Avalanche 首席架构师解读区块链共识演化:即将上线的雪之协议特性何在?
Avalanche 首席架构师、Libra 项目共识 HotStuff 论文作者 Ted Yin 分析区块链不同共识协议的优劣势,并从技术角度简单介绍 Avalanche 共识机制。
原文标题:《共识的 1.0 到 3.0,即将上线的雪崩协议有何不同?》
撰文:Ted Yin,Avalanche 联合创始人兼协议架构师
本文内容来自币乎直播:《共识的 1.0 到 3.0,即将上线的雪崩协议有何不同?》,由 Avalanche 首席架构师、Facebook Libra 项目共识 HotStuff 论文作者 Ted 分析区块链不同共识协议的优劣势,并从技术角度简单介绍 Avalanche 的共识机制。特别感谢币乎作者行走的整理。
先做个自我介绍, 我中文名是尹茂帆,英文名是 Ted。我现在是 Avalanche 的联合创始人和协议架构师。我现在是康奈尔就读的博士,第四年结束,马上要第五年了。
宣传标题里讲的 1.0、2.0、3.0,是我们很早宣传时,为了方便介绍我们新的共识算法用到的概念。今天会主要介绍算法上比较能直观理解的部分。之前我也讲过系统的整体架构、平台服务之类的。
为了避免过度营销的嫌疑,我先解释下 1.0、2.0、3.0 是什么意思。大家更多可以看作是三种本质上不同的方式来实现共识。大家不要理解成区块链 1.0、2.0、3.0。我知道之前有人炒作过区块链 3.0.
没有必要纠结数字的高下,我会去讲每个算法共识是在做什么,大家就会对我们平台基于的新方法与众不同的地方就会有一定的认识。
第一代,中本聪时代

首先进入我们视野的是需要挖矿的,Proof of Work(PoW) 工作量证明。这个协议的优势和劣势都相对比较明显。
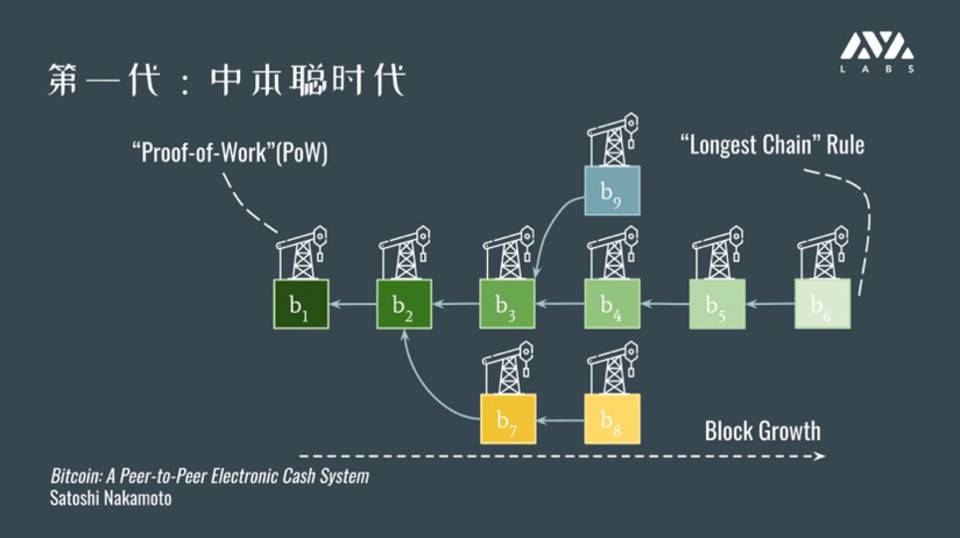
从上图可以看出,这种协议结构非常清晰。严格意义不能只算一条链,而是树形的结构。树的根是创世的块,每个节点或者叫区块都是延续前面某一个区块作为前任节点,不断生长。
它的规则是,每个块会包含难以被伪造,而且容易验证的事情,是工作量证明。其实是大家去猜一个让区块满意哈希数学上要求的数。比如这个哈希要小于某个特定值。前面有多少个前导 0。
优点
1. 可以在完成共识的同时做为准入机制
