一个JVM内存溢出问题分析解决(200704)
今天准备结合一个案例再详细说明下技术问题分析诊断的全过程。
自己从事软件开发和架构设计多年,虽然已经较长时间没有参与具体的编码开发工作,但是仍然是沉淀大项目一线的项目管理,总体架构设计,牵头进行关键技术问题的分析和诊断。在谈具体问题解决前,我先想谈两个重点感觉,即:
1.历史的技术实践积累和知识可能遗忘,但是遗留下的问题解决思路不会遗忘
2.不要惧怕问题,任何复杂技术问题的解决往往就是自我学习和知识重新梳理的过程
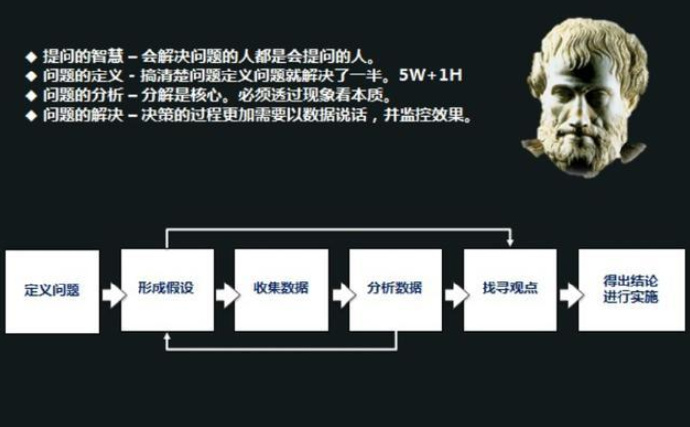
思维框架再怎么完善,问题解决方法论再怎么详尽,你仍然会看到实际的问题分析解决往往并不会对问题解决方法进行生搬硬套,但是我们经常谈到的问题定义-》分析》解决的核心流程不变,其次就是谈到提出最优假设并快速验证确认的解决思路不变。
问题现象和问题定义
在讲具体的问题诊断和分析前,首先来看下问题现象是如何的,即:
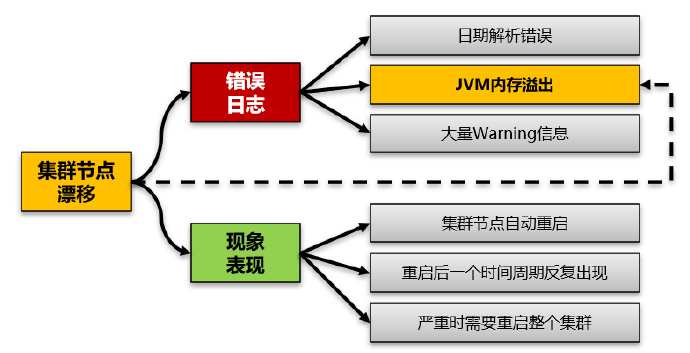
在生产环境运行的业务系统,对于中间件集群出现了集群节点偏移现象,在中间件的系统日志中出现了大量的错误信息,其中包括了时间解析错误,也看到了内存溢出的错误信息。
对于做技术的可能都知道,生产环境的运行问题解决往往困难度很大,特别是一些无法在开发测试环境进行重新的问题,比如上面谈到的运行过程中的节点偏移和溢出,这类问题基本没有可能在测试环境重新,你只能基于生产环境运行情况进行分析。
如果一个问题能够在开发环境重现,那么自然就简单,你完全可以在开发环境进行代码的Debug,通过Debug可以快速的问题点并进行解决。
对问题现象的进一步说明
可以看到该问题的现象即是集群节点出现了漂移,同时有集群节点出现了JVM Out of Memory内存溢出的异常信息日志。在该问题出现侯后继续观察我们会发现。漂移会导致集群节点机器自动重启,重启后有时候可以自动恢复,如果漂移影响到多个节点往往需要人工干预对整个集群进行重启。而这个影响往往就很大。
另外,集群或节点重启后系统运行正常,但是过半天或1天时间后会再次触发节点重启。
基于以上说明,我们给出一个问题的初步定义如下:
