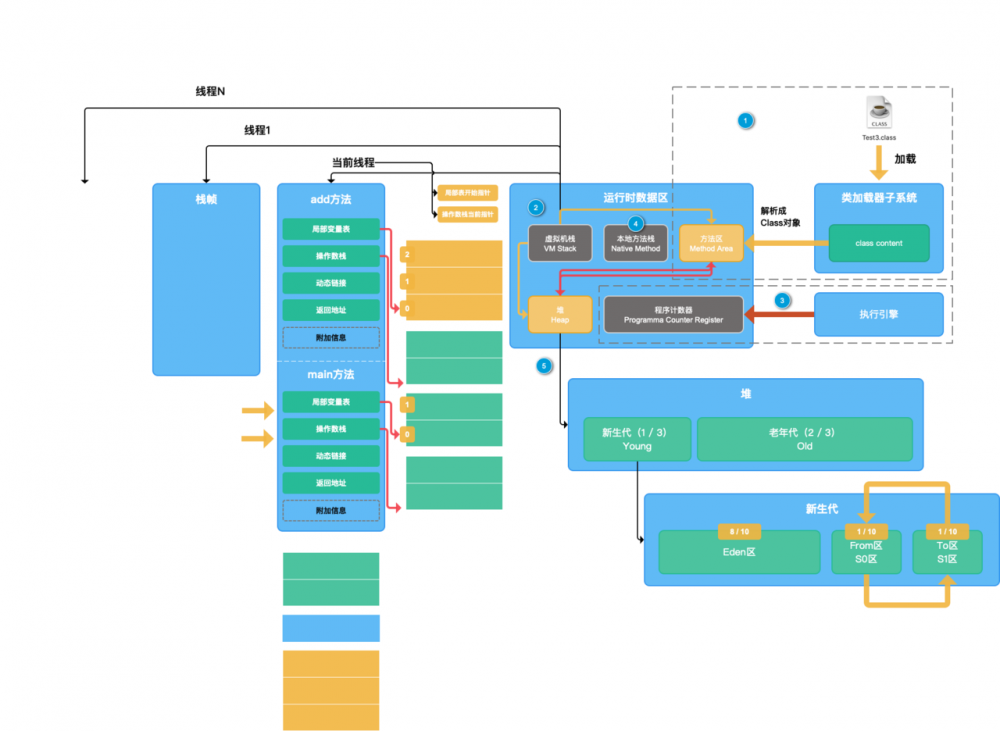
图片来源于:鲁班学院-子牙老师
JVM 的3大组成部分: 类加载器 、 运行时数据区 、 执行引擎
下文我会按照 JVM 最佳学习顺序来逐个介绍:类加载器->方法区->内存结构->GC->执行引擎
在上图里大家可以看的很清楚了,这是我能找到的 JVM 最准确、全面的一张结构图了,大家以后以这个为准吧
运行时数据区 这个一向是大家理解的重点,这里有一点其实很多人搞不清楚
问:线程栈位于哪块内存??或者说工作线程在哪里
答:在 CPU L3 中,线程栈和线程独有的区域其实都在 CPU 缓存中
线程独有的区域包括: 虚拟机栈、本地方法栈、程序计数器 这3个,这3个区域是线程间不可见的,只有自己所在线程可以访问
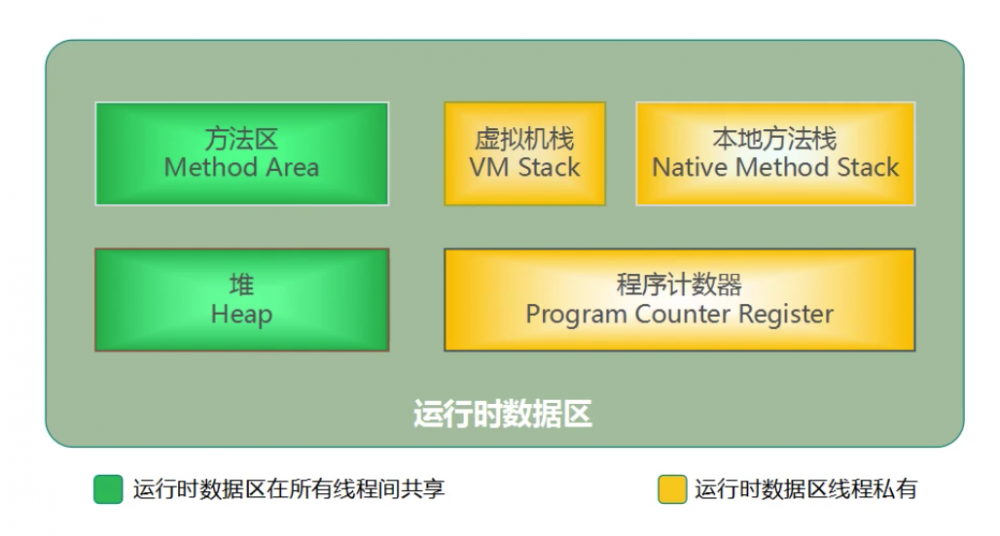
有句话这么说的: 栈管运行,堆管存储 ,所以堆内存很大,自然要放在物流内存中,也就是内存条里
但是用与模拟计算机计算、运行的这3个区域呢,可以放在内存条里,但是不知道大家知不知道,内存条离 CPU 远,而且性能也是一般,内存条的到 CPU 读写的速度比 CPU 缓存慢至少 100 倍,用于模拟计算机运算的这3块数据分区要是内存条里,那 CPU 光剩封着数据传递了吗,CPU 周期会极大的浪费,为了效率想,所以线程栈这3块数据分区选择放在 CPU 的 L3 3级缓存中
看图,从 CPU->内存条也是一个 IO 操作,速度并没有我们想象中的块,真正快的还是 CPU 自身携带的寄存器缓存,那速度才是真的快,真的可以匹配 CPU 的时钟周期的硬件,内存相比要慢上百倍
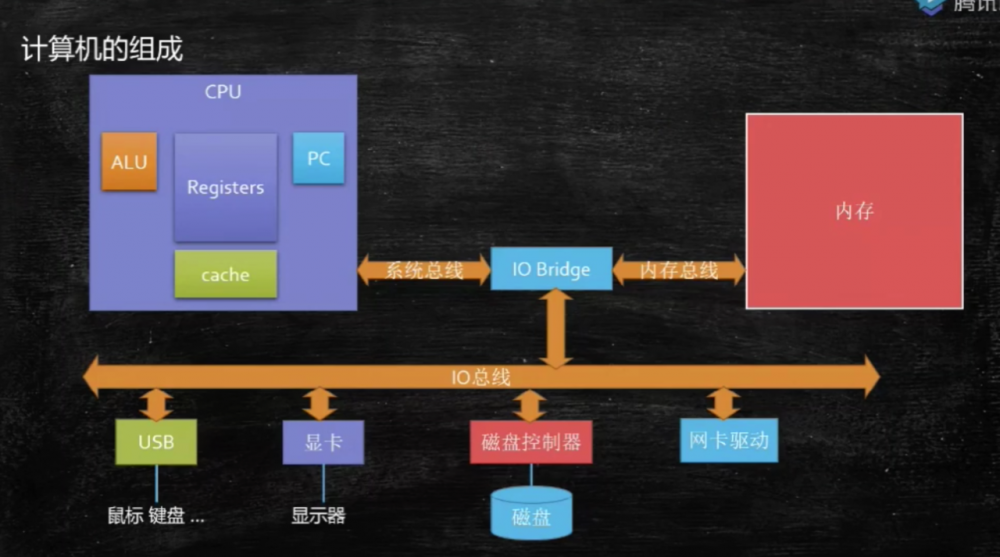
这张图大家看个意思
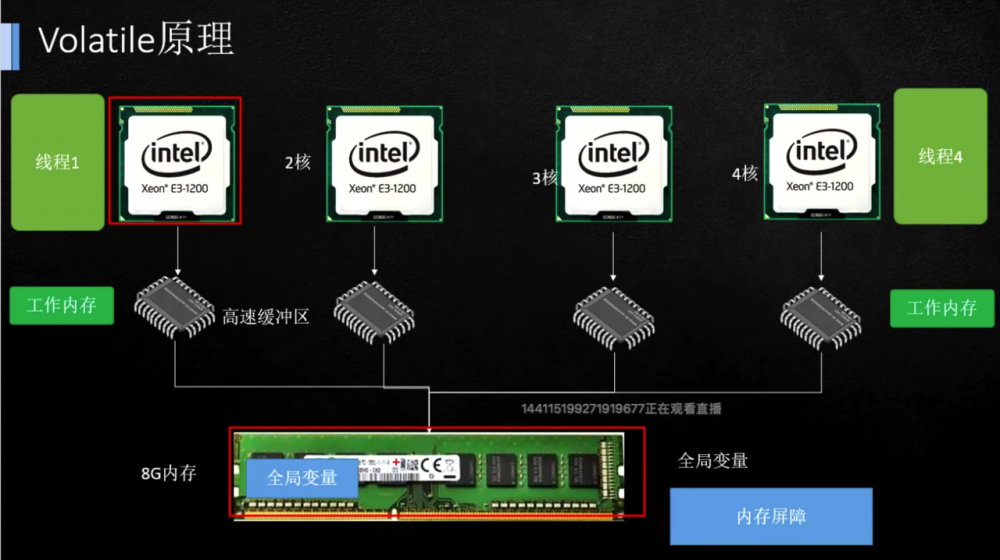
至于为什么线程栈要放在 L3 3级缓存中,是因为多核心 CPU 中,L3 是每个核心共享的,L1、L2 是每个核心独享的,线程因为执行时长的原因可能要在多个核心之间来回切换,那么只有放到 L3 才是合适的,线程由那个CPU核心执行时,该线程的数据会拷贝一份进入L2、L1,这也叫线程的上下文切换
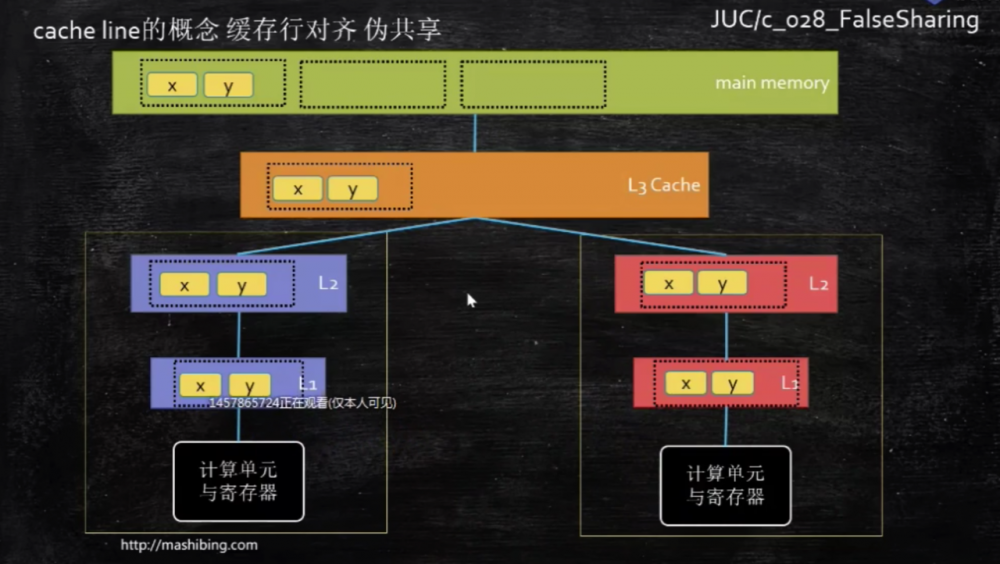
关于内存的部分我会开单章详细说明,比这里说的更加详细
类加载器 这个很重要的,好多黑科技都有使用到类加载器手动new对象,我们要对这块有清晰的了解才行,虽然 android 有自己的 DexClassLoader,但是也是以 java 的类加载器位基础的,学了不吃亏
执行引擎 包括3部分: 解释器,JIT 即时编译器,GC 垃圾回收器 3部分组成
java 默认是逐行解释的,运行时,运行到那行字节码了,解释器就去执行该行自己码,字节码怎么执行呢,很简单,没一个字节码指令对应一个 C++ 的方法,JVM 整体都是用 C++ 写的,所以最终字节码都是转换成 C++ 代码去执行
从 OpenJDK cpp 里可以找到执行器的源码,java_executor.cpp 就是
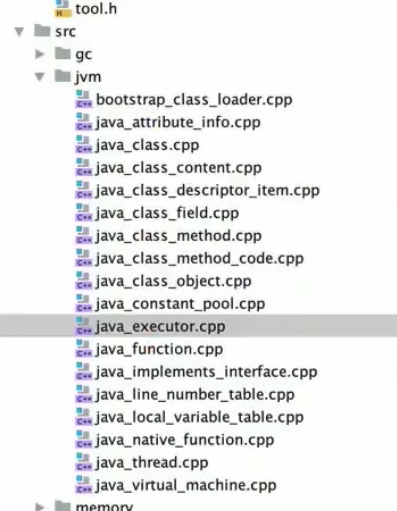
很清楚吧,switch、case,每个字节码指令都对应一个或者多个 C 的方法
