总结《深入理解JVM》 G1 篇
注:一下内容主要结合《深入理解JVM》3th总结而来。
接上一篇,我们来说说 G1 , G1 作为现在的主要的 JVM GC ,被作为各大互联网主要使用的垃圾回收器,了解 G1 回回收原理和回收过程,才能帮组我们更好的定位问题,解决问题。
-XX:+UseG1GC 开启 G1 GC
G1内存划分
G1 看起来和 CMS 比较类似,但是实现上有很大的不同。
传统分代 GC 将整体内存分为几个大的区域,比如 Eden,S0,S1,Tenured 等。
而 G1 将内存区域分为了n个 不连续的 , 大小相同 的 Region , Region 具体的大小为1到32M,根据总的内存大小而定,目标是数量不超过2048个。 如下图所示:
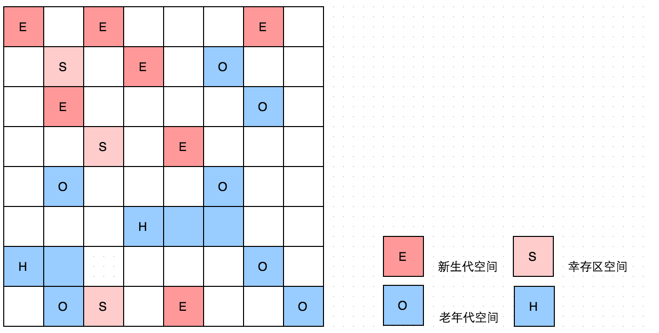
每个 Region 在 G1 中扮演了不同的角色,比如 Eden (新生区),比如 Survivor (幸存区),或者 Old (老年代)
除了传统的老年代,新生代, G1 还划分出了 Humongous 区域,用来存放巨大对象( humongous object,H-obj )。
对于巨大对象,值得注意的有以下几点:
-
H-obj的定义是大于等于Region一半的对象 -
H-obj直接分配到Old gen,防止频繁拷贝。但是H-obj的回收却不是在Mixed GC阶段,而是concurrent marking阶段中的clean up过程和full GC这点一定注意,在调优过程中你会在
GC日志中经常发现这句[GC pause (G1 Humongous Allocation) (young) (initial-mark), 0.0029216 secs]疑惑点就在于为什么
Humongous Allocation却是引发的yong gc。原因便是在于为了通过
yong gc的initial-mark开始进行concurrent marking,进而通过clean up回收大对象如果想要查看
G1日志的时候,为了方便快速达到GC的效果,你可能会直接分配一些大对象以便填满整个堆从而引发GC,但是如果光是大对象,你可能会发现GC日志中并没有Mixed GC,而是频繁的Yong GC和Concurrent Marking,这便是原因 -
H-obj永远不会被移动,虽然G1的回收算法总体上看是基于标记-整理的,但是对于H-obj则永远不会移动,要么直接被回收,要么一直存在。因此H-obj可能会导致较大的内存碎片进而引起频繁的GC
G1 的回收过程
G1 的内存划分形式,决定了 G1 同时需要管理新生代和老年代。根据回收区域的不同, G1 分为两种回收模式:
Yong GC Mixed GC
当 mixed gc 回收速度赶不上内存分配的速度, G1 会使用单线程(使用 Serial Old 的代码)进行 Full GC
其中,整个 Yong GC 过程都回 STW ,而 Mixed GC 主要包括两个阶段:第一个阶段为并发标记周期( Concurrent Marking ),这个过程主要进行标记,当完成并发标记后,再进行老年代的垃圾回收( Evacuation ):这个过程主要复制和移动对象,整理 Region 。
Mixed GC
按道理来说,应该先说 Yong Gc ,可是 Yong GC 貌似不是 G1 的回收重点,同时也没有什么参数可以控制 Yong GC ,所以这里暂时跳过。不过需要知道一点就是 Yong GC 的回收过程和其他垃圾回收器差不多,也是先标记,再复制。不过整个过程都会 STW ,同时由于 Yong GC 的标记过程和后面 Mixed GC 中的并发标记( Concurrent Marking )的第一个阶段,初始标记( initial marking )所做的工作相同,因此, Concurrent Marking 的初始标记阶段总是搭载着 Yong GC 进行。
Mixed GC 分为两个阶段,第一个阶段是并发标记,第二个阶段是筛选回收。并发标记过程如下:
- 初始标记(initial marking)
- 并发标记(concurrent marking)
- 最终标记(final marking,remarking)
- 清理(cleanup)
这里的清理不是清理对象(和CMS不太一样),虽然《深入理解JVM》将清理和筛选回收并为一个过程,但是 GC 日志上他们是完全分开的过程。这里以 GC 日志为准
标记完成后, G1 再选择一些区域进行筛选回收。注意,这几个阶段,是可以分开执行的,也就是说,可能得执行方式如下所示:
