将FART和Youpk结合来做一次针对函数抽取壳的全面提升

本文为看雪论坛精华文章
看雪论坛作者 ID:一颗金柚子
0x00 声明
相信授人以鱼不如授人以渔。
0x01 前言
作为App安全逆向分析的第一步,针对加固手段衍生的脱壳技术正在蓬勃发展,由于本人所学知识还未能进入VMP阶段,因此本帖就基于目前常见的函数抽取壳而展开。
学术界有了不少有意思的脱壳系统。 AppSpear搜集内存中的运行时Dalvik数据结构(Dalvik Data Structure,以下简称DDS)来重新组装一个正常的Dex文件。
一般而言,一个应用程序只能通过某些固定的系统服务完成转换。因此,AppSpear就选择通过监控某些JNI接口并确定何时开始收集Dalvik数据结构。
其次,无论加固厂商加密原始数据有多复杂,Dalvik都很少修改原始字节码的语义。Dex加载过程结束后,从DDS中就可观察到原App的字节码的准确内容。
最后取出anti-analysis代码并进一步综合Dex文件、清单文件和其他资源文件然后重打包并进行解包分析。
有很多研究者开始对整个运行环境进行监控从而观察内存读写操作来抓住解包时机。Lei X等人提出了一种新的自适应方法,并开发了一个名为PackerGrind的新系统来脱壳应用程序。
PackerGrind是取得了一定的效果,但是如果打包的应用程序将不同的代码加载到相同的内存中,并在不同的条件下执行它们,PackerGrind就因为缺乏语义信息从而无法判断哪些代码是真实的;DROIDUNPACK 是Duan Y 等人提出的一种脱壳工具,基于整个系统仿真监视程序执行和内存操作执行。
由于DROIDUNPACK是建立在整个系统仿真之上,实施反仿真技术将不可避免地破坏后续的分析而且成本相对后面要讲到的脱壳工具来说较大。
看雪论坛中出现了不少前辈们的作品。 DexHunter是在Android系统代码调用函数dvmDefineClass(Dalvik下的函数)进行类加载之前,主动地一次性加载并初始化Dex文件所有的类。
DexHunter主要关注如何在内存中定位和转储Dex。DexHunter脱壳过程中所使用的location和fileName是其技术人员通过人工分析得到的,通过对每个加固服务的加固方式进行详细地分析和研究,选择固定的特征字符串作为脱壳开始的标志。
采用这样的方法有一个明显的限制:如果加固厂商针对不同的App有不同特征的加固方法,那么DexHunter就不能再准确地定位出脱壳起点。
Fupk3是由美团大佬写的一个Android半自动脱壳机,首先遍历gDvm中的dvmUserDexFiles结构,获取所有cookie; 其次对内存中的Dex文件,遍历触发函数,并通过在解析器处插桩,截取解密后的code_item,获取code_item后直接返回不执行该函数。
然后对内存中截取出来的数据进行重组,生成Dex文件。最后利用修改过的smali/baksmali对dump下来的dex文件进行修复。
Fupk3基于Android 系统 KTU84P (4.4.4_r1)开发,可以对没被虚拟化的Java层函数进行转储。 然而,Fupk3还是基于Dalvik环境的自动化脱壳方案,其中Fupk3首次将脱壳粒度细化到函数级别。
DexHunter和Fupk3都可以应对函数抽取型加固壳。但很可惜的是,两个优秀方案以及前文提及的AppSpear由于环境的限制无法应对Android8.0以及更高版本ART的系统变化。
时间点来到2019年,FART横空出世,结合了DexHunter和Fupk3的优点(主动调用链不影响正常调用的构造和CodeItem结尾计算方法),开始着力于ART高版本环境下函数粒度的主动调用。
FART告诉我们的一个道理是:无论函数抽取壳做得有多么复杂,一定存在某一个时刻,Dex的部分数据肯定是还原的状态。通过三种组件的配合使用可以达到一种“输入->输出”自动化的流程,并且寒冰老师也在他的文章中提及三个组件可以分离使用,这种组件独立性为结合Frida提供了无限的可能性。稍微多嘴讲一下FART的一些优秀特征:
关于Fart的脱壳点:
有两点,一个点是Execute函数,另一个点就是送到主动调用链的时候。
①初始化函数<clinit> - Execute => dumpDexFileByExecute
②其他正常函数=> DexFile_dumpMethodCode => myfartInvoke => Invoke => dumpArtMethod
关于主动调用链:
①启动fart线程-(getClassloader来获取ClassLoader)>
②fartwithClassLoader-(反射获取mCookie)>
③loadClassAndInvoke-(dumpMethodCode将各种函数转化成ArtMethod类型并送入我们的fake_Invoke参数包装)>
④送入系统的Invoke-(调用dumpArtMethod实现第二个脱壳点)。
Fart主动调用前提:
①获取appClassLoader;
②通过ClassLoader加载到所有类 ;
③通过每个类获取到该类下的所有方法【包括构造函数和普通函数】。
时间再次推移到2020年。 一款针对Dex整体加固和应对各式各样Dex抽取的脱壳机——Youpk于看雪论坛诞生。
作者在参考链接中明确表示是结合了Fupk3和FART二者的优点,其特色是着重于加深主动调用流程至Switch解释器的每条汇编指令执行前回调。Youpk在回调中仅仅做了一项操作:对CodeItem的直接转储。当然,Youpk作者在文中提及,针对某些厂商的抽取, 可以等待几条指令真正被执行且CodeItem解密后再进行dump 。
//interpreter_switch_impl.cc
// Code to run before each dex instruction.
