Gauva 源码分析 | Cache 下篇 加载、失效时机
继续分析 Local Cache ,本次的文章会讲述 Segment 的结构,缓存读写及失效逻辑。
Segment 类图
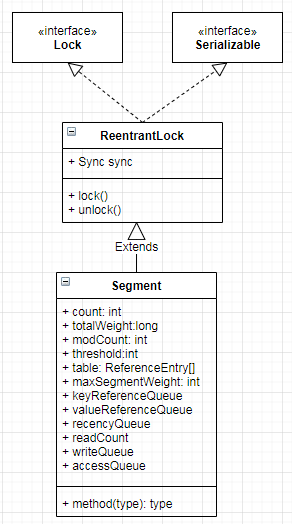
上一篇说过,LocalCache 本质上就是一个 Map ,Segment 组成的数组就是 LocalCache 的存储结果。这个和 ConcurrentHashMap 是比较类似的。下面分析一下 Segment ,主要从加载和失效两个模块考虑。
加载K-V
// LocalCache.java:3952
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException {
// 先调用reHash方法,扰动一下
int hash = hash(checkNotNull(key));
// 通过Hash值定位到segment,然后调用get方法
return segmentFor(hash).get(key, hash, loader);
}
复制代码
// Segment 加载
V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
checkNotNull(key);
checkNotNull(loader);
try {
if (count != 0) { // read-volatile
// don't call getLiveEntry, which would ignore loading values
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e != null) {
long now = map.ticker.read();
// 检查是否过期、被回收、或正在加载,则返回null
V value = getLiveValue(e, now);
if (value != null) {
// 记录访问信息,写入最近常用队列
recordRead(e, now);
statsCounter.recordHits(1);
// 如果命中,则考虑是否需要刷新,取得新值。Guava 自动刷新机制。
// 如果考虑二级缓存时,本地缓存可以用来做一级缓存,Redis做二级缓存。
// 一级缓存的失效时间可以更短一点,二级缓存失效时,Guava可以临时返回已给Null,并通知Redis重新加载,这样有效防止缓存雪崩和缓存穿透
return scheduleRefresh(e, key, hash, value, now, loader);
}
// 如果是正在加载,则阻塞等待加载完成
ValueReference<K, V> valueReference = e.getValueReference();
if (valueReference.isLoading()) {
return waitForLoadingValue(e, key, valueReference);
}
}
}
// 以上为无锁访问,如果没有结果,则在下面加锁加载
// at this point e is either null or expired;
return lockedGetOrLoad(key, hash, loader); // 从此处进入
} catch (ExecutionException ee) {
Throwable cause = ee.getCause();
if (cause instanceof Error) {
throw new ExecutionError((Error) cause);
} else if (cause instanceof RuntimeException) {
throw new UncheckedExecutionException(cause);
}
throw ee;
} finally {
// 读取后尝试执行清理
postReadCleanup();
}
}
复制代码
上述一段代码,先会进行无锁访问,假如找到数据,就直接返回,没有在开始加锁加载数据。
和我们直觉把整个加载过程上锁不一样,这里的加载过程是这样的:
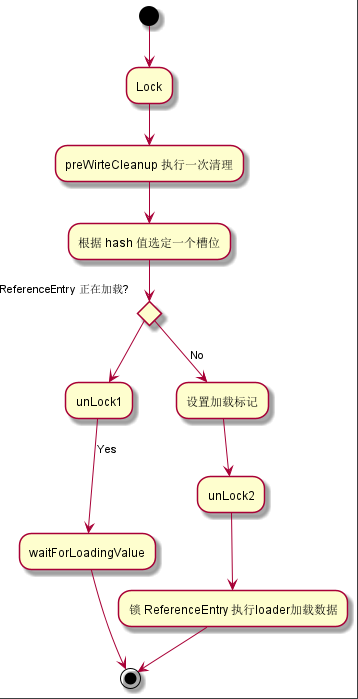
这样的加载过程可以有更好的并发,因为第一个 lock 锁的是 Segment ,粒度是很大的,用来加载过程会大大影响性能。Cache 的方法是,先构建 ReferenceEntry 对象,然后对 ReferenceEntry 上锁(一个 key 一个 ReferenceEntry,粒度极小),再进行加载。那么锁 Segment 的操作是为了构建 ReferenceEntry 对象,并设置一个 Loading 的中间状态,这样可以保证其他过来 get 同一个 key 的线程不会重复加载数据。
关键字:
- 大粒度且自旋锁 Segment 用来原子地构建 ReferenceEntry
- 锁 ReferenceEntry 以保证 loader 只执行一次
这里的技术类似:先发布对象引用占位,然后再等加载逐渐完成。
// Segment 加载
V lockedGetOrLoad(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException {
ReferenceEntry<K, V> e;
ValueReference<K, V> valueReference = null;
LoadingValueReference<K, V> loadingValueReference = null;
// 此处会上锁并进行加载,但加载过程并不需要上锁,上锁只是判断是否决定上锁
// ,决定后,把对象设置一个loading状态,然后释放锁去加载数据
boolean createNewEntry = true;
lock();
try {
// re-read ticker once inside the lock
long now = map.ticker.read();
preWriteCleanup(now);
int newCount = this.count - 1;
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
// 通过以上的 hash 值,选定一个槽位
ReferenceEntry<K, V> first = table.get(index);
for (e = first; e != null; e = e.getNext()) {
// 遍历这个槽位的链表
K entryKey = e.getKey();
if (e.getHash() == hash
&& entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
valueReference = e.getValueReference();
if (valueReference.isLoading()) {
// 预防在并发过程中,有其他线程先执行了加载操作,并处于 loading 过程
createNewEntry = false;
} else {
V value = valueReference.get();
if (value == null) {
enqueueNotification(
entryKey, hash, value, valueReference.getWeight(), RemovalCause.COLLECTED);
} else if (map.isExpired(e, now)) {
// This is a duplicate check, as preWriteCleanup already purged expired
// entries, but let's accommodate an incorrect expiration queue.
// 二次忍忍
enqueueNotification(
entryKey, hash, value, valueReference.getWeight(), RemovalCause.EXPIRED);
} else {
recordLockedRead(e, now);
statsCounter.recordHits(1);
// we were concurrent with loading; don't consider refresh
return value;
}
// immediately reuse invalid entries
writeQueue.remove(e);
accessQueue.remove(e);
this.count = newCount; // write-volatile
}
break;
}
}
if (createNewEntry) {
loadingValueReference = new LoadingValueReference<>();
if (e == null) {
e = newEntry(key, hash, first);
e.setValueReference(loadingValueReference);
table.set(index, e);
} else {
e.setValueReference(loadingValueReference);
}
}
} finally {
unlock();
postWriteCleanup();
}
if (createNewEntry) {
try {
// Synchronizes on the entry to allow failing fast when a recursive load is
// detected. This may be circumvented when an entry is copied, but will fail fast most
// of the time.
synchronized (e) {
return loadSync(key, hash, loadingValueReference, loader);
}
} finally {
statsCounter.recordMisses(1);
}
} else {
// The entry already exists. Wait for loading.
return waitForLoadingValue(e, key, valueReference);
}
}
复制代码
回收 K-V
RemovalCause
从这个枚举处可以找到 Cache 项失效的各种原因,Segment.removeEntry 方法是移除 K-V 的数据。根据官方文档,Cache 的过期策略有以下几种:
- 基于容量回收。这个比较容易,在set、put数据的时候,判断count的数值,然后把最近没有使用的缓存项回收掉。
- 定时回收。通过写操作或一定读操作后会触发执行
- 显式清除。用户手动清理
还有一种文档不提及的,我认为也算是一个失效策略吗,GC 清除软引用
- GC 清理软引用
以上清理方式都是在用户读写缓存过程中,自动进行回收的,假如需要定时回收,可以直接调用 Cache.cleanUp() 方法。
// RemovalCause 策略枚举
public enum RemovalCause {
/**
* The entry was manually removed by the user. This can result from the user invoking {@link
* Cache#invalidate}, {@link Cache#invalidateAll(Iterable)}, {@link Cache#invalidateAll()}, {@link
* Map#remove}, {@link ConcurrentMap#remove}, or {@link Iterator#remove}.
*
* 用户手动移出
*/
EXPLICIT {
@Override
boolean wasEvicted() {
return false;
}
},
/**
* The entry itself was not actually removed, but its value was replaced by the user. This can
* result from the user invoking {@link Cache#put}, {@link LoadingCache#refresh}, {@link Map#put},
* {@link Map#putAll}, {@link ConcurrentMap#replace(Object, Object)}, or {@link
* ConcurrentMap#replace(Object, Object, Object)}.
*
* 用户手动替换
*/
REPLACED {
@Override
boolean wasEvicted() {
return false;
}
},
/**
* The entry was removed automatically because its key or value was garbage-collected. This can
* occur when using {@link CacheBuilder#weakKeys}, {@link CacheBuilder#weakValues}, or {@link
* CacheBuilder#softValues}.
