Lambda初次使用很慢?从JIT到类加载再到实现原理
问题回顾
描述的话不多说,直接上图:
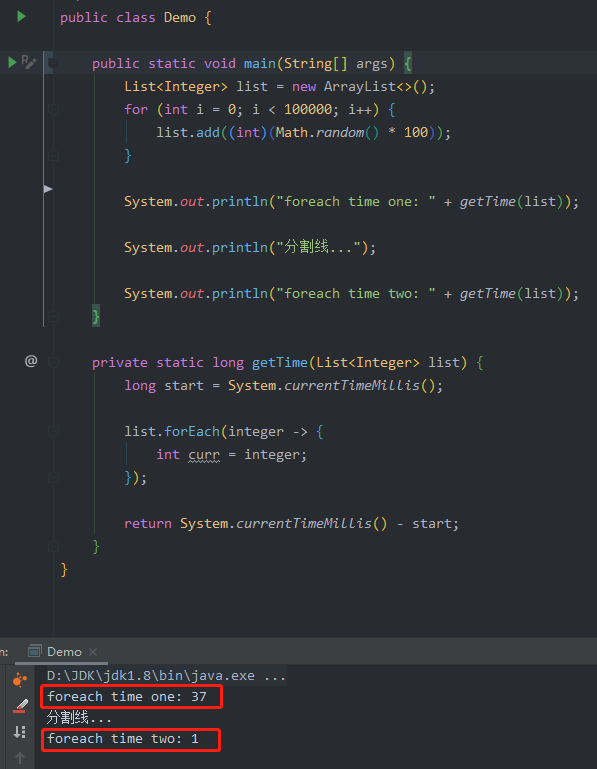
看到输出结果了吗?为什么第一次和第二次的时间相差如此之多?咱们一起琢磨琢磨, 也可以先去看看结论再回过头看分析
注:并非仅第二次快,而是除了第一次,之后的每一次都很快
给与猜想
-
是否和操作系统预热有关?
-
是否和JIT(即时编译)有关?
-
是否和ClassLoader类加载有关?
-
是否和
Lambda有关,并非foreach的问题
验证猜想
操作系统预热
操作系统预热这个概念是我咨询一位大佬得到的结论,在百度 / Google 中并未搜索到相应的词汇,但是在模拟测试中,我用普通遍历的方式进行测试:
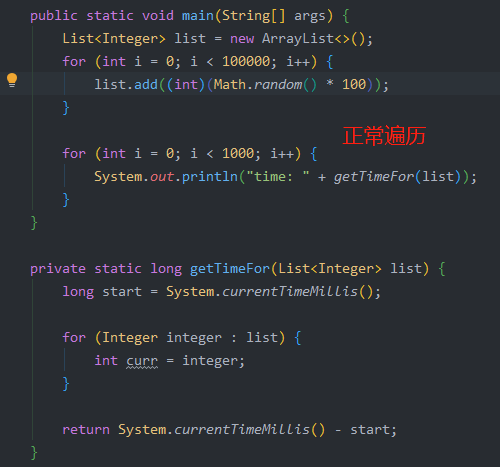
基本上每次都是前几次速度较慢,后面的速度更快,因此可能有这个因素影响,但差距并不会很大,因此该结论并不能作为问题的答案。
JIT 即时编译
首先介绍一下什么是JIT即时编译:
当 JVM 的初始化完成后,类在调用执行过程中,执行引擎会把字节码转为机器码,然后在操作系统中才能执行。在字节码转换为机器码的过程中,虚拟机中还存在着一道编译,那就是 即时编译
。
最初,JVM 中的字节码是由解释器( Interpreter )完成编译的,当虚拟机发现某个方法或代码块的运行特别频繁的时候,就会把这些代码认定为 热点代码
。
为了提高热点代码的执行效率,在运行时,即时编译器(JIT,Just In Time)会把这些代码编译成与本地平台相关的机器码,并进行各层次的优化,然后保存到内存中
再来一个概念, 回边计数器
回边计数器用于统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为 "回边"(Back Edge)
建立回边计数器的主要目的是为了触发 OSR(On StackReplacement)编译,即栈上编译,在一些循环周期比较长的代码段中,当循环达到回边计数器阈值时, JVM 会认为这段是热点代码
,JIT 编译器就会将这段代码编译成机器语言并缓存,在该循环时间段内,会直接将执行代码替换,执行缓存的机器语言
从上述的概念中,我们应该可以得到一个结论:第一条所谓的操作系统预热大概率不正确,因为普通遍历方法执行N次,后续执行的时间占用比较小,很可能是因为JIT导致的。
那 JIT即时编译 是否是最终的答案?我们想办法把 JIT 关掉来测试一下,通过查询资料发现了如下内容:
Procedure
-
Use the -D option on the JVM command line to set the java.compiler property to NONE or the empty string.