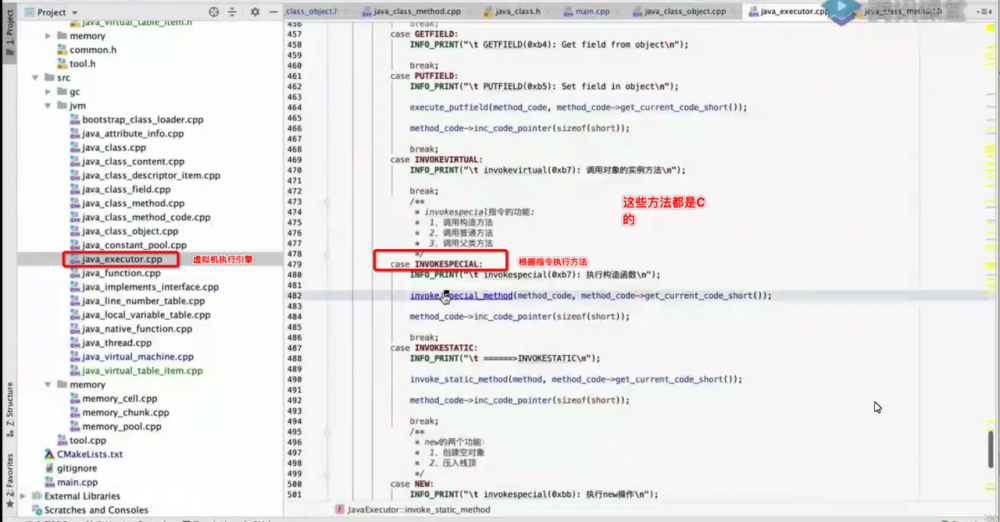
IT 即时编译器 是 ART 虚拟机新加入的特性,也是目前 VM 发展的趋势,很多 VM 也加入了 JIT 这个特性,JIT 干的事就是记录并判断热点代码,正常流程解释器解释自己码要吧相关参数带入到相应的C方法路面去执行,会C方法进一步翻译成汇编语言才能给CPU硬件去执行
JIT 就是把热点代码提前编译成汇编代码,可以直接运行,比解释器省了一部操作,这样可以提高CPU执行效率
JIT 对于热点代码编译成机器码之后是缓存在方法区的
先写这么多,后面我们详细说
从程序共享角度来看内存划分
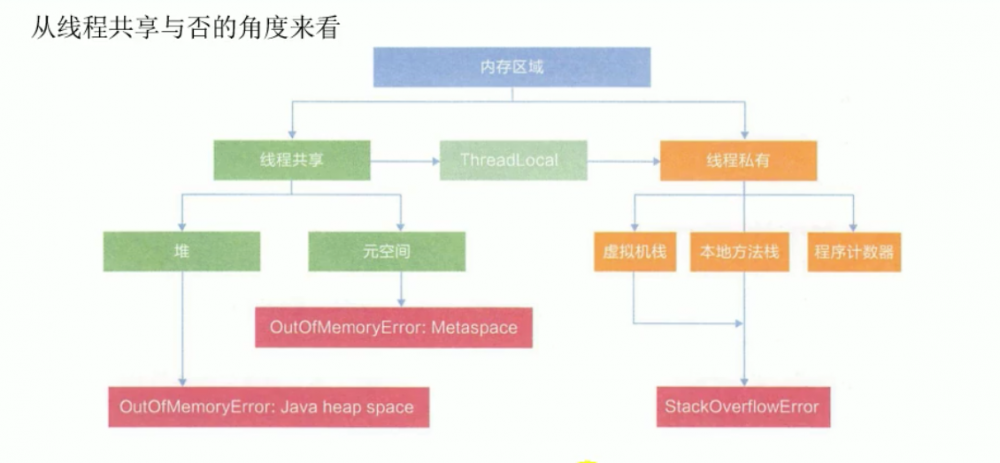
堆内存: 元空间: 栈空间:
只有程序计数器不会OOM,栈空间在CPU L3里面,很小的,一般也就1M大小,栈的深度大了,尤其是跑递归的时候,很有可能内存不足就OOM了
方法区
1. 基本介绍
方法区这个名称是 JVM 规范对管理 class 类信息的内存区域的称谓,大家可以看成是一个接口,声明出方法来了,但是具体怎么实现还得看具体的实现类不是
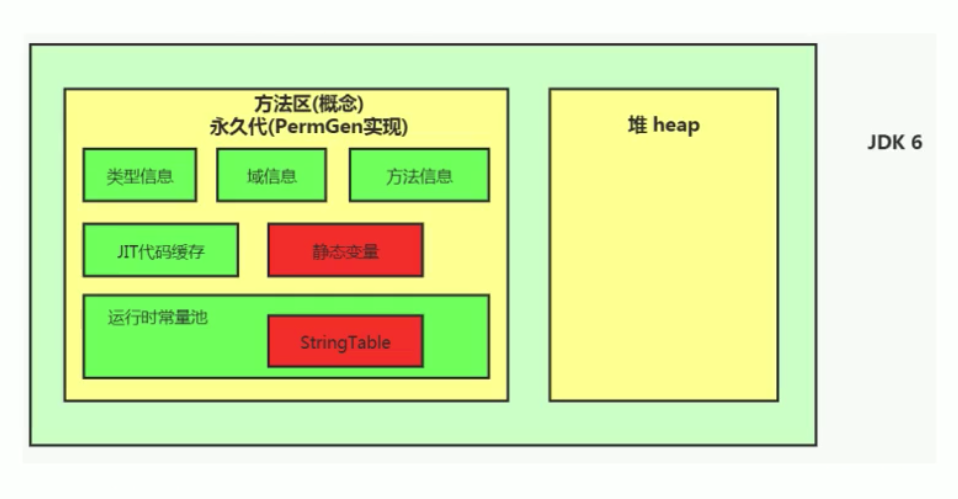
JDK1.6 之前 hotspot 虚拟机关于方法区的实现叫永久带,和堆内存一样都在JVM实例进程内,OOM的问题比较严重,GC也会频繁扫描这个区域,性能比较低
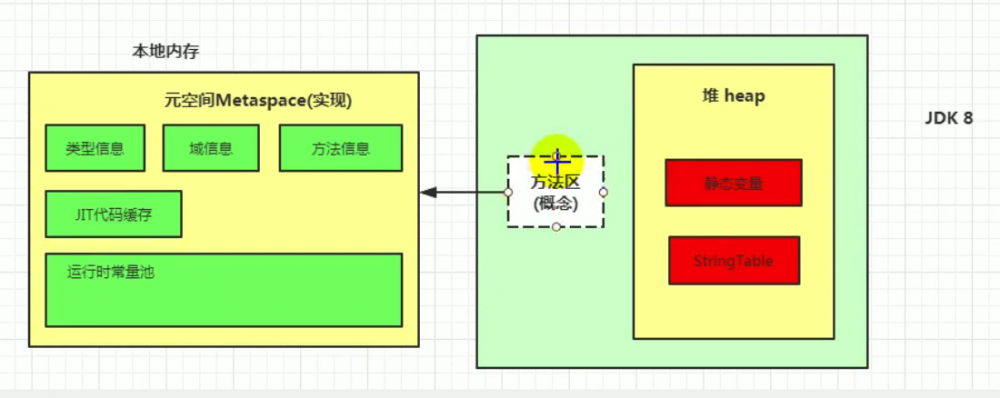
JDK1.8 hotspot 虚拟机换了个方法区的实现叫元空间,把类信息从JVM实例内存区域移出来,放到本地内存 native memory 中去了,这样 OOM 风险小多了,再也不怕加载的类太多爆 OOM 了,GC 扫描的频率也降低了
JVM 各部分之间联系很紧密,方法区承载类加载器加载、解析到内存中的字节码文件,记录类的元信息,包括:
类的信息: 字段信息: 方法信息: 类加载器的引用: class 引用: 常量池: JIT 即时编译器编译过后的代码缓存
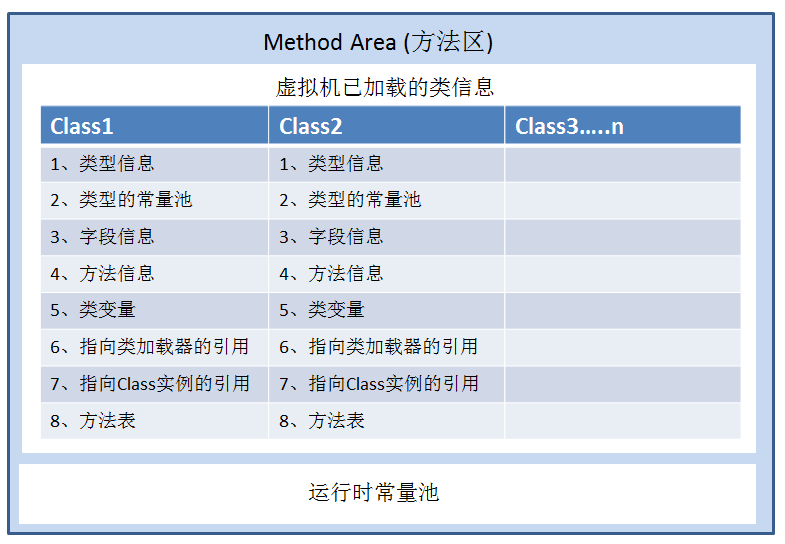
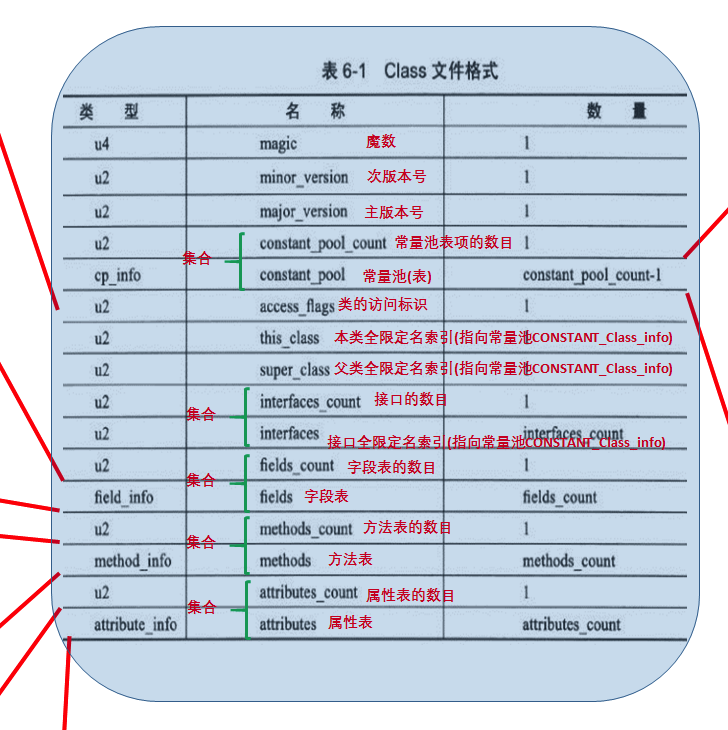
或者这张图,classFile 就是编译之后的class文件,它的数据结构就是这样的,单词不难,大家一看就知道咋回事了,就像一个Bean数据对象一样,记录一个类里面的都有啥,难点不好理解的是 constant_pool,这个下面会仔细说一下的
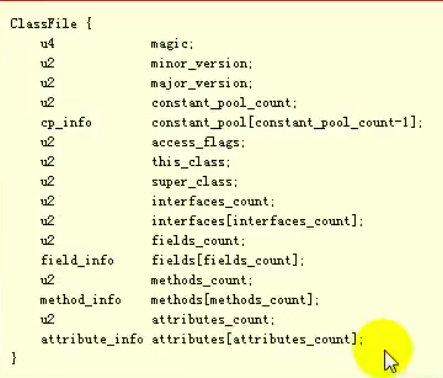
这是代中文对照的图:
堆、栈、元空间的相互关系:
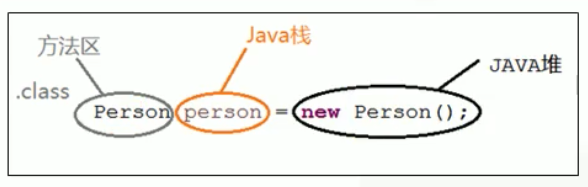
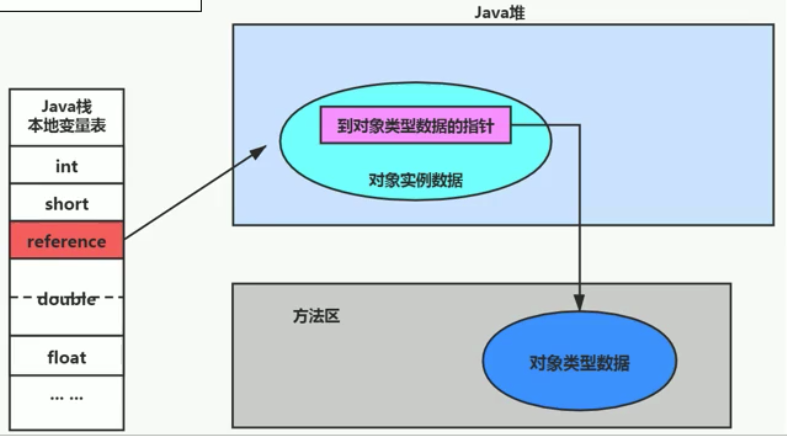
2. 从字节码入手
其实我们从反编译下字节码就知道怎么回事了,字节码文件会加载到方法区,也就是数据储存结构有些变化,但是东西还是字节码里面的东西
public class Max {
public static int staticIntValue = 100;
static {