国外最早讨论公链还是联盟链的区别,就是因为中本聪算法本身除了能实现共识,还额外有附加作用,可以同时控制有效参与共识的人数,是通过控制算力来控制系统。
2. 可以比较优雅的进行安全性退化
系统中「坏人」所占的百分比增加时,肯定系统会越来越不安全。在中本聪的共识中,不安全不是「坏人」到达一定程度系统就崩溃了,没有安全的保证了。而是一直是概率的安全保证。系统有一个相对平滑的过度过程。
3. 松散成员信息
因为系统基于工作量,每个人各自闷头挖矿就好,就是最后向全网散布新挖的矿时进行通讯就好。它对成员信息的要求不是那么强。
问题
这些问题其中有一些是大家知道的。
1. 工作量证明极其浪费资源
无论是否有新的交易被提交,区块链是必须不停向前运转,无法停下。运转的速度是需要所有机器同时做猜测,一刻不停歇来保证的。
我这有个比较老的数据,18 年比特币全网的耗电总量大概是一个奥地利两个丹麦三个爱尔兰全国当年的装机总量。现在的数据可能会更糟糕。
2. 极低的负载能力
耗了这么多电,用了这么多能量。最后能做的事情没有那么多,负载能力并不强。吞吐量平均每秒只有几笔交易这个数量级。
3. 很长的确认时间
如果单位时间只能在全球做几笔交易,又有大量交易被提交,平均每笔交易的确认时间就会很长。现在比特币确认时间差不多要 40 分钟到 1 小时左右。
4. 安全效率不是很高
我花了这么多精力、电能,不考虑实际性能,我们只讨论到底有多安全。比如在全网百分之多少算力是「坏」的情况下,一笔交易被「双花」的百分比大概有多少。
对于中本聪协议而言,相比第二类协议,假设网络中参与者都是三分之一是「坏人」的情况下,中本聪的协议六个区块要等一个小时,能带来的安全性没有我们想象的那么高。不是 99.999% 都是安全的,其实只有 90% 甚至不到是安全的。
而另一类协议可以做到永远是安全的。只要参与网络决策过程的「坏人」数量是低于一定阈值,比如三分之一。
第二代协议,PBFT
比较有意思的是,第二代协议诞生的时间并不是晚于中本聪的协议。只是当时没有区块链和炒作的概念,所以没有进入大家的视野。

它尝试做的东西(和中本聪协议)是非常类似的。根据我的印象,可能在上世界 70 年代就有了不错的研究,80 年代就登上舞台。在 2000 年之前就达到了研究的顶峰。有大量的论文讨论这件事。