Type the following command at a shell or command prompt:
java -Djava.compiler=NONE <class> 复制代码
注:该段内容来自IBM官方资料,地址见 <收获> ,咱们先不要停止思考
通过配置 IDEA JVM 参数:

执行问题中的代码测试结果如下:
# 禁用前
foreach time one: 38
分割线...
foreach time two: 1
# 禁用后
foreach time one: 40
分割线...
foreach time two: 5
复制代码
我测试了很多次,结果都很相近,因此得到可以得到另一个结论: JIT
并非引发该问题的原因(但是它的确能提高执行效率)
难道和类加载有关?
在进行类加载验证时,我依然无法放弃 JIT
,因此查阅了很多资料,知道了某个命令可以查看 JIT
编译的耗时情况,命令如下:
java -XX:+CITime com.code.jvm.preheat.Demo >> log.txt
复制代码解释一下命令的意思
# 执行的目录
C:/Users/Kerwin/Desktop/Codes/Kerwin-Code-Study/target/classes>
# 命令含义:Prints time spent in JIT Compiler. (Introduced in 1.4.0.)
# 打印JIT编译所消耗的时间
-XX:+CITime
# 代表我指定的类
com.code.jvm.preheat.Demo
# 输出至log.txt文件,方便观看
>> log.txt
复制代码展示一下某一次结果的全部内容:
foreach time one: 35
分割线...
foreach time two: 1
Accumulated compiler times (for compiled methods only)
------------------------------------------------
Total compilation time : 0.044 s
Standard compilation : 0.041 s, Average : 0.000
On stack replacement : 0.003 s, Average : 0.002
Detailed C1 Timings
Setup time: 0.000 s ( 0.0%)
Build IR: 0.010 s (38.8%)
Optimize: 0.001 s ( 2.3%)
RCE: 0.000 s ( 0.7%)
Emit LIR: 0.010 s (40.7%)
LIR Gen: 0.002 s ( 9.3%)
Linear Scan: 0.008 s (31.0%)
LIR Schedule: 0.000 s ( 0.0%)
Code Emission: 0.003 s (12.4%)
Code Installation: 0.002 s ( 8.2%)
Instruction Nodes: 9170 nodes
Total compiled methods : 162 methods
Standard compilation : 160 methods
On stack replacement : 2 methods
Total compiled bytecodes : 13885 bytes
Standard compilation : 13539 bytes
On stack replacement : 346 bytes
Average compilation speed: 312157 bytes/s
nmethod code size : 168352 bytes
nmethod total size : 276856 bytes
复制代码分别测试的结果如下:
| 类型 | Total compilation time(JIT编译总耗时) |
|---|---|
| 两次 foreach(lambda) 循环 | 0.044 s |
| 两次 foreach (普通)循环 | 0.016 s |
| 两次 增强for循环 | 0.015 s |
| 一次 foreach(lambda) 一次增强for循环 | 0.046 s |
通过上述测试结果,反正更加说明了一个问题:只要有 Lambda 参与的程序,编译时间总会长一些
再次通过查询资料,了解了新的命令
java -verbose:class -verbose:jni -verbose:gc -XX:+PrintCompilation com.code.jvm.preheat.Demo
复制代码解释一下命令的意思
# 输出jvm载入类的相关信息
-verbose:class
# 输出native方法调用的相关情况
-verbose:jni
# 输出每次GC的相关情况
-verbose:gc
# 当一个方法被编译时打印相关信息
-XX:+PrintCompilation
复制代码对包含Lambda和不包含的分别执行命令,得到的结果如下:
从日志文件大小来看,就相差了十几kb
注:文件过大,仅展示部分内容