staticIntValue = 300;
}
public final int finalIntValue = 3;
public int intValue = 1;
public static void main(String[] args) {
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void speak() {
int a = 10;
int b = 20;
int c = a + b;
}
}
复制代码
反编译下: java -v -p Max.class > Max.txt ,加 -p 是因为私有属性不加这个不先是,最后 > Max.txt 是把反编译出来的字节码写入到txt文件中,这样方便看
Classfile /Users/zbzbgo/Desktop/Max.class
// 字节码参数
Last modified 2020-6-20; size 746 bytes
MD5 checksum 5c6bccb4965bf8e6408c8e3ef8bca862
Compiled from "max.java"
// 包名+类名
public class com.bloodcrown.bw.Max
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER // 访问限定符
// 常量池,里面其实都是字符串,需要解析时加载
Constant pool:
#1 = Methodref #11.#30 // java/lang/Object."<init>":()V
#2 = Fieldref #10.#31 // com/bloodcrown/bw/Max.finalIntValue:I
#3 = Fieldref #10.#32 // com/bloodcrown/bw/Max.intValue:I
#4 = Long 100000l
#6 = Methodref #33.#34 // java/lang/Thread.sleep:(J)V
#7 = Class #35 // java/lang/InterruptedException
#8 = Methodref #7.#36 // java/lang/InterruptedException.printStackTrace:()V
#9 = Fieldref #10.#37 // com/bloodcrown/bw/Max.staticIntValue:I
#10 = Class #38 // com/bloodcrown/bw/Max
#11 = Class #39 // java/lang/Object
#12 = Utf8 staticIntValue
#13 = Utf8 I
#14 = Utf8 finalIntValue
#15 = Utf8 ConstantValue
#16 = Integer 3
#17 = Utf8 intValue
#18 = Utf8 <init>
#19 = Utf8 ()V
#20 = Utf8 Code
#21 = Utf8 LineNumberTable
#22 = Utf8 main
#23 = Utf8 ([Ljava/lang/String;)V