#define PREAMBLE() /
do { /
inst_count++; /
bool dumped = Unpacker::beforeInstructionExecute(self, shadow_frame.GetMethod(), /
dex_pc, inst_count); /
if (dumped) { /
return JValue(); /
} /
if (UNLIKELY(instrumentation->HasDexPcListeners())) { /
instrumentation->DexPcMovedEvent(self, shadow_frame.GetThisObject(code_item->ins_size_), shadow_frame.GetMethod(), dex_pc); /
} /
} while (false)
从Youpk最关键的回调过程来分析,beforeInstructionExecute这个方法的传参依靠ins_count即指令数就可以判断执行了多少条指令。比如ins_count等于5时代表已经执行了5条指令。
不过,我们可以通过一些加固壳中的反编译内容发现有些指令是参差不齐的,有可能关键解密相关函数一次在3条以内,一次在5条以外,如果来来回回查看个数似乎略失自动化的意义。
因此我们通过接下来结合对Youpk的分析,强化FART。
0x02 实验
Youpk在文中写到构造主动调用链时,检索Dex文件中所有的类时类的数目大小通过NumClassDefs()来获得,坐标在/art/runtime/dex_file.h。

而FART中调用原生方法getClassNameList获取当前dexfile对象下的所有类名并存储为数组便于进行类的遍历,Youpk在遍历类的时候是在unpacker.cc中进行,说明它此时已经进入了Native层,FART的遍历还是在Java层,这一区别可能涉及到Java和C++中循环开销这里先暂且不涉及太多。Youpk选择类似forName的方式解析并初始化Class,因为初始化会帮我们链接并设置好非常多的信息。
FART中我们的Java层传递过来的method是使用反射方法加载的,但我们并没有对它真正进行调用,而是通过dumpMethodCode函数把它转为ArtMethod函数并传递给了Invoke,这流程是一种模拟调用 【FART中dumpMethodCode这个函数就是模拟了CallxxxxxMethod的流程】 。
因此根据Youpk的解析并初始化思路,我选择在jobject2ArtMethod中进行一些修改。因为这里是Method转ArtMethod的关键之处。
我们可以用Java到Native的方式去类似地实现一个:观察GetMethodID函数源码实现,最终调用的FindMethodID是以“初始化—为ArtMethod赋值—加密ArtMethod使其成为jmethodID类型”为流程进行的。
不过,现在我们需要的并不是让其加密,因为我们不是真正地去使用CallxxxxMethod,而是将其在构造后直接送入ArtMethod::Invoke。现在目的明确且为了符合Youpk思路,我们只需要完成最重要的事情—— 初始化 ,然后再返回即可。
主要修改art/runtime/native/java_lang_reflect_Method.cc。
extern "C" ArtMethod* jobject2ArtMethod(JNIEnv* env, jobject javaMethod) {
ScopedFastNativeObjectAccess soa(env);
ArtMethod* method = ArtMethod::FromReflectedMethod(soa, javaMethod);
//add
ObjPtr<mirror::Class> declaring_class = method->GetDeclaringClass();