最后没有在当时跑出来的原因是当年工业界对「去中心化」、「去信任」、透明的平台之类的概念并不是很在意。那时候硅谷的互联网前浪还在创业中。没有更多人去考虑更「乌托邦」的世界。
在第二代协议中,一个代表性作品,比较实际可以被作用到系统的就是实用拜占庭容错共识,简称 PBFT
优势
1. 网络规模小时非常快
和它类似的协议,CFT,就是容宕机,机器坏掉的错的协议。这种协议应用很广泛,是在谷歌、百度、阿里都大量使用的基础架构。对于提供云服务的系统,需要保证系统 24 小时乘 7 天不间断的对外表现出工作的状态。为了实现,就需要一定程度的容错。这类算法已经在大规模应用了。可以认为是支撑起现在云平台的应用之一。
和云平台可以容宕机错误的协议类似,PBFT 也很快,不需要挖矿,而且安全是确定性的。只要「坏人」是有阈值的,比如小于三分之一,就可以保证系统一旦做决议就不会被反悔。
2. 是永远安全而不是概率性安全
3. 相对久的科研历史
劣势
1. 难以扩容
系统有一个尴尬性的问题,系统中会有「领袖」或者「协调者」。对于这样的特殊节点,会成为整个系统的瓶颈。
有人会说有些协议不需要具体的某个人主导,而是所有人完全民主的方式去投票决议。但其实在那种情况下,网络通信还不如一个人去协调。因为每个人都想去做领袖,每个人都去做和领袖一样多的事情,在消息复杂度上,效率没有改善反而变得更差了。
2. 基于 Quorum
Quorum 确实找不到中文更好的翻译。大家可以理解成以前议会中达到法律效力的人阈值,就是少数服从多数中多数的量,或者达成多数的群体就被称为一个 Quorum。
基于 Quorum 的算法,比如知道系统中有 100 个人,我希望超过 66 个人容易,才是绝大多数票。这个算法需要 100% 准确知道现在参与投票的有哪些人。我们不需要具体知道哪一个人有什么特性,而需要确定知道系统中有多少参与者,对参与者的信息要求是非常准确的。
3. 对「坏人」的硬性假设
前面举例中,一旦系统中有超过 33 个「坏人」,比如 34 个、40 个,而系统只能容到 33 个的情况,则系统的安全性没有任何保证。
4. 很多核心协议极为复杂
作为很底层的协议,按理应该较为容易实现,但这类协议,就像不是拜占庭而是孪生容错的协议一样,都很难高效实现,很难理解。
但近几年这个问题也有所改善。我另外做的研究项目 HotStuff,Libra 用的协议对协议本身的复杂度进行了优化。当然本身也有协议本身的局限性。
