JAVA常用数据结构
这篇文章主要记录下平常开发中常用的数据结构,会简单说明每种数据结构的优点、缺点、特点等等。
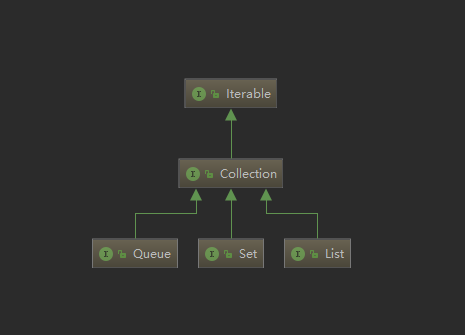
JDK提供了一组主要的数据结构实现,如List、Map、Set、Queue 等常用数据结构。这些数据都继承自java.util.Collection接口,并位于java.util包内。
List
-
ArrayList
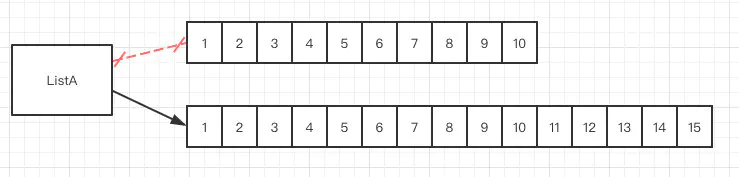
- 基于动态数组集合,可以动态的增加、删除元素,动态扩容等,默认初始容量10,超出上限会扩容至:
int newCapacity = oldCapacity + (oldCapacity >> 1);也就是原来容量的1.5倍。 - 优点:按下标索引速度快(O(1))。缺点:插入删除会慢(O(n))。
- 一个容量10的ArrayList。

- 扩容1.5倍后的样子
- ArrayList 扩容源码
/** * Increases the capacity to ensure that it can hold at least the * number of elements specified by the minimum capacity argument. * * @param minCapacity the desired minimum capacity */ private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; // 旧的容量 + 旧的容量左移一位(也就是除以2) int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); } 复制代码 - 基于动态数组集合,可以动态的增加、删除元素,动态扩容等,默认初始容量10,超出上限会扩容至:
-
LinkedList
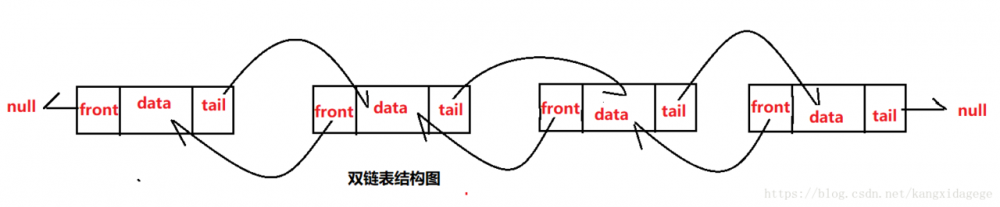
- 基于链表的集合,是一个双向链表,没有初始化大小,也没有扩容的机制,会一直在前面或者后面新增Node。
- 优点:便于存取,只要改变头尾节点指向 (O(1))。缺点:索引慢,极端情况会出现从头结点遍历到最后一个节点的情况 (O(n))。
- 单向链表:每个节点只会指向下一个节点
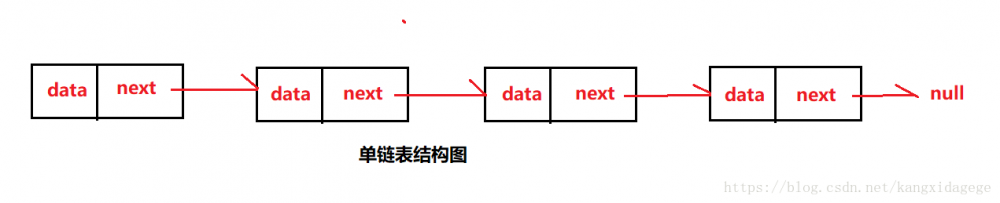
- 双向链表:每个节点会保存上一个节点和下一个节点
-
Vector
- 也是基于数组的一个集合,对一些操作数据的方法加了synchronized,可以看做是ArrayList一个同步、线程安全的版本
- 优点:线程安全的。缺点:同步必然会导致效率慢。
-
小结
- 上面几种集合都属于线性数据结构,也是有序,元素之间都有关联关系。
- 基于数组的:在分配内存时是一块规整的内存,所有数据都紧邻着。(也有说数组不属于线性结构的,希望大佬指正)
- 基于链表的:虽然在内存里都是不连续的,但是每个节点都会保留下一个节点的引用。
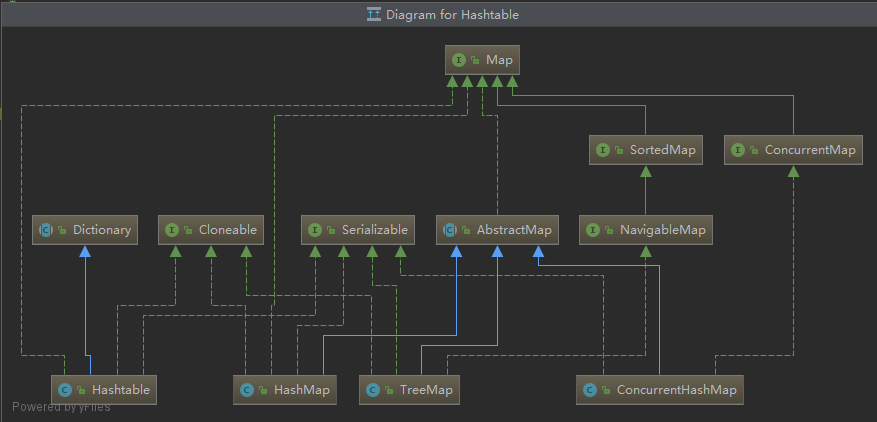
Map
Map 是一种把键对象和值对象映射的集合,它的每一个元素都包含一对键对象和值对象。 Map没有继承于Collection接口。
-
HashMap
- HashMap 底层是数组+链表(jdk1.8是数组+链表/红黑树),HashMap可能也是应用最多的数据结构了。
- 初始容量
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 复制代码- 负载因子:据说0.75是在时间和空间上一个较为合适的数,过高容易哈希碰撞,过低容易浪费空间
/** * The load factor used when none specified in constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f; 复制代码
- 阈值
/** * The next size value at which to resize (capacity * load factor). * * @serial */ int threshold; 复制代码- 扩容机制:
