Java并发编程学习系列五:函数式接口、Stream流等
四大函数接口
什么是函数式接口?
有且只有一个抽象方法的接口被称为函数式接口,函数式接口适用于函数式编程的场景,Lambda 就是 Java 中函数式编程的体现,可以使用Lambda表达式创建一个函数式接口的对象,一定要确保接口中有且只有一个抽象方法,这样Lambda才能顺利的进行推导。
函数式接口里除了抽象方法之外,还允许包含默认方法和静态方法。
@FunctionalInterface注解
与@Override 注解的作用类似,Java 8中专门为函数式接口引入了一个新的注解:@FunctionalInterface 。该注解用于 编译级错误检查 ,加上该注解,当你写的接口不符合函数式接口定义的时候,编译器会报错。 。但是这个注解不是必须的,只要符合函数式接口的定义,那么这个接口就是函数式接口。
在 java.util.function 包下定义了内置核心四大函数式接口,可以使用 lambda 表达式。

关于这四个接口的介绍如下图所示:
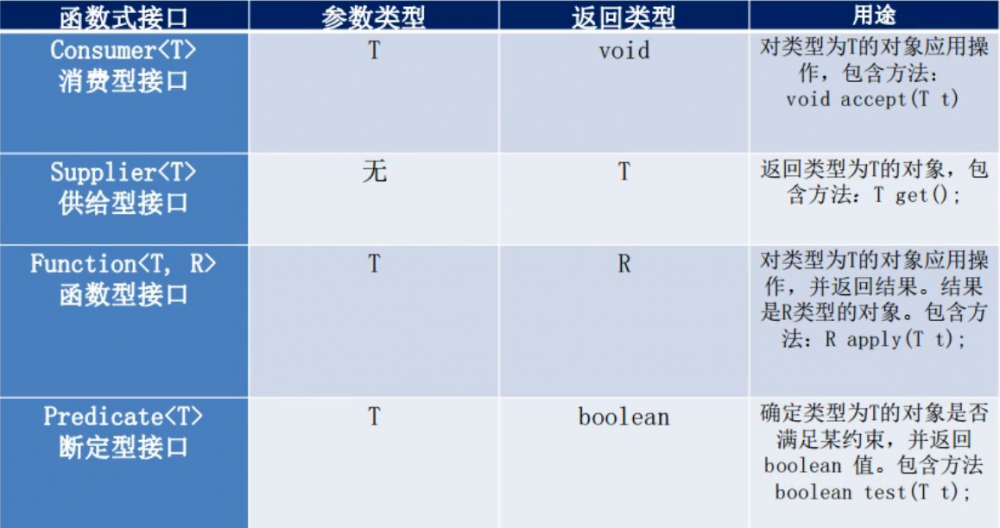
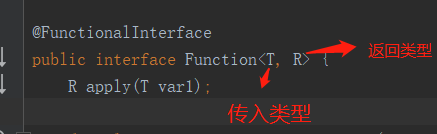
Function
函数型接口,有一个输入,有一个输出。
public static void main(String[] args) {
// Function function = new Function<String, Integer>() {
// @Override
// public Integer apply(String s) {
// return s.length();
// }
// };
//使用lambda表达式
Function<String, Integer> function = s -> {
return s.length();
};
System.out.println(function.apply("xxx"));
}
复制代码
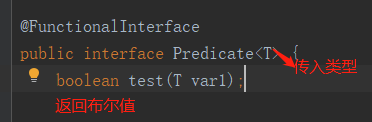
Predicate
断定型接口,有一个输入参数,返回只有布尔值。
public static void main(String[] args) {
//判断字符串是否为空,空返回true