# 包含Lambda
[Loaded java.lang.invoke.LambdaMetafactory from D:/JDK/jre1.8/lib/rt.jar]
# 中间省略了很多内容,LambdaMetafactory 是最明显的区别(仅从名字上发现)
[Loaded java.lang.invoke.InnerClassLambdaMetafactory$1 from D:/JDK/jre1.8/lib/rt.jar]
5143 220 4 java.lang.String::equals (81 bytes)
[Loaded java.lang.invoke.LambdaForm$MH/471910020 from java.lang.invoke.LambdaForm]
5143 219 3 jdk.internal.org.objectweb.asm.ByteVector::<init> (13 bytes)
[Loaded java.lang.invoke.LambdaForm$MH/531885035 from java.lang.invoke.LambdaForm]
5143 222 3 jdk.internal.org.objectweb.asm.ByteVector::putInt (74 bytes)
5143 224 3 com.code.jvm.preheat.Demo$$Lambda$1/834600351::accept (8 bytes)
5143 225 3 com.code.jvm.preheat.Demo::lambda$getTime$0 (6 bytes)
5144 226 4 com.code.jvm.preheat.Demo$$Lambda$1/834600351::accept (8 bytes)
5144 223 1 java.lang.Integer::intValue (5 bytes)
5144 221 3 jdk.internal.org.objectweb.asm.ByteVector::putByteArray (49 bytes)
5144 224 3 com.code.jvm.preheat.Demo$$Lambda$1/834600351::accept (8 bytes) made not entrant
5145 227 % 4 java.util.ArrayList::forEach @ 27 (75 bytes)
5146 3 3 java.lang.String::equals (81 bytes) made not entrant
foreach time one: 50
分割线...
5147 227 % 4 java.util.ArrayList::forEach @ -2 (75 bytes) made not entrant
foreach time two: 1
[Loaded java.lang.Shutdown from D:/JDK/jre1.8/lib/rt.jar]
[Loaded java.lang.Shutdown$Lock from D:/JDK/jre1.8/lib/rt.jar]
# 不包含Lambda
5095 45 1 java.util.ArrayList::access$100 (5 bytes)
5095 46 1 java.lang.Integer::intValue (5 bytes)
5096 47 3 java.util.ArrayList$Itr::hasNext (20 bytes)
5096 49 3 java.util.ArrayList$Itr::checkForComodification (23 bytes)
5096 48 3 java.util.ArrayList$Itr::next (66 bytes)
5096 50 4 java.util.ArrayList$Itr::hasNext (20 bytes)
5096 51 4 java.util.ArrayList$Itr::checkForComodification (23 bytes)
5096 52 4 java.util.ArrayList$Itr::next (66 bytes)
5097 47 3 java.util.ArrayList$Itr::hasNext (20 bytes) made not entrant
5097 49 3 java.util.ArrayList$Itr::checkForComodification (23 bytes) made not entrant
5097 48 3 java.util.ArrayList$Itr::next (66 bytes) made not entrant
5099 53 % 4 com.code.jvm.preheat.Demo::getTimeFor @ 11 (47 bytes)
5101 50 4 java.util.ArrayList$Itr::hasNext (20 bytes) made not entrant
foreach time one: 7
分割线...
