架构设计(15)-- 分布式链路跟踪:我们自研log2组件
我们最近升级改造我们链路跟踪系统Log2,然后我们花了将近一周时间调研不少开源的链路跟踪系统,在此调研过程中,做了一些笔记和总结,若有误请指教。
《 分布式链路跟踪1: 理论知识 》
《 分布式链路跟踪2: Zipkin实践 》
《 分布式链路跟踪3:skywalking原理和实践 》
《 分布式链路跟踪4:自研组件Log2 》
一、log2背景
我们系统在2016年开始基于dubbo开始做分布式服务化,当时没有专门的架构运维团队,一些运维工作分散到研发人员头上,研发人员各自管理运维及自己研发应用所用的服务。在这个阶段,频繁出现问题,出现问题后又不能快速定位问题。比如dubbo偶尔超时问题,我们都无法定位问题在哪,一开始以为是我们使用dubbo不当,或者框架问题。后来我通过tcpdump抓包分析,也没有定位到问题。这时我们急需一个链路跟踪系统,简单满足如下需求:
1、全局globalId. 根据globalId可以查询所有相关日志。
2、跟踪记录入口方法action参数和返回结果。
3、记录响应时间。
4、记录某个方法的执行时间。
5、跟踪组件不能影响业务需求。
二、基本原理
由于当时我们服务几乎都是JAVA开发,我们也简单调研一些开源系统,没有满足第2条需求。当时skywalking还没有那么流行。
最后我们自研组件,我们就命名为log2,然后通过ELK来展示。
JAVA分布式链路追踪其实原理都很简单:
1、上下文传递:
每个请求过来,主线程都会分配一个线程newThread 来执行请求。把请求的context存到该分配线程newThread 的ThreadLocal里面(一般使用InheritableThreadLocal 《线程ThreadLocal和TransmittableThreadLocal区别》 ),然后context随着线程一路传递下去就行。
2、拦截请求
1、实现org.springframework.web.servlet.HandlerInterceptor接口实现拦截器。
2、利用Spring的切面(AOP)实现拦截。
例如:zipkin的链路跟踪是通过拦截器实现,在服务入口处添加拦截器,获取上级请求过来的链路信息span,然后构建新span。并将新span信息存在当前线程ThreadLocal中。使用接口拦截器可以获取拦截的请求对应的类和方法的相关信息,但缺点在于该handler对象无法获取具体执行方法的参数信息。而基于AOP实现的拦截器可以获取到具体参数。
因此最后我们选择AOP实现。
3、跨服务传递跟踪信息
开源跟踪组件一般都是通过修改rpc header来实现传递跟踪信息,由于我们已经记录了方法参数,因此在参数里面传递全局globalId。
三、自研log2历程
1.0版本的需求简单:
1、全局ID.
2、跟踪入口方法action参数和返回结果。
3、记录响应时间。
4、记录某个方法的执行时间。
5、跟踪组件不能影响业务需求。
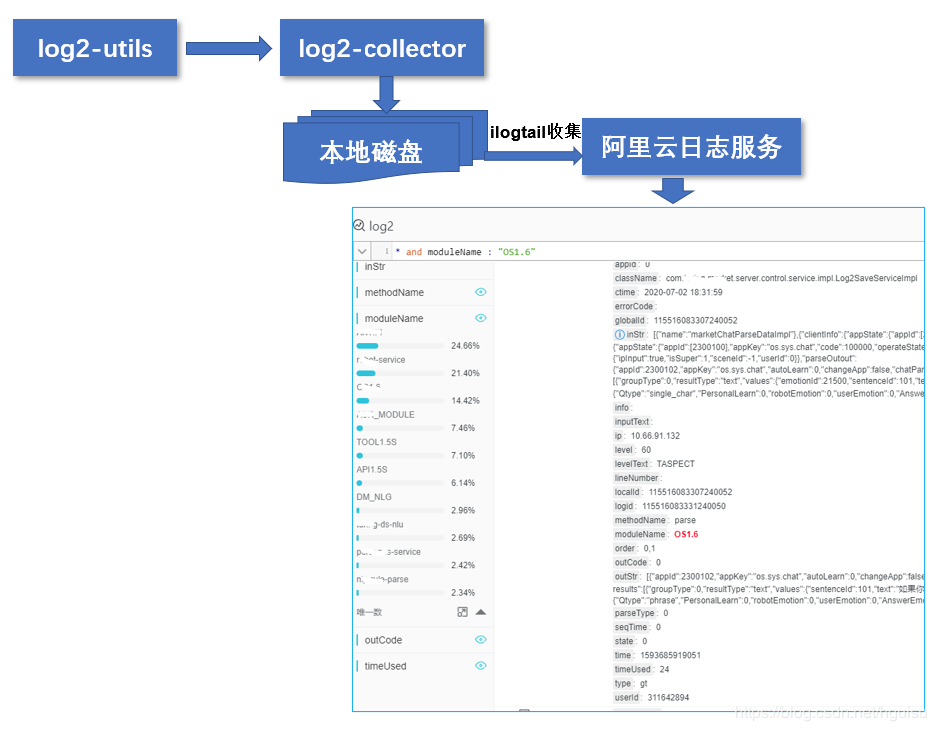
系统主要由:
