深入理解Spring IOC(七) 、 总结,含常见面试题
我们在之前的文章中,对spring加载bean的流程做了详细的讲解,我们知道要将xml中的各个节点解析成真正的bean要经过下面的主要过程:
1、将xml中的信息解析成BeanDefinition,这其中,XmlBeanDefinitionReader专门负责去读取xml,并且将xml中的信息解析成BeanDefinition放到DefaultListableBeanFactory中。
2、BeanFactoryPostProcessor去根据自己的需要修改BeanFactory中已经加载好的BeanDefinition
3、拿到所有的beanName,一个一个的去对单例调用getBean方法去初始化,这个过程分为了以下步骤:
- (1)将这个beanName对应的BeanDefinition转化成RootBeanDefinition,这也是出于初始化的需要,RootBeanDefinition才是标准的初始化流程需要的BeanDefinition,里面包含了很多解析过程的缓存,以及其他重要的属性,这步主要是DefaultListableBeanFactory的preInstantiateSingletons中做的。
- (2)接下来是要看是通过工厂方法还是构造方法去创建这个对象,如果有工厂方法,则去解析需要的工厂方法和其参数,如果没有工厂方法,则需要使用构造方法去创建对象,这时候就需要判断究竟使用哪个构造方法,判断流程为先使用AutowiredAnnotationBeanPostProcessor中的determineCandidateConstructors方法来确定候选的构造方法,这里确定的原则主要是根据注解来确定,如果你有多个@Autowired标注的构造方法,那么只能有一个的required为true,determineCandidateConstructors方法可能会返回多个方法,这时候需要根据参数匹配的原则来匹配最合适的构造方法并解析其参数,这时候可能会触发其他bean的初始化(createArgumentArray方法),最合适的构造方法和参数都拿到后,则去调用它创建对象。这一步主要是在AbstractAutowireCapableBeanFactory中的createBeanInstance中完成。
- (3)获取到上一步创建的对象之后,则要进行属性填充的工作,这时候主要处理的是@AutoWired绑定的属性和方法,@Value绑定的属性,@Inject绑定的属性。这个工作主要是在AbstractAutowireCapableBeanFactory中的populateBean方法中完成。
- (4)属性填充完毕之后,则去执行各种初始化的方法,其中有InitializingBean,以及@PostConstruct和在xml中定义的init-method都会在这里执行,这个工作是在AbstractAutowireCapableBeanFactory中的initializeBean中完成。
- (5)判断是不是需要提前曝光bean。
相关面试题
话说其实我是不怎么愿意讲面试题的,因为我认为你把源码看懂之后根本就不需要看这样的东西,但是大多数读者貌似都有这样的需求,所以也就没办法,说说最常见的一些面试题
顺便求一波赞,祝点赞的人面试一飞冲天:smile:~
-
- IOC的好处:这个在我的这篇文章( 深入理解Spring IOC(一) 、统一资源的加载 )的开篇说的很清楚了,好处是解耦,具体的你可以回过头再去看看。
-
-
Spring怎么解决循环依赖: 循环依赖主要是通过三层缓存来解决的,三层缓存并不是官方概念,当然我也不知道是谁提出来的这个概念,就姑且这么叫吧。这三层缓存在源码中分别是singletonObjects,earlySingletonObjects,以及singletonFactories这三个map。其中singletonObjects是用来保存创建好的成品对象,earlySingletonObjects是用来保存提前曝光出来的对象,singletonFactories是用来保存获取半成品对象的ObjectFactory的。它们是怎么配合起来解决循环依赖的呢?我们来看个最简单的例子:
有两个类A和B,A中有类型为B的成员属性,B中又有类型为A的成员属性,注意不能是prototype,也不能是构造器依赖。当创建了一个不完整的A对象时候(其实也就是只调用了A的构造方法而没有进行属性填充),这时候会把这个“不完整”的A对象包装成ObjectFactory后放到singletonFactories中,再去做属性填充的动作,然后就在属性填充的时候发现了需要初始化B,就跑去初始化B去了,然后也是先创建了一个不完整的B并且包装成ObjectFactory放到了singletonFactories后去填充属性,这时候发现需要一个A,然后又去初始化A,但是此时singletonFactories里面的话已经有个不完整的A的ObjectFactory了,这时候就可以通过这个singletonFactories来获取到半成品的A的ObjectFactory,再通过A的ObjectFactory获取到半成品A,注意这里还会把这个半成品A的ObjectFactory从singletonFactories移除, 然后还会把半成品A放到earlySingletonObjects中去 ,拿到半成品A后去填充B,B创建完了之后再用创建完的B填充A,这样A和B的创建过程就完成了
-
