架构设计:分布式服务,库表拆分模式详解
一、服务间隔离
1、分布式结构
分布式系统架构的明显特点,就是按照业务系统的功能,拆分成各种服务,每个服务下面都有自己独立的数据库,以此降低业务间的耦合度,隔离不同的数据库保证系统最大的稳定性等。
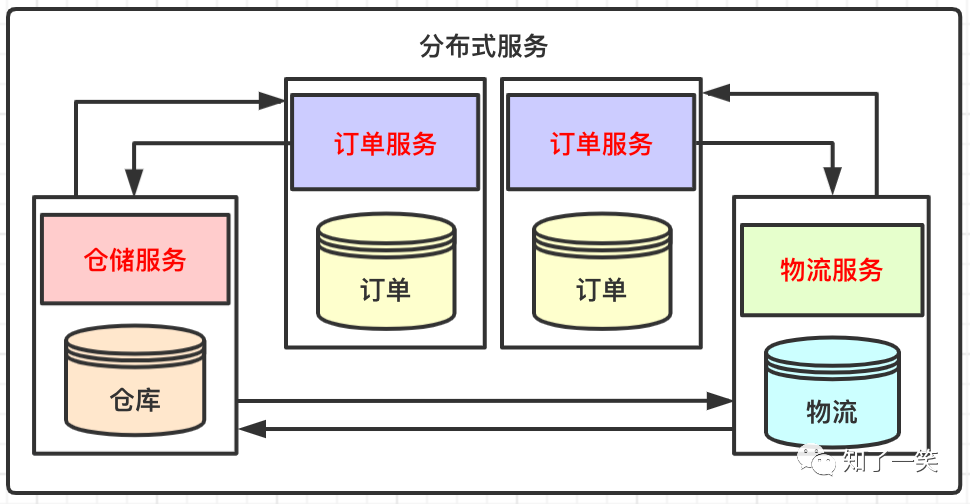
例如上图是电商系统中经典的业务场景,订单-仓储-物流的服务模式,不同服务提供不同的应用场景,服务间存在通信机制,以此实现服务的高可用。
2、隔离思想
分布式的架构体系中,涉及一个根本思想逻辑:隔离;
服务和数据库根据业务拆分,进而隔离开来,整个架构中某个服务挂掉,不会影响其他的服务继续执行。例如上述1中:如果物流服务挂掉,影响的是用户无法实时追踪物流状态,但是不会影响订单的持续产生。
隔离的策略也是各有不同,常见的电商系统是典型的按照业务特点进行拆分,这种就是不同的业务场景下,使用不同的服务和数据库;还有一种业务场景,多租户平台,针对大客户提供独立的服务和数据库,对小客户提供公服务和数据库,这种策略比较现实:大客户带来收益多,完全覆盖服务和数据库的成本,必须保证不能被一些非必要因素影响。
不管是基于什么策略拆分隔离,首先都必须面对数据库设计的问题。
二、数据库设计
1、拆分思想
数据库在业务体系不大的情况,一般都是单库出现,最多加一个备份库以备不时之需,当业务体量不断扩大,就会考虑拆分场景,例如常见的:水平拆分,垂直拆分策略。
水平拆分
首先把单表表分割N个结构相同的表,然后把数据按照策略分散到不同的表中,这是表层面;如果把表在分散在不同的数据库中,这就是数据库层面的水平拆分。
垂直拆分
把单表中数据按照不同特点,拆分成两张不同的表,常见的策略是根据数据是修改多,还是读取多,把修改频繁的字段放一张表,读取频繁的放另一张表,这是表层面;如果根据业务特点,拆分不同库,这就是数据库层面。
2、拆分模式
读写分离
读写分离是数据库拆分的最基本方式,实现起来难度也不大,只需要根据读写库的配置,把业务中数据写操作路由到写库,数据读操作路由到读库即可。
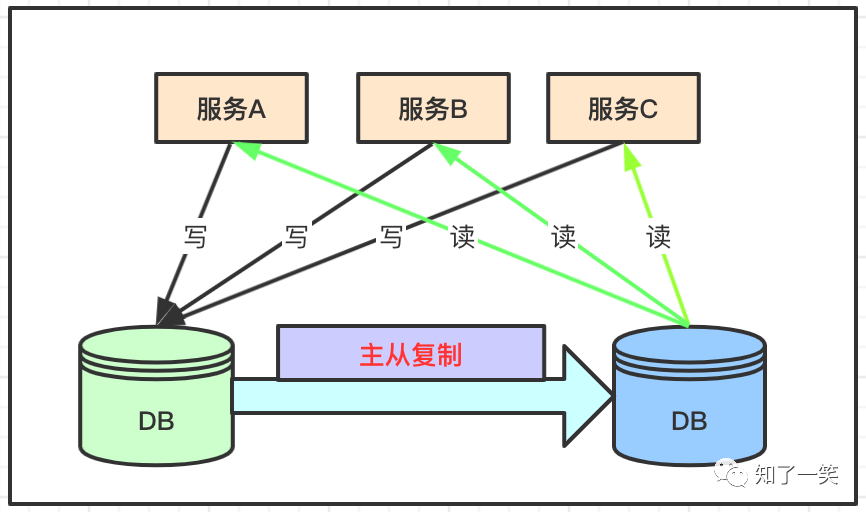
