【源码学习】ThreadLocal
参考java.util.concurrent.ThreadLocalRandom解决java.util.Random在并发场景下对seed的竞争问题而使用ThreadLocal为每一个线程维护一个seed,Tomcat使用ThreadLocal维护session,不难发现,ThreadLocal主要的用途是为不同的线程提供本地副本,从而避免数据竞争,以及状态同步问题。但是必须注意,ThreadLocal不是同步工具,不提供对封装对象的操作的原子性保证。并发场景下,任然要注意操作的线程安全。
实现原理
简单来讲,ThreadLocal是一个工具外壳,提供了访问当前线程副本的入口。实际的值保存在对应线程的ThreadLocalMap里,用ThreadLocal对象作为key访问。
阅读源码可以知道,ThreadLocal先通过getMap(Thread t)获得存放在对应线程中的threadLocals,然后在threadLocals所指向的ThreadLocalMap中通过以ThreadLocal对象为key,取出对应的value。可见,所有的线程都是在自己的内部维护一个Map来保存自己的副本,从而避免了线程之间的数据竞争和同步,同时也做到了状态的隔离。
然而,这样的实现方式也就导致子线程的ThreadLocal不会继承父线程的ThreadLocal,即直接在子线程访问ThreadLocal对象的get()方法无法获取到父线程的值。因为此时通过get()获得的ThreadLocalMap是子线程中的threadLocals,而Thread的构造器中没有拷贝父线程的threadLocals内容到新的Thread中的代码。那么如果我们就需要子线程能继承父线程中的ThreadLocalMap呢?比如我需要父线程中的session能自动传播到子线程,答案是使用InheritableThreadLocal。Thread的构造器中有如下代码:
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
复制代码
即线程在创建时会复制父线程的inheritableThreadLocals的拷贝到自己的inheritableThreadLocals属性上。而InheritableThreadLocal<T>继承自ThreadLocal<T>并重写了getMap(Thread t)方法,直接返回当前线程的inheritableThreadLocals,这样就能实现子线程继承父线程的ThreadLocalMap。
源码分析
get()和set(T value)