#24 = Utf8 StackMapTable
#25 = Class #35 // java/lang/InterruptedException
#26 = Utf8 speak
#27 = Utf8 <clinit>
#28 = Utf8 SourceFile
#29 = Utf8 max.java
#30 = NameAndType #18:#19 // "<init>":()V
#31 = NameAndType #14:#13 // finalIntValue:I
#32 = NameAndType #17:#13 // intValue:I
#33 = Class #40 // java/lang/Thread
#34 = NameAndType #41:#42 // sleep:(J)V
#35 = Utf8 java/lang/InterruptedException
#36 = NameAndType #43:#19 // printStackTrace:()V
#37 = NameAndType #12:#13 // staticIntValue:I
#38 = Utf8 com/bloodcrown/bw/Max
#39 = Utf8 java/lang/Object
#40 = Utf8 java/lang/Thread
#41 = Utf8 sleep
#42 = Utf8 (J)V
#43 = Utf8 printStackTrace
{
// 成员变量信息
public static int staticIntValue;
descriptor: I
flags: ACC_PUBLIC, ACC_STATIC
public final int finalIntValue;
descriptor: I
flags: ACC_PUBLIC, ACC_FINAL
ConstantValue: int 3
public int intValue;
descriptor: I
flags: ACC_PUBLIC
// 默认的构造方法
public com.bloodcrown.bw.Max();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: iconst_3
6: putfield #2 // Field finalIntValue:I
9: aload_0
10: iconst_1
11: putfield #3 // Field intValue:I
14: return
LineNumberTable:
line 8: 0
line 17: 4
line 19: 9
// 方法信息
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=1
0: ldc2_w #4 // long 100000l
3: invokestatic #6 // Method java/lang/Thread.sleep:(J)V
6: goto 14
9: astore_1
10: aload_1
11: invokevirtual #8 // Method java/lang/InterruptedException.printStackTrace:()V
