IDEA中Tomcat在控制台乱码问题及IDEA编码设置UTF-8的方法
1.首先要分清是tomcat日志编码,与idea的日志显示控制台编码
2.tomcat日志编码:cmd内 “cd /d tomcat根目录” “bin/catalina.bat run” 运行,"chcp65001"切换cmd为utf8,"chcp 936"切换cmd为gbk,确定tomcat日志编码,一般因为tomcat/conf/logging.properties
3.idea显示编码:windows默认用gbk所以idea显示默认为gbk编码,【一定】在 Help-- custom vm options 添加-Dfile.encoding=UTF-8,强制为utf8编码显示,不要自己改.vmoptions可能位置不对,idea会在用户目录复制一个
4.【切忌】自己改tomcat的logging.properties 为GBk 会导致调试时get/post参数乱码
总结
到此这篇关于IDEA中Tomcat在控制台乱码问题及IDEA编码设置UTF-8的文章就介绍到这了,更多相关idea tomcat 控制台乱码 编码UTF-8内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
时间:2020-07-09
IDEA 启动 Tomcat 项目输出乱码的解决方法
刚开始碰到的时候没调试成功又放下了,老系统放在 MyEclipse 下面跑,这两天 MyEclipse 和 Tomcat 老出问题,借着这个机会又试了试,成功了. 大部分调试方法来自这里,但是有微调. 在 tomcat Server 中设置 VM options , 值为 -Dfile.encoding=UTF-8,可惜没生效 注意: 刚开始我也是设成UTF-8,但设了一圈回来,Console 窗口里日志行的信息两个字是生效了,但日志行内容还是乱码,于是试着把这一步的设置改成 GBK,居然成功了
idea tomcat乱码问题的解决及相关设置的步骤
今天使用idea运行tomcat 项目时候出现乱码,上网搜了一下,分享给大家. 问题,在idea中出现乱码问题,以前没有的,好像在设置系统代码为utf8之后就出现了,于是尝试了一系列办法,希望这些办法对您有帮助. 先看一下乱码的样式. 设置办法 1.在tomcat Server中设置 VM options , 值为-Dfile.encoding=UTF-8 ,可惜没生效 2.在setting中的 File encodings 中设置编码格式,后来发现这是设置页面编码格式的,所以也没生效,不过遇到
解决IDEA 启动Tomcat控制台乱码问题
今天在Idea中用Tomcat跑一个Web项目,启动后,Tomcat日志在控制台打印出来都是乱码,如下图所示: 这个问题是Tomcat的编码问题引起的,解决该问题可以进行如下配置: -Dfile.encoding=UTF-8 如果还不行,就这样: 点击确定.重启TOMCAT进行调试,可以看到控制台中tomcat日志中的中文能正常显示了. 上面基本上应该不会出现乱码啦 如上述全部尝试还是乱码则需要修改配置文件 进入idea的安装目录, 进入bin目录下.找到idea.exe.vmoptions这个
IntelliJ IDEA 统一设置编码为utf-8编码的实现
问题一: File->Settings->Editor->File Encodings 问题二: File->Other Settings->Default Settings ->Editor->File Encodings 问题三: 将项目中的.idea文件夹中的encodings.xml文件中的编码格式改为uft-8 问题四: File->Settings->Build,Execution,Deployment -> Compiler -&g