// Predicate predicate = new Predicate<String>() {
// @Override
// public boolean test(String s) {
// return s.isEmpty();
// }
// };
Predicate<String> predicate = str ->{return str.isEmpty();};
System.out.println(predicate.test("ff"));
}
复制代码
Consumer
消费型接口,有一个输入参数,没有返回值。

public static void main(String[] args) {
// Consumer<String> consumer = new Consumer<String>() {
// @Override
// public void accept(String s) {
// System.out.println(s);
// }
// };
Consumer<String> consumer = Str ->{System.out.println(Str);};
consumer.accept("fjdskf");
}
复制代码
Supplier
供给型接口,没有输入参数,只有返回参数。

public static void main(String[] args) {
// Supplier<String> supplier = new Supplier<String>() {
// @Override
// public String get() {
// return "hresh";
// }
// };
Supplier<String> supplier = () -> {
return "hresh";
};
System.out.println(supplier.get());
}
复制代码
Stream流式计算
官网文档定义如下:
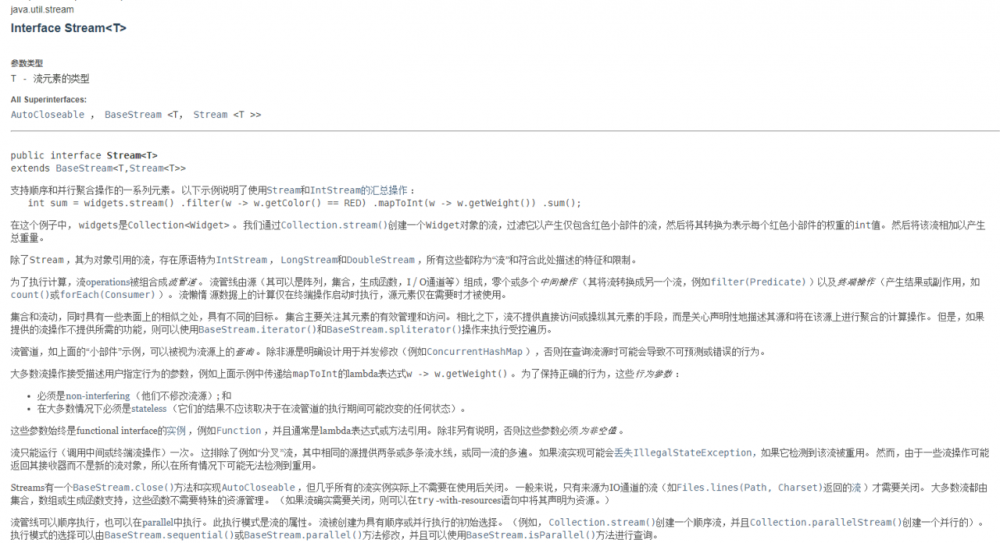
关于流的方法可以去 官网 看详细介绍。
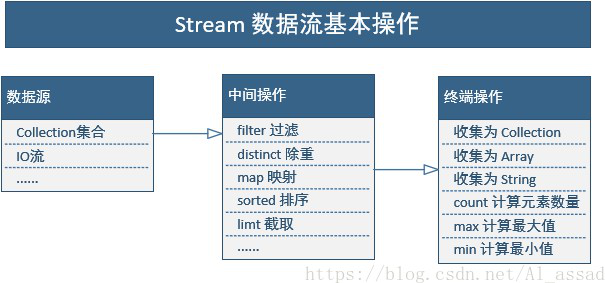
流(Stream)到底是什么呢?
是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。
集合存储数据,流讲的是计算!