14: return
Exception table:
from to target type
0 6 9 Class java/lang/InterruptedException
LineNumberTable:
line 23: 0
line 26: 6
line 24: 9
line 25: 10
line 27: 14
StackMapTable: number_of_entries = 2
frame_type = 73 /* same_locals_1_stack_item */
stack = [ class java/lang/InterruptedException ]
frame_type = 4 /* same */
public void speak();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=4, args_size=1
0: bipush 10
2: istore_1
3: bipush 20
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: return
LineNumberTable:
line 30: 0
line 31: 3
line 32: 6
line 33: 10
// 这是静态代码块和静态属性赋值,写代码时谁写在前面,谁的赋值就在前面,注意有先后顺序
static {};
descriptor: ()V
flags: ACC_STATIC
Code:
stack=1, locals=0, args_size=0
0: bipush 100
2: putstatic #9 // Field staticIntValue:I
5: sipush 300
8: putstatic #9 // Field staticIntValue:I
11: return
LineNumberTable:
line 10: 0
line 13: 5
line 14: 11
}
SourceFile: "max.java"
复制代码
大家看个意思,方法区储存的类信息其实和字节码差不了对少
3. 方法区的储存结构
图里的字符串常量池不方法区里,JVM 规范虽然是这样的,但是具体的虚拟机实现都会有变化的,具体看实际
-
存储位置:
方法区不在用户进程的内存中,而是在本地内存 native memory 中,这样的好处是加载过多的类也不会造成堆内存的OOM了 -
方法区数据结构:
操作系统中,可以有多个 JVM 实例,看着每个JVM都有自己的方法区。但实际上在 native memory 内存中,方法区只有一块。每个类加载器在方法区都可以申请一块自己的空间,类加载器相互之间不能访问,每个类加载器自己的空间内,给每一个类信息都分配一块空间,就像Map<Classload,Map<String,Class>>这样的数据结构一样。系统类加载器是 static 的,每个进程的系统类加载器是都是不同的对象,对应的方法区空间也不一样,所以他们之间加载的类信息是不能共享的,好比A进程加载Dog的1.3版本,B进程加载Dog的1.0版本,这并不影响进程A和B之间的独立运行 -
classload 和方法区class相互记录:
