架构设计(11)-- 分布式链路跟踪: 理论知识
我们最近升级改造我们链路跟踪系统Log2,然后我们花了将近一周时间调研不少开源的链路跟踪系统,在此调研过程中,做了一些笔记和总结,若有误请指教。
一、背景:分布式系统的问题
在分布式系统架构里面,往往包含众多应用服务,这些服务之间通过RPC调用来完成业务请求,如果其中某个RPC请求异常、超时和错误,很难去定位。这时我们需要分布式链路跟踪,去跟进请求链路到底有哪些服务,请求参数、请求结果、超时异常等情况,就可以清晰可见,然后监控服务运行状况和快速定位问题。
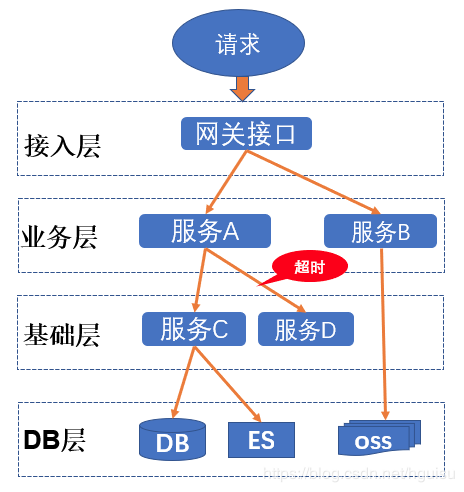
例如:在分布式微服务系统中,一个来自用户的请求,请求先达到网关接口A,然后网关接口通过远程调用A,B服务获取结果最终,A服务调用后端算法服务C、D,算法服务D需要需要访问ES, 这样经过一系列服务调用后最后将数据返回。经历了这么多个服务,怎么样将它的请求过程的数据记录下来呢?在各种服务之间调用我们面临主要问题:
1、监控问题:如何快速发现和定位问题?即如何做好链路监控,及时掌握系统健康状况和实时了解自身的业务运行情况。
2、故障问题:如何判断故障影响范围? 某个服务出现问题后,可以判断对系统哪些服务有影响。
3、依赖问题:如何梳理服务依赖以及依赖的合理性? 服务依赖是否存在逆向或者循环调用。
4、性能分析:如何分析链路性能问题和容量规划?对于激增的流量可以有应急方案和准备。
同时我们会关注在请求处理期间各个调用的各项性能指标,比如:吞吐量(TPS)、响应时间及错误记录等。
- 吞吐量 ,根据拓扑可计算相应组件、平台、物理设备的实时吞吐量。
- 响应时间 ,包括整体调用的响应时间和各个服务的响应时间等。
- 错误记录 ,根据服务返回统计单位时间异常次数。
全链路性能监控 从整体维度到局部维度展示各项指标 ,将跨应用的所有调用链性能信息集中展现,可方便度量整体和局部性能,并且方便找到故障产生的源头,生产上可极大缩短故障排除时间。
在这种情况下,一般都会引入APM(Application Performance Management & Monitoring应用性能监控管理)系统,通过各种探针采集数据,收集关键指标,同时搭配数据呈现和监控告警,能够解决上述的大部分问题。
二、APM需求
Google开源的 Dapper链路追踪组件,并在2010年发表了论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》(即《 Dapper,大规模分布式系统的跟踪系统》),这篇文章是业内实现链路追踪的标杆和理论基础,具有非常大的参考价值。
Dapper 的基本思路 :是在服务调用的请求和响应中加入SpanID,标明上下游请求的关系。利用这些跟踪信息,可以可视化地分析服务调用链路和服务间的依赖关系。
《 Dapper,大规模分布式系统的跟踪系统》,总结如下:
1、APM功能模块
1)、埋点与生成日志
埋点即系统在当前节点的上下文信息,可以分为 客户端埋点、服务端埋点,以及客户端和服务端双向型埋点。埋点日志通常要包含以下内容traceId、spanId、调用的开始时间,协议类型、调用方ip和端口,请求的服务名、调用耗时,调用结果,异常信息等,同时预留可扩展字段,为下一步扩展做准备;
不能造成性能负担:一个价值未被验证,却会影响性能的东西,是很难在公司推广的!