任何一个生产环境出现了故障或问题的时候我们都要清楚,实际上你需要有两个层面的思考。
层面1:是什么导致的?你有无标准的经验和套路积累
层面2:究竟是什么问题,必须要明确清楚真正要解决的是什么问题再去找原因
两个层面实际上是问题解决的两种常见方法。对于层面1更多则是黑盒思维,从外在环境变化入手的非结构化解决方式,快速的提出最可能假设并严重,对于层面2则是从问题本身异常入手去分析具体根源。
初步分析1-问题解决标准套路
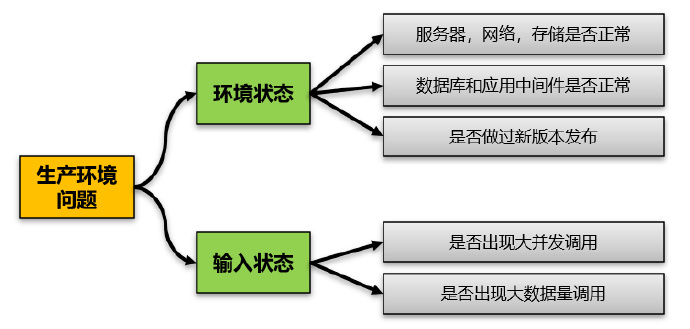
基于我们已有的实践经验,我们应该对不同类型的问题形成标准的解决套路,包括对于问题发现后最基本的问题定义和边界思考。举例来说,对于生产环境如果出现问题,我们首先就是要考虑一个软件运行环境,如果没有做过什么大的变动,一般并不会无缘无故的就出现问题,那么基于这个思路我们思考方式应该为:
- 基础服务器,网络硬件环境是否正常
- 基础的数据库,中间件是否正常,是否做过配置修改和补丁安装
- 是否做过新版本部署和发布
- 外在输入是否发生变化,比如出现大并发,大数据量访问
简单来说上面这个就是最基本的生产环境出现问题的时候思考步骤。比如2和3都没有动过,但是我们对生产环境数据库进行了补丁程序升级,那么出现问题就应该优先假设是补丁程序导致。如果要快速的解决问题,最可行的方法仍然是先对补丁程序进行回滚。
基于标准套路完善问题定义
简单来说问题的初步分析过程往往也是进一步完善问题定义的过程,当我们看到我们的标准经验库的时候,我们会进一步的对我们面对的问题进行完善。而这个完善正好是两个方面:
其一是问题产生环境,其二是问题产生的输入。
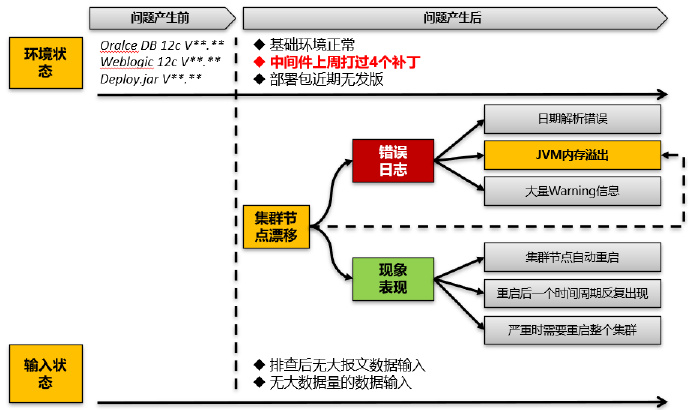
到了这里后,我们基本就把问题产生前后外在环境和输入输出的变化全部搞清楚了。其中唯一的一个大变化就在于补丁安装。
解决措施1-对于补丁是否会退?
在这里我们把补丁安装和是否回退拿出来单独做下讨论。
首先经过分析,我们一共打了4个补丁,而且其中还有一个补丁不支持回退。也就是说我们即使进行回退也回退不干净,万一就是刚好无法回退的补丁导致的问题怎么办?