方法区里的class类信息对象会记录自己是哪个类加载器加载的,类加载器一样会记录自己加载过哪些类信息
4. 方法区的 OOM
方法区默认大小是 20.75M ,android 上是 20.79M ,最大值是一个无限大的数,但是实际上是物理内存的上限,超过这个上限一样也会 OOM
jinfo -flag MetaspaceSize 74290 -XX:MetaspaceSize=100m
方法区我们可以设置固定大小,也可以设定动态调整,默认是动态调整的,一旦方法区满了就会触发 Full GC,GC 会去回收方法区中不被用到的 class 类信息,什么时候 class 类信息不被用到呢。就是加载 class 类信息的 classload 销毁了,那么这个这个 classload 加载的所有的 class 类信息都无用了,可以被回收了
Full GC 要是发现还是不能方法区内存需求,就会扩大方法区的内存大小,但是一次肯定不会增加很多,估计就是几M 的事。这里就有个问题了,要是我们一上来设置的过小,我们加载的类又很多,那会方法区就会频繁的触发 Full GC,这是一个可以优化的点

5. 理解什么是常量池
常量池这东西我们应该清楚的,即便网上的资料,看那些文字描述基本看不懂,但是这不是我们不去理解的理由,方法区和类加载机制是紧密联系的,所以方法区的一切我们都应该知道
常量池这块挺复杂的:
classfile 里面的叫常量池 方法区里面的叫运行时常量池
他俩之间的关系:
-
字节码文件 classfile 被 classload 加载到内存之后,字节码文件中的常量池就变成运行时常量池了
一定要搞清楚他俩是什么,我一开始看这里的时候头疼啊,一会常量池,一会运行时常量池,我都怀疑网上的文章是不是写错了,去看《深入理解java虚拟机》这本书又写的不连贯,写的莫名其妙,看着描述的文字很多,但就是没说明白这是啥
其实他俩的关系就是一句话:文件里的字节码常量池加载到内存之后就是运行时常量池了。学习他俩其实把字节码的常量池搞明白就行了,剩下那个自然就懂了
先看看常量池的字节码吧,用的是前面反编译出来的字节码
Constant pool: #1 = Methodref #11.#30 // java/lang/Object."<init>":()V #2 = Fieldref #10.#31 // com/bloodcrown/bw/Max.finalIntValue:I #3 = Fieldref #10.#32 // com/bloodcrown/bw/Max.intValue:I #4 = Long 100000l #6 = Methodref #33.#34 // java/lang/Thread.sleep:(J)V #7 = Class #35 // java/lang/InterruptedException #8 = Methodref #7.#36 // java/lang/InterruptedException.printStackTrace:()V #9 = Fieldref #10.