因为要写log,业务QPS越高,性能影响越重。通过采样和异步log解决。
2)、收集和存储日志
主要支持分布式日志采集的方案,同时增加MQ作为缓冲;
每个机器上有一个 deamon 做日志收集,业务进程把自己的Trace发到daemon,daemon把收集Trace往上一级发送;
多级的collector,类似pub/sub架构,可以负载均衡;
对聚合的数据进行 实时分析和离线存储;
离线分析 需要将同一条调用链的日志汇总在一起;
3)、分析和统计调用链路数据,以及时效性
调用链跟踪分析:把同一TraceID的Span收集起来,按时间排序就是timeline。把ParentID串起来就是调用栈。
抛异常或者超时,在日志里打印TraceID。利用TraceID查询调用链情况,定位问题。
依赖度量:
- 强依赖 :调用失败会直接中断主流程
- 高度依赖 :一次链路中调用某个依赖的几率高
- 频繁依赖 :一次链路调用同一个依赖的次数多
离线分析:按TraceID汇总,通过Span的ID和ParentID还原调用关系,分析链路形态。
实时分析:对单条日志直接分析,不做汇总,重组。得到当前QPS,延迟。
4)、展现以及决策支持
2、APM技术目标
1)、探针的性能消耗
APM组件服务的影响应该做到足够小。服务调用埋点本身会带来性能损耗,这就需要调用跟踪的低损耗,实际中还会通过配置采样率的方式,选择一部分请求去分析请求路径。在一些高度优化过的服务,即使一点点损耗也会很容易察觉到,而且有可能迫使在线服务的部署团队不得不将跟踪系统关停。
2)、代码的侵入性
即也作为业务组件,应当尽可能少入侵或者无入侵其他业务系统,对于使用方透明,减少开发人员的负担。
对于应用的程序员来说,是不需要知道有跟踪系统这回事的。如果一个跟踪系统想生效,就必须需要依赖应用的开发者主动配合,那么这个跟踪系统也太脆弱了,往往由于跟踪系统在应用中植入代码的bug或疏忽导致应用出问题,这样才是无法满足对跟踪系统“无所不在的部署”这个需求。
3)、可扩展性
一个优秀的调用跟踪系统必须支持分布式部署,具备良好的可扩展性。能够支持的组件越多当然越好。或者提供便捷的插件开发API,对于一些没有监控到的组件,应用开发者也可以自行扩展。
4)、数据的分析
数据的分析要快 ,分析的维度尽可能多。跟踪系统能提供足够快的信息反馈,就可以对生产环境下的异常状况做出快速反应。分析的全面,能够避免二次开发。
三、开源APM系统
在谷歌论文《 Dapper,大规模分布式系统的跟踪系统》的指导下,许多优秀开源的APM系统应运而生。
目前市面上开源的APM系统主要有CAT、Zipkin、Pinpoint、SkyWalking,大都是参考Google的 Dapper 实现。
1、各个开源APM简介
CAT:是由国内美团点评开源的,基于Java语言开发,目前提供Java、C/C++、Node.js、Python、Go等语言的客户端,监控数据会全量统计,国内很多公司在用,例如美团点评、携程、拼多多等。从网上相关资源查阅:集成方案是通过代码埋点的方式来实现监控,比如: 拦截器,注解,过滤器等。 对代码的侵入性很大,集成成本较高。风险较大。
Zipkin:由Twitter公司开发并开源,Java语言实现。如果是基于spring cloud 微服务系统,结合spring-cloud-sleuth使用较为简单, 集成很方便。
Pinpoint:一个韩国团队开源的产品,运用了字节码增强技术,只需要在启动时添加启动参数即可,对代码 无侵入 ,目前支持Java和PHP语言,底层采用HBase来存储数据,探针收集的数据粒度非常细,但性能损耗大,因其出现的时间较长,完成度也很高,应用的公司较多
SkyWalking: 国人开源的产品,主要开发人员来自于华为 ,2019年4月17日Apache董事会批准SkyWalking成为顶级项目,支持Java、.Net、NodeJs等探针,数据存储支持Mysql、Elasticsearch等,跟Pinpoint一样采用字节码注入的方式实现代码的 无侵入 ,探针采集数据粒度粗,但性能表现优秀,且对云原生支持,目前增长势头强劲,社区活跃,中文文档没有语言障碍
2、功能技术比较
面对各种链式追踪系统开源,我们如何选择:
1、结合公司自身情况:包括系统复杂度、使用技术栈。
2、根据上面提到APM的技术需求:探针的性能消耗、代码的侵入性、可扩展性、数据分析的指标来选择。
| cat | zipkin | pinpoint | skywalking | |
|---|---|---|---|---|
| 依赖 | Java 6,7,8 Maven 3.2.3+ mysql5.6 Linux 2.6以及之上(2.6内核才可以支持epoll) |
Java 6,7,8 Maven3.2+ rabbitMQ |
Java 6,7,8 maven3+ Hbase0.94+ |