其次,我们对我们面对的问题的严重度进一步分析。即该问题是集群中存在漂移和节点自动重启导致的问题,问题出现的频度并不高,往往是在1天或2天周期出现一次。同时在问题出现后集群往往可以自我修复,即自动对出问题的集群节点进行重启,重启完成后再进行挂接。
如果该问题发生频度高,实际上你只能够是紧急回退。
正是因为该问题的严重度没有想象的高,因此我们没有马上去做补丁回退的动作,因为如果补丁进行了回退,实际上问题在哪里并没有找到。那么后续补丁还如何继续打?即使Oracle技术支持来帮助解决问题,没有环境复现,估计也没法真正帮你解决掉。
但是基于标准套路经验匹配,我们至少最终确定了最可能问题导致原因,即补丁安装。
初步分析2-因果分清,找寻真正要解决的问题
在前面问题分析的两个层次谈到,第一是分析外在去看什么原因导致问题;其二是根据问题现象,从现象出发来看究竟什么是真正的问题。在前面的问题初步描述我们看到,实际有两个关键点。
第一就是集群节点漂移,其二是JVM内存溢出。
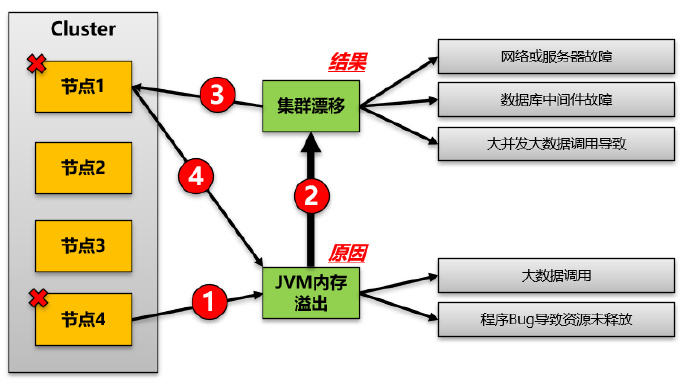
再次说明下,这个问题暴露出来首先我们得到的反馈是集群节点漂移。因此我们先根据日志信息和集群节点漂移关键字去查询了下support知识库,但是没有得到我们需要的信息,给出的原因也和该问题不符合。
其次我们回到详细的日志分析。日志里面明显可以查到类似java.lang.OutOfMemoryError: Java heap space这种异常日志信息。
那么集群漂移和堆内存溢出,究竟谁才是真正的问题?
在出现问题后,我们第一时间询问了数据中心的运维人员,了解网络和服务器是否正常,在得到了正常的答案后,我们进一步确认集群漂移肯定只是问题现象,而不是引起问题的根本原因。
为了印证这个假设,我们对集群中多台机器某个时间点的日志进行对比分析,最终确认了真正的问题是JVM内存溢出,而不是集群漂移,整体的问题现象过程可以结合上图阐述为:
- 节点4出现内存溢出,导致节点4无法工作
- 集群管理器将节点4上的所有请求漂移到节点1
- 节点1获取漂移过来的所有请求,但是由于请求量大,进一步导致节点1内存溢出
即内存溢出首先导致节点漂移,同时节点漂移又导致了更多的集群节点机器出现了内存溢出。
到了这一步,我们基本明确了要首先去分析和解决JVM内存溢出问题。
两个错误假设-排除JVM内存泄漏
在基本确认了是JVM内存泄漏后,由于我们在日志里面发现了其它的异常信息,因此我们首先对异常日志是否导致内存溢出进行了分析。但是从最终来看,去验证这个假设本身意义不大。
进入一个分支:即日期解析问题错误
在内存溢出后,实际我们当时并没有马上去看JVM的GC打印日志数据,而是首先看了集群环境的操作日志和错误日志。而从这些日志中我们发现了日期解析错误的问题。对于该问题的关键字如下:
java.text.ParseException: Unable to parse date[11-03-19 08:06PM]
using either Default Date Format[MM-dd-yyyy HH:mma] or
Recent Date Format[MM-dd-yyyy HH:mma] parse position=[0]
对于这个问题从日志上可以看出来,MFT在Get源端的文件目录和文件列表的时候,获取到的日期格式在解析的时候出现了错误。而对于源端是Windows服务器安装的SFTP服务,因此搜索该问题,最终得到的结果是需要将Windows下的FTP配置修改unix模式。
在完成这个修改后重新验证该问题解决。
注意,由于这个问题解决本身也需要在测试环境进行分析和验证,因此在问题没有解决前,我们先暂停了涉及到该问题的两个服务,然后重新观察日志输出和环境稳定性。
最终看到的是日志已经没有了,整个集群环境也没有再出现内存溢出。因此我们刚开始错误的认为问题点就在这个地方。但是实际gc日志里面内存仍然是在持续不断的增长。问题根本没有解决。再持续观察发现,即使是停止了这两个服务,仍然会出现内存溢出,集群节点需求去重启才能够解决问题。
日期解析问题这个错误的分支导致我们在分析解决问题中多花了了很多的时间。
另外一个分支:堆栈日志排除
接着我们又进入了另外一个分支,简单来说就是进一步排查堆栈日志。因为当时我给出另外一个假设,就是如何来确定究竟是哪个进程占用了大量的内存。
即先用Top命令来查看下占用大量内存的进程和线程信息,然后再到堆栈日志里面查看这些线程究竟是什么信息。占用内存大的线程,我们还需要进行16进制的转换,最终才能够在堆栈和线程日志里面找到对应的线程。这个时候我们在线程里面发现了相关的加锁信息,和等待解锁信息。
"ExecuteThread: '2' for queue: 'weblogic.socket.Muxer'" #189 daemon prio=5 os_prio=0 tid=0x00007f3004055800 nid=0x16e runnable [0x00007f30559dc000]
java.lang.Thread.State: RUNNABLE
at weblogic.socket.PosixSocketMuxer.poll(Native Method)
at weblogic.socket.PosixSocketMuxer.processSockets(PosixSocketMuxer.
