从0-1开发Java性能剖析工具

背 景
在这个应用 满天飞 的时代,作为一代宠儿,我们每个人都肩负着使命:保证我们应用的服务质量。服务质量包括:应用的可用性、可靠性、响应指标等。 本文的主题更多的是和系统的 响应指标相 关。
本文作者来自京东生态运营部-保险研发中心工作,从去年6.18开始,就开始连续负责保险系统的6.18、11.11大促的运筹准备工作,同时肩负着保证核心系统的服务质量的要责。
说到大促的准备工作,核心必然离不开整个系统的压测。每次压测都会耗费大量的时间和心血在系统调优上,以保证系统提供稳定、高速、可靠的服务。几次调优下来,金融的各种监控起到了非常棒的助力作用,包括主机监控、SGM监控等。过程中,可以实时的看到应用所在服务器的CPU、内存等硬核指标,同时也可以通过SGM轻松的看到秒级的应用响应情况,包括99及999指标等。一旦发现了比较慢的响应时,可以通过SGM的钻取功能轻松的定位到链路中真正耗时的部位。
但是有一点比较尴尬,SGM默认只支持比如JSF,HTTP等重要协议入口的方法性能监控,当然如果想监控其它方法,可以通过配置把想要监控的方法配置到SGM中意支持性能监控。但是问题来了,业务相当复杂,中间来回调用可能会涉及到成百上千的方法,这样都配置上去需要耗费相当的人力。然后还需要在完成监控之后把所有的方法配置再去掉,太繁琐了。
我们到底需要什么?
1 能够轻松的在生产或者预发环境引入类似JProfiler的CPU剖析能力
生在Java的世界,真的是幸运的,丰富完整的生态让我们解决任何问题基本都能够轻松应对。对于诊断工具也是非常丰富,比如说自带的jstat、jmap,商业化的工具JProfiler、开源的工具VisualVM。进入分布式时代更是有SkyWalking、Pinpoint等分布式调用链路跟踪引擎。
JProfiler、VisualVM都有比较强大的性能剖析能力。但很遗憾,商业化的并不方便引入系统中,同时并不能非常方便的引入到我们现有的生产或者预发,没有能够提供方便的接入能力,同时不太满足我们的定制化需求,稍候会说到。
2 支持包配置,可以轻松的对所有属于包内的类的方法调用都会自动进行监控
不同的业务线,肯定包名都是不一致的,不同的业务线使用可以根据自己的诉求进行包名的填加。以对不同的类的方法进行跟踪监控。
3 支持指定监控时机
业务系统随时在运行,我们不能随时都进行监控,我们需要具备在需要时打开监控,不需要的时候关闭监控。
4 支持指定监控入口
刚才说过,我们默认是支持直接指定包名的,这就可能带来一个问题,包内的所有方法入口都会被跟踪监控,这个在真正进行性能剖析的时候不是我们所期望的,这样必然会有相当一部分不是我们的数据会影响我们的判断,因为分析的场景下一般都是针对性比较强的,需要能够指定我们分析的入口,然后只有进入这个入口才会进行性能剖析数据的采样,避免不必要的采样对性能剖析的影响。
5 支持进行统计分析
数据落地后,对于源数据我们称之为Raw Data,对我们而言基本是没有任何价值的。只有统计后的结果才是对我们有意义的。比如,我们真正想看到的数据是这个样子的:入口方法总共耗费了多少时间,这么多时间,大部分的时间被耗费在被调用的哪个方法上了,这样的数据对我们才是有意义的。
技 术 储 备