if (UNLIKELY(!declaring_class->IsInitialized())) {
StackHandleScope<1> hs(soa.Self());
HandleWrapperObjPtr<mirror::Class> h_class(hs.NewHandleWrapper(&declaring_class));
if (!Runtime::Current()->GetClassLinker()->EnsureInitialized(soa.Self(), h_class, true, true)) {
return nullptr;
}
}
//addend
return method;
}
对其他壳还好,但是在实际某款App的测试中发现这个初始化会引起一些问题(经研究发现这个壳当看到如果 对这些activities中的关键类进行初始化就对程序进行了一种退出保护 )。
在这种情况下Youpk可能就失去了后续所有步骤的进行,因此初始化这里还需要借鉴FART的策略: 通过壳最后的ClassLoader,经过反射思路使用不带初始化过程的loadClass加载类 ,并且这里要在Java层中进行,方便将类进行传递和储存。
================================根据Youpk的思路,构造完整的主动调用链=================================
从LinkCode源码中可以知道,无论一个类方法是通过解释器执行,还是直接以本地机器指令执行,均可以通过ArtMethod类的成员函数GetEntryPointFromCompiledCode获得其入口点,并且该入口不为NULL。
不过,Invoke并没有直接调用该入口点,而是通过Stub来间接调用。 这是因为ART需要设置一些特殊的寄存器。同时,ArtMethod::Invoke会在其中判断需要执行的函数时运行在什么模式的,①解释模式②Quick模式③JNI函数。
我们要恢复的函数肯定是会在解释模式下执行的【这个原因我会在后面讲到】,因此我们只关注这一部分区域。
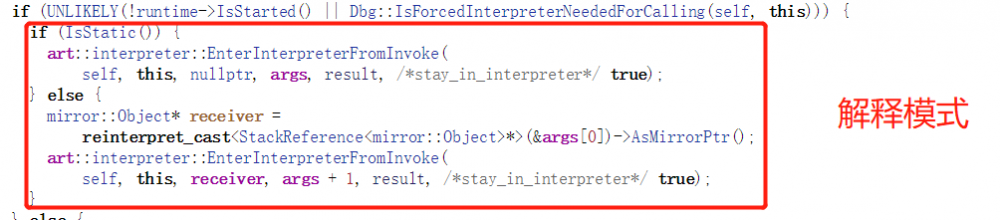
首先判断是否是Native化的函数,如果是则主动调用没有意义,反之,则进入主动调用连。
//art/runtime/art_method.cc
//ArtMethod::Invoke
if (Callflag == 5201314){
const DexFile::CodeItem* code_item= this->GetCodeItem();
if(LIKELY(code_item != nullptr)){
ManagedStack fragment;
self->PushManagedStackFragment(&fragment);
if(IsStatic()){
art::interpreter::EnterInterpreterFromInvoke(
self, this, nullptr, args, result, false);
LOG(ERROR)<<"EnterInterpreterFromInvoke is ok!";
}else{
art::interpreter::EnterInterpreterFromInvoke(
self, this, nullptr, args+1, result, false);
LOG(ERROR)<<"EnterInterpreterFromInvoke is ok!";
}
self->PopManagedStackFragment(fragment);
}
return;
}
}
//addend
可以看到,进行了静态函数和非静态函数的判断,静态函数的参数数量会比非静态少一个,因为非静态需要一个对象。构造“完整”的主动调用链首先 一定要把握好一个重要原则“不真实执行” ,一些参数可以设置为空,但关键的参数还是得构造。