ANSI,Unicode,BMP,UTF等编码概念实例讲解

一.前言 其实从开始写Java代码以来,我遇到过无数次乱码与转码问题,比如从文本文件读入到String出现乱码,Servlet中获取HTTP请求参数出现乱码,JDBC查询到的数据乱码等等,这些问题很常见,遇到的时候随手搜一下都可以顺利解决,所以没有深入的去了解. 直到前两天同学与我谈起一个Java源文件的编码问题(这问题在最后一个实例分析),从这个问题入手拉扯出了一连串的问题,然后我们一边查资料一边讨论,直到深夜,终于在一篇博客中找到了关键性线索,解决了所有的疑惑,以前没有理解的语句都能解释清楚
可以把编码转换成 gb2312编码lib.UTF8toGB2312.js
//Author: Unknow //把编码转换成 gb2312编码 function UrlEncode(str) { var i, c, ret="", strSpecial="!/"#$%&'()*+,/:;<=>?@[/]^`{|}~%"; for(i = 0; i < str.length; i++) { //alert(str.charCodeAt(i)); c = str.charAt(i); if(c
用Javascript实现UTF8编码转换成gb2312编码
复制代码 代码如下: //把编码转换成 gb2312编码 function UrlEncode(str) { var i, c, ret="", strSpecial="!/"#$%&'()*+,/:;<=>?@[/]^`{|}~%"; for(i = 0; i < str.length; i++) { //alert(str.charCodeAt(i)); c = str.charAt(i); if(c==&quo
php自动识别文字编码并转换为目标编码的方法
本文实例讲述了php自动识别文字编码并转换为目标编码的方法.分享给大家供大家参考.具体如下: 在PHP处理页面的时候,我们对于字符集的转换都是采用了iconv或者mb_convert等函数,但,这其实是有一个前提的.即我们事先得知道in和out是什么样的编码,我们才能进行正确的转换. 虽然大多数转换都是在gbk和utf-8之间转,但如果不知道转换对象的编码怎么办呢?谷歌出来这么一个函数safeEncoding,可以简单的识别UTF8和GBK的编码.这个函数在一定程度上识别的很准确,但是在一些比较
iOS 原生地图地理编码与反地理编码(详解)
当我们要在App实现功能:输入地名,编码为经纬度,实现导航功能. 那么,我需要用到原生地图中的地理编码功能,而在Core Location中主要包含了定位.地理编码(包括反编码)功能. 在文件中导入 #import <CoreLocation/CoreLocation.h> 地理编码: /** 地理编码 */ - (void)geocoder { CLGeocoder *geocoder=[[CLGeocoder alloc]init]; NSString *addressStr = @&qu
两种设置php载入页面时编码的方法
php载入页面时设置页面编码的两种方法 1:输出meta标签: 1.在php mvc的控制器里面或php页面echo '<meta http-equiv="content-type" content="text/html; charset=utf-8">'; 2.在php页面或html页面<meta http-equiv="content-type" content="text/html; charset=utf-8&