*
* 因为 GC 原因, 软引用会被清理
*/
COLLECTED {
@Override
boolean wasEvicted() {
return true;
}
},
/**
* The entry's expiration timestamp has passed. This can occur when using {@link
* CacheBuilder#expireAfterWrite} or {@link CacheBuilder#expireAfterAccess}.
*
* 因为过期时间到,所以需要清理
*/
EXPIRED {
@Override
boolean wasEvicted() {
return true;
}
},
/**
* The entry was evicted due to size constraints. This can occur when using {@link
* CacheBuilder#maximumSize} or {@link CacheBuilder#maximumWeight}.
*
* 因为 容量 清理
*/
SIZE {
@Override
boolean wasEvicted() {
return true;
}
};
/**
* Returns {@code true} if there was an automatic removal due to eviction (the cause is neither
* {@link #EXPLICIT} nor {@link #REPLACED}).
*/
abstract boolean wasEvicted();
}
// Segment.java
/**
* 清理Segment中的entry,cause 是清楚的原因
*
* @param entry
* @param hash
* @param cause
* @return
*/
@VisibleForTesting
@GuardedBy("this")
boolean removeEntry(ReferenceEntry<K, V> entry, int hash, RemovalCause cause) {
int newCount = this.count - 1;
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
if (e == entry) {
++modCount;
ReferenceEntry<K, V> newFirst =
removeValueFromChain(
first,
e,
e.getKey(),
hash,
e.getValueReference().get(),
e.getValueReference(),
cause);
newCount = this.count - 1;
table.set(index, newFirst);
this.count = newCount; // write-volatile
return true;
}
}
return false;
}
/**
* 获取Value,并顺便检测是否过期,假如过期就返回null
*
* Gets the value from an entry. Returns null if the entry is invalid, partially-collected,
* loading, or expired.
*/
V getLiveValue(ReferenceEntry<K, V> entry, long now) {
if (entry.getKey() == null) {
tryDrainReferenceQueues();
return null;
}
V value = entry.getValueReference().get();
if (value == null) {
tryDrainReferenceQueues();
return null;
}
if (map.isExpired(entry, now)) {
// 判断 entry 是否过期,假如是,则尝试对所有segment下所有的 K-V 做一次过期检测
tryExpireEntries(now); // 从此处切入
return null;
}
return value;
}
@GuardedBy("this")
void expireEntries(long now) {
drainRecencyQueue();
ReferenceEntry<K, V> e;
while ((e = writeQueue.peek()) != null && map.isExpired(e, now)) {
// 从 writeQueue 队列中,逐个 entry 去检查,假如可以删除,则把Entry从table的Entry链中删除
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
while ((e = accessQueue.peek()) != null && map.isExpired(e, now)) {
// 当上
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
}
/**
* Performs routine cleanup following a read. Normally cleanup happens during writes. If cleanup
* is not observed after a sufficient number of reads, try cleaning up from the read thread.
*/
void postReadCleanup() {
// postRead 读数据后置处理。设置一个readCount计数器,假如达到某个阈值,也触发一次 cleanUp,达到清理的效果
if ((readCount.incrementAndGet() & DRAIN_THRESHOLD) == 0) {
cleanUp();
}
}
复制代码
LRU 算法实现
在 Cache 容量有限的情况下,LRU 算法是一个缓存实现局部性非常重要的环节。作用是尽量让热点数据都在缓存里。
在观察 LRU 算法如何实现前,先从 LRU 如何删除数据开始看。从代码上看, Cache 使用了 recencyQueue 来记录活跃的数据
@GuardedBy("this")
void evictEntries(ReferenceEntry<K, V> newest) {
if (!map.evictsBySize()) { // 不限制容量,那就跳过此方法
return;
}
drainRecencyQueue();
// If the newest entry by itself is too heavy for the segment, don't bother evicting
// anything else, just that
if (newest.getValueReference().getWeight() > maxSegmentWeight) { // 单个Value的Weight比设定的 maxSegmentWeight 直接拒绝插入缓存
if (!removeEntry(newest, newest.getHash(), RemovalCause.SIZE)) {
throw new AssertionError();
}
}
while (totalWeight > maxSegmentWeight) { // 将超过容量的数据逐个删除
ReferenceEntry<K, V> e = getNextEvictable(); // 找到下一次需要被删除的
if (!removeEntry(e, e.getHash(), RemovalCause.SIZE)) {
throw new AssertionError();
}
}
}
// 在找到下一个需要删除的
ReferenceEntry<K, V> getNextEvictable() {
for (ReferenceEntry<K, V> e : accessQueue) { // 直接遍历队列,取出weight > 0 的 Entry删除
int weight = e.getValueReference().getWeight();
if (weight > 0) {
return e;
}
}
throw new AssertionError();
}
@GuardedBy("this")
void drainRecencyQueue() {
ReferenceEntry<K, V> e;
while ((e = recencyQueue.poll()) != null) {
// An entry may be in the recency queue despite it being removed from
// the map . This can occur when the entry was concurrently read while a
// writer is removing it from the segment or after a clear has removed
// all of the segment's entries.