- locked <0x000000060515d188> (a weblogic.socket.PosixSocketMuxer$1)
而实际这个信息并没有太大的作用,即weblogic监听程序有加锁,但是并没有形成死锁,有锁和等待是正常的,单纯从这里并看不出来具体有什么问题。

从上图我们的jstat线程堆栈里面我们也看到有锁。但是咨询Oracle后反馈,对于Weblogic监听程序上有锁是正常的,只要不是循环等待的死锁。也就是说单纯从线程日志信息仍然无法发现关键的问题所在。
对于JVM内存溢出问题解决
网上有很多关于Java JVM内存溢出的问题和解决方案,实际上对于这类问题已经属于一种很常见的问题,已经形成了一种标准的问题解决和诊断方法论。
最佳方法就是按照这个步骤去诊断,而不是靠你自己经验去提出各种假设,因为在这种情况下你提出的假设很可能都是瞎猜,反而浪费了大量时间。
既对于问题在你没有足够经验的时候一定遵循通用方法论步骤去解决。再回到内存溢出问题,这个问题通用步骤如下:
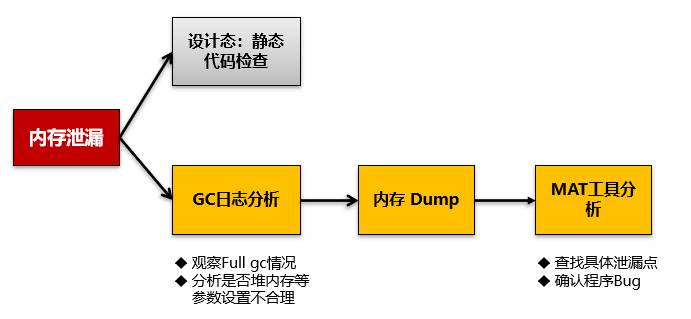
到了这里,我们基本回归到通用问题解决方法论。
由于是生产环境问题,而且由于是商用产品,我无法在测试环境重现,也无法进行静态代码检查。因此首先还是需要进行Java GC的内存回收日志分析。
对于Java启动的时候,我们已经设置了类似如下的启动参数对日志进行打印记录。
从表象到根源-一个软件系统JVM内存溢出问题分析解决全过程

因此在出现问题后,我们基本每2个小时左右对gc日志进行一次提取和分析。
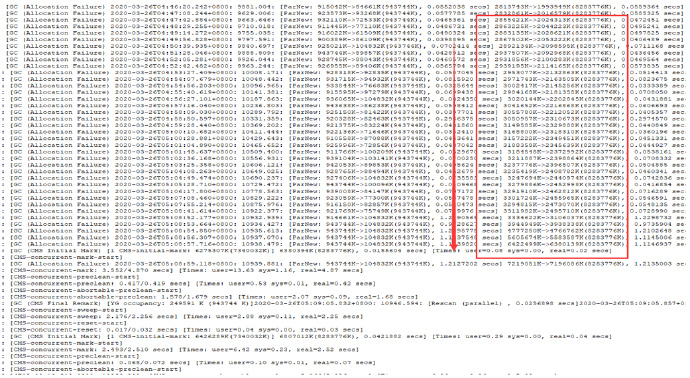
我们本身JVM启动参数堆内存设置6g,应该足够大了。实际从JVM内存启动数据来看,发现堆内存增值相当快,导致较为频繁的Full GC或CMS GC操作。而实际上在这个时间段业务系统本身根本就没有大的并发和数据量调用。
对于CMS GC回收,回收时间相当长。其次在回收后往往只能从6g回收到5g,也就是说在堆内存里面已经形成了大量的泄漏内存无法进行垃圾回收。同时我们也看到,在多次回收不下来的时候,节点出现内存溢出。到这里我们基本有了一个基本的问题诊断结论,即:
堆内存持续增长无法回收,导致了JVM内存溢出,存在内存泄漏可能性极大。
再次进入一个错误分支-调整JVM启动参数
在上面图可以看到。通用的问题诊断方法也包括两个方面,一个就是通过gc数据观察,先分析是否存在JVM启动参数设置不合理的情况导致了内存溢出。