UUencode 编码,UU编码介绍、UUencode编码转换原理与算法
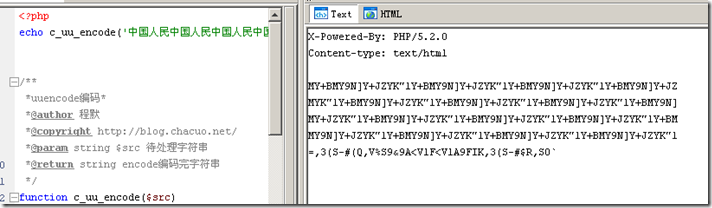
UUencode编码起先用在unix网络中,先是Unix系统下将二进制的资料借由uucp邮件系统传输的一个编码程式,也是一种二进制到文字的编码.不属于MIME编码中一员.它也是定义了用可打印字符表示二进制文字一种方法,并不是一种新的编码集合.主要解决,二进制字符在传输.存储中问题.它早期在电子邮件中使用较多,最近这些年来基本上被MIME 中Base64所取代了.E-mail中一般采用UU.MIME.BINHEX三种编码标准! 我想,了解下这种编码将二进制字符转换为可打印字符实现思路!对我们以后做
Base64 编码介绍、Base64编码转换原理与算法
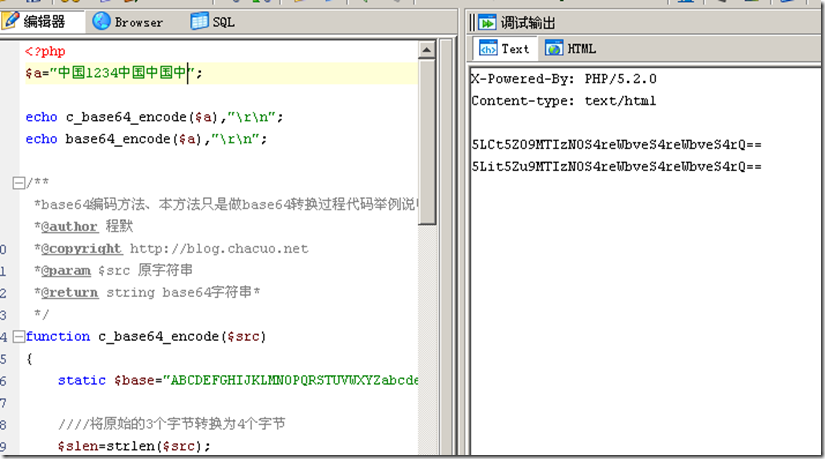
Base64编码,是我们程序开发中经常使用到的编码方法.它是一种基于用64个可打印字符来表示二进制数据的表示方法.它通常用作存储.传输一些二进制数据编码方法!也是MIME(多用途互联网邮件扩展,主要用作电子邮件标准)中一种可打印字符表示二进制数据的常见编码方法!它其实只是定义用可打印字符传输内容一种方法,并不会产生新的字符集!有时候,我们学习转换的思路后,我们其实也可以结合自己的实际需要,构造一些自己接口定义编码方式.好了,我们一起看看,它的转换思路吧! Base64实现转换原理 它是用64个可
浅析PHP中的字符串编码转换(自动识别原编码)
复制代码 代码如下: /** * 对数据进行编码转换 * @param array/string $data 数组 * @param string $output 转换后的编码 */function array_iconv($data,$output = 'utf-8') { $encode_arr = array('UTF-8','ASCII','GBK','GB2312','BIG5','JIS','eucjp-win','sjis-win','EUC-JP'); $enc
XXencode 编码,XX编码介绍、XXencode编码转换原理与算法
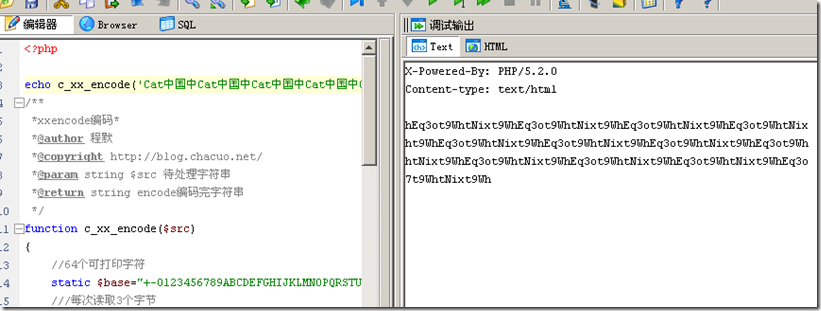
Xxencode编码,也是一个二进制字符转换为普通打印字符方法.跟UUencode编码原理方法很相似,唯独不同的是可打印字符不同.通个UUencode编码,我们知道它有个缺点就是,64个可打印字符中,有很多的特殊字符.而XXencode编码方法,对64个原字符有做规范.这里它有跟Base64类型了.都有指定可打印字符范围.及编号.Xxencode编码在上世纪后期,IBM大型机中得到很广泛的应用.现在逐渐被Base64编码转换方法所取代了. Xxencode编码原理 XXencode将输入文本以每
正文到此结束
- 本文标签: 调试 XML src IO java db https UI 实例 lib JavaScript 目录 windows ip HTML build Logging cmd tomcat 配置 App 总结 IOS IBM servlet 安装 时间 开发 文章 JDBC unix 邮件系统 cat 代码 解决方法 博客 乱码 PHP mail 互联网 IDE 参数 http id web eclipse 数据 谷歌 core 希望 XEN myeclipse js
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