5102 54 3 java.util.ArrayList$Itr::hasNext (20 bytes)
5102 55 4 java.util.ArrayList$Itr::hasNext (20 bytes)
5103 53 % 4 com.code.jvm.preheat.Demo::getTimeFor @ -2 (47 bytes) made not entrant
foreach time two: 1
5103 54 3 java.util.ArrayList$Itr::hasNext (20 bytes) made not entrant
[Loaded java.lang.Shutdown from D:/JDK/jre1.8/lib/rt.jar]
[Loaded java.lang.Shutdown$Lock from D:/JDK/jre1.8/lib/rt.jar]
复制代码我们可以结合JIT编译时间,结合JVM载入类的日志发现两个结论:
-
凡是使用了Lambda,JVM会额外加载
LambdaMetafactory类,且耗时较长 -
在
第二次调用Lambda方法时,JVM就不再需要额外加载LambdaMetafactory类,因此执行较快
完美印证了之前提出的问题:为什么第一次 foreach 慢,以后都很快,但这就是真相吗?我们继续往下看
排除 foreach 的干扰
先来看看 ArrayList
中 foreach
方法的实现:
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
复制代码乍一看,好像也没什么特别,我们来试试把 Consumer 预先定义好,代码如下:
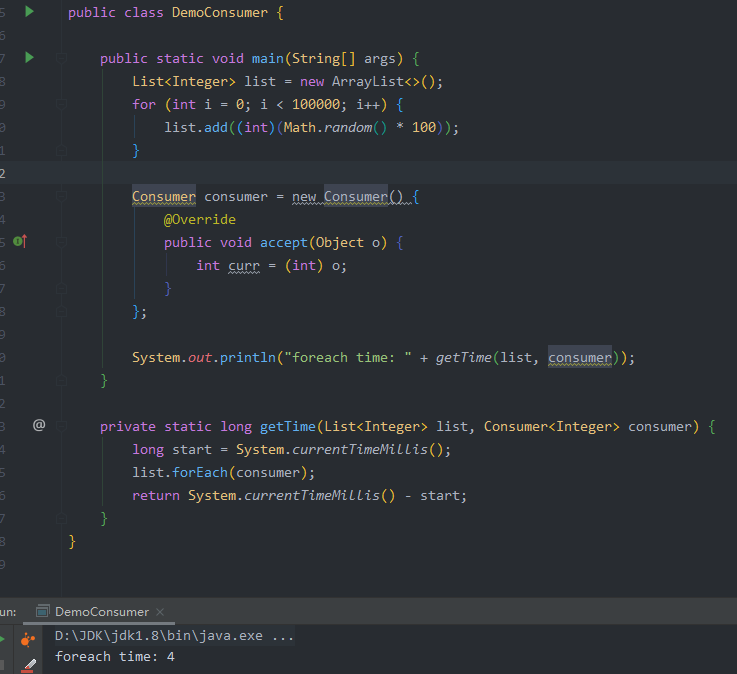
可以发现速度很快,检查 JIT编译时间
,检查 类加载
情况,发现耗时短,且无 LambdaMetafactory
加载
根据刚才得到的结论,我们试试把 Consumer
用 Lambda
的方式定义一下
Consumer consumer = o -> {
int curr = (int) o;
};
# 执行结果耗时
foreach time: 3
复制代码再来看看编译时间和类加载,赫然发现:JIT编译时间较长,且有LambdaMetafactory加载
重新探究Lambda的实现原理
Lambda
表达式实现原理的细节,我之后会再出一篇新的文章,今天就先说一下结论:
-
匿名内部类在编译阶段会多出一个类,而
Lambda不会,它仅会多生成一个函数 -
该函数会在运行阶段,会通过
LambdaMetafactory工厂来生成一个class,进行后续的调用
为什么 Lamdba
要如此实现?
匿名内部类有一定的缺陷:
-
编译器为每个匿名内部类生成一个新的类文件,生成许多类文件是不可取的,因为每个类文件在使用之前都需要加载和验证,这会影响应用程序的启动性能,加载可能是一个昂贵的操作,包括磁盘I/O和解压缩JAR文件本身。
-
如果lambdas被转换为匿名内部类,那么每个lambda都有一个新的类文件。由于每个匿名内部类都将被加载,它将占用JVM的元空间,如果JVM将每个此类匿名内部类中的代码编译为机器码,那么它将存储在代码缓存中。
-
此外,这些匿名内部类将被实例化为单独的对象。因此,匿名内部类会增加应用程序的内存消耗。
-
最重要的是,从一开始就选择使用匿名内部类来实现lambdas,这将限制未来lambda实现更改的范围,以及它们根据未来JVM改进而演进的能力。
内容参考:https://www.infoq.com/articles/Java-8-Lambdas-A-Peek-Under-the-Hood/
真相
在理解了匿名内部类以及 Lambda
表达式的实现原理后,对 Lambda
耗时长的原因反而更懵逼,毕竟匿名内部类的生成一个新类和 Lambda
生成一个新方法所耗时间差别不会太多,然后运行期间同样有Class产生,耗时也不应该有太大的区别,到底哪里出现了问题呢?