因此在这里我们又进入到一个错误分支去调整JVM参数。为什么说是错误分支,因为根据前面分析,JVM参数再不合理也不应该导致full gc操作都无法将堆内存回收下来。
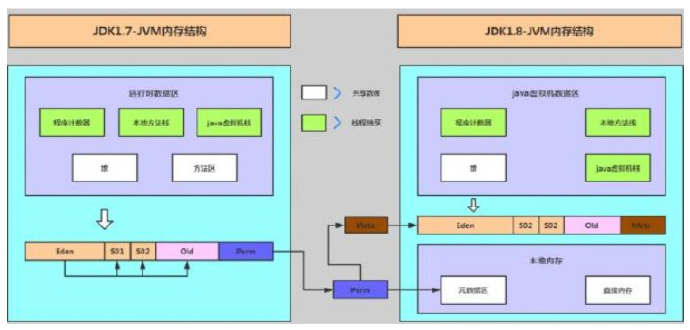
可以看下我们设置的JVM启动参数
for linux-amd64 JRE (1.8.0_181-b13), built on Jul 7 2018 00:56:38 by "
Memory: 4k page, physical 32781868k(10560756k free), swap 8388604k(7407524k free)
CommandLine flags: -XX:CMSInitiatingOccupancyFraction=80 -XX:+ExplicitGCInvokesConcurrent -XX:InitialHeapSize=8589934592 -XX:MaxHeapSize=8589934592 -XX:MaxMetaspaceSize=4294967296 -XX:MaxNewSize=1073741824 -XX:MaxTenuringThreshold=6 -XX:MetaspaceSize=2147483648 -XX:NewSize=1073741824 -XX:OldPLABSize=16 -XX:+ParallelRefProcEnabled -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCMSInitiatingOccupancyOnly -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
JDK8+移除了Perm,引入了Metapsace,它们两者的区别是什么呢?Metasace上面已经总结了,无论-XX:MetaspaceSize和-XX:MaxMetaspaceSize两个参数如何设置,都会从20.8M开始,随着类加载越来越多不断扩容调整,上限是-XX:MaxMetaspaceSize,默认是几乎无穷大。
而Perm的话,我们通过配置-XX:PermSize以及-XX:MaxPermSize来控制这块内存的大小,jvm在启动的时候会根据-XX:PermSize初始化分配一块连续的内存块,这样的话,如果-XX:PermSize设置过大,就是一种赤果果的浪费。
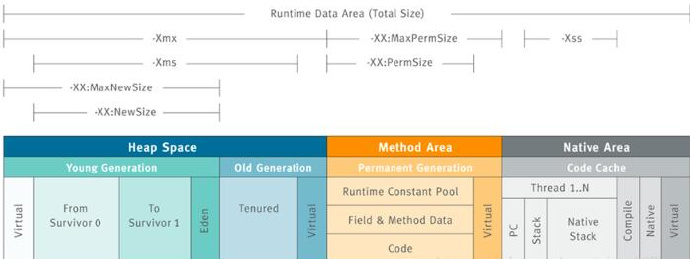
我们为何去调整JVM启动参数?