#37 // com/bloodcrown/bw/Max.staticIntValue:I #10 = Class #38 // com/bloodcrown/bw/Max #11 = Class #39 // java/lang/Object #12 = Utf8 staticIntValue #13 = Utf8 I #14 = Utf8 finalIntValue #15 = Utf8 ConstantValue #16 = Integer 3 #17 = Utf8 intValue #18 = Utf8 <init> #19 = Utf8 ()V #20 = Utf8 Code #21 = Utf8 LineNumberTable #22 = Utf8 main #23 = Utf8 ([Ljava/lang/String;)V #24 = Utf8 StackMapTable #25 = Class #35 // java/lang/InterruptedException #26 = Utf8 speak #27 = Utf8 <clinit> #28 = Utf8 SourceFile #29 = Utf8 max.java #30 = NameAndType #18:#19 // "<init>":()V #31 = NameAndType #14:#13 // finalIntValue:I #32 = NameAndType #17:#13 // intValue:I #33 = Class #40 // java/lang/Thread #34 = NameAndType #41:#42 // sleep:(J)V #35 = Utf8 java/lang/InterruptedException #36 = NameAndType #43:#19 // printStackTrace:()V #37 = NameAndType #12:#13 // staticIntValue:I #38 = Utf8 com/bloodcrown/bw/Max #39 = Utf8 java/lang/Object #40 = Utf8 java/lang/Thread #41 = Utf8 sleep #42 = Utf8 (J)V #43 = Utf8 printStackTrace 复制代码
大家看看这常量池的字节码感觉像啥,像不像list列表,有int索引,数据一行一行很规则
没错,常量池本质就是一张表,虚拟机根据字节码指令来这张表找到和这个类关联的类、方法名、参数类型、字面量等信息
大家注意啊,常量池里面存的都是字符串,为啥?class文件不是字符串能是什么,就算加载到内存里对应的还是字符串,只有类加载器根据这么字符串信息把这个类加载出来,这些字符串才有意思
所以像: java/lang/Object、java/lang/Thread、com/bloodcrown/bw/Max.intValue 这些,我们知道其实他们是什么,是类的类型,接口,方法,包名等等,常量池中的这些字符串就叫做 符号引用
但是单单字符串我们是没法用的,必须要类加载器把这些字符串描述的类都正式在内存中加载出来才有意义。这个过程在类加载机制中的解析环节,会把常量池中这些字符串转换成加载过后的class类型信息在方法区中的地址,这个地址叫做: 直接引用
从常量池->运行时常量池=从符号引用->直接引用,说白了就是把字节码中描述信息的字符串都正式加载成出来,生成对应的类、接口、注解等等可以使用的信息