这种方式实现的数据库拆分虽然相对容易,如果出现主从复制挂掉的情况,就会导致数据读不到,或者数据读取延时,所以在强一致的要求的情况下,使用不多。
分库分表
分库分表主要用来解决单表数据量过大的问题,根据特定字段的路由规则,把数据分散到不同的库,不同的表中。
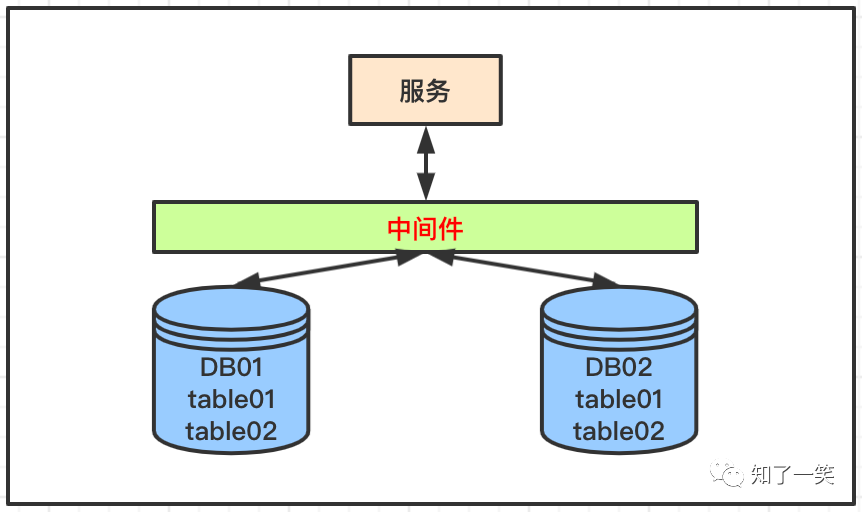
通常是基于一些唯一值的哈希算法实现的分库分表策略。也有一些成熟的中间件可以集成到项目直接使用,这种模式更多适用于单点数据的查询的场景,可以基于路由快速定位数据所在的库表。
业务分库
基于业务特点拆分数据库,是当前分布式架构下,或者微服务模式的基础用法,不同业务场景下数据放在一个库,因为数据关联性很强,在使用的时候方便,同时与其他业务数据隔离开来,避免单点故障导致数据库挂掉。
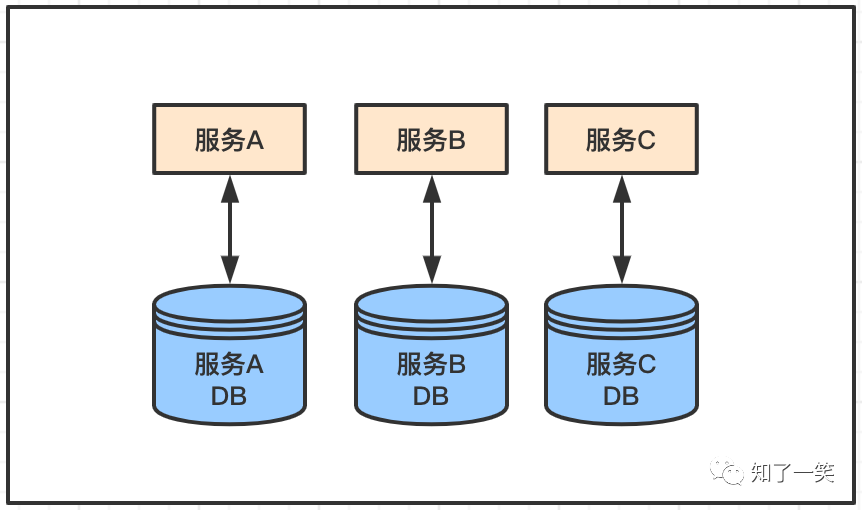
这种模式虽然看起来更合理,但是复杂度也是非常的陡,因为两种业务场景下的数据不可能绝对没有关联,比如订单库一定依赖用户库的信息,这就需要订单服务和用户服务之间需要通信,引发的问题就会很多。
用户分库
在多租户场景下,会根据客户流水大小提供不相同的服务和数据库,这是一个十分现实的策略,毕竟可能一个大客户的月流水超过几个小客户的总和。
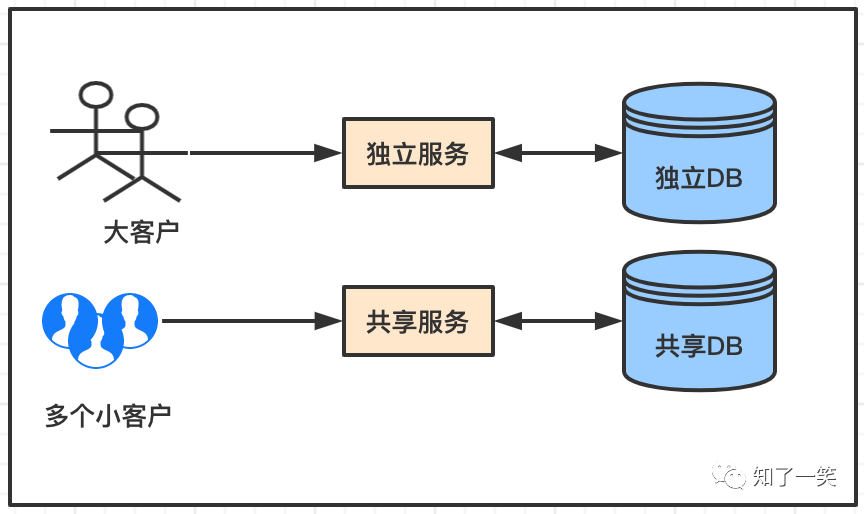
既然可以根据客户情况分库,也可以基于其他策略,比如地区,常见云服务的应用,选择华南,华北,华东区之类的。
三、架构体系难点
这里所提到的涉及问题,是指基于 业务分库 模式下的出现的问题。
1、服务依赖
在分布式架构体系下,不同服务都有各自的数据库,但是数据之间一定是有关系的,服务A要用服务C的数据库,就必须通过服务C提供的接口来获取,这是基本机制,不然拆分服务和库就没意义了,这样就会导致服务间产生依赖关系。
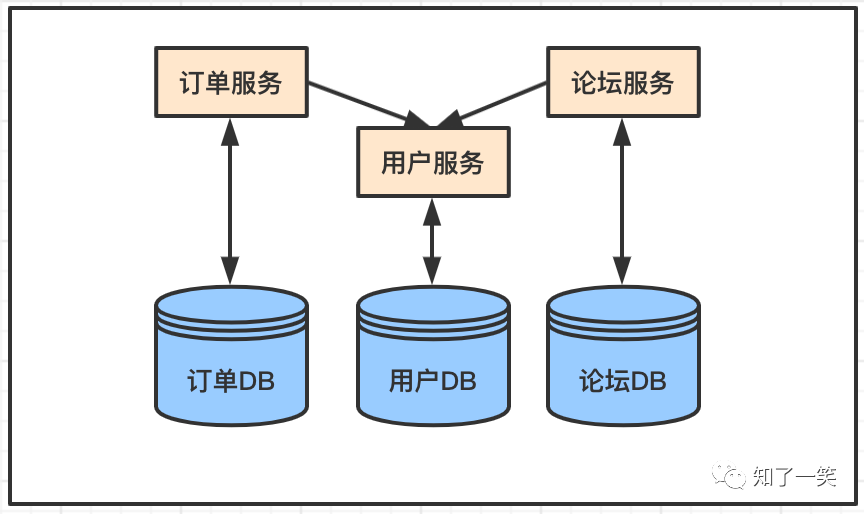
如上图,如果订单服务和论坛服务同时依赖用户服务,那么就要考虑如果用户服务挂掉,会影响多大的范围,做好权衡,还有一个关键点,如果多个服务依赖一个服务,那么就要保证被依赖的服务有足够的能力应对,例如这里,如果订单服务有10W的流量,论坛服务有10W的流量,那么就要保证部署上用户服务起码要能承受20W的流量。