特点:
- Stream 自己不会存储元素。
- Stream 不会改变源对象,相反,他们会返回一个持有结果的新Stream。
- Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
案例测试
1、新建一个实体类 User
@Data
@AllArgsConstructor
public class User {
private int id;
private String name;
private int age;
}
复制代码
2、流式计算
/**
* 题目:请按照给出数据,找出同时满足以下条件的用户
* 也即以下条件:
* 1、全部满足偶数ID
* 2、年龄大于24
* 3、用户名转为大写
* 4、用户名字母倒排序
* 5、只输出一个用户名字 limit
*/
public class Test {
public static void main(String[] args) {
User u1 = new User(1,"a",22);
User u2 = new User(2,"b",23);
User u3 = new User(3,"c",24);
User u4 = new User(4,"d",25);
User u5 = new User(6,"e",26);
List<User> list = Arrays.asList(u1,u2,u3,u4,u5);
list.stream().filter(u->{return u.getAge()>23;})
.filter(u->{return u.getId() %2 ==0;})
.map(u->{return u.getName().toUpperCase();})
.sorted((uu1,uu2)->{return uu2.compareTo(uu1);})
.limit(1)
.forEach(System.out::println);
List<Integer> list2 = null;
list2 = list.stream().map(u -> {return u.getAge()+2;}).collect(Collectors.toList());
list2.forEach(System.out::println);
}
}
复制代码
使用流式计算,代码看起来更加简洁,效率相应也会有所提升。
分支合并
什么是ForkJoin
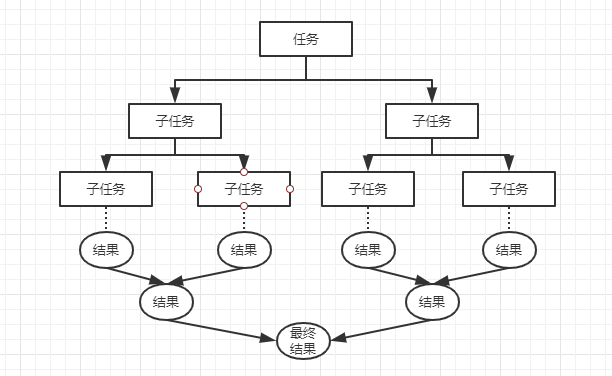
从 JDK1.7开始,Java 提供 Fork/Join 框架用于并行执行任务。ForkJoin 的框架的基本思想是分而治之。什么是分而治之?分而治之就是将一个复杂的计算,按照设定的阈值进行分解成多个计算,然后将各个计算结果进行汇总。相应的 ForkJoin 将复杂的计算当做一个任务。而分解的多个计算则是当做一个子任务。
主要有两步:
- 任务切分;
- 结果合并
它的模型大致是这样的:线程池中的每个线程都有自己的工作队列(PS:这一点和 ThreadPoolExecutor 不同,ThreadPoolExecutor 是所有线程共用一个工作队列,所有线程都从这个工作队列中取任务),当自己队列中的任务都完成以后,会从其它线程的工作队列中偷一个任务执行,这样可以充分利用资源。
工作窃取
另外,forkjoin 有一个工作窃取的概念。简单理解,就是一个工作线程下会维护一个包含多个子任务的双端队列。而对于每个工作线程来说,会从头部到尾部依次执行任务。这时,总会有一些线程执行的速度较快,很快就把所有任务执行完了。空闲下来的线程不会闲置下来,而是随机选择一个其他的线程从队列的尾巴上“偷走”一个任务。这个过程会一直继续下去,知道所有的任务都执行完毕。
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:
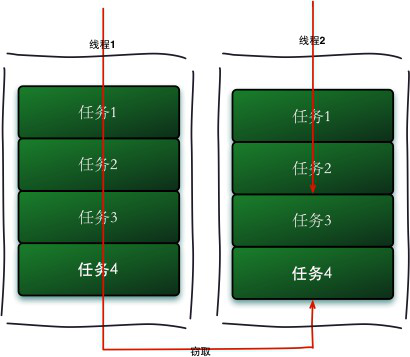
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
核心类
ForkJoinPool
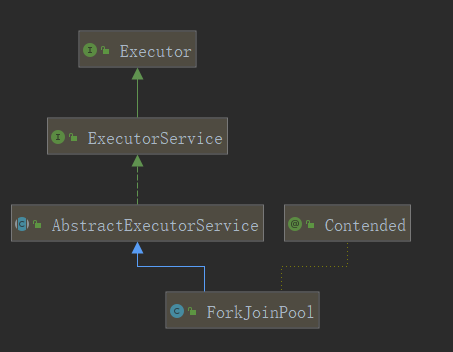
在官方文档中有如下定义:
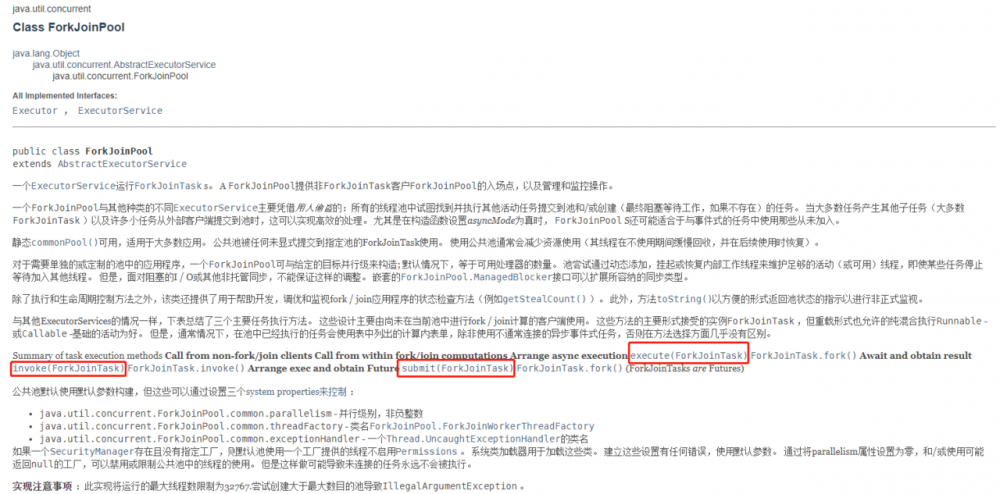
ForkJoinPool 执行任务的线程池,继承了 AbstractExecutorService 类,该线程池是通过 DefaultForkJoinWorkerThreadFactory 或者 InnoCuousForkJoinWorkerThreadFactory 线程工厂产生的工作线程 。