首先我们在GC日志里面看到了大量的Minor GC操作,我们感觉这个操作很频繁,即新生代的内存只有1G,会快速的占用新生代后触发Minor GC操作进行内存转移。
因此我们怀疑是否是 MaxNewSize 设置太小的原因导致。由于我们集群里面有两组集群,有一组集群没有出现故障,我们去看了下另外一组集群的启动参数配置。发现MaxNewSize的配置为2G。这个设置按照Sun官方建议年轻代的大小为整个堆的3/8左右,也合理。因此我们申请对该设置进行调整。
但是调整后发现问题依然没有解决,反而触发了更加严重的Gull GC操作。
找寻内存泄漏的工具
到这里我们走到最后一步,还是需要通过MAT工具去找寻内存泄漏。
MAT(Memory Analyzer Tool)工具是eclipse的一个插件(MAT也可以单独使用),使用起来非常方便,尤其是在分析大内存的dump文件时,可以非常直观的看到各个对象在堆空间中所占用的内存大小、类实例数量、对象引用关系、利用OQL对象查询,以及可以很方便的找出对象GC Roots的相关信息,当然最吸引人的还是能够快速为开发人员生成内存泄露报表,方便定位问题和分析问题。
当然你也可以下载独立运行的MAT应用。
对于MAT工具本身实际早就知道,但是为何我们一开始没有马上去使用该工具。
一个原因就是当时看了下,Dump出来这个文件接近6个G,文件巨大,这么大的文件是否能够分析和处理我们当时比较怀疑,因此一直没有去尝试。
比如对于内存溢出的问题,观察到的现象就是堆内存持续的增长而无法释放,而且在进行full gc的时候内存也无法回收,最终导致内存溢出。而对于这个问题,简单来说即:
内存溢出--》内存泄漏-》应该去分析内存哪里泄漏-》dump内存数据进行分析
上面这个就是对于内存溢出和泄漏最标准的解决模式,我们就需要沿着这个模式走,在这里你不要再去提出各种假设,去猜测究竟哪里出现了内存泄漏。因为dump分析可以最快速的诊断出哪里有内存泄漏,这条路往往才是最佳最高效的解决路径。
因此我们还是通过jmap进行内存dump,拿到数据后通过MAT分析工具打开进行内存泄漏分析。
实际我们在osb内存溢出重启后,已经无法拿到dump数据。这个mft能拿到原因是内存在持续缓慢增长,而不是马上突变溢出。
在初次打开Dump文件的时候,直接导致MAT工具报内存泄漏,这种即是在处理问题过程中出现的一些小问题,这个问题网上搜索后很容易解决。
-Xmx1024m => -Xmx7024m
即对MAT工具本身的 JVM启动参数进行调整,将堆内存调整为7G。由于自己电脑刚好是8g内存,基本刚好能够支撑顺利打开文件。
在用该工具进行分析时候,即快速的找到和定位了问题点。
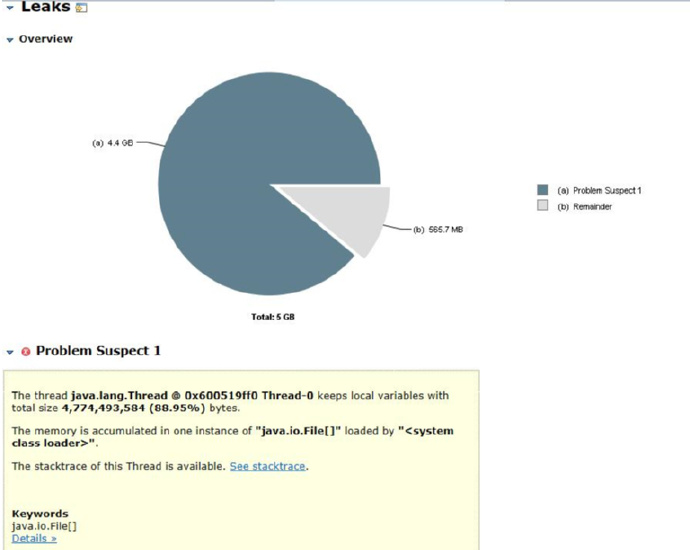
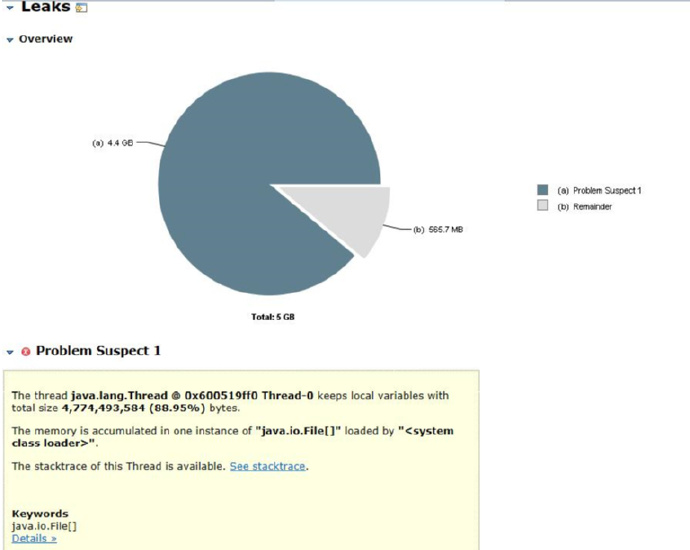
The thread java.lang.Thread @ 0x600519ff0 Thread-0 keeps local variables
with total size 4,774,493,584 (88.95%) bytes.