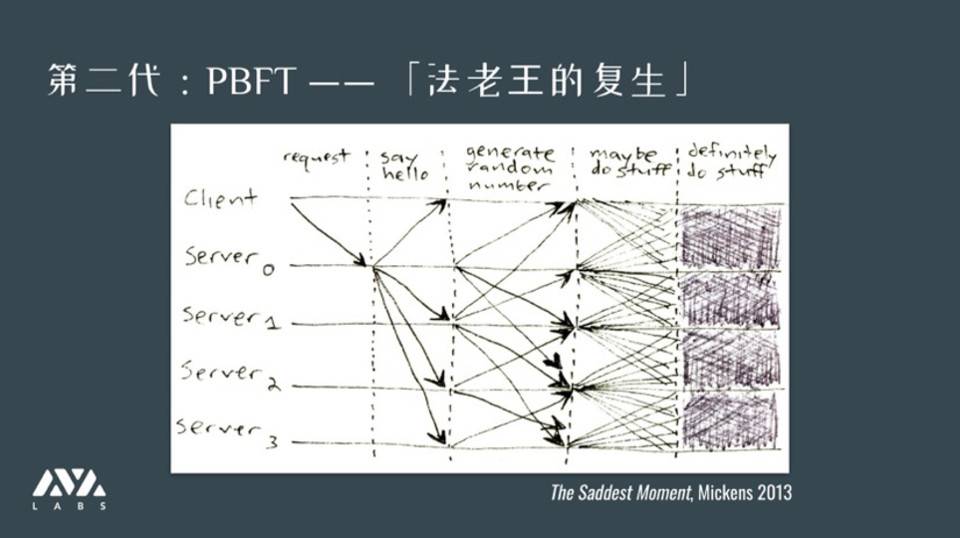
上图是我经常用的一张图。会给大家直观的感受,这类协议的执行过程往往是作为客服端提交一个交易,交易在全网范围得到多次广播,最后才神奇地达到共识。
2013 年就有人说这类协议完全看不懂,为什么多投几轮票莫名其妙就达成共识了。这个漫画也是讽刺,就是能不能把协议弄简单点。
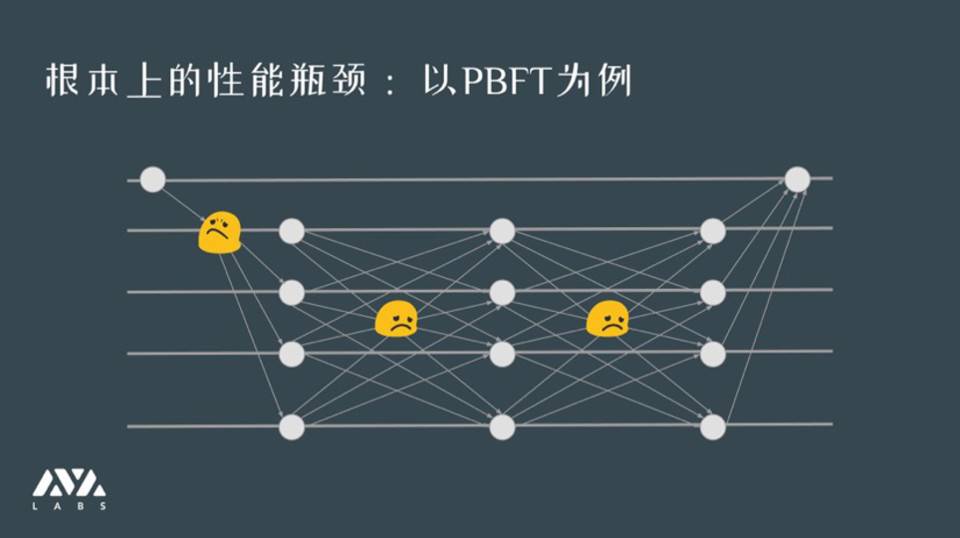
这张图是解释协议在网络上信息量或者性能上的瓶颈。以 PBFT 为例,会有一个一到多和多到多的消息发送过程。对于这种网络,随着参与节点的增加,它的代价其实是平方数量级增加的。在 HotStuff 中可以做到线性数量级,但问题是还是会有一个节点给所有节点发送消息,这是是目前无法避免的。

前面我们介绍了两大类共识。目前我所知道的几乎所有协议都是脱胎于这两个标准的范式。只要不是瞎掰的,都是基于这两个其中某一个,再去做性能上的优化,或者加一些添头,核心基本是没有变。
这就可以引出我们今天重点要提到的第三代共识。
第三代,雪之协议 Avalanche
原来论文里是 Avalanche,翻译成中文是雪崩。很多人会觉得名字起得晦气。我一开始就知道,但可能一开始是在美国做的项目,(除了我)没人懂中文,没有太多同感;另一方面我觉得也无所谓,毕竟咱们都是新一代的人,不是很在意名字谐音的问题。反而名字谐音,未必是坏事。上来就说自己很厉害,姿态太高了反而不太好。我们就沿用了这个名称。
Avalanche 是在 18 年 5 月我们投到 IPFS 上的初稿,大家可以看到,经过一年时间修改,主体内容没有太大的变化,现在也基本定型了。
比较不幸的巧合是,当年我们做这个协议用的模式是传染病的模型。在这个特殊时期,我们可以换个方式理解,类似流言传播的模型。
为什么听上去八杆子打不到的东西会和共识、区块链 有关系呢?一会会举例说明。

优势
其实兼具了前两类共识的优点。
1. 安全性退化优雅
和中本聪共识类似,不会因为「坏人」达到阙值之后就完全不能用了。
2. 对成员信息要求相对松散
我看到的世界和你看到的世界在个别参与人之间有有些出入,但总体差不多就可以了。
3. 无视网络大小,快就完事了