ForkJoinPool 主要通过 execute 、 invoke 和 submit 这三个方法来处理任务 ForkJoinTask 。查看方法详细介绍可知: execute 方法异步执行给定任务,无返回值; invoke 方法执行给定的任务,在完成后返回其结果,结果类型与 ForkJoinTask 中的 V 类型一致; submit 方法执行任务 ForkJoinTask 并返回一个结果任务 ForkJoinTask 。
查看上述三个方法,实质上都执行的是 externalPush 方法,在该方法中有个任务队列 WorkQueue ,它是 ForkJoinPool 的内部类, WorkQueue 中有执行任务的线程( ForkJoinWorkerThread owner ),还有这个线程需要处理的任务( ForkJoinTask<?>[] array ),新提交的任务就是加到 array 中。
ForkJoinWorkerThread
执行任务的工作线程,即 ForkJoinPool 线程池里面的线程,每个线程都维护者一个双端队列 WorkQueue ,用于存放内部任务。
ForkJoinTask
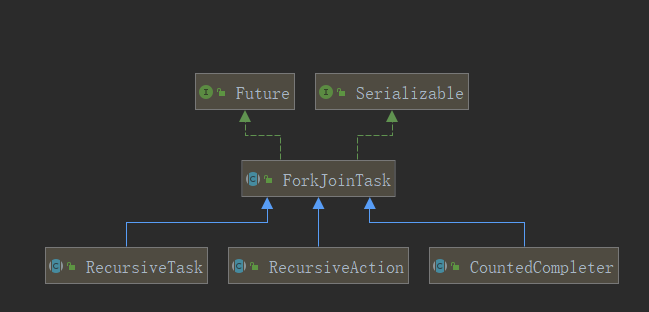
ForkJoinTask 代表运行在 ForkJoinPool 中的任务。主要方法:
fork() join() invoke()
子类: Recursive:递归
-
RecursiveAction一个递归无结果的ForkJoinTask(没有返回值) -
RecursiveTask一个递归有结果的ForkJoinTask(有返回值)
代码测试
RecursiveTask 实现类
public class ForkJoinDemo extends RecursiveTask<Long> {
private Long start; //起始值
private Long end; //结束值
public static final Long temp = 10000L;//临界值
public ForkJoinDemo(Long start, Long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
Long length = end - start;
//判断是否拆分完毕
if(length <= temp){
Long sum = 0L;
//如果拆分完毕就相加
for (Long i = start; i <= end; i++) {
sum+=i;
}
return sum;
}else{
Long middle = (start+end)/2;
ForkJoinDemo task1 = new ForkJoinDemo(start,middle);
task1.fork();//拆分,并压入线程队列
ForkJoinDemo task2 = new ForkJoinDemo(middle+1,end);
task2.fork();
//合并结果
return task1.join()+task2.join();
}
}
}
复制代码
测试代码
public class ForkJoinTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Long start = 0L;
Long end = 1000000000L;//10亿
work1(start,end); //5687
// work2(start,end); //4360
// work3(start,end); //195
}
//普通线程计算
public static void work1(Long start,Long end){
long startTime = System.currentTimeMillis();
Long sum=0L;
for (Long i = start; i<= end; i++) {
sum+=i;
}
long endTime = System.currentTimeMillis();
System.out.println("result="+sum+",time="+(endTime-startTime));
}
//ForkJoin实现
public static void work2(Long start,Long end) throws ExecutionException, InterruptedException {
long startTime = System.currentTimeMillis();
Long sum=0L;
