Spring IOC 源码解析(一),容器中的 BeanDefinition(XML 解析篇)
Spring 的核心就是 Bean,围绕这 Bean 这个概念衍生出来 IOC(控制反转),AOP(面向切面编程),该系列文章主要分析 IOC 源码;
IOC(控制反转):意思就是将我们平常编程中人为创建对象和管理对象的这一系列复杂关系,交给 Spring 容器去做
测试代码
@Test
public void t5() {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("classpath:spring_1.xml");
UserService userService = (UserService) applicationContext.getBean("userService");
userService.queryUser("long");
}
复制代码
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="userService" class="com.example.ana.service.impl.UserServiceImpl" />
</beans>
复制代码
找到 BeanDefinition 的加载入口

- 调用 setConfigLocations(String ...location) 将传入的 "classpath:spring_1.xml" 保存到 configLocations 中
- 然后调用 refresh() 后依次调用到 AbstractXmlApplicationContext 的 loadBeanDefinitions(beanFactory) 方法,方法参数的 BeanFactory 会在上一次调用中创建好,后续解析到的 BeanDefinition 就能够正确的放入该容器中
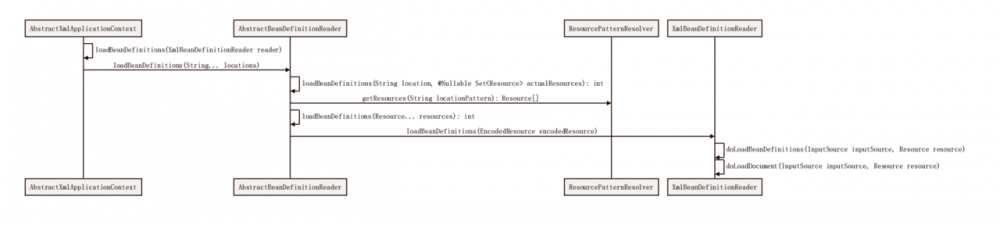
根据配置文件路径将其解析为 Resource 和 Document
-
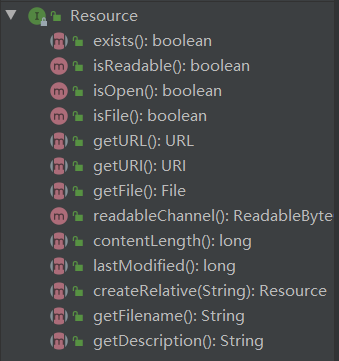
根据之前保存的 configLocations 通过 ResourcePatternResolver(ResourceLoader 的子类) 进行解析返回 Resource[],以为这里我们只有一个配置文件 spring_1.xml 所以返回数组只有一个值,Resource 代表一个资源,它描述了一个文件的相关信息
-
根据 Resource 获取其 InputStream,其实就是 resource.getFile().getInputstream(),然后根据 InputStream 创建 InputSource
-
然后调用 DefaultDocumentLoader 的 loadDocument(InputSource inputSource, EntityResolver entityResolver, ...) 方法
-
创建 DocumentBuilder
-
调用 parse(InputSource is)
-
最终调用 DomParser 的 parse(InputSource inputSource) 方法,将其解析为 Document
其实总结下来就一句话,根据 configLocations 对应的文件解析为 Resource,然后通过 Resource 获取到文件输入流,最后通过 DomParser 将输入流进行解析为 Document
Document 是文档的根节点,他的实现类,包含了 xml 或者 html 等文档各个节点和命名空间的数据,比如说它其中的 Element 的 node 属性就能包含 <bean id="xxx" class="xxx" /> 这样一个节点数据,能够获取到它的 id、class 等,通过这个 Document 的信息就能比较方便的创建 BeanDefinition 了
将 Document 解析为 BeanDefinition 并放入容器

- 首先创建 DefaultBeanDefinitionDocumentReader 通过它来读取 Document 将其解析为 BeanDefinition
- 创建 XmlReaderContext,用它来保存读取解析上下文的信息
- 创建一个 BeanDefinitionParserDelegate 委派器
- 然后通过 Document 获取其 Element,通过 Element 获取所有的 node(也是一种 Element) 结点进行遍历,如果发现是
http://www.springframework.org/schema/beans这样的命名空间,那么就 BeanDefinitionParserDelegate 这个委派器解析 Element 元素将其解析后返回 BeanDefinitionHolder,解析流程不复杂大体就是通过 Element 获取 bean 元素的 id,class,别名等信息来创建 BeanDefinitionHolder,new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray) - 调用
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry()); - 最后调用 getReaderContext().getRegistry().registerBeanDefinition(String beanName, BeanDefinition beanDefinition) 方法,实际上调用的 DefaultListableBeanFactory 的 registerBeanDefinition 方法,将其放入容器中
// 主要逻辑
BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);
if (existingDefinition != null) {
this.beanDefinitionMap.put(beanName, beanDefinition);
}
复制代码
- 然后循环第 4 步的后续节点,依次处理完,最后文档定义的 bean 等元素全部解析为 BeanDefinition 放入 BeanFactory 容器中了
总结
spring 首先将配置文件解析为 Resource,然后根据 Resouce 获取其输入流信息解析生成 Document 通过该 Document 获取到的 Element 包含了定义的所有节点信息,然后通过 Element 获取所有的 Bean 结点遍历依次解析,解析就是通过这些结点获取 bean 定义的 id、class、alias 等信息,根据这些信息来创建 BeanDefinition,最后将 BeanDefinition 放入 DefaultListableBeanFactory 的 BeanDefinitionMap 中同时保存一份 beanDefinitionNames
正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