The memory is accumulated in one instance of
"java.io.File[]" loaded by "".
再进一步查看堆栈和对象信息可以看到,在这个线程里面一共初始化了900多万个Java.io.File对象并加入到了java.io.File[]集合里面。这个是问题的关键所在。
而继续查询可以看到该对象初始化对应的文件路径为集群中的临时目录和临时文件,而且大量的都是过期的临时文件。在通过ls命令查看该临时目录,发现该目录下有上千万的临时文件存在没有清理。
那么到了这里基本可以考虑的解决方法一定是先对临时文件和目录进行清理。

在我们对临时目录和临时文件进行删除的同时,我们对集群所有节点的内存gc数据日志进行了监控,从最近几天的监控情况可以看到,基本没有触发过大的full gc操作。其次,对于cms gc操作基本上每次只需要执行1次即可以将堆内存回收下来。
如果是当前这个日志数据来看,基本就已经到了一个正常的水平。
截至到这里,我们基本找到问题的根源,在清理掉临时目录和文件后,问题基本得到解决,但是我们真正找到问题的根源了吗?实际还是没有。
问题还需要进行的进一步思考

在进行清理的时候,又出来两个其他思考如下:
其一:为何应用会去大量的读这些临时文件目录,实际上正常的文件传输服务并不会去读这些临时文件目录。这个问题刚开始我们没有答案,但是实际上我们观察内存增长情况发现,内存的增长会在某些时间点出现突变,那么是否在这些时间点进行了某些定时任务处理。是否是purge schedule引起还需要进一步验证。
注:集群有一个purge schedule的定时任务清扫,但是在测试环境验证感觉好像没有清理。
其二:进一步分析观察到的堆栈信息可以看到,首先是调用isFIle来判断该文件究竟是目录还是文件,而要做这个操作又调用getBooleanAttributes0方法,这个方法在linux操作系统下实际上调用stat命令来分析究竟是目录还是文件。从线程堆栈信息来看,实际上卡死在这个地方。
待进一步分析的问题点
到此,基本定位还是需要清理临时文件目录,然后再观察。但是实际待进一步分析的仍然是究竟是什么定时任务或实际的运行实例任务在不断的读取临时文件目录,并不断的初始化File实例对象。这个如果进一步搞清楚那么整个问题才算得到彻底的解决并查找到根源。
问题的解决过程是知识不断整理和学习的过程
从表象到根源-一个软件系统JVM内存溢出问题分析解决全过程
我实际上一直在强调,对于技术人员一定不要怕技术问题。
往往对于复杂的技术问题,刚好正是锻炼你思维能力和分析解决问题能力的关键,在这个过程中一方面是利用已有的知识经验,一方面是在问题解决过程中不断的进行新知识学习。
比如对于该问题的解决,自己也基本又复习和学习了一遍相关的知识点。
- JVM内存模型(又重新复习了下 jvm内存模型)
- 内存泄漏问题的分析流程和分析工具
- MFT工具本身的传输机制和配置
- 相关linux 内存,进程,监控命令,gc数据日志分析
- 而这些知识本身对于你后期工作实践和新问题解决也相当有用。
正文到此结束
- 本文标签: 服务器 map 内存模型 实例 总结 项目管理 id 部署 FTP服务 js 集群 管理 parse 锁 ACE MQ 并发 root https 产品 大数据 解析 开发 SFTP 垃圾回收 测试环境 web ip 进程 关键技术 HTML 操作系统 删除 IO Full GC java eclipse 线程 数据 空间 解决方法 http ORM JVM 目录 windows 数据库 UI 时间 参数 src Action 架构设计 linux unix Oracle 配置 需求 软件 ftp queue bug 测试 swap 安装 代码 插件 对象初始化 下载 模型
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