ForkJoinPool pool = new ForkJoinPool();//实现ForkJoin 就必须有ForkJoinPool的支持
ForkJoinTask task = new ForkJoinDemo(start,end);
// ForkJoinTask result = pool.submit(task);
// sum = (Long) task.get();
sum = (Long) pool.invoke(task);
long endTime = System.currentTimeMillis();
System.out.println("result="+sum+",time="+(endTime-startTime));
}
//并行流进行大数值运算
public static void work3(Long start,Long end) {
long startTime = System.currentTimeMillis();
Long sum=0L;
sum = LongStream.rangeClosed(start,end).parallel().reduce(0,Long::sum);
long endTime = System.currentTimeMillis();
System.out.println("result="+sum+",time="+(endTime-startTime));
}
}
复制代码
异步回调
前言
我们前面讲并发编程一直都着重于多线程同步调用,除了同步线程,还存在异步线程。在此之前我们来回顾一下同步和异步的定义。
同步:就是当任务A依赖于任务B的执行时,必须等待任务B执行完毕之后任务A才继续执行,此过程任务A被阻塞。任务要么都成功,要么都失败!想一想我们打电话的情景即可! 异步 :任务A调用任务B,任务A不需要等到任务B执行完毕,任务B只是返回一个虚拟的结果给任务A,使得任务A能够继续做其他事情,等到任务B执行完成之后再通知任务A(回调)或者是任务A主动去请求任务B要结果。
Future 模式的核心思想是能够让主线程将原来需要同步等待的这段时间用来做其他的事情。(因为可以异步获得执行结果,所以不用一直同步等待去获得执行结果)
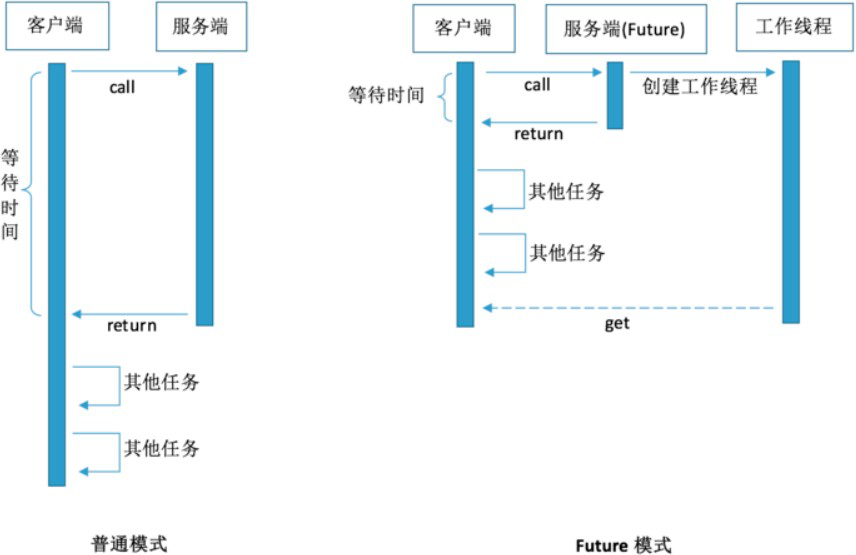
上图简单描述了普通模式和使用Future的区别,普通模式下,客户端访问服务端,等待结果返回非常耗时,此时客户端只能等待无法去做其他任务。而 Future 模式下,客户端向服务端发送完请求之后,先得到一个虚拟结果,真实的结果在未来某个时刻完成之后返回给客户端,而客户端在此期间可以去做其他任务。
Future的优点:比更底层的 Thread 更易用。要使用 Future ,通常只需要将耗时的操作封装在一个 Callable 对象中,再将它提交给 ExecutorService 。
ExecutorService executor = Executors.newFixedThreadPool(4); // 定义任务: Callable<String> task = new Task(); // 提交任务并获得Future: Future<String> future = executor.submit(task); // 从Future获取异步执行返回的结果: String result = future.get(); // 可能阻塞 复制代码
当我们提交一个 Callable 任务后,我们会同时获得一个 Future 对象,然后,我们在主线程某个时刻调用 Future 对象的 get() 方法,就可以获得异步执行的结果。在调用 get() 时,如果异步任务已经完成,我们就直接获得结果。如果异步任务还没有完成,那么 get() 会阻塞,直到任务完成后才返回结果。
一个 Future 接口表示一个未来可能会返回的结果,它定义的方法有:
get() get(long timeout, TimeUnit unit) cancel(boolean mayInterruptIfRunning) isDone()
使用 Future 获得异步执行结果时,要么调用阻塞方法 get() ,要么轮询看 isDone() 是否为 true ,这两种方法都不是很好,因为主线程也会被迫等待。
从Java 8开始引入了 CompletableFuture ,它针对 Future 做了改进,可以传入回调对象,当异步任务完成或者发生异常时,自动调用回调对象的回调方法。
代码测试
CompletableFuture 可以指定异步处理流程:
-
runAsync()返回无结果的CompletableFuture; -