启动程序 -> young GC -> young GC -> young GC -> young GC + initial marking (... concurrent marking ...) -> young GC (... concurrent marking ...) (... concurrent marking ...) -> young GC (... concurrent marking ...) -> final marking -> cleanup -> mixed GC -> mixed GC -> mixed GC ... -> mixed GC -> young GC + initial marking (... concurrent marking ...)
接下来详解介绍每个标记阶段所做的工作。
初始标记(initial marking):会 Stop The World ,从标记所有 GC Root 出发可以直接到达的对象。这个过程虽然会暂停,但是它是借用的 Yong GC 的暂停阶段,因此没有额外的,单独的暂停阶段。
并发标记(concurrent marking): 并发阶段。从上一个阶段扫描的对象出发逐个遍历查找,每找到一个对象就将其标记为存活状态。注意:此过程还会扫描 SATB (并发快照)所记录的引用。
回忆并发快照:它是一个用来解决并发过程中由于用户修改引用关系而导致对象可能被误标的方案。 CMS 使用的是增量更新,这里 G1 使用的是并发快照,在并发标记开始的时候记录所有引用关系。
最终标记(final marking,remarking): 会 STW ,虽然前面的并发标记过程中扫描了 SATB ,但是毕竟上一个阶段依然是并发过程,因此需要在并发标记完成后,再次暂停所有用户线程,再次标记 SATB 。同时这个过程也会处理弱引用。
这三个阶段都和 CMS 比较类似, CMS 也是在最终标记阶段处理弱引用。
不过 CMS 的最终标记阶段需要重新扫描整个 Yong gen ,因此可能 CMS 的 remark 阶段会非常慢。
清理(clean up):暂停阶段。清理和重置标记状态。用来统计每个 region 中的中被标记为存活的对象的数量,这个阶段如果发现完全没有活对象的region就会将其整体回收到可分配region列表中。
标记完成后,便是清理( Evacuation ),这个阶段是完全暂停的。它负责把一部分 region 里活的对象拷贝到空的 region 里面,然后回收原本的 region 空间,此阶段可以选择任意多个 region 来构成收集集合( Collection Set ),选定好收集集合之后,便可以将 Collection Set 中的对象并行拷贝到新的 region 中。
明白了 G1 整体回收过程,接下来对比 CMS 我们可以看看 G1 是如何处理并发过程中的一些问题的:
-
记忆集(Remember Set): 前面说过,对于跨代引用的问题,
CMS选择了不维护新生代对老年代记忆集,因为新生代变化太快,维护起来开销比较大,而G1的解决方案是,不管Yong GC还是Mixed GC,都会将Yong Gen加入到Collection Set中,简单说就是要么是只回收新生代,要么整个新生代和老年代一起回收,这样就避免了新生代对老年代记忆集的维护。这里只讨论了新生代对老年代的引用的记忆集的维护,老年代对新生代的引用还是会维护一个记忆集的
-
并发过程中引用变化: 这里在
Remarking阶段我们已经说了,CMS使用的增量更新的方案,而G1则是使用的并发快照(STAB snapshot-at-the-beginning) -
关于记忆集和并发快照的维护,
G1也是通过写屏障(write barrier)来进行维护。
G1回收日志
talk is cheap, show me the code
以上过程基本上都是通过《深入理解JVM》和网上一些资料总结而来的,究竟是不是这样,还是需要实际操作一下,接下来我们看看 G1 的回收日志:
Yong GC
//GC 原因:分配大对象 GC类型yong gc 此次带有并发标记的initial mark 此次GC花费0.0130262s
[GC pause (G1 Humongous Allocation) (young) (initial-mark), 0.0130262 secs]
//暂停过程中,并行收集花费4.5ms 使用4个线程同时收集
[Parallel Time: 4.5 ms, GC Workers: 4]
//并发工作开始时间戳
[GC Worker Start (ms): Min: 1046.3, Avg: 1046.3, Max: 1046.4, Diff: 0.1]
//扫描root集合(线程栈、JNI、全局变量、系统表等等)花费的时间
[Ext Root Scanning (ms): Min: 0.9, Avg: 1.0, Max: 1.2, Diff: 0.3, Sum: 4.0]
//更新Remember Set的时间