比如这里我们将receiver的位置置空,由于其他位置不能是nullptr,所以都需要我们根据能执行程度而构造,例如self是当前线程、ArtMethod的位置则是this以及参数个数的位置是args和args+1。
而且在构造的同时,在函数的最前方需要加入 识别主动调用链到来的标志——5201314 。我们将继续进入解释模式下的EnterInterpreterFromInvoke函数,并且当主动调用链完成调用之后我们直接return,不让它继续真实执行。
EnterInterpreterInvoke这个函数前面部分都在做参数压栈操作,最后几行才真正进入主题。

①如果不是Native,那么调用Execute执行,Execute就是ART的解释器入口代码,Dex的字节码是通过ArtMethod::GetCodeItem函数获得,由Execute逐条执行。
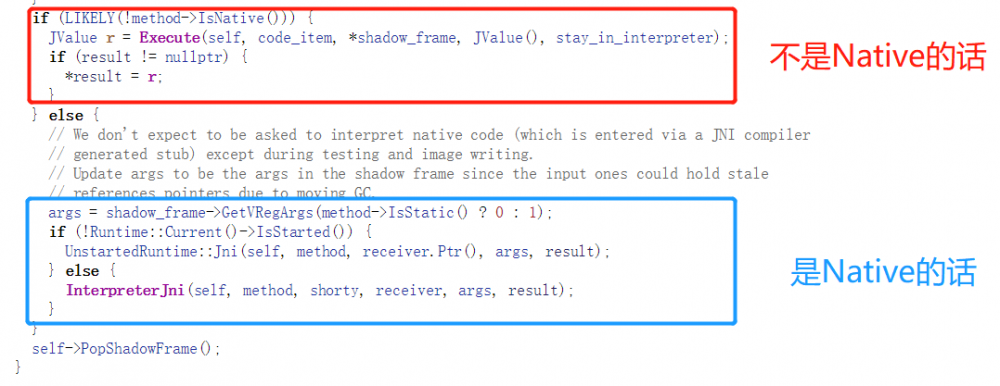
②Native函数则调用InterpreterJni。InterpreterJni通过GetEntryPointFromJni来获得native的函数的入口点,跳转并执行。
显而易见,我们想要搞定的函数肯定不是Native,因此走①。
构造思路:
在经过构造失败多次后发现,EnterInterpreterInvoke这个函数在它的逻辑中有个不得不提的操作就是它会通过SetVRegReference去追溯参数内容,因此如果参数不合法,会造成异常。
在构造这个函数内部逻辑的时候,首先想到由于我们自定义传递的参数有一些是Null(或者因无法实际获取其真实的内容而假设构造的参数存在),因此不让其指向o.Ptr和receiver.Ptr的指针。
我们选择使用SetVReg来替代,因为这是一个ART源码中默认使用的方法。可以发现EnterInterpreterInvoke中Switch语句default中使用SetVReg函数来进行传参,且在最末尾明确看到它是不会去解引用参数的内容的。
SetVRegLong则与SetVReg同理:
271 void SetVReg(size_t i, int32_t val) {
272 DCHECK_LT(i, NumberOfVRegs());
273 uint32_t* vreg = &vregs_[i];
274 *reinterpret_cast<int32_t*>(vreg) = val;
275 // This is needed for moving collectors since these can update the vreg references if they
276 // happen to agree with references in the reference array.
277 if (kMovingCollector && HasReferenceArray()) {
278 References()[i].Clear();
279 }
280 }
原理是源码在非解引用的情况中均使用SetVReg和SetVRegLong来进行参数的传递,而不去使用SetVReference解引用我们构造的参数。
前面也讲到,主动调用链来的函数并非Native函数,我们最终是会进入Execute函数,因此在Execute前面的函数我们都需要保留并完整地执行完成。当真正执行完Execute之后保存结果寄存器的值,然后抛出栈帧并返回。
Execute函数中如果有 jit,并且 jit 编译出了对应 method 的 quick code,那么选择通过 ArtInterpreterToCompiledCodeBridge 这个去执行对应的 quick code。