俗话说:“难者不会,会者不难”,说难的人,说明对事物本身是不了解的,真正了解的人,必然不会觉得难。就像好多人现在逐渐的开始接触到区块链,都觉得这个东西有些晦涩,当逐渐的深入之后,会觉得真的没有那么难理解。
我相信大家对于任何的技术的学习,都会感同身受。“温故而知新”,大家对于这句话再熟悉不过了,对的,它出自论语。对于技术,大家一定会有一样的感觉,随着我们资历不断的提升,我们对以往技术的理解都会不一样,因为我们在不断的长大。
同样的,想做一个这样的工具,我们需要具备一定的知识储备,并且需要有一定深度的认识,不能浅尝则止。下面我们就具体的说说我们需要哪些技术储备。
1 Java
貌似是句费话。因为本身我们做的工具要和Java打交道,甚至是Java的底层字节码,所以你不仅需要会用Java编程,还要懂一些Java字节码的知识。
2 类加载机制
一个Java类文件,从源代码的诞生到最终在JVM中执行,需要经历好多的过程:
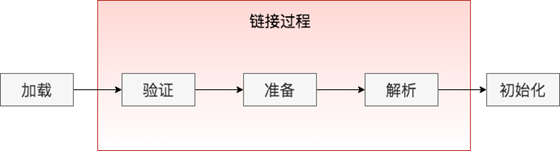
具体每个过程的具体职能,我们这里就不详细展开了,大家如果想要深入了解,建议看一下这里: https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-5.html 。我们这里重点说一下类的加载过程。
在 Java 中,所有的类都是通过类加载器 ClassLoader 完成类的加载的,主要有三种类加载器: Bootstrap ClassLoader、 ExtensionClassLoader 、 AppClassLoader :
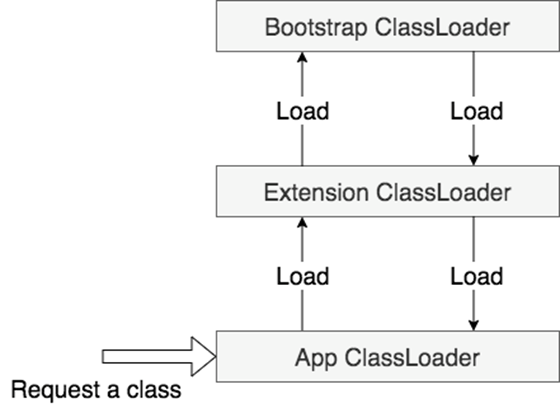
图中我们可以看到,当我们需要加载一个Class进入JVM的时候,会经过如下步骤:
-
J VM 会判断是否已经加载过这个 Class ,如果有则直接使用,如果没有则需要通过 ClassLoader 机制来加载 Class;
-
ClassLoader 机制会把加载请求交给 App ClassLoader , App 会直接委托给 Extension 来处理, Extension 会真委托给 Bootstrap 来处理;
-
Bootstrap 会通过 jre 的 classpath : jre/lib/rt.jar 搜索需要加载的类,如果 OK 就使用这个类,如果不 OK ,就再委托给 Extension 来加载;
-
Extension 会在 jre/lib/ext 下搜索对应的类,如果找到就用这个类,找不到就委托给 App 加载这个类,如果找到就用这个类,找不到就会抛出 ClassNotFoundException 的异常。
其实这个也就是大家熟知的双亲委派机制,即优先Parents加载,加载不到的,才会由自己加载。
3 AOP
说起AOP,大家应该并不陌生。类似于我们说OOP,它本身也是一种编程范式,学名叫“面向切面编程”。面向对象的特点是:继承、封装、多态。本质上是希望我们把功能按不同的关注点进行很好的隔离,让编程本身变的更加专注和简单。
比如,如果大家做业务编程,必然少不了记录操作日志、权限管理等。大家一般会选择怎样处理。简单的,大家会直接把相关的代码放入业务代码中。下面我们以权限为例,写些伪代码。