//由于Remember Set的维护是通过写屏障结合缓冲区实现的,这里Update RS就是
//处理完缓冲区里的元素的时间,用来保证当前Remember Set是最新
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
//Update RS 过程中处理了多少缓冲区
[Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0]
//扫描记忆集的时间
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
//扫描代码中的Root(局部变量)节点时间
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.1]
//拷贝(疏散)对象的时间
[Object Copy (ms): Min: 3.0, Avg: 3.0, Max: 3.1, Diff: 0.0, Sum: 12.1]
//线程窃取算法,每个线程完成任务后会尝试帮其他线程完成剩余的任务
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
//线程成功窃取任务的次数
[Termination Attempts: Min: 1, Avg: 1.3, Max: 2, Diff: 1, Sum: 5]
//GC 过程中完成其他任务的时间
[GC Worker Other (ms): Min: 0.1, Avg: 0.2, Max: 0.3, Diff: 0.2, Sum: 0.8]
//展示每个垃圾收集线程的最小、最大、平均、差值和总共时间。
[GC Worker Total (ms): Min: 4.2, Avg: 4.3, Max: 4.3, Diff: 0.1, Sum: 17.1]
//min表示最早的完成任务的线程的时间,max表示最晚接受任务的线程时间
[GC Worker End (ms): Min: 1050.6, Avg: 1050.6, Max: 1050.6, Diff: 0.0]
//释放管理并行垃圾收集活动数据结构
[Code Root Fixup: 0.0 ms]
//清理其他数据结构
[Code Root Purge: 0.0 ms]
//清理card table (Remember Set)
[Clear CT: 0.8 ms]
//其他功能
[Other: 7.8 ms]
//评估需要收集的区域。YongGC 并不是全部收集,而是根据期望收集
[Choose CSet: 0.0 ms]
//处理Java中各种引用soft、weak、final、phantom、JNI等等。
[Ref Proc: 5.2 ms]
//遍历所有的引用,将不能回收的放入pending列表
[Ref Enq: 0.1 ms]
//在回收过程中被修改的card将会被重置为dirty
[Redirty Cards: 0.4 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
//将要释放的分区还回到free列表。
[Free CSet: 0.1 ms]
//Eden 回收前使用3072K 总共12M ——> 回收后使用0B,总共11M
//Survivors 回收前使用0B,回收后使用1024K
//整个堆回收前使用101M 总共256M,回收后使用99M,总共256M
//可以看到这里新生代没有占满就开始Yong GC,其目的是为了开启Concurrent Marking
[Eden: 3072.0K(12.0M)->0.0B(11.0M) Survivors: 0.0B->1024.0K Heap: 101.0M(256.0M)->99.0M(256.0M)]
[Times: user=0.00 sys=0.00, real=0.01 secs]
Concurrent Marking
并发标记一般发生在 Yong GC 之后。 Yong GC 之后便完成 initial mark 了