如果这些条件不满足,那么根据kInterpreterImplKind选择 Mterp 或者 Switch 类型的解释器实现来解释执行对应的 Dalvik 字节码。
因为默认使用 Mterp 类型的 Interpreter 实现,所以大多数情况下会调用 ExecuteMterpImpl() 函数来解释执行 Dalvik 字节码。
Mterp底层是由汇编语言实现,虽然执行效率很高,但是改动非常麻烦。因此在构造时选择解释器的类型为Switch方式,原因是它的底层由C++代码实现,可读性高且可操作空间大。
Interpreter的工作目的就是将传进来的Java方法使用机器能理解的语言去解释将会执行的操作。Switch实现方式是通过计步器逐条执行指令。
ExecuteSwitchImpl中首先通过GetDexPC()获取初始时候的执行步数; Instruction::A t(insns + dex_pc) 获得将要执行的指令语句(insns是codeitem的基地址);再根据指令选择将要执行的case条件;执行完相应操作之后通过 Next_?xx函数 跳转到下一次将要执行的指令(本次执行的指令占几个字节,?就为几);每次执行完一个循环,重新设置计步器。
通过前面的一些提到的关键函数,我画了一张流程图出来便于梳理过程和加深理解:
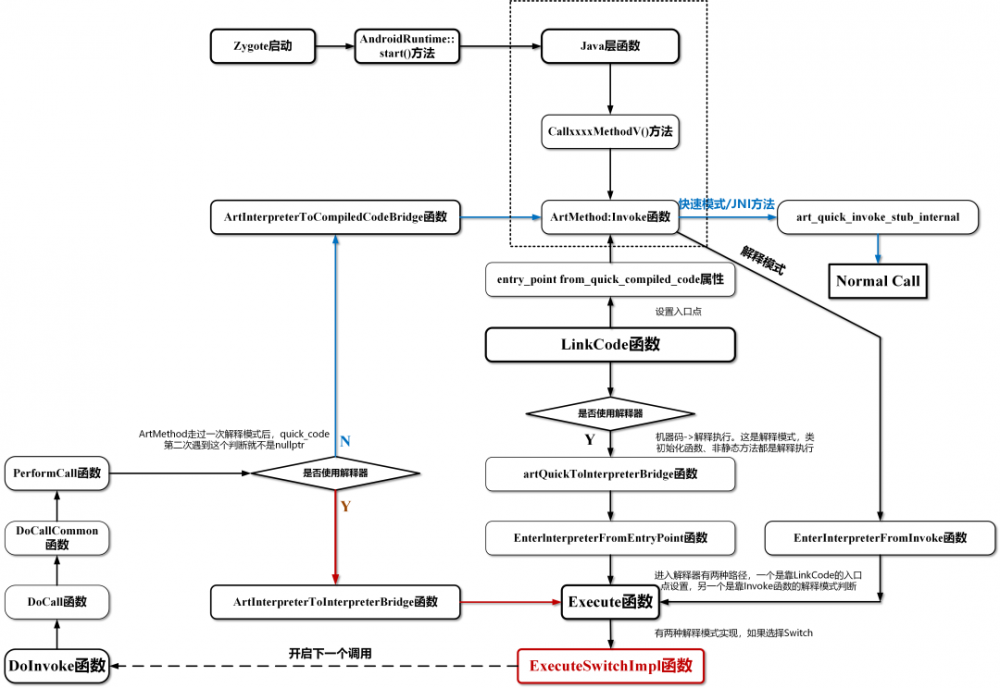
本帖所讲的是右侧第二种进入解释器的路径,因为这可以让所有的函数都可以进入解释模式。第一种进入方法静态方法就不是经过Execute,因此无法全面覆盖所有的函数。
这张图中,有一个判断函数值得注意,即ShouldUseInterpreterEntrypoint(是否使用解释器函数。
bool ClassLinker::ShouldUseInterpreterEntrypoint(ArtMethod* method, const void* quick_code) {
if (UNLIKELY(method->IsNative() || method->IsProxyMethod())) {
return false;
}
if (quick_code == nullptr) {
return true;
}
Runtime* runtime = Runtime::Current();
instrumentation::Instrumentation* instr = runtime->GetInstrumentation();
if (instr->InterpretOnly()) {
return true;
}
if (runtime->GetClassLinker()->IsQuickToInterpreterBridge(quick_code)) {
// Doing this check avoids doing compiled/interpreter transitions.
return true;
}
if (Dbg::IsForcedInterpreterNeededForCalling(Thread::Current(), method)) {
// Force the use of interpreter when it is required by the debugger.
return true;
}
....
}
可以看到上面每个判断条件都会作为是否使用 Interpreter 模式的一个依据,我们主要关注一下下面几个条件:
quick_code == nullptr
instr->InterpretOnly()
IsQuickToInterpreterBridge(quick_code)
……
当上面这几个条件有一个满足时,ShouldUseInterpreterEntrypoint 就会返回 true,使用 Interpreter 模式
到这里可能会有个疑问: quick_code那又是怎么获取到的呢?