这是最大的优点或者吸引我的地方。协议没有一个节点需要和其他所有节点通信,而是每个节点都是对等的,从网络中只能和常数的,或者很小规模的节点通信。
就像现实社会中谣言的传播一样,不是用大喇叭广播说这件事是真的,而是我和几个或者十几个狐朋狗友聊八卦,不知道为什么全村就都知道了。
4. 绿色环保
整个协议过程不需要挖矿,类似第二类协议只需要投票,不需要挖矿。这就意味着对于交易而言不需要很长的等待时间。
5. 协议直觉上符合现实
当然数学证明上很复杂。这个论文中有提到,当然大家也没必要把它弄懂。
接下来我会尝试从直觉的角度,非常粗略地讲一讲一个共识是怎么运行的。

我们想象有一群人,比如一百或一千人在讨论娱乐圈某个瓜是真还是假。换一种不是大家能听懂的话,我们考虑一个网络有 N 个节点参与一个二元共识,就是真或假。
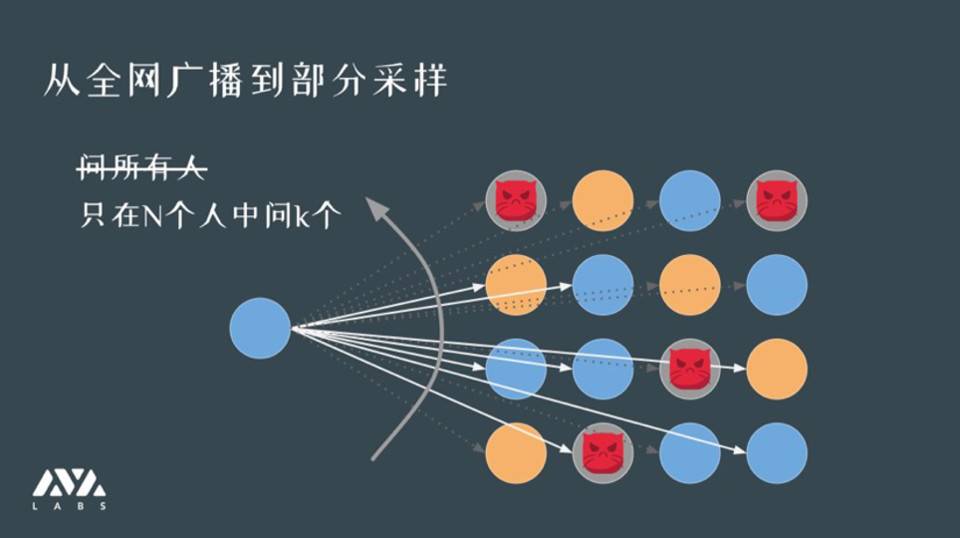
在这个假定下,我们让每个人独立且自由随机地选择 K 个人。比如我们在 100 人设定中,假设每个人每次随机和十个人进行采样。采样就是指某个人张三要去问这十个人,传言是否实锤了?这就是一种询问或者一次采样。通过检查 K 个采样的结果,是否大部分人都认为实锤了来更新张三对事实的倾向,我更倾向于是真还是假。
这个过程相比其他基于投票的协议有巨大的、本质上的变化是,它不需要和全网中每个人(节点)进行通讯,只需要从 N 个人中取 K 的近似。而 K 可以很小。
比如我对 100 人的网络是问十个人,对 1000 人的网络还是问 10 个人。
k 的选择和你需要的安全程度是有关的,而基本与网络大小是无关的。对于我需要的安全度,一千人参与的网络和一亿人参与的网络,问出来的近似程度是差不太多的。因为我们发现在统计学上,采样可以很好地逼近整体,所以在很大程度上可以让询问的规模和网络规模做到一定程度的解耦,不需要再去问所有人。
我看到弹幕有人问采样成本高吗。成本就是网络通讯的成本,比如我给十个节点发消息,这个成本和挖矿、投票等需要给所有人发消息的成本比是低很多的。节省了大部分向全网发消息的代价。
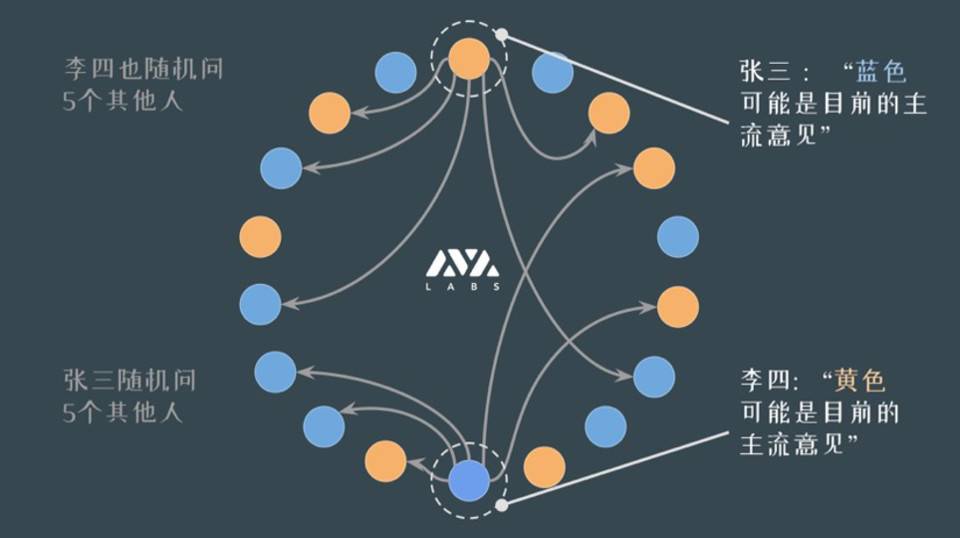
我们再举个更具体的例子。如下图。

比如张三是最上面的节点。一开始他认为这件事是假的,我们用橙色表示。他询问了五个人,发现大部分人告诉他这件事是真的。这时张三发现好像主流意见和自己目前倾向是向左的,可以会去调整。