log2-utils:采集器,采集跟踪信息。
log2-collector: 日志接收中心,并做些格式化落地,方便存储。
ELK:日志展示查询

组件开发完成后,应用在一些不重要的服务,在这期间我们也不敢大面积的推广使用,遇到不少问题:
1、ThreadLocal的问题:ThreadLocal内存泄漏,没有及时清掉log2Context。
2、父子线程传递问题:ThreadLocal不支持继承性,比如new Thread() 新线程无法传递log2Context,改InheritableThreadLocal就没问题。《 线程ThreadLocal和TransmittableThreadLocal区别 》
3、线程池问题:InheritableThreadLocal的log2Context在线程池里面重复使用,需要使用Alibaba的一个库解决了这个问题 https://github.com/alibaba/transmittable-thread-local
1.xx.x 版本的需求:
2017年底log2使用已经比较稳定,但是还没有大规模推广使用,系统难于定位问题仍然存在。一次又一次无休止的故障总结会后,我们强制推广log2,同时阿里云的日志服务产品也正好出来,我们放弃ELK, 日志全部存储到日志阿里云日志服务上。(阿里云日志服务产品开始收费比较低, 按1T/天的日志量,我们自己搭建ELK, 单服务器费用就花费不少。)
在这期间,我们:
1、优化了log2-collector,分析方法参数和方法返回结果。
2、使用阿里云的监控服务,监控log2日志的响应时间。
遇到的问题:
log2-collector虽然也是异步处理,但接收并发过大,QPS到达万级别,导致log2-utils发送队列堆积,造成某个应用服务内存泄漏。我们解决办法是在应用服务器部署log2-collector,应用服务器直接通过127.0.0.1来发送。
2.0版本的需求:
2019年,我们优化升级到2.0 :
1、log2-util可以过滤方法参数,比如图片参数。
2、全局globalId由网关nginx生成,log2-util通过HttpRequestContext来获取。
这样通过globalId实现了nginx日志和log2日志关联
目前2.0版很稳定,log2-utils性能消耗很低,在qps为500情况下,消耗请求时间大概为3~5ms。
整体架构如下:
四、3.0版本
我们最近调研了zipkin, skywalking等优秀的开源跟踪系统,目前不能应用开源跟踪系统的原因:
1、缺少参数信息:开源跟踪系统都没有方法参数记录。
2、服务费用成本:使用开源跟踪系统,需要自建ES集群,日志量比较大,需要几十台服务器,成本比较高。
3、人力成本比较大:迁移肯定需要有人来完成。
回到我们开头,我们升级改造log2,升级到3.0版本
1、优化代码结构,考虑是否可以开源。
2、优化和日志组件log4j2,logback集成使用。
3、日志落地
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