const void* quick_code = method->GetEntryPointFromQuickCompiledCode();
//机器码地址为空或者是调试状态等,需要解释模式
bool enter_interpreter = class_linker->ShouldUseInterpreterEntrypoint(method, quick_code);
if (method->IsStatic() && !method->IsConstructor()) {
//静态方法且不是类初始化"<clinit>"方法,设置入口地址为art_quick_resolution_trampoline
//跳转到artQuickResolutionTrampoline函数。该函数和类的解析有关
//初始化完毕后会调用FixupStaticTrampolines()来更新入口地址为正确的机器码。
method->SetEntryPointFromQuickCompiledCode(GetQuickResolutionStub());
} else if (quick_code == nullptr && method->IsNative()) {
//jni方法,设置入口地址为art_quick_generic_jni_trampoline,跳转到artQuickGenericJniTrampoline函数。
method->SetEntryPointFromQuickCompiledCode(GetQuickGenericJniStub());
} else if (enter_interpreter) {
//解释执行,设置入口地址为art_quick_to_interpreter_bridge,跳转到artQuickToInterpreterBridge函数。
method->SetEntryPointFromQuickCompiledCode(GetQuickToInterpreterBridge());
}
在LinkCode中,第一句代码就是quick_code的获取方式,它使用了GetEntryPointFromQuickCompiledCode方法。ArtMethod对象第一次链接的时候肯定是需要运行在解释模式下的,因为在进入LinkCode之前没有其他函数会执行 SetEntryPointFromQuickCompiledCode这个步骤,因此这里是设置入口点的起始位置。
那么,进入解释模式的判断点ShouldUseInterpreterEntrypoint中quick_code为nullptr只有可能是一个函数第一次执行的时候。因此当对象第二次经过这个判断时,就会返回false,并经过流程再次路过ArtMethod::Invoke然后进入Quick模式。
Fupk3中F8大佬曾在论坛提示过,针对“ 有的函数抽取加固,是在原函数中插入一些还原相关的新指令,要真正执行时才能真正还原 ”这样的情况时:预读取一条指令,判断是否是壳的解密代码,如果是的话需要执行完再dump method。
那么问题一就来了, 什么才是已还原的指令该有的第一条指令呢?
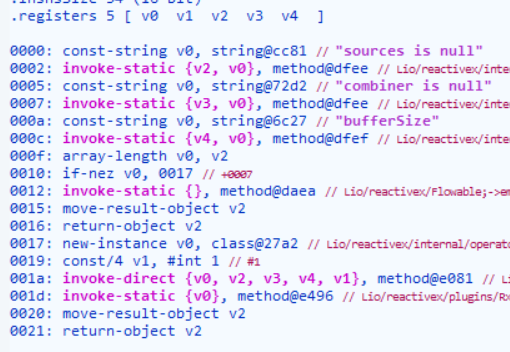
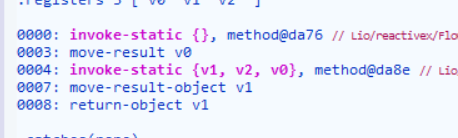
可以看到,正常的指令正如上图所展示的那样,有很多的invoke-xxx指令,也有很多参数的赋值。由于有多样的特征我们不好定量,我们可以反其道而行之, 可以观察壳中的第一条指令是什么 ,如果是像这样的壳:
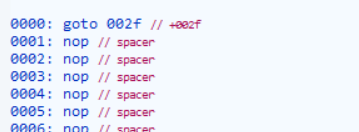
我们就可以判断执行的时候第一条指令是否为goto相关指令, 如果是则需要真正执行这个流程 ,若不是可以直接dump method。
那么问题二就来了:怎么真正执行goto以后的这个流程?

可以看到上图的goto 002f是强转到002f的位置上进行参数的赋值,随后进入invoke-static中调用,invoke-xxxx是开启下一个调用的“跳板”,我们针对这个指令做处理,令其执行完后dump,不再执行后面的goto 0001的操作。
下面是invoke-static指令相关代码:
case Instruction::INVOKE_STATIC: {
PREAMBLE();
bool success = DoInvoke<kStatic, false, do_access_check>(
self, shadow_frame, inst, inst_data, &result_register);
POSSIBLY_HANDLE_PENDING_EXCEPTION(!success, Next_3xx);
break;
}
因此我们可以如下进行改动:
//针对每一种dex指令处理。每种dex之前,都有一个PREAMBLE宏,就是调用instrumentation的DexPcMovedEvent函数。
case Instruction::INVOKE_STATIC: {
PREAMBLE();//这里保留
//修改
//调用DoInvoke,这个函数是真正执行invoke-static逻辑的关键。
bool success = DoInvoke<kStatic, false, false>(
self, shadow_frame, inst, inst_data, &result_register);
//POSSIBLY_HANDLE_PENDING_EXCEPTION(!success, Next_3xx);
//执行完就返回到主动调用链入口处等待下一个函数
return JValue();
}
而据Youpk作者的思路,PREAMBLE()所用到的beforeInstructionExecute在art_method.cc中我原本是这么写的:
//addYoupk
extern "C" bool beforeInstructionExecute(ArtMethod *method, uint32_t dex_pc, int count_ins, int Callflag ) REQUIRES_SHARED(Locks::mutator_lock_) {
//判断主动调用链标识
if (Callflag == 5201314 && count_ins > 2) {
dumpArtMethod(method);
return true;
}
return false;
}
//addYoupkend
我在Youpk的帖子中问道“执行几条指令之后再dump”部分是根据ins_count这个传参来判断还是在Opcode中dump呢?“
作者回答到“通过Opcode和ins_count共同判断”。
我们现将这个代码“提”出来,放在ExecuteSwitchImpl进入Switch Opcode 选择之前,做 预读一条代码 再做是否dump的决定。
但是在这之前我们可以学习一下源码是怎么提取指令的:
do {
dex_pc = inst->GetDexPc(insns);//表示计步器,等于几就是第几+1条指令,从0开始
shadow_frame.SetDexPC(dex_pc);
TraceExecution(shadow_frame, inst, dex_pc);
inst_data = inst->Fetch16(0);
switch (inst->Opcode(inst_data))
....