而李四也在问自己采样的人,这是同步发生的。对于李四可能一开始倾向于是真的,随机问了五个人,发现大部分人告诉他是假的。
这种情况说明网络还处于争论阶段。就像上了热搜的话题,除了吃瓜群众,还有粉丝和当事人还在辩论,没有一边倒的情况。
无论如何,张三、李四各自做了询问之后,可能会调整自己的倾向性。会根据目前主流意见调整自己的看法。下图中就是这个过程。
这个过程是个动态的过程。

这个链接是我去年抽空写的小程序,把这个过程做成了动画,上面可以模拟这个过程。大家可以设置网络规模,可以看到二元共识是如何形成的。
虽然下面的曲线大家会看着似曾相识,因为是基于传染病模型的灵感。但大家不要想象成是基于感染还是没感染的情况。更多是类似两种观点彼此竞争。
总结一下 Avalanche。它是利用了采样的方法,可以视为大幅度泛化的,基于少数服从多数的表决系统。不需要任何工作量证明。所以 Avalanche 兼具前两种共识的优点。网络有多快,理论上就能跑多快。本身也能轻松扩容大量节点。对成员没有严格限制。

大家习惯性的把只要不是中本聪的协议都称为 PoS 协议。主要原因还是准入机制。严格意义来讲,对于共识,准入并不是要解决的事情。大家提到共识算法是 PoW 还是 PoS,这种说法本质是错误的。应该是这个系统本身是基于 PoW 还是 PoS,或者是什么样的准入机制。
共识机制和准入机制并不天然具有相关性。只是中本聪恰巧将两者耦合起来了。对任何不基于中本聪的挖矿的协议,都需要一个额外的准入机制。
在这点上我们和其他不需要挖矿的协议是类似的。也就是说可以尝试引入任意的准入机制,比如用 PoS 来做机制。
因为时间有限,今天就差不多到这里。下面是提问环节。
互动问答
1. 关于有向无环图
大家可以发现我讲了半天根本没有讲 DAG 有向无环图这回事。这是对这类协议误会最深的事情。
DAG 本身并不能达成共识,只是一种优化的手段。你如果看到任何项目用 DAG 来做共识的话,我觉得这个说法本身就是错误的。
其他 DAG 的案例,相对靠谱的 Conflux 用有向无环图加上中本聪共识,尝试用 DAG 提高中本聪共识的吞吐量。本身 DAG 本身不是让共识变得更好,要么是增加吞吐量,不能改变延迟;要么是通过 DAG 解耦需求,原来需要线性的交易所有交易要拍成一根链。现在可以让不相关的交易并发发生,时间前后不要么重要。