2、分布式事务
既然数据库在不同的服务下面,服务之间又存在依赖关系,那么保证数据的事务一致性就是非常大的难题。
这里基于支付业务的转账场景做一个简单的演示,从数据源1的账户表中,向数据源2的账户表中操作转账,尽管在代码层面看添加了事务最高级别的控制,但是却没有起到控制作用,导致出账成功,但是入账失败,这就是典型的分布式事务问题。
@Service
public class AccountServiceImpl implements AccountService {
@Resource
private JdbcTemplate jdbcTemplateOne ;
@Resource
private JdbcTemplate jdbcTemplateTwo ;
/**
* @param fromUser 出账 账户
* @param toUser 入账 账户
* @param money 涉及 金额
*/
@Transactional(isolation= Isolation.SERIALIZABLE)
@Override
public void transfer(String fromUser, String toUser, int money) {
// fromUser 出账
jdbcTemplateOne.update(
"UPDATE user_account SET money = money-? WHERE username= ?",
new Object[] {money, fromUser});
int i = 1/0 ;
// toUser 入账
jdbcTemplateTwo.update(
"UPDATE user_account SET money = money+? WHERE username= ?",
new Object[] {money, toUser});
}
}
这里只是先演示分布式事务的问题,如何解决分布式事务问题,需要很多的篇幅描述,后面的连续几篇文章再细说。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