后面就是各种Opcode case语句
明白了,那就可以有【如果是针对goto指令->Invoke-static指令的话】
if(dex_pc == 0){
//直接把case紧挨着的Instruction指令粘贴过来
if(inst->Opcode(inst_data)!=Instruction::GOTO){
//如果不是,则直接执行beforeInstructionExecute的核心dump代码
if (Callflag == 5201314) {
dumpArtMethod(method);
return JValue();
}
}
再回到Invoke-static指令的解释中,我们可以知道关键逻辑在于DoInvoke这个函数。
DoInvoke是一个模板函数,能处理invoke-direct/static/super/virtual/interface等指令。
现在我们处于方法A中,接下来看A如何调用B:
①method_idx为方法B在dex文件里method_ids数组中的索引
②找到方法B对应的对象。它作为参数存储在方法A的ShadowFrame对象中。
③sf_method代表ArtMethod* A
④FindMethodFromCode查找目标方法B对应的ArtMethod对象,即ArtMethod* B。
template<InvokeType type, bool is_range, bool do_access_check>static inline bool DoInvoke(Thread* self,
ShadowFrame& shadow_frame,
const Instruction* inst,
uint16_t inst_data,
JValue* result) {
//method_idx为方法B在dex文件里method_ids数组中的索引
const uint32_t method_idx = (is_range) ? inst->VRegB_3rc() : inst->VRegB_35c();
//找到方法B对应的对象。它作为参数存储在方法A的ShadowFrame对象中。。
const uint32_t vregC = (is_range) ? inst->VRegC_3rc() : inst->VRegC_35c();
ObjPtr<mirror::Object> receiver =
(type == kStatic) ? nullptr : shadow_frame.GetVRegReference(vregC);
//sf_method代表ArtMethod* A
ArtMethod* sf_method = shadow_frame.GetMethod();
//FindMethodFromCode查找目标方法B对应的ArtMethod对象,即ArtMethod* B。
ArtMethod* const called_method = FindMethodFromCode<type, do_access_check>(
method_idx, &receiver, sf_method, self);
if (UNLIKELY(called_method == nullptr)) {
} else if (UNLIKELY(!called_method->IsInvokable())) {
} else {
...