我们在 Avalanche 中采用的 DAG 是后者。如果绝大部分工作都是交易和资产转移的话,交易不需要严格的前后顺序,用 DAG 可以极大提高系统的并发度。
2. Avalanche 是如何解决块传播和零确认存在的问题的?对于其他技术有什么优势?核心技术点在哪里?
我不太理解块传播和零确认指什么问题。我就比较广泛的就区块链做块的通信做一些探讨。
Avalanche 算法在通信中不是全网广播,因为没有任何一个节点做这个事情。它会有优势,不需要同时给每个人发消息。可能大家没有感觉这有什么区别?就是和一小撮人发消息和给所有人发消息。但在技术和工程上影响的差别还是很大的。
我们可以想象如果一个节点成为众矢之的,大家都给它发消息,这个节点的负荷能力会承受不住。因为我们假定参与的节点都相对对等。不会存在特殊节点是超级计算机,其他都是手机。如果在对等情况情况下, 那个(向全网广播)的节点就会成为瓶颈。
不过如果你问的是区块本身如何散布出去的话,我们这方面更像比特币一些。我们也是通过类似谣言网络去传播的。和刚才的共识几乎是类似的。在设计上,传播、共识、通信的模式是一样的。
3. Avalanche 有 Slush、Snowflake、Snowball 和 Avalanche 四个子协议,能简单说下他们之间的区别与联系吗?
这位用户显然是看了一眼我们论文的。我们论文中提到的四个协议,还是为了方便大家理解。
简要的说,真正可以被使用的拜占庭容错的协议是 Snowball 雪球协议。Slush 雪水协议不是拜占庭容错,而是基于以前的流言网络总结出来的,看是否可以做一致性的事情。Snowflake 雪花可以做拜占庭,但会有一些活性上的问题。「坏人」可以不断拉扯系统,让系统无法朝一边倒,使一种音浪占大多数,短时间就能席卷整个网络。它可以维持这种平衡。
Snowball 是增加了一点雪球效应的成分在其中。也就是说这个网络并非完全没有记忆,每个人对自己确认的状态有一个信心度。这个信心度短时间确认后无法强行改到另一个观点。我如果已经承认这件事实锤了,不会因为我某一次的采样而突然跳到另一边,就是站边很稳定。
最后 Avalanche 是基于 Snowball 优化出来的一个支持纯交易的系统。后来我们也基于 Snowball 做了另一个系统 Snowone 打算用来做智能合约的链和区块链治理的链。
4. 以下几个问题请教一下: 1. 协议算法是否参考了粒子群算法?算法的一致性和收敛性是否有验证? 2. 节点不保存全区块数据?全区块数据如何溯源?
这个问题问得非常好。这个算法有物理、化学背景的人会想起粒子群算法,或者物理学中的异星模型。
我并不是对其他领域特别熟悉。你所说的粒子群算法可能是指一类,如果把协议运作模式中的每个节点视作一个基本粒子。协议视为基本粒子按照基本物理法则和周围的粒子进行交互的话,可以认为是粒子群算法中的一种。我们 的一致性和收敛性是有理论上的论证的。
第二个问题,我们目前节点如果参与子网 A,那么子网 A 中的所有数据还是会保存的。目前用的和其他项目,主流算法相同的,要去保存整个链上的数据。当然因为有子网的存在,不需要保存整条链,但对你感兴趣的链的数据是要保存的。
将来我们也考虑过要不要不用让每个人保存整个数据,做一些灵活度上的优化。但是需要注意,不去保存整个数据,其实是对容错度的妥协。放弃一定的容错度,来减少网络冗余的信息量或者每个节点维护自身的数据量。
5. 我们看到 AVA 测试网得到参数 tps 大约 3400,确认延迟 1.35 秒。有些项目动不动就号称百万 tps,这个成绩看上去没有那么突出,这个性能所在的瓶颈是什么?主网上线的时候性能表现如何?
这是个老生常谈的问题。TPS 只是一个指标,用来衡量网络能承载多少量的交易的指标。如果只看 TPS,我们可以想象,如果我用顺丰或中国邮政,用快递货车拉一车硬盘或者 SD 卡,从上海拉到北京,就算两三天才到,但因为承载的信息量很大,平均吞吐量会高于任何区块链项目。但你用快递能做区块链么?我觉得未必。
除了看吞吐量以外,还需要看延迟。对于普通用户而言,其实并不是很在意整个系统能够容纳多少。用支付宝也不会在意阿里巴巴的吞吐量有多强,而是(更关注)一笔交易从提交到确认平均要多长时间。所以需要一分为二看事情。
6. 每一个子网络都是由 AVA 网络维护安全性的吗?还是他们和侧链的设计类似,安全性和主网络是独立开来的?
是否想说,侧链和主链的地位不太对等?所以侧链基本没有共识?