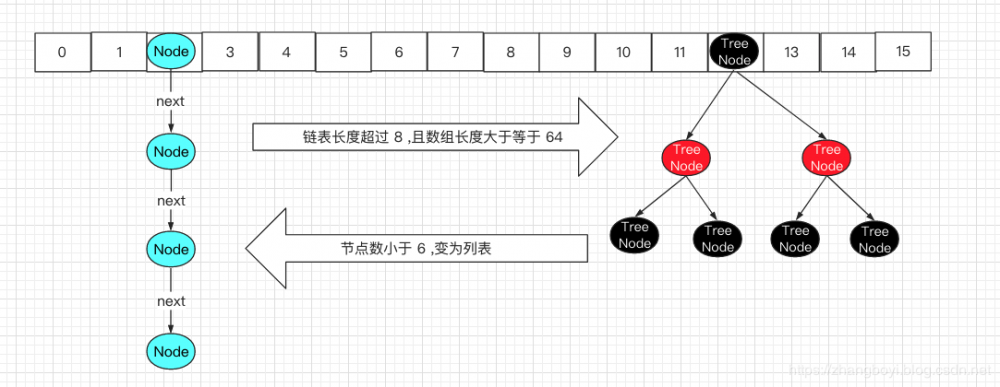
当size > (capacity * load factor)时会触发扩容(newCap = oldCap << 1)。源码resize()方法有点长,这里就不贴了。 - 何时转换红黑树:
//条件1:当链表长度>=8 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; //条件2:并且桶数量>=64链表: final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; //如果小于64将继续扩容 if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { TreeNode<K,V> hd = null, tl = null; do { TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); } } 复制代码- 何时退化成链表:
当长度小于6又会退化成链表(如果小于8又转换成链表,可能会出现链表与红黑树反复转换的情况),在removeTreeNode()和split()方法都触发判断逻辑。 - HashMap 链表红黑树转换过程
-
HashTable
其实就是HashMap的一个线程安全版本,像Vector和ArrayList的关系一样,对内部的方法都加了
synchronized关键字修饰。public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable { public Hashtable(int initialCapacity) { this(initialCapacity, 0.75f); } } 复制代码- 缺点:因为采用
synchronized保证同步,每次都会锁住整个map,所以高并发线程在争夺同一把锁的时候性能急剧下降。
- 缺点:因为采用
-
TreeMap
平常开发中用的不多,是一个红黑树版本的map,实现了
NavigableMap<K,V>并且NavigableMap又继承了SortedMap<K,V>类,SortedMap接口有一个Comparator<? super K> comparator();比较器,所以TreeMap是支持比较排序的。public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable { public TreeMap(Comparator<? super K> comparator) { //支持比较器 this.comparator = comparator; } static final class Entry<K,V> implements Map.Entry<K,V> { //红黑树结构 K key; V value; Entry<K,V> left; Entry<K,V> right; Entry<K,V> parent; boolean color = BLACK; /** * Make a new cell with given key, value, and parent, and with * {@code null} child links, and BLACK color. */ Entry(K key, V value, Entry<K,V> parent) { this.key = key; this.value = value; this.parent = parent; } } } 复制代码- TreeMap的结构

- 特点:采用红黑树实现,是一个有序的map。
- TreeMap的结构
-
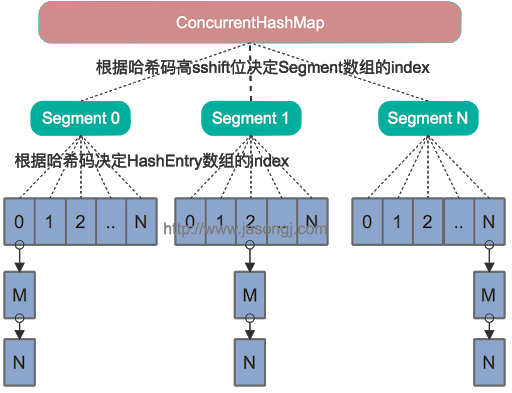
ConcurrentHashMap
底层也是HashMap,同时保证了线程安全,与HashTable不同的ConcurrentHashMap采用分段锁思想,抛弃了使用synchronized修饰操作方法的同步方式。
-
分段锁思想:
都知道HashTable效率低下的原因是因为整个容器只有一把锁,多线程争抢同一把锁导致。 ConcurrentHashMap分段锁指得是将数据分成一个个的