supplyAsync()返回无结果的CompletableFuture; -
whenComplete()处理正常和异常结果; -
thenAccept()处理正常结果; -
exceptional()处理异常结果; -
thenApplyAsync()用于串行化另一个CompletableFuture; -
anyOf()和allOf()用于并行化多个CompletableFuture。
CompletableFuture.runAsync()
返回一个 CompletableFuture ,它需要一个实现了 Runnable 接口的对象 ,无返回值(此处说的无返回值指的是 CompletableFuture)。
public static void main(String[] args) throws ExecutionException, InterruptedException {
//没有返回值的异步回调
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(()->{
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
});
System.out.println("主线程优先执行");
completableFuture.get();
}
复制代码
执行结果为:
主线程优先执行 ForkJoinPool.commonPool-worker-1 复制代码
CompletableFuture.supplyAsync()
返回一个 CompletableFuture ,它需要一个实现了 Supplier 接口的对象 ,有返回值。
public class CompletableFutureTest {
public static void main(String[] args) throws InterruptedException {
//创建一个CompletableFuture
CompletableFuture<Double> cfture = CompletableFuture.supplyAsync(CompletableFutureTest::fetchPrice);//lambda语法简化方法调用
// cfture.thenAccept(result ->{// 如果执行成功
// System.out.println(result);
// }).exceptionally(e ->{// 如果执行异常
// e.printStackTrace();
// return null;
// });
cfture.whenComplete((r1,r2) ->{
System.out.println("执行结果为:"+r1); //输出执行成功的结果
System.out.println("异常信息:"+r2); //输出异常信息
}).exceptionally(e ->{// 如果执行异常
e.printStackTrace();
return null;
});
// 主线程不要立刻结束,否则CompletableFuture默认使用的线程池会立刻关闭
TimeUnit.SECONDS.sleep(2);
System.out.println("主线程执行完毕");
}
static Double fetchPrice() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
}
if (Math.random() < 0.3) {
throw new RuntimeException("fetch price failed!");
}
return 5 + Math.random() * 20;
}
}
复制代码
无异常时结果为:
执行结果为:6.110276836465158 异常信息:null 主线程执行完毕 复制代码
抛出异常结果为:

相比 Future , CompletableFuture 更强大的功能是,多个 CompletableFuture 可以串行执行。
public class CompletableFutureTest {
public static void main(String[] args) throws Exception {
// 第一个任务:
CompletableFuture<String> cfQuery = CompletableFuture.supplyAsync(() -> {
return queryCode("中国石油");
});
cfQuery.thenAccept((result) -> {