return DoCall<is_range, do_access_check>(called_method, self, shadow_frame, inst, inst_data,
result);
}}
DoCall又进一步调用DoCallCommon,DoCallCommon又在return中调用PerformCall。
inline void PerformCall(Thread* self,
const CodeItemDataAccessor& accessor,
ArtMethod* caller_method,
const size_t first_dest_reg,
ShadowFrame* callee_frame,
JValue* result,
bool use_interpreter_entrypoint)
REQUIRES_SHARED(Locks::mutator_lock_) {
if (LIKELY(Runtime::Current()->IsStarted())) {
if (ShouldUseInterpreterEntrypoint) {
//解释模式,debug或者机器码不存在,调用ArtInterpreterToInterpreterBridge
interpreter::ArtInterpreterToInterpreterBridge(self, accessor, callee_frame, result);
} else {
//ArtMethod第二次经过时
//以机器码执行方法B,调用ArtInterpreterToCompiledCodeBridge
interpreter::ArtInterpreterToCompiledCodeBridge(
self, caller_method, callee_frame, first_dest_reg, result);
}
} else {
interpreter::UnstartedRuntime::Invoke(self, accessor, callee_frame, result, first_dest_reg);
}}
结合我上面贴的图分析,之后会经过ShouldUseInterpreterEntrypoint进行判断quick_code是否为null,由于当前的ArtMethod已经进入过一次解释器,因此再次碰到这个判断时,此时的quick_code已经被LinkCode设置好,会走else分支,调用ArtInterpreterToCompiledCodeBridge函数并重新进入ArtMethod::Invoke:
void ArtInterpreterToCompiledCodeBridge(Thread* self,
ArtMethod* caller,
ShadowFrame* shadow_frame,
uint16_t arg_offset,
JValue* result)
REQUIRES_SHARED(Locks::mutator_lock_) {
ArtMethod* method = shadow_frame->GetMethod();
EnsureInitialized();
//又回到最初FART进来的Invoke,且此时Invoke最终需要调用到entry_point_from_quick_compiled_code_完成真实调用
method->Invoke(self, shadow_frame->GetVRegArgs(arg_offset),
(shadow_frame->NumberOfVRegs() - arg_offset) * sizeof(uint32_t),
result, method->GetInterfaceMethodIfProxy(kRuntimePointerSize)->GetShorty());}
由于我们又回到了art_method.cc,因此很容易直接调用FART的最终dump的API(和之前写的做好区分工作):
if(fromExecuteSwitch){
if (!IsStatic()) {
(*art_quick_invoke_stub)(this, args, args_size, self, result, shorty);
}else{
(*art_quick_invoke_static_stub)(this, args, args_size, self, result, shorty);
}
//在真实调用结束后马上dump
dumpArtMethod(this);
return;
}
至此,结合Youpk启发的思路,加上寒冰大佬不断深入讲解的FART,一个完整的主动调用链就构造完成。之后的启发是无穷的,基本上又可以解决另一类函数抽取壳。
关于动态加载Dex的脱壳:
Youpk作者说到,不支持App动态加载的dex/jar,而FART中的API可以解决这个问题,可以使用Frida融合进去强化这个功能。
Fart中getClassLoader则是通过反射获取加壳App最终的ClassLoader,也就是替换、修正以后的ClassLoader,因为我们要通过这个ClassLoader去加载App自己的Dex,如果ClassLoader不对的话就无法完成对其中的类的加载。
在动态加载的过程中,最终依附的ClassLoader是DexClassLoader,而对于在Java中所用的非静态方法都会在堆中存在相应的实例,使用Frida众多API中寻找实例的函数——Java.choose,就可以完成对DexClassLoader对象的获取,最终可当作必要参数传入FartwithClassLoader。
0x03 结论
个人觉得函数抽取是一个非常有意思的研究点,FART内部逻辑的严谨性不言而喻,之后发展的工具如果是ART环境下,我觉得都可以结合到FART当中,因为FART是一个框架,而不是仅仅作为工具存在,通过这个框架可以有很广泛的延展性。
Youpk也做到了非常深的主动调用路径,不过作者可能没有将其深入版本再写出来,这里就先抛砖引玉了。
FART给了我很多的乐趣。:)

看雪ID:一颗金柚子
https://bbs.pediy.com/user-879358.htm
*本文由看雪论坛 一颗金柚子 原创,转载请注明来自看雪社区。
推荐文章++++
* 循序渐进分析CVE-2020-1066
*HW前期之分析一款远控木马
*熊猫烧香病毒逆向过程及其分析思路
*Galame汉化中的逆向 (一):文本加密(压缩)与解密
* 恶意样本分析学习—GlobeImposter3.0勒索病毒分析
好书推荐

﹀
﹀
﹀
公众号ID:ikanxue
官方微博:看雪安全
商务合作:wsc@kanxue.com

戳 “阅读原文 ” 一起来充电吧!
正文到此结束
- 本文标签: 代码 静态方法 虚拟化 实例 自动化 http UI bug App 2019 编译 参数 tar Listeners API 字节码 遍历 db src 安全 id CTO 加密 ssl 美团 Job SOA 索引 解析 源码 自适应 cat MQ 空间 Proxy update list https 文章 数据 回答 Android 测试 微博 线程 IO 时间 非静态方法 java value struct ACE 调试 病毒 HTML 汉化 开发 find ORM
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