get方法很简单,就是通过访问当前线程的threadLocals变量获取ThreadLocalMap,然后以ThreadLocal实例为键提取map中的值。需要注意的是当ThreadLocalMap不存在或者当前线程的ThreadLocalMap中没有以ThreadLocal实例为键的entry时如何处理的。此外还应当注意到,ThreadLocal会在调用get方法时检查并清理应当被释放的value。简单流程如下图:
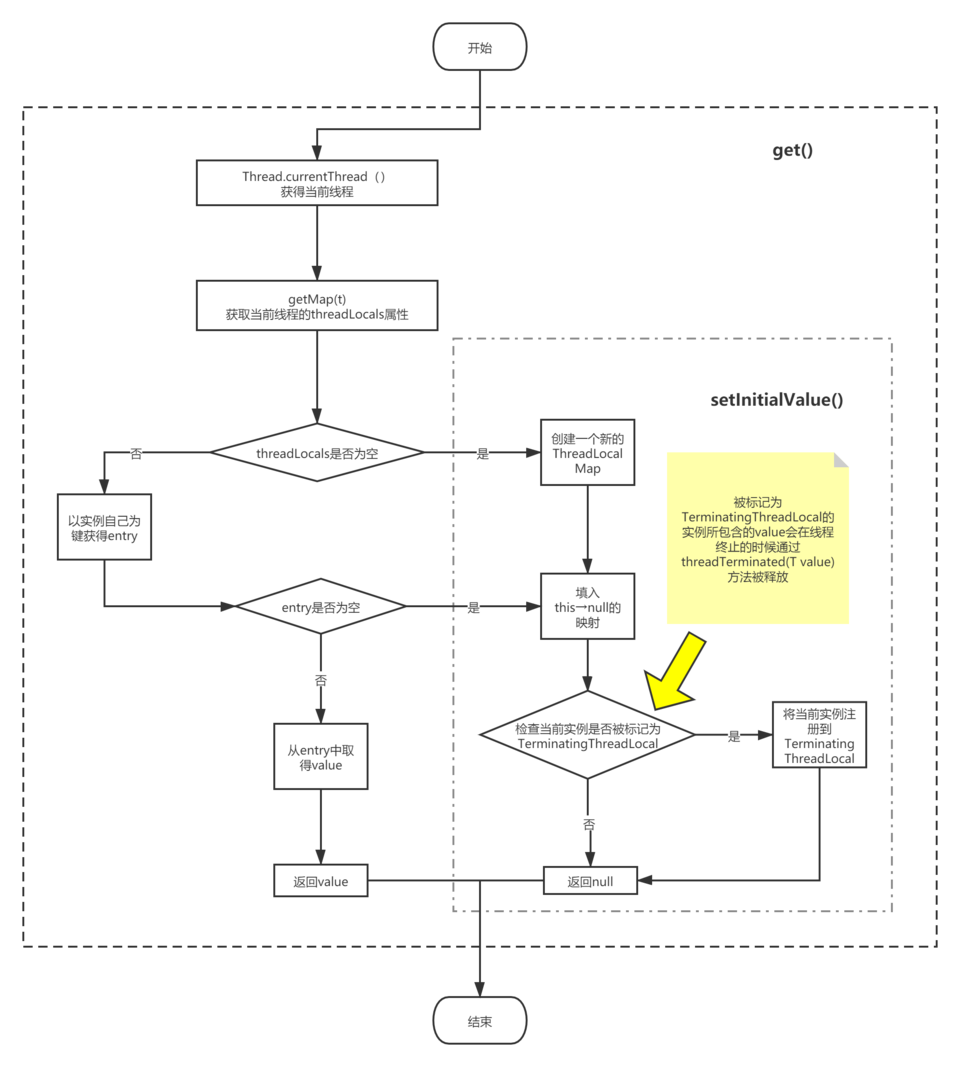
由于ThreadLocalMap使用开放地址法处理哈希碰撞,所以map在get方法中遇到entry为空或者entry的key和实例不相等时,会按顺序遍历下一个slot,直到找到或者全部查询一边。
set方法更简单,同样通过访问当前线程的threadLocals变量获取ThreadLocalMap,如果不存在就以value作为初值创建一个新的ThreadLocalMap赋给当前线程的threadLocals,存在map的话就调用Map的set方法把this→value的映射写进去。
ThreadMap的set方法还包含清理key为null的entry和扩容与rehash的过程。判断扩容和rehash的阈值是entry数量的大于数组总长的2/3,即负载因子是2/3,与HashMap不同,这个值不能修改。
关于0x61c88647
仔细看源码就会发现,ThreadLocalMap的Hash使用了一个魔数0x61c88647。这个数字被用于生成ThreadLocal对象的hashcode,而这个hashcode会被当作ThreadLocalMap的散列表下标来使用。
//ThreadLocal
···
private static AtomicInteger nextHashCode = new AtomicInteger();
private final int threadLocalHashCode = nextHashCode();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
···
//ThreadLocalMap
···
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
···
复制代码
为什么是0x61c88647而不是其他什么数字?可以看到,ThreadLocal利用AtomicInteger不断累加0x61c88647从而将32bit的空间分成许多hash槽。
等一下!!!散列算法,32bit,0x61c88647...