Java 6,7,8 maven3.0+ nodejs zookeeper elasticsearch |
| 实现方式 | 代码埋点(拦截器,注解,过滤器等) | 拦截请求,发送(HTTP,mq)数据至zipkin服务 | java探针,字节码增强 | java探针,字节码增强 |
| 存储选择 | mysql , hdfs | in-memory , mysql , Cassandra , Elasticsearch | HBase | elasticsearch , mysql、H2 |
| 通信方式 | — | http , MQ | thrift | GRPC |
| MQ监控 | 不支持 | 不支持 | 不支持 | 支持(RocketMQ,kafka) |
| 全局调用统计 | 支持 | 不支持 | 支持 | 支持 |
| trace查询 | 不支持 | 支持 | 不支持 | 支持 |
| 报警 | 支持 | 不支持 | 支持 | 支持 |
| JVM监控 | 不支持 | 不支持 | 支持 | 支持 |
| star数 | 4.5K | 7.9K | 5.6K | 2.8K |
| 优点 | 功能完善。 | spring-cloud-sleuth可以很好的集成zipkin , 代码无侵入,集成非常简单 , 社区更加活跃。 对外提供有query接口,更加容易二次开发 |
完全无侵入, 仅需修改启动方式,界面完善,功能细致。 | 完全无侵入,界面完善,支持应用拓扑图及单个调用链查询。 功能比较完善(zipkin + pinpoint) |
| 缺点 | 1、代码侵入性较强,需要埋点 2、文档比较混乱,文档与发布版本的符合性较低,需要依赖点评私服 (或者需要把他私服上的jar手动下载下来,然后上传到我们的私服上去)。 |
1、默认使用的是http请求向zipkin上报信息,耗性能。 2、跟sleuth结合可以使用rabbitMQ的方式异步来做,增加了复杂度,需要引入rabbitMQ 。 3、数据分析比较简单。 |
1、不支持查询单个调用链, 对外表现的是整个应用的调用生态。 2、二次开发难度较高 |
1、3.2版本之前BUG较多 ,网上反映兼容性较差 . 3.2新版本的反映情况较少 2、依赖较多。 |
| 文档 | 网上资料较少,仅官网提供的文档,比较乱 | 文档完善 | 文档完善 | 文档完善 |
| 开发者 | 大众点评 | naver | 吴晟(华为开发者) ,目前已经加入Apache孵化器 | |
| 支持技术栈 | dubbo spring mvc ,spring aop ,springmvc-url spring boot mybatis log4j , logback playframework http请求 |
dubbo spring mvc spring boot |
Tomcat 6+, Jetty 8/9, JBoss 6, Resin 4, Websphere 6+, Vertx 3.3+ Spring, Spring Boot (Embedded Tomcat, Jetty) HTTP Client 3.x/4.x, HttpConnector, GoogleHttpClient, OkHttpClient, NingAsyncHttpClient Thrift, Dubbo mysql, oracle, mssql, cubrid,PostgreSQL, maria arcus, memcached, redis, cassandra MyBatis DBCP, DBCP2, HIKARICP gson, Jackson, Json Lib log4j, Logback |
Tomcat7+ , resin3+, jetty spring boot ,spring mvc strtuts2 spring RestTemplete ,spring-cloud-feign okhttp , httpClient msyql ,oracle , H2 , sharding-jdbc,PostgreSQL dubbo,dubbox ,motan, gRpc , rocketMq , kafla redis, mongoDB,memcached , elastic-job , Netflix Eureka , Hystric |
| 使用公司 | 大众点评, 携程, 陆金所,同程旅游,猎聘网 | naver | 华为软件开发云、天源迪科、当当网、京东金融 | |
| 客户端支持语言 | JavaScript,Python,Java, Scala, Ruby, C#, Go | Java,.NETCore ,PHP, Python和 NodeJS |
3、性能比较
我们没有实际测试这些组件的性能:摘自 https://juejin.im/post/5a7a9e0af265da4e914b46f1