//扫描GC Roots [GC concurrent-root-region-scan-start] //扫描GC Roots完成,花费0.0004341s [GC concurrent-root-region-scan-end, 0.0004341 secs] //并发标记阶段开始 [GC concurrent-mark-start] //并发标记介绍。花费0.0002240s [GC concurrent-mark-end, 0.0002240 secs] //重新标记开始,会STW. //Finalize Marking花费0.0006341s //处理引用:主要是若引用。花费0.0000478 secs //卸载类。花费0.0008091 secs //总共花费0.0020776 secs [GC remark [Finalize Marking, 0.0006341 secs] [GC ref-proc, 0.0000478 secs] [Unloading, 0.0008091 secs], 0.0020776 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] //清理阶段 会STW //主要: 标记所有`initial mark`阶段之后分配的对象,标记至少有一个存活对象的Region //清理没有存活对象的Old Region和Humongous Region //处理没有任何存活对象的RSet //对所有Old Region 按照对象的存活率进行排序 //清理Humongous Region前使用了150M,清理后使用了150M ,耗时0.0013110s [GC cleanup 150M->150M(256M), 0.0013110 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Mixed GC
当并发标记完成后,就可以进行 Mixed GC 了, Mixed GC 主要工作就是回收并发标记过程中筛选出来的 Region
Mixed GC 做的工作和 Yong GC 流程基本一样,只不过回收的内容是依据并发标记而来的。
G1 可能不能一口气将所有的候选分区收集掉,因此 G1 可能会产生连续多次的混合收集与应用线程交替执行
[GC pause (G1 Evacuation Pause) (mixed), 0.0080519 secs]
[Parallel Time: 7.6 ms, GC Workers: 4]
[GC Worker Start (ms): Min: 140411.4, Avg: 140415.1, Max: 140418.9, Diff: 7.4]
[Ext Root Scanning (ms): Min: 0.0, Avg: 0.2, Max: 0.5, Diff: 0.4, Sum: 1.0]
[Update RS (ms): Min: 0.0, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.3]
[Processed Buffers: Min: 0, Avg: 1.3, Max: 4, Diff: 4, Sum: 5]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 0.0, Avg: 2.6, Max: 5.2, Diff: 5.2, Sum: 10.3]
[Termination (ms): Min: 0.0, Avg: 0.9, Max: 1.8, Diff: 1.8, Sum: 3.4]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 4]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms): Min: 0.1, Avg: 3.8, Max: 7.5, Diff: 7.4, Sum: 15.2]
[GC Worker End (ms): Min: 140418.9, Avg: 140418.9, Max: 140418.9, Diff: 0.0]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.1 ms]
[Other: 0.4 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.1 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.1 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]
[Eden: 4096.0K(4096.0K)->0.0B(138.0M) Survivors: 8192.0K->2048.0K Heap: 68.0M(256.0M)->65.5M(256.0M)]
[Times: user=0.03 sys=0.00, real=0.01 secs]
这里贴出日志,只是为了说明他们内容是一样的,因此这里就不再继续注释。
Full GC
G1 Full GC