0x61c88647转换成10进制是1640531527,32位整数斐波那契散列使用的乘数是2654435769,转换为有符号int的话是-1640531527。依照公式H(key) = ((key * 2654435769) >> X) << Y,这里key可以视作一个步长为1,首项为0的数列,那么key*2654435769就可以被看作是乘数累加,再用table长度作为掩码,与运算之后就得到下标。
那为什么HashMap不使用这种方法呢?因为你绝对不想所有的HashMap共享一套哈希槽, nextHashCode 是一个ThreadLocal类持有的静态属性,意味着所有的ThreadLocal实例所拥有的 threadLocalHashCode 都是在实例创建时由 nextHashCode 分配的。换言之,即使不同线程之间的ThreadLocalMap中持有的ThreadLocal实例不相同,所有线程的ThreadLocalMap都会给那些自己没持有的ThreadLocal实例空出对应的哈希槽位。对于HashMap的使用场景,这是不可接受的。
resize()
既然用的哈希数组实现,那就要考虑扩容的问题。ThreadLocalMap和HashMap一样,每次扩容哈希数组长度增加一倍。需要注意两点,首先ThreadLocalMap会尝试清理掉“垃圾”,如果长度依然大于0.75*threshold,就进行resize()的操作。而resize()的过程中,依然会检查key,并将删去key为null的entry持有的value的引用,以便于GC回收垃圾;其次,关于扩容的阈值是0.75*threshold,而不是threshold,通过注释得知故意选择较小的threshold是为了避免迟滞( hysteresis )。
关于迟滞,我的理解如下:
由于哈希值是通过斐波那契散列累加出来的,而且所有的ThreadLocal共享一个数列,但是每个ThreadLocalMap的长度又不一致,所以ThreadLocalMap发生碰撞的概率还是比较大的。这一点可以从ThreadLocalMap选择2/3作为负载因子,以及注释"Set the resize threshold to maintain at worst a 2/3 load factor."看出。那么,在判断是否需要扩容的阈值选择上,就不得不考虑新创建的ThreadLocal带来的hashcode膨胀的问题。由于存在外部hashcode快速膨胀的可能性,扩容条件的判断就可能存在延时,也就是说,扩容有迟滞的可能性,所以需要人为的进一步减小阈值从而让扩容相对提前进而避免迟滞。
/**
* Re-pack and/or re-size the table. First scan the entire
* table removing stale entries. If this doesn't sufficiently
* shrink the size of the table, double the table size.
*/
private void rehash() {
expungeStaleEntries();
// Use lower threshold for doubling to avoid hysteresis
if (size >= threshold - threshold / 4)
resize();
}
/**
* Double the capacity of the table.
*/
private void resize() {
Entry[] oldTab = table;
int oldLen = oldTab.length;
int newLen = oldLen * 2;
Entry[] newTab = new Entry[newLen];
int count = 0;
for (Entry e : oldTab) {
if (e != null) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null; // Help the GC
} else {
int h = k.threadLocalHashCode & (newLen - 1);
while (newTab[h] != null)
h = nextIndex(h, newLen);
newTab[h] = e;
count++;
}
}
}
setThreshold(newLen);
size = count;
table = newTab;
}
复制代码
关于垃圾回收
ThreadLocal对垃圾回收的处理方式非常值得学习。
一方面,其充分利用了jvm的引用分类功能,通过弱引用实现了散列表中entry的key自动回收。
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
复制代码
另一方面,在所有的操作过程中,都会检查僵尸对象,保证不出现内存溢出。比如:
set(T value) 实质上是调用ThreadLocalMap的 set(ThreadLocal<?> key, Object value) ,而ThreadLocalMap的set方法则会在插入过程中调用 cleanSomeSlots 方法来清理垃圾,然后再判断是否需要rehash,rehash的过程中又会使用 expungeStaleEntries 再一次清理僵尸对象,并判断是否需要resize,如果要resize,在拷贝旧的map到新map的过程中还会处理一次僵尸对象。
T get() 分两种情况,一种是线程有ThreadLocalMap,map里有对应的key,由于可能存在hash碰撞,在调用 getEntryAfterMiss 进行线性查找key的时候遇到哈希槽的key为null的时候就会用 expungeStaleEntry 处理对应的value,另一种是不存在ThreadLocalMap或者map里没有对应的key,就会走 setInitialValue 返回一个null。在 setInitialValue 过程中,如果map存在,就会调用 set(ThreadLocal<?> key, Object value) 从而走前面提到的流程处理掉僵尸对象,如果不存在旧创建新的map并赋值,最后还会检查实例自己是不是被标记为TerminatingThreadLocal,如果是还会将自己注册到TerminatingThreadLocal,从而在Thread终止时可以调用 threadTerminated 完成回收动作。