我们发现业务代码只有那么一行。功能性代码对业务切入太大了。不喜欢,我们需要调整一下:

是不是感觉好一点点啦,看的稍微干净一点了。但还是不太好,业务人员总是需要在业务代码的逻辑中加入功能代码,我们再调整一下:

这回啥感受,是不是感觉棒棒的,大家有没有发现,其实我们整个过程就是一个面向切面的优化过程。只是切面的位置在逐渐的调整。 以上这个场景大家发现有个特点,就是无论如何还是需要开发人员告知切面程序相关的业务信息,比如这里的 businessCode 。 其实,稍候我们说到的切面实现方式,由于本身功能和业务完全无关,所以开发人员可以完全无感知,不需要什么注解。
4 Java Agent
到这里开始有些小兴奋,因为马上就进行核心支撑能力的说明。其实早在JDK1.5的时候,Java就提供了一套Instrumentation的API,这套API提供了一套修改字 节码的能力。这就意味着我们不需要相关类的源代码,而直接对运行在JVM中的字节码进行修改,这种能力的魅力自然不用多费口舌啊,必然会给应用能力带来巨大的影响。
01 - 一个简单的Java Agent
实现Java Agent需要如下几个步骤:
-
必须实现接下这个方法: publicstaticvoidpremain(StringagentArgs, Instrumentation inst) 这个实际上是一个入口程序,类似于我们通常理解的 Java 中的 main 方法, JVM 初始化之后,会调用 premain 方法,这个方法可以有多个,会按照指定的顺序进行调用;
-
还有关键的一步,需要在 META-INF 中加入 MANIFIST.MF 文件,里面会包含一些 Agent 相关的元数据信息,比如: Premain-Class , Can-Redefine-Classes , Can-Retransform-Classes 等信息;
-
通过 -javaagent 参数指定我们自己做的 agent.jar 文件,启动 JVM ,所有的 transform 就会生效。
Java1.6后,有了增强的黑科技,我们不一定非要通过-javaagent指定,Java提供了一个API,我们可以在JVM运行时Attach到JVM上,然后加载agent.jar,再对类进行操作。只不过这个时候我们需要实现的不再是premain方法,而是agentmain方法。性能剖析就是通过JVM的Attach API进行的agent载入和处理。
02 - 字 节码修改工具
常用的字节码处理工具有:
-
ASM:它是一个直接操作字节码的工具,分析类信息,修改类信息
-
Javassist:分析、编辑、创建Java字节码的类库,这个工具相比ASM提供了多了一些抽象,更容易理解和使用,同时在类的修改等方面也提供了一些便捷的方法
-
ByteBuddy:对字节码的操作进行了高度抽象,提供了声明式API,对字节码的修改和操作同样的依赖于ASM,不仅仅如此,ByteBuddy提供了大量的API用来降低agent、instrument的使用成本。我们接下来编写的剖析工具正是基于这个工具。
编 码 实 录
我会按照设计思路逐一分析。工具上主要依赖ByteBuddy完成相关功能。
1 述求
-
能够在应用启动时完成Agent的安装由于环境的限制,我们不可能在jdk级别加入javaagent,我们需要在应用内部启动一个agent完成类的重新定义;
-
支持指定对哪些包中的类的方法进行统计记录我们不可能对所有的包都进行切入分析,成本太高了,而且对于java.lang、java.util层面的包,分析的意义也不大,我们也不可能去改这些类;
-
可以对进行剖析的方法入口进行指定由于采样数据落地成本比较高,我们不期望所有的方法都进行记录。我们只对指定的入口进行剖析和分析。也就是说,只有从特定入口进入的数据,我们才会统计落地;
-
能够指定采样间隔如果在量比较大的时候,如果我们每次都进行方法耗时的统计、链路的跟踪,势必会对整体的性能数据产生较大的影响,尤其是方法的耗时级别在毫秒级的时候;
-
能够指定采样阈值在接口被大量访问是,有可能我们只是关心那些突起的方法调用情况,所以不在毛刺区间的数据我们是没有必要保留的。只有那些大于指定阈值的数据我们才会记录落地;
2 应用内部安装Agent
-
依赖ByteBuddy相关Jar

-
安装 Agent
3 修改字节码,插入性能分析代码
我们剖析的核心就在这里,我们会通过ByteBuddy的Advise机制把我们的代码切入到所有需要剖析的方法中:

4 把Advice切入到字节码中

5 测试
接下来就可以测试了,调用包内类的相关方法的时候,就会看到你期望的结果了。【END】

作者: 皮亮
京东数科架构师,拥有多个行业系统架构经验,现负责保险系统的研发及架构相关工作。
▼ 往期优质文章 ▼
业务与系统的傲慢与偏见
京东金融云测平台方案揭秘
揭秘京东数科618背后的技术密码
面对黑客攻击,京东数科WAF建设这样做!
听说算法工程师80%的时间都在做特征工程?
京东第一位博士后出站 看他研究的是什么“黑科技”
AutoML系列 | 04-AutoML系统中的元知识迁移应用



关注技术说,我们只凭技术说话!

好内容值得被分享~
正文到此结束
- 本文标签: App 统计 ORM 工程师 pinpoint 测试 Oracle 黑客 时间 src 黑客攻击 专注 类加载器 定制 科技 UI 需求 lib FAQ 分布式 字节码 协议 tar 金融 Java类 文章 id JVM ssl 系统架构 代码 开源 http 希望 架构师 服务器 js 配置 API 开发 ECS MQ bus java https 安装 管理 参数 主机 AOP javaagent CST 云 质量 map Bootstrap HTML 运营 IO 本质 Agent classpath 京东 数据
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

