Java中的GraphQL服务器:第三部分:提高并发性
GraphQL的思想是通过将多个通常不相关的请求批处理到一个网络调用中来减少网络往返的次数。通过一次传送许多信息,大大减少了等待时间。当多个顺序的网络往返可以用一个来代替时,它特别有用。好吧,老实说,每个网络浏览器都会自动为我们完成此操作。例如,当我们打开一个包含多个图像的网站时,浏览器将同时发送每个图像的HTTP请求。或者,确切地说,它将开始不超过与同一主机的一定数量的连接。介于2到8之间,具体取决于浏览器。同样适用于多个AJAX / RESTful调用(请参阅 fetch() API ),默认情况下是并发的,开发人员方面无需进行任何额外的工作。实际上,这就是_A_在AJAX 1中的含义。
那么,GraphQL有什么优势?
如果Web浏览器已经可以同时对多个数据发出并发请求,为什么还要麻烦GraphQL?有一些优点:
- 如果您需要进行的并发连接数量超出允许的数量(最多2-8个,请参见上文),浏览器无论如何都会限制您的工作,从而使一些请求排队
- GraphQL通过仅返回您明确要求的属性和关系来防止过度获取和N + 1问题,不多,也不少
- 只有一个批处理请求。并发发生在服务器端。好吧,不是真的...
GraphQL服务器默认情况下不使用并发
默认情况下,在Java的GraphQL服务器实现中, 最后一句_不正确_。记住,我们为每个非平凡的属性和关系提供了很多解析器。提醒一下,这是我们的解析器的外观:
@Component
class PlayerResolver implements GraphQLResolver<Player> {
Billing billing(Player player) //...
String name(Player player) //...
int points(Player player) //...
ImmutableList<Item> inventory(Player player) //...
}
这些方法中的每一个仅在需要时才被调用,并且每个都是潜在的重量级。不幸的是,默认情况下,服务器端的GraphQL引擎会顺序调用解析器方法。因此,与RESTful API(!)相比,总体延迟要差得多。Restful API将利用浏览器的内置并发性。为了显示这种行为的糟糕程度,我设置了Zipkin并跟踪了每个解析器:
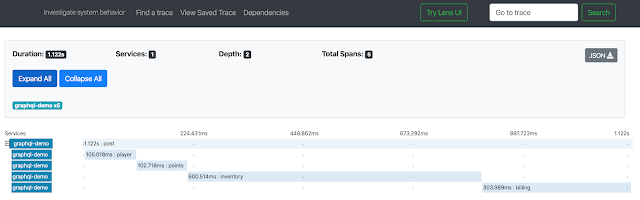
请注意,完全不相关的解析程序彼此之间是如何等待的。幸运的是,此性能瓶颈很容易解决。原来GraphQL引擎了解 CompletableFuture !
异步解析器
看看经过改进的解析器API:
@Component
class PlayerResolver implements GraphQLResolver<Player> {
CompletableFuture<Billing> billing(Player player) //...
CompletableFuture<String> name(Player player) //...
CompletableFuture<Integer> points(Player player) //...
CompletableFuture<List<Item>> inventory(Player player) //...
}
并发的来源在这里并不重要。有可能:
- Java的9分的
HttpClient, - 专用线程池,
- 从反应器的反应转换
Mono使用Mono.toFuture(), -
Deferred使用Kotlin的[ ]对象进行转换asCompletableFuture()
关键是,GraphQL考虑了这一未来,并同时调用多个解析器。看看Zipkin的效果如何:
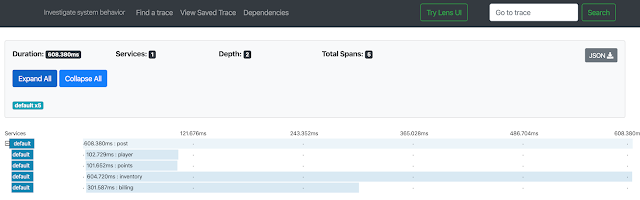
此图像教给我们两件事:
inventory
GraphQL为客户提供了绝佳的机会来以细粒度的方式自定义其查询。您要决定要多少数据。API生产者不再负责。同样,API不必是最低公分母。每个客户都做出独立的决定,而不是_一个合适的选择_。最后但并非最不重要的一点是,能够轻松地描述每个解析器是一个巨大的胜利。GitHub上提供了本系列所有文章
的 完整源 代码,包括Docker上的Zipkin设置。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