使用问题
小心使用ThreadLocal封装对象
ThreadLocal不是同步工具,对于被ThreadLocal封装的对象,在操作时最好其当做事实不可变对象来使用。考虑下面的代码
@Slf4j
public class Example1 {
public static CountDownLatch latch = new CountDownLatch(6);
public static void main(String[] args) throws InterruptedException {
ExecutorService pool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 6; i++) {
pool.execute(new Task());
}
latch.await();
pool.shutdown();
System.exit(0);
}
public static class Task implements Runnable {
private static final List<String> list = new ArrayList<>();
ThreadLocal<List<String>> listThreadLocal = ThreadLocal.withInitial(() -> list);
@Override
public void run() {
listThreadLocal.get().add(Thread.currentThread().getName());
log.info(listThreadLocal.get().toString());
latch.countDown();
}
}
}
复制代码
如果执行这段代码,就会发现完全无法预测每个线程打印的内容。虽然list被ThreadLocal封装,但是每个线程获得的只是list的引用,list被事实共享给了所有线程。若要保证线程安全,ThreadLocal封装的对象最好是一个事实不可变对象,每次修改都是set一个修改后的全新副本。至少应该保证初始化时传入的对象只可被线程自己访问。例如将Task用下面的代码替换:
public static class Task implements Runnable {
private static final List<String> list = new ArrayList<>();
ThreadLocal<List<String>> listThreadLocal = ThreadLocal.withInitial(() -> new ArrayList<>(list));
@Override
public void run() {
listThreadLocal.get().add(Thread.currentThread().getName());
log.info(listThreadLocal.get().toString());
latch.countDown();
}
}
复制代码
此时每个线程都获得了一个只被自己访问的list的副本。所以最后的结果一定是一个仅包含当前执行线程name的列表。
线程复用的情况下,慎用ThreadLocal
由于ThreadLocal实际上是保存在当前线程的threadLocals属性下的,所以ThreadLocal实际上是和线程的生命周期一致。在传统的多线程模型中,任务的生命周期和线程生命周期保持一致。但是在线程复用的模型中,比如netty的Reactor模型,一个线程可能会来回服务于多个任务,在多个任务切换时,ThreadLocal就必须跟着重新赋值,否则就会数据污染,缓存一个脏副本。当然可以通过及时remove()来避免污染,但由于生命周期不一致,再一次进入需要重新传值,而频繁的传值,本身就和ThreadLocal的设计目标不符。目前异步响应式编程大行其道,几乎是未来高并发低延时网络服务的事实标准。ThreadLocal的适用范围正在减小,在使用响应式框架时,类似的需求应当考虑用context来替换ThreadLocal。
内存溢出风险
通过源码分析,我们可以发现Doug Lea设计ThreadLocal做了非常全面的工作来保证僵尸对象的回收,可是ThreadLocal仍然有溢出风险。说法有些恶意夸大,但这主要还是因为现在的场景较过去已经发生巨大变化,网络开发强调高并发低延迟,传统的一个线程服务一个连接的做法不再适合。通过线程复用技术避免调度开销,降低延迟成为主流。此时,线程的生命周期不再和任务的生命周期绑定。线程持有的ThreadLocalMap可能在上一个任务中还有使用,在后面的任务中就不再使用了。诚然GC会回收掉ThreadLocalMap里面的key,但是由于不再操作ThreadLocalMap,导致ThreadLocalMap没有机会触发后续清理value的工作,那么这些value就会一致持有强引用,对应的对象也就变成了僵尸。
当然,处理方法也很简单,使用完毕之后手动remove即可,但这也很危险。依赖于手动处理资源释放的设计天然存在人为风险。忘记remove,错误的调用时机都会带来不必要的麻烦,使用时要慎之又慎。总而言之,溢出风险视使用情况而定,在线程复用的场景下使用需要格外注意资源的回收。
正文到此结束
- 本文标签: id 缓存 源码 安全 需求 key ask 垃圾回收 CountDownLatch java cat 代码 实例 src IO JVM rmi 线程 多线程 DOM example executor ArrayList Netty 遍历 同步 Service session https IDE CTO final HashMap rand tomcat 数据 空间 开发 Atom 模型 并发 mina UI 注释 list 生命 高并发 Reactor tab map 响应式 value http
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