其实在我们的设计中,都没有提过侧链。我们希望解决的问题不是把主要矛盾转嫁到侧链或者非主链上来完成所谓的性能提升。
我们提出子网,主要是可用性,或者对用户而言使用体验上的提升。我们意识到,系统得有一个主网,去做核心的、重要的决议。同样大家也想去运行自己的子链,属于自己的链。按理说我们可以要求每个人自己去运行,但实际上没人会这么多,没有必要。
第一是可能大家不愿意去做,可能子链本身就是做着玩的,凭什么要帮你去提升链的安全性?另一方面,假设我去做了,可能会去收费,做经济上的要求。那对于只想玩一玩,不需要所有人参加的子链就会很亏(没动力做)。
所以我们就增加了子网,让系统更灵活。你可以想象成,无论如何所有小朋友都要去上学,学校的班级就是主网,而子网就是兴趣班。你家孩子只有一个,但你可以让他参加不同的兴趣班。子网和主网都在各自发挥各自的目的,算法是一个算法,并没有安全性上的问题。可能参与人数不同,如果子网参与人数过少,容错的程度会确实不如主网,但也仅仅因为参与的节点数不够造成的。
7. Avalanche 在跨链的设计上和 Cosmos 以及波卡有哪些异同?当有项目希望接入 Avalanche 的跨链,会需要先去构建一个基于 AVA 底层架构的 fork 网络,这种设计是否反而会增加使用门槛?
我就不讲其他项目了。讲一下我们是怎么去做跨链的。我们也是用了现在研究比较火热的「原子交换」来实现跨链。我们也是进行了系统化的设计和论证。
目前系统上已经有了跨链。我们有一个链来控制参与的人,因为参与需要交押金,就是 staking,我们有专门做 staking 的链,这个链同时也是做治理的链,本身也有自己的共识,是有顺序的共识。
对于 Avalanche 而言,没有要求所有交易都要有线性的结构,而是只要之间没有冲突,可以天马行空的同时进行。跨链就是使用了范用的办法。我不太清楚具体 cosmos 和波卡使用了什么办法,但至少我们的办法能满足系统内部链与链之间的需求。
我们这里提到的跨链不是 ava 和别的项目之间的跨链。这点上我们和主打跨链服务的创业公司和项目是有本质区别的。我们内部的跨链是内部周转的系统,因为所用的共识是同类的,所以没有太多问题。
8. Avalanche 不能称之为链吧?
这是个非常好的哲学问题,是灵魂的拷问。这取决于你对区块链的定义。什么是区块链呢?如果把这个问题定义清楚,称它是链也罢,不是链也罢,做得事情,提供的服务是类似的,这有什么区别呢?
9. Avalanche 和 showone 有什么区别?
你可以理解成,Showone 更像你理解的那种链,是一步一个脚印的完成共识的,Avalanche 更像随意的结构,大家放飞自我,只是通过共识算法解决双花问题。Avalanche 显然会比 Showone 更快,或者更容易扩容。但局限性就是无法直接支持智能合约。所以当时我们才觉得可以把两个同源的协议进行混搭,会非常完美解决目前的需求。
10. 可以把 Avalanche 共识和挖矿结合起来么?
一年多、两年前我记得其实有人提过这个想法。他们基于我们的协议做了「预共识」,他们希望先用我们的共识加速交易确认,再用慢的 PoW 进行最后的确认。
11. 关于募资的问题
由于私募实在太多人希望认购,所以我们倾听了社区的意见给出了不同的方案,我们在保障代币分配的公平性的同时尽量希望和项目共同成长,确保代币分配的公平性、开放性。
因此我们有三个选项:选项 A1:0.5 美元 / 币,锁仓一年,最多买 25k usd。选项 A2:0.5 美元 / 币,锁仓 1.5 年,无上限。选项 B:0.85 美元 / 币,不锁仓,每人最多 5k。
时间是 7.8 北京时间晚上 10 点开始,Avalanche token sale 信息以及购买渠道大家可以查看。
关于交易所,我们已经联系了业内一线的交易所,希望在上线的时候能够触达足够多的、质量高的用户群体,因此请大家期待我们未来的进度,我们会在今年夏季发布主网,尽请大家期待一下。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