Segment<K,V>,每个Segment又继承ReentrantLock,这样一个map容器就会有多个Lock,每个Lock锁不同的数据段,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
static class Segment<K,V> extends ReentrantLock implements Serializable { private static final long serialVersionUID = 2249069246763182397L; final float loadFactor; Segment(float lf) { this.loadFactor = lf; } } 复制代码- 1.7与1.8的区别:
1. 因为底层是HashMap,so 1.8之后也变成了数组+链表/红黑树。
2. 1.8之后放弃了分段锁,采用了synchronized+CAS来保证并发。 - 1.8为何放弃分段锁:
1. 我认为主要是1.8对synchronized进行了优化(偏向锁、轻量级锁、自旋锁、自适宜自旋) 2. 加入多个分段锁浪费内存空间。 3. 生产环境中, map在放入时竞争同一个锁的概率非常小,分段锁反而会造成更新等操作的长时间等待。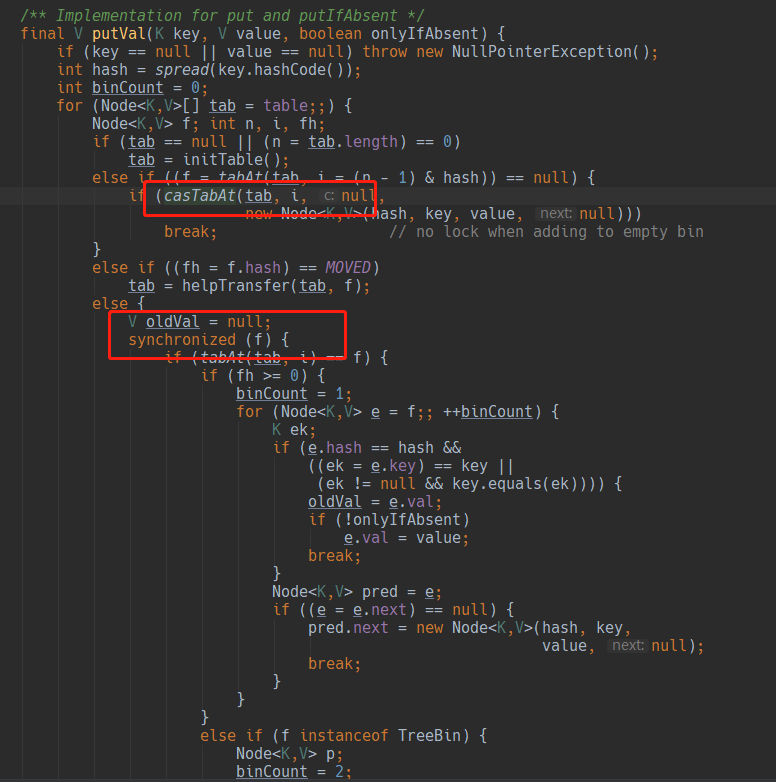
-
Set
-
HashSet
HashSet 基于HashMap实现,利用Map的key不能重复来实现Set的元素唯一性
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable { private transient HashMap<E,Object> map; // 底层就是一个HashMap // Dummy value to associate with an Object in the backing Map private static final Object PRESENT = new Object(); public HashSet(Collection<? extends E> c) { map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); addAll(c); } // HashSet每次add()都是将值插入Key上,而Value统一用一个static final修饰的Object对象 public boolean add(E e) { return map.put(e, PRESENT)==null; } } 复制代码 -
LinkedHashSet
LinkedHashSet 基于LinkedHashMap实现,继承自HashSet,可以看出是一个有序的Set(可以像LinkedHashMap自定义排序)
public class LinkedHashSet<E> extends HashSet<E> implements Set<E>, Cloneable, java.io.Serializable { public LinkedHashSet() { super(16, .75f, true); } public LinkedHashSet(Collection<? extends E> c) { super(Math.max(2*c.size(), 11), .75f, true); addAll(c); } } 复制代码
正文到此结束
- 本文标签: CTO 同步 Collection LinkedList java 安全 final IO 索引 线程 空间 锁 queue ConcurrentHashMap 时间 开发 文章 HashTable HashSet https 代码 list ACE HashMap 并发 struct 多线程 value 删除 高并发 zab node 数据 key http id synchronized tab UI 遍历 src 希望 ArrayList 源码 map
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