比较关注探针的性能,毕竟APM定位还是工具,如果启用了链路监控组建后,直接导致吞吐量降低过半,那也是不能接受的。对skywalking、zipkin、pinpoint进行了压测,并与基线(未使用探针)的情况进行了对比。
选用了一个常见的基于Spring的应用程序,他包含Spring Boot, Spring MVC,redis客户端,mysql。 监控这个应用程序,每个trace,探针会抓取5个span(1 Tomcat, 1 SpringMVC, 2 Jedis, 1 Mysql)。这边基本和 skywalkingtest 的测试应用差不多。
模拟了三种并发用户:500,750,1000。使用jmeter测试,每个线程发送30个请求,设置思考时间为10ms。使用的采样率为1,即100%,这边与生产可能有差别。pinpoint默认的采样率为20,即50%,通过设置agent的配置文件改为100%。zipkin默认也是1。组合起来,一共有12种。下面看下汇总表:
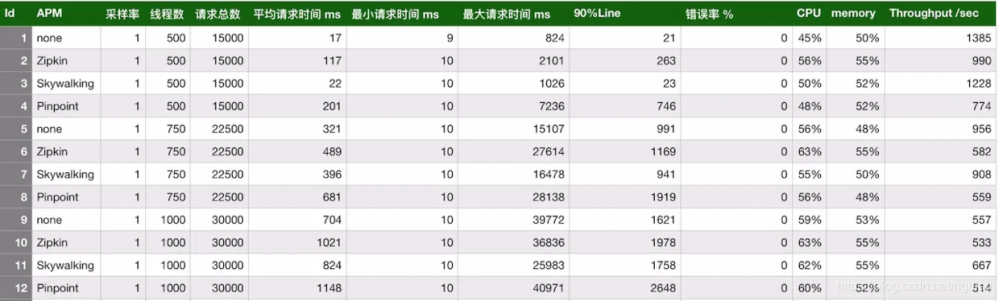
从上表可以看出,在三种链路监控组件中, skywalking的探针对吞吐量的影响最小,zipkin的吞吐量居中。pinpoint的探针对吞吐量的影响较为明显 ,在500并发用户时,测试服务的吞吐量从1385降低到774,影响很大。然后再看下CPU和memory的影响,在内部服务器进行的压测,对CPU和memory的影响都差不多在10%之内。
4、collector的可扩展性
zipkin
开发zipkin-Server(其实就是提供的开箱即用包),zipkin-agent与zipkin-Server通过http或者mq进行通信, http通信会对正常的访问造成影响,所以还是推荐基于mq异步方式通信 ,zipkin-Server通过订阅具体的topic进行消费。这个当然是可以扩展的, 多个zipkin-Server实例进行异步消费mq中的监控信息 。
skywalking
skywalking的collector支持两种部署方式: 单机和集群模式。collector与agent之间的通信使用了gRPC 。
pinpoint
同样,pinpoint也是支持集群和单机部署的。 pinpoint agent通过thrift通信框架,发送链路信息到collector 。
===================================================================
参考: https://juejin.im/post/5a7a9e0af265da4e914b46f1
正文到此结束
- 本文标签: sharding SDN dist db QPS Cassandra 文章 REST spring AOP 京东 数据 开源 测试 rabbitmq Netflix 时间 统计 ip Logback 谷歌 JavaScript 进程 mybatis web Spring Boot 配置 mongo Google client node JDBC 程序员 python 负载均衡 Eureka 云 IO HDFS 开发者 性能问题 协议 zipkin Feign 需求 core tomcat 微服务 json scala 线程 快的 apache id sql bug API MySQL5 端口 字节码 App ACE js 2019 软件 mysql cache 集群 UI 总结 服务器 RocketMQ Spring cloud 代码 src jetty Agent 实例 Job Oracle 大众点评 zip 服务端 zookeeper 分布式系统 管理 DBCP tab JVM CTO http https 部署 插件 linux ORM cat 金融 开发 探针 分布式 架构设计 Node.js lib maven pinpoint MongoDB 下载 tar 美团 java MQ HBase Elasticsearch redis dubbo 插件开发 Sleuth JMeter 推广 struct 并发 SpringMVC Twitter 产品 参数 PHP Spring REST 系统架构
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
收到
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
https://pplx.ai/floraliu4199466 这个链接打不开是什么原因?
-
-
-
-
来看看,最近更新了一波,顺着友联过来的,几年过去了,网站越搞越好,厉害
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