再次通过查询资料,最终找到了答案:
You are obviously encountering the first-time initialization overhead of lambda expressions. As already mentioned in the comments, the classes for lambda expressions are generated at runtime rather than being loaded from your class path. However, being generated isn’t the cause for the slowdown. After all, generating a class having a simple structure can be even faster than loading the same bytes from an external source. And the inner class has to be loaded too. But when the application hasn’t used lambda expressions before, even the framework for generating the lambda classes has to be loaded (Oracle’s current implementation uses ASM under the hood). This is the actual cause of the slowdown, loading and initialization of a dozen internally used classes, not the lambda expression itself.
大概翻译过来如下:
显然,您遇到了lambda表达式的首次初始化开销。正如注释中已经提到的,lambda表达式的类是在运行时生成的,而不是从类路径加载的。
然而,生成类并不是速度变慢的原因。毕竟,生成一个结构简单的类比从外部源加载相同的字节还要快。内部类也必须加载。但是,当应用程序以前没有使用lambda表达式时,甚至必须加载用于生成lambda类的框架(Oracle当前的实现在幕后使用ASM)。这是导致十几个内部使用的类(而不是lambda表达式本身)减速、加载和初始化的真正原因。
真相:应用程序初次使用Lambda时, 必须加载用于生成Lambda类的框架 ,因此需要更多的编译,加载的时间
回过头去看看类加载的日志,赫然发现了 ASM框架
的引入:
[Loaded jdk.internal.org.objectweb.asm.ClassVisitor from F:/Java_JDK/JDK1.8/jre/lib/rt.jar]
[Loaded jdk.internal.org.objectweb.asm.ClassWriter from F:/Java_JDK/JDK1.8/jre/lib/rt.jar]
[Loaded jdk.internal.org.objectweb.asm.ByteVector from F:/Java_JDK/JDK1.8/jre/lib/rt.jar]
[Loaded jdk.internal.org.objectweb.asm.Item from F:/Java_JDK/JDK1.8/jre/lib/rt.jar]
[Loaded jdk.internal.org.objectweb.asm.MethodVisitor from F:/Java_JDK/JDK1.8/jre/lib/rt.jar]
[Loaded jdk.internal.org.objectweb.asm.MethodWriter from F:/Java_JDK/JDK1.8/jre/lib/rt.jar]
[Loaded jdk.internal.org.objectweb.asm.Type from F:/Java_JDK/JDK1.8/jre/lib/rt.jar]
[Loaded jdk.internal.org.objectweb.asm.Label from F:/Java_JDK/JDK1.8/jre/lib/rt.jar]
[Loaded jdk.internal.org.objectweb.asm.Frame from F:/Java_JDK/JDK1.8/jre/lib/rt.jar]
[Loaded jdk.internal.org.objectweb.asm.AnnotationVisitor from F:/Java_JDK/JDK1.8/jre/lib/rt.jar]
[Loaded jdk.internal.org.objectweb.asm.AnnotationWriter from F:/Java_JDK/JDK1.8/jre/lib/rt.jar]
复制代码结论
-
导致 foreach 测试时数据不正常的罪魁祸首是:
Lambda表达式 -
Lambda表达式在应用程序中首次使用时,需要额外加载ASM框架,因此需要更多的编译,加载的时间 -
Lambda表达式的底层实现并非匿名内部类的语法糖,而是其优化版 -
foreach 的底层实现其实和增强 for循环没有本质区别,一个是外部迭代器,一个是内部迭代器而已
-
通过 foreach + Lambda 的写法,效率并不低,只不过需要提前进行
预热(加载框架)
收获
-
JIT 即时编译的概念和相关命令
-
IBM 官方资料库, 地址
-
Oracle 关于JVM命令大全, 地址 | 国内博主翻译版本 地址
-
Lambda底层实现文章, 地址

本文使用 mdnice 排版
正文到此结束
- 本文标签: java node cat 注释 list src IO lambda 目录 IBM Oracle 时间 value lib ORM 缓存 tab tar 代码 实例 build Action 字节码 测试 Google 遍历 consumer Property JVM 翻译 https IDE HTML 百度 文章 equals 编译 struct 数据 App final ACE ArrayList ssl shell UI CTO 操作系统 http 本质 web db 配置 空间 参数 统计 id
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