为什么需要把半成品A放到earlySingletonObjects中去呢?你可以试着结合那部分的源码想一下A依赖B,B依赖C,C依赖D,D又依赖A、B、C的这种复杂循环依赖场景你就会明白了。另外earlySingletonObjects的设计并不仅仅是为了解决循环依赖,它是还有别的作用的(代理相关的),所以不要仅仅只是背面试题。我现在再就问你一个问题,Spring是怎样判断你的这两个Class是不是循环依赖的?估计很多只是背题的人就懵了,所以只背题而根本都不看相关源码的话,面试官总是可以花式吊打你的,不信你到我面前来试试:smiling_imp:
-
- bean的生命周期: 所谓生命周期,主要是涵盖着从bean的诞生一直到被销毁,网上还有文章扯到了BeanFactoryPostProcessor上面了,但是在BeanFactoryPostProcessor执行的时候,bean还没变成受精卵呢你生命周期个蛋蛋,看过我文章的都知道因为此时还是BeanDefinition而已,bean都还没有初始化。对于bean的生命周期,我认为在《spring揭秘》这本书上的这张图可以说是解释的很准确了:
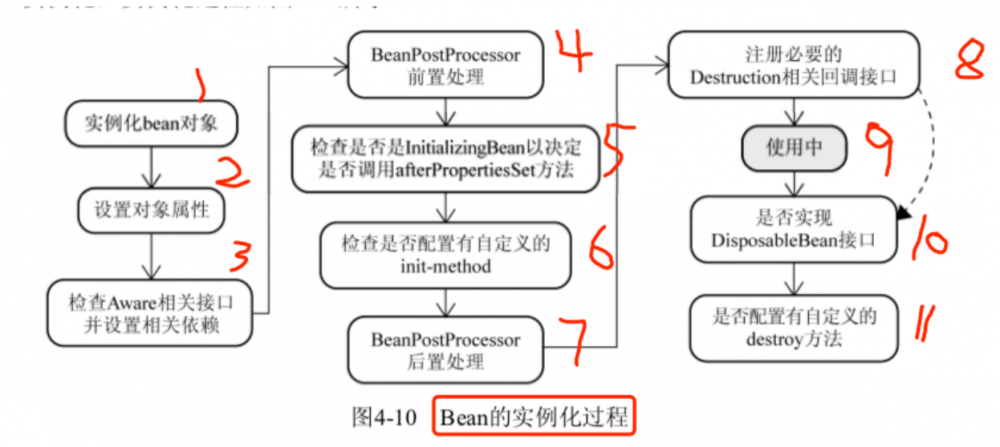
为了把这个问题说的更清楚一些,我不顾让图变丑的巨大危险,给图里的步骤上面标上了表示步骤的数字 ,
我们一步一步来看:
第1步,创建一个"不完整"的bean对象,细节在第五篇的creatBeanInstance方法中,这是创建bean必须经过的过程(除过代理);
第2步填充属性也是必须经过的,哪怕你没有属性,这一步也是要走的;
第3步这个,是先检查你的bean是不是实现了Aware接口,没有实现Aware那就直接跳过了,如果实现了Aware,还要检查是哪个Aware,然后才会给你设置某个Aware,这里会检查三个Aware,分别是BeanNameAware、BeanClassLoaderAware、BeanFactoryAware这三个Aware,注意肯定是没有ApplicationContextAware的,网上说有这个Aware的怕是自己都根本没看过源码的;
第4步这个是BeanPostProcessor的前置处理,是必须经过的;
第5步和第6步,都是先要检查,然后满足条件才调用,没有的话就跳过了;
第7步这个是BeanPostProcessor的后置处理,也是必须经过的;
第8步是你这个bean必须是个DisposableBean或者实现了java的AutoCloseable接口,或者你得实现DestructionAwareBeanPostProcessor这个接口,才会走这步,这时候会把你满足条件的bean加到disposableBeans这个map中方便后续调用(和三层缓存在一个类中);
第9步对应的是我们在业务中的使用;
第10和第11步是对应销毁bean,这个通常是因为AbstrctApplicationContext的close方法被调用,这时候会调用之前存在disposableBeans中的所有bean的相关销毁的方法,也是属于不一定会走的方法。
为什么我把图上的文字“Bean的实例化过程”用红框圈出来了呢?因为很明显,这个图不仅仅包含创建了,而是还有销毁过程,因此我觉得这个图更应该叫做bean的生命周期而不是Bean的实例化过程才对(个人观点)~
不止于源码的
到这里,整个正篇部分就完了,后边还有一些扩展篇没有写完。或许你到这里觉得spring ioc的代码很牛,但其实真正牛的是ioc的这种思想,它真正意义上解决了面向对象的痛点。很多人都很认同spring为java续命了十几年,这种说法我一定程度上是认同的,现在spring系列的东西为我们的开发生产带来了太多的便利,当然也淘汰了一大批人,很多人只会crud的逐渐适应不了这种变化,也有很多人抱怨变化太快,但是如果你一直也只是会用别人封装的东西的话那其实说真的,不淘汰你淘汰谁?
话又说回来,Spring解决了面向对象编程的痛点,那又有什么缺点呢?我们现在做微服务的小伙伴肯定都有这样的体验,就是一个springboot应用,明明我们业务代码在里面没有多少,但是这个应用真正跑起来都很很费内存,这个就和spring应用在运行期间有自动装载了很多的bean有着千丝万缕的关系,这一点其实不太符合微服务的这个味道。
至于为什么要读源码,我想看到我说这些心里话的这块的人,我们是有一个共同的目标,那就是希望自己能成为一个比别人更好一些的工程师。我自己是的目标便是要自己做的能够比别人更好。Ioc这部分源码看完了之后,觉得看很多框架层面报的错都变简单了很多,更重要的是去看好多框架和Spring整合的源码这里是真的变得很容易,这并不是我在装逼,而是自己真真实实的收获和提高。
或许你虽然看到了这里但是前面的文章却都还看的不太明白,这其实很正常,我还是建议你能从我第一篇给出来的github上面把我的代码拉下来,进去对着我的注释跟一跟, 研究源码,从来不可能只是看看别人的文章就能明白那里面的东西,那是必须一遍遍的看,一遍遍的debug 。也有很多读者很有野心,总是想在面试的时候反手把面试官按在地上摩擦一下证明证明自己,但是那绝对不是说是你背多少题就能做到的,要想经得起考验,肯定是要把内功练好的。想要变得比别人强这点恒心还是需要有的,我看源码看的头昏眼花,但是最后都坚持下来了。如果有什么问题实在不明白,也可以和我来沟通,我如果有时间会给你讲,我的邮箱是554013882@qq.com,文章有什么问题,也可以发到这里来。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