总结一下,常量池的内容包括:
数值量: 字符串 类引用 字段引用 方法引用
那为什么要涉及一个常量池出来呢,既然都是字符串,我们写在用的地方不就好了嘛~距网上的解释,JVM 官方是考虑到有的字符串会重复被使用,为了尽可能减少class文件体积。另一个考虑是,每个类里面其实都涉及其他类,如果不用字符串代替class本身涉及到的其他的类型信息,那么就要把这些涉及到的类型信息都写在同一个class文件里,那么这回造成灾难性的后果,class文件大到难以接收,文件结构也会变得不可预期,大量的class文件中都会有重复信息,甚至涉及到不同类型的版本,这样就没法搞了
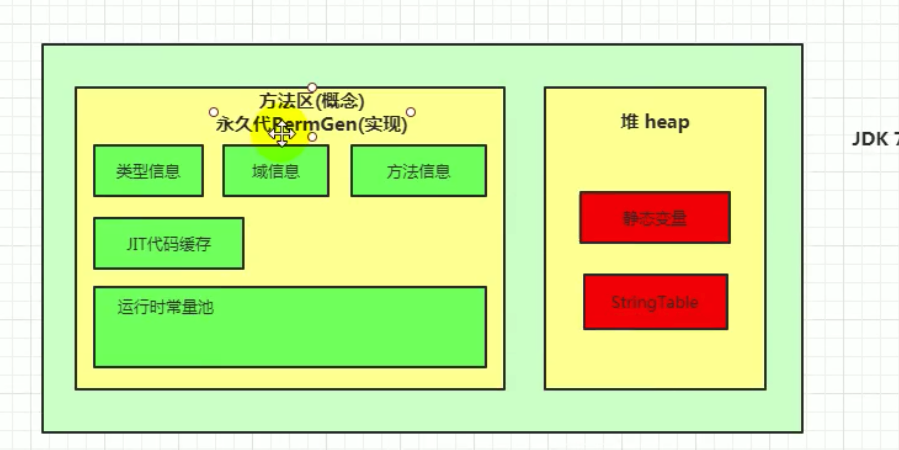
6. JDK1.8 方法区变化
前文说过,方法区是 JVM 规范的称为,只是一种建议规范,并且还没有做强制限制。具体设计成什么样,还得看看方法区的具体实现,永久带和元空间就是方法区的具体实现,区别很大
永久带这东西只有 hotspot 虚拟机再 JDK1.6 之前才有,其他虚拟机像 JRockit、J9 人家压根就不用,而是用自己的实现:元空间
永久代: 设计在JVM内存中,和堆内存连续的一块内存中,储存类元信息、字符串常理池、静态数据,因为有JVM虚拟机单个实例的内存限制,永久带会较多几率触发 FullGC,类加载的多还会出现 OOM,尤其是后台程序加载的模块多了
元空间: 设计在本地内存 native memory,没有了JVM虚拟机内存限制,OOM 基本就杜绝了,FullGC 触发的几率较低。类元信息随着方法区中的迁移,改在本地内存中保存,字符串常量池和静态数据则保存在堆内存中
JDK 1.6 之前方法区采用永久带,JDK1.8 开始,方法区换用元空间,JDK1.7 在其中起过度

OOM
遇到 OOM 呢, 第一时间看内存分布,用工具 dump 出一张内存快照出来,工具有很多
- 先看是不是有不合理代码生成了大量对象并且这些对象内存泄露了,占用了大量内存出去
- 再看内存泄露,一般单单内存泄露不会 OOM,但是可以优化内存使用
- 增加屋里内存
- 看看是不是某些大体积对象声明周期过长,比如 bitmap

接口的匿名实现类实际上是被作为一种类型来使用的,在每一个匿名实现类在方法区都会占据一块 class 空间
正文到此结束
- 本文标签: 软件 构造方法 http map 管理 图片 Android 性能优化 源码 开发 递归 线程 开发者 文章 需求 物理内存 web list Full GC https src 阿里巴巴 大数据 executor App 本质 定制 操作系统 缓存 Oracle UI ACE 代码 MQ java value 字节码 ip lib cat Bootstrap bean 空间 专心 翻译 参数 类加载器 科技 配置 生命 多线程 垃圾回收 实例 JVM IBM 总结 互联网 IDE constant Apple 数据分区 编译 快的 synchronized tar 安装 博客 API IO 解析 索引 tab final 进程 数据 免费 时间 id ssl
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