if (accessQueue.contains(e)) { // 这段代码实在没看懂
accessQueue.add(e);
}
}
}
// 尝试删除数据 entry
@GuardedBy("this")
boolean removeEntry(ReferenceEntry<K, V> entry, int hash, RemovalCause cause) {
int newCount = this.count - 1;
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry<K, V> first = table.get(index);
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
if (e == entry) { // 从链表中找到了该数据,直接删除
++modCount;
ReferenceEntry<K, V> newFirst =
removeValueFromChain(
first,
e,
e.getKey(),
hash,
e.getValueReference().get(),
e.getValueReference(),
cause);
newCount = this.count - 1;
table.set(index, newFirst);
this.count = newCount; // write-volatile
return true;
}
}
return false;
}
复制代码
后记
设计一个可用的 Cache 绝对不是一个普通的 Map 这么简单,联系第一篇关于 Cache 的文章,这里小结一下关于 Guava Cache 的知识。
回归到读 LocalCache 的源头,我是希望可以了解 设计一个缓存要考虑什么? , 局部性原理 是一个系统性能提升的最直接的方式(编程上,硬件上当然也可以),缓存的出现就是根据 局部性原理 所设计的。
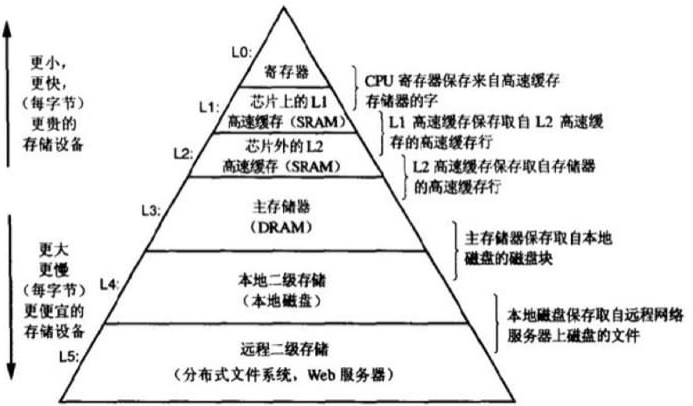
缓存作为存储金字塔的一部分,一定需要考虑以下几个问题:
- 何时加载
在设计何时加载的问题上,Guava Cache 提供了一个 Loader 接口,让用户可以自定义加载过程,在由 Cache 在找不到对象的时候主动调用 Loader 去加载,还通过一个巧妙的方法,既保证了 Loader 的只运行一次,还能保证锁粒度极小,保证并发加载时,安全且高性能。
- 何时失效
失效处理上,Guava Cache 提供了基于容量、有限时间(读有限时、写有限时)等失效策略,在官方文档上也写明,在基于限时的情况下,并不是使用一个线程去单独清理过期 K-V,而是把这个清理工作,均摊到每次访问中。假如需要定时清理,也可以调用 CleanUp 方法,定时调用就可以了。
- 如何保持热点数据有效性
在 Cache 容量有限时, LRU 算法是一个通用的解决方案,在源码中,Guava Cache 并不是严格地保证全局 LRU 的,只是针对一个 Segment 实现 LRU 算法。这个前提是 Segment 对用户来说是随机的,所以全局的 LRU 算法和单个 Segment 的算法是基本一致的。
- 写回策略
在 Guava Cache 里,并没有实现任何的写回策略。原因在于,Guava Cache 是一个本地缓存,直接修改对象的数据,Cache 的数据就已经是最新的了,所以在数据能够写入 DB 后,数据就已经完成一致了。
引用
- 并发编程网- Guava Cache 官方文档翻译
- Github Guava Cache部分 官方wiki
- Guava Cache部分 翻译
- Google Guava Cache 全解析
正文到此结束
- 本文标签: 遍历 翻译 http 二级缓存 cat synchronized 代码 volatile git kk 希望 数据 tk 解析 rewrite src cache 线程 ConcurrentHashMap GitHub 并发编程 db 文章 MQ UI 并发 App java build ORM tar HashMap Google value tab ACE IO map 类图 CEO final Atom 本质 IDE key 源码 删除 一级缓存 安全 缓存 时间 锁 https queue id redis
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