//GC类型:Full GC GC原因:调用System.gc() GC前内存使用298M GC后使用509K 花费时间:0.0101774s [Full GC (System.gc()) 298M->509K(512M), 0.0101774 secs] //新生代:GC前使用122M GC后使用0B 总容量由154M扩容为230M //幸存区:GC前使用4096K GC后使用0B //总内存:GC前使用298M GC后使用509K 总量量512M不变 //元空间:GC前使用3308K GC后使用3308K 总容量1056768K [Eden: 122.0M(154.0M)->0.0B(230.0M) Survivors: 4096.0K->0.0B Heap: 298.8M(512.0M)->509.4K(512.0M)], [Metaspace: 3308K->3308K(1056768K)] [Times: user=0.01 sys=0.00, real=0.01 secs]
可以看到这次 GC 使用的时间是10ms,但是这仅仅是在整个堆只有512M,且只使用300M的情况下, G1 是没有 Full GC 的机制的, G1 GC 是使用的 Serial Old 的代码(后面被优化为多线程,但是速度相对来说依然比较慢),因此 Full GC 会暂停很久,因此在生产环境中,一定注意 Full GC ,正常来说几天一次 Full GC 是可以接受的。
G1 Full GC 的原因一般有:
-
Mixed GC赶不上内存分配的速度,只能通过Full GC来释放内存,这种情况解决方案后面再说 -
MetaSpace不足,对于大量使用反射,动态代理的类,由于动态代理的每个类都会生成一个新的类,同时class信息会存放在元空间,因此如果元空间不足,G1会靠Full GC来扩容元空间,这种情况解决方案就是扩大初始元空间大小。 -
Humongous分配失败,前面说过G1分配大对象时,回收是靠Concurrent Marking或Full GC,因此如果大对象分配失败,则可能会引发Full GC具体规则这里不太明白,因为测试的时候,
Humongous都是引发的Concurrent Marking。
G1调优
前面说了这么多,就是为了明白当 GC 影响到线上环境的时候的时候,应该怎么去调整。因此,明白了 G1 的回收过程,就能大体的明白每个参数的作用,应该如何去修改。
-
-XX:+UseG1GC: 使用G1回收器。 -
-XX:MaxGCPauseMillis = 200:设置最大暂停目标。默认为200,G1只会仅最大努力达到这个目标,这个目标值需要结合项目进行调整,时间太短,则可能会引起吞吐下降,同时每次Mixed GC回收的垃圾过少,导致最后垃圾堆积引起Full GC,时间太长,则可能会引起用户体验不佳。 -
-XX:InitiatingHeapOccupancyPercent = 45: 表示并发开始GC周期的堆使用阈值,当整个堆的使用量达到阈值时,就会开始并发周期。这个参数和CMS一样主要用来防止Mixed GC过程中的并发失败,如果过晚进行并发回收,则可能会因为并发过程中剩余的内存不足以满足用户所树妖的内存,这就会导致G1放弃并发标记,升级为Full GC.这种情况一般都能在GC中看到to-space exhausted字样。这个参数也不能调的太小,太小会导致一直循环,占用
CPU资源。 -
-XX:G1MixedGCCountTarget=8: 每次Mixed GC回收的老年代内存数量,默认为8,这也是为了解决to-space exhausted的问题,每次Mixed GC多回收一些,老年代空余的内存就会多一些,但是相应的可能会导致暂停时间增加 -
-XX:ConcGCThreads: 每次GC使用的CPU数量, 值不是固定。同样也是为了解决to-space exhausted的问题,使用线程多,则GC便会快一些,代价是用户的CPU时间会被占用。 -
-XX:G1ReservePercent=10%: 假天花板数量,作用是预留10%的空间不使用,留给并发周期过程中当可能会出现to-space exhausted的问题时候使用,防止出现to-space exhausted,预留过多可能会导致内存浪费 -
不要设置年轻代大小:不要使用
-Xmn,因为G1是通过需要扩展或缩小年轻代大小,如果设置了年轻代大小,则会导致G1无法使用暂停时间目标。
以上,只是 G1 的常见需要注意的参数,当然还可能有其他问题,比如大对象的分配,元空间大小等等, 总体来说,明白 GC 的回收过程,多多实践,大体就能通过 GC 的日志找出问题所在。

胖毛说,总结经典Java书籍读书笔记
参考文献:
Java Hotspot G1 GC的一些关键技术 -- 美团技术团队
请教G1算法的原理
深入理解G1的GC日志(一)
Garbage First Garbage Collector Tuning
HotSpot虚拟机垃圾收集优化指南--G1
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