System.out.println("query result: " + result);
});
// cfQuery成功后继续执行下一个任务:
CompletableFuture<Double> cfFetch = cfQuery.thenApplyAsync((code) -> {
return fetchPrice(code);
});
// cfFetch成功后打印结果:
cfFetch.thenAccept((result) -> {
System.out.println("price: " + result);
});
// 主线程不要立刻结束,否则CompletableFuture默认使用的线程池会立刻关闭:
TimeUnit.SECONDS.sleep(2);
}
static String queryCode(String name) {
try {
TimeUnit.MILLISECONDS.sleep(200);
} catch (InterruptedException e) {
}
return name;
}
static Double fetchPrice(String code) {
try {
TimeUnit.MILLISECONDS.sleep(600);
} catch (InterruptedException e) {
}
return 5 + Math.random() * 20;
}
}
复制代码
除了串行执行外,多个 CompletableFuture 还可以并行执行。例如,我们考虑这样的场景:
同时从新浪和网易查询证券代码,只要任意一个返回结果,就进行下一步查询价格,查询价格也同时从新浪和网易查询,只要任意一个返回结果,就完成操作。
public class CompletableFutureTest {
public static void main(String[] args) throws Exception {
// 两个CompletableFuture执行异步查询:
CompletableFuture<String> cfQueryFromBing = CompletableFuture.supplyAsync(() -> {
return queryName("hresh", "https://cn.bing.com/");
});
CompletableFuture<String> cfQueryFromBaidu = CompletableFuture.supplyAsync(() -> {
return queryName("hresh2", "https://cn.baidu.com/");
});
// 用anyOf合并为一个新的CompletableFuture:
CompletableFuture<Object> cfQuery = CompletableFuture.anyOf(cfQueryFromBing, cfQueryFromBaidu);
// 并行执行结果可能是两个CompletableFuture中任意一个的返回结果
cfQuery.thenAccept((result) -> {
System.out.println("name: " + result);
});
// 主线程不要立刻结束,否则CompletableFuture默认使用的线程池会立刻关闭:
Thread.sleep(200);
}
static String queryName(String name, String url) {
System.out.println("query name from " + url + "...");
try {
Thread.sleep((long) (Math.random() * 100));
} catch (InterruptedException e) {
}
return name;
}
}
复制代码
参考文献
使用CompletableFuture
正文到此结束
- 本文标签: 并发编程 http IO 并发 多线程 参数 ask executor stream https IDE list DDL Service lambda struct 数据 DOM src Action 静态方法 tab UI App ThreadPoolExecutor 函数式编程 线程同步 测试 map CTO 同步 queue 模型 rand 编译 cat consumer 线程池 id 递归 java 线程 时间 final ACE 服务端 tag tar 代码
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

