Java并发之内存模型
Java是一门支持多线程执行的语言,要编写正确的并发程序,了解Java内存模型是重要前提。而了解硬件内存模型有助于理解程序的执行。
本文主要整理以下内容
- Java内存模型
- 硬件内存架构
- 共享对象可见性
- 竞争条件
Java内存模型
Java内存模型最新修订是在Java5。 JSR-176 罗列了 J2SE5.0 相关发布特性,包含其中的 JSR-133 (JavaTM内存模型与线程规范),java虚拟机遵循此规范。延续至今该内存模型在Java8中依然奏效。
JSR 全称 Java Specification Requests,意为Java标准化技术规范的正式请求。
Java程序运行在虚拟机上(Jvm)。从逻辑角度看,Jvm内存被划分为 线程堆栈 和 堆 。每个线程都拥有自己的堆栈,该线程堆栈存储的数据不对其它线程可见。堆内存用于存储共享数据。
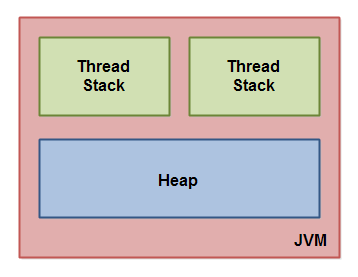
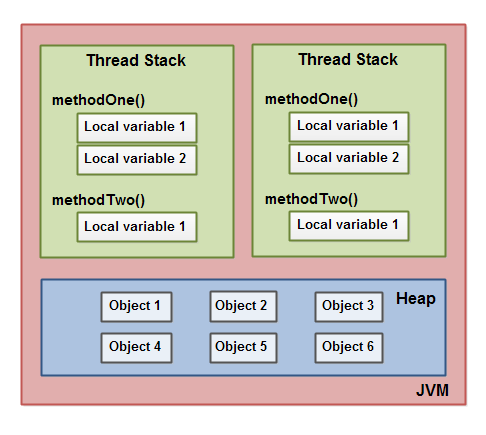
线程堆栈存储方法中所有局部变量,包含原始类型(boolean,byte,short,char,int,long, float,double)和对象引用。
堆存储需要共享对象和静态变量。
注意对象不一定都会存储到堆内存。看下面例子,假如果Object对象不需要被其它线程共享,编译器会执行 堆分配转化为栈分配 。
解释一下,编译器会根据 对象是否逃逸 做出优化。优化的其中一项就是 堆分配转化为栈分配 ,目的在于减轻GC压力,提升性能。此优化动作由Jvm参数-XX:+DoEscapeAnalysi 进行控制。Java8 默认开启。
测试:通过开启或关闭 -XX:+PrintGC -XX:-DoEscapeAnalysis 观察是否执行GC来判断对象存储位置。
public static void main(String[] args){
for(int i = 0; i < 10000000; i++){
createObj();
}
}
public static void createObj(){
new Object();
}
硬件内存架构
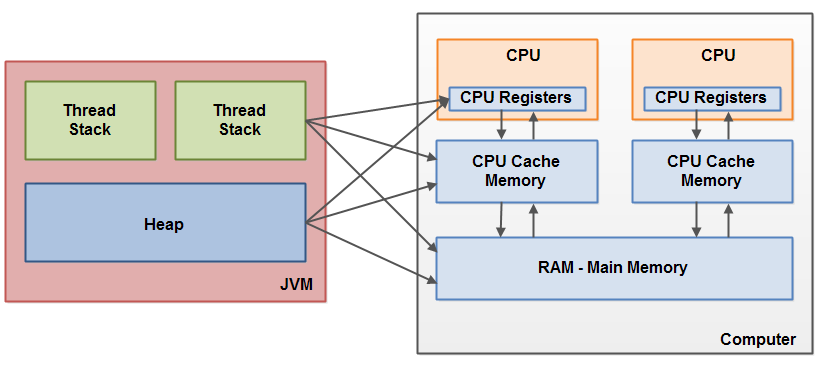
如下图,现代计算机通常都装有2个或者更多的CPU,CPU又可以是多核。一个CPU包含一组寄存器,每个CPU具有一个高速缓存,而高速缓存又分为L1,L2,L3,L4 不同层级缓存。
RAM为主存储也就是我们说的计算机内存,所有CPU都可以读取主存储。
当CPU读取主存储数据时,它会将部分主存储数据读入CPU高速缓存中,又将缓存的中一部分读入寄存器执行,操作结束后,将值从 寄存器 刷新到 高速缓存 中, 高速缓存 在特定的时刻将数据统一刷新到内存中。

实际执行
事实上,上面阐述的 Java堆栈内存模型 是为了理解抽象出来的。实际执行就像下图一样,线程栈和堆的数据可能分散到硬件不同的存储区域。数据分散在不同区域会带来以下两个主要问题。
共享对象可见性
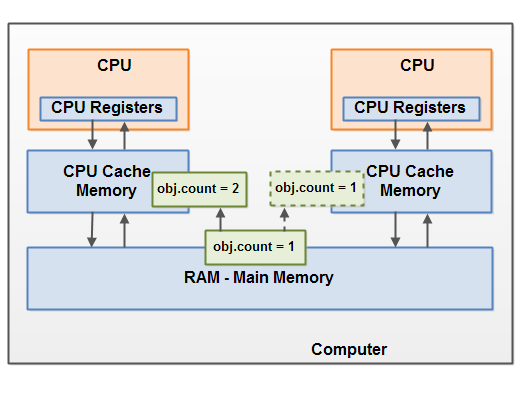
下面场景两个线程同时操作对象obj.count,其中一个线程对obj.count进行更新,但是对其它线程不可见。
线程A操作obj时,先从主存里拷贝一个数据副本到 CPU高速缓存 ,又到寄存器,然后修改obj.count=2后刷新到 CPU高速缓存 ,但是数据暂未同步到主存。以此同时线程B也操作obj,拷贝的数据副本仍然为obj.count=1,这会导致程序结果错误。
解决此问题,可以使用 Java volatile 关键字。 volatile 可简单理解为跳过 CPU高速缓存 ,让修改结果及时同步到主存,从而保证了其它线程读到最新值。 volatile 后期专门介绍。
竞争条件
另外一种情况假如果多个线程同时更行obj.count,这时会发生 竞争条件 。
解决方法,使用 Java synchronized 保证线程执行顺序,另外 synchronized 包裹中的所有变量都直接从主存读取(跳过 CPU高速缓存 ),并且当线程退出 synchronized 后,所有更新的变量将同步到主存。

总结
本文记录Java内存模型,其中主要内容来源于 Jakob Jenkov 大神博客。
欢迎大家留言交流,一起学习分享!!!
http://tutorials.jenkov.com/java-concurrency/java-memory-model.html
正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

