jvm之栈、堆
1. Java Virtual Machine
人群当中,一位叫java的小伙子正向周围一众人群细数着自己取得的荣耀与辉煌。就在此时,c老头和c++老头缓步走来,看着被众人围住的java,c老头感叹地对着身旁的c++说道:“原以为你就可以挑起我的梁子一直走下去的。”
c++笑着回应道:“江山代有才人出,这世界以后总会是90后甚至00后的天下!”
察觉到c和c++的java连忙走出人群,说道:“两位前辈谦虚了,这世界可还离不开两位前辈,我只不过是站在了两位前辈的肩上罢了。”
“你这小子可是解决了我们不少的问题啊,像指针、多继承、内存管理......那时,可是有很多程序员对我们抱怨颇深!”c++夸赞道。
“还有Java Virtual Machine,真的是一个不错的想法!”一旁的c补充道。
......
Java虚拟机,一直都是都是我们在学习Java的过程中反复提及的一个东西,那么JVM具体是怎样的呢?请看下图:
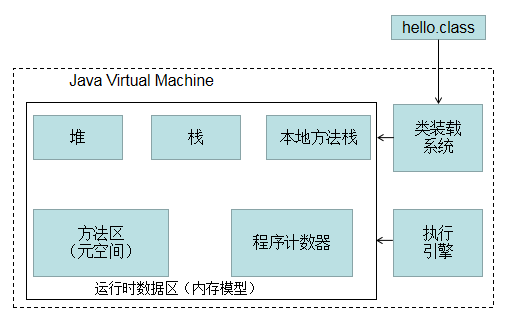
简单说来,JVM的工作就是通过类加载系统将字节码文件加载到内存当中去,加载到内存当中的数据,就从逻辑上形成了我们看到的图中的运行时数据区(内存模型),
随后执行引擎操作/调度内存模型中数据执行程序。
现在看到内存模型里面的东西,大家是否有些眼熟呢?现在回想起自己面试时,遇到的JVM面试题是不是全是关于内存模型里面的东西。比如:栈、堆、Eden、Survivor、GC等等。
2. 举个小栗子
public class Example{
public int add(){
int a = 3;
int b = 4;
int c = a + b;
return c;
}
public static void main(String[] args){
Example e1 = new Example();
e1.add();
//.......
}
//......
}
这个栗子是在干啥,不用多说吧!今天我们就要来慢慢地剥开它,以往剥开吃得太快就没有什么感觉了。
3. 栈
栈,全称为Java 虚拟机栈,线程私有,生命周期和线程一致。描述的是 Java 方法执行的内存模型:每个方法在执行时都会床创建一个栈帧(Stack Frame)用于存储 局部变量表 、 操作数栈 、 动态链接 、 方法出口 等信息。每一个方法从调用直至执行结束,就对应着一个栈帧从虚拟机栈中入栈到出栈的过程。
怎样解释上面的话呢?那就需要开始剥栗子了!刀来(大喝一声)!
当栗子开始执行时,由于只有一个main线程,因而JVM只需要为main线程分配好栈区的内存(话句话说如果有多个线程,自然就会有多个栈区,并且为各自线程私有)。OK! main继续执行,就会遇到main()方法,遇到之后呢!JVM又会在栈区当中再划出一个小块来存放main()方法执行过程的数据,这一小块区域也就是栈帧。main()方法执行过程中又有一个add()方法出现了,同样地,JVM又会再为add()分配一个栈帧,同时压入到栈区,以后再遇到其他方法也是如此。当然,方法在执行完成之后,便会弹出并释放内存,当线程中栈区的所有方法都返回之后,程序也就算是执行完毕了。
那么栈帧又是何许物业?咦,我刀呢?算了,手撕吧。
当我们扯开栈区,撕开栈帧,一不小心,局部变量表、操作数栈、动态链接、方法出口......哗啦啦地散落一地。
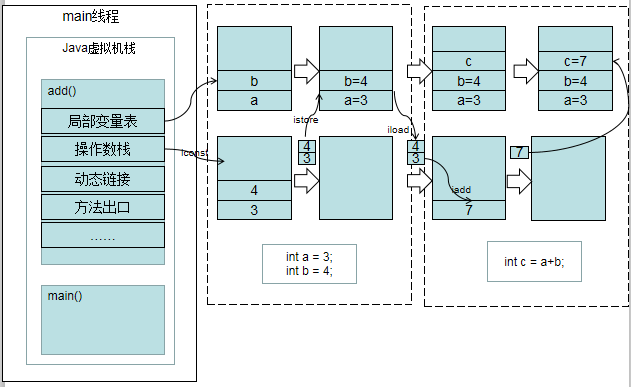
捡起add()栈帧的局部变量表和操作数栈就可以看到这样一个画面,在执行栗子中add()方法中的三行代码时,局部变量表和操作数栈的一个变化过程:首先,执行 int a = 3; 局部变量表中会分配出一个int区域,表示为a;同时iconst命令使得操作数栈中压入了常量3,然后再由istore命令将3弹出,赋值给局部变量表中a。同样, int b = 4; 这一行代码也是如此。然后, int c = a + b; 从右往左开始,先执行 a + b ,也就是iload命令从局部变量中取出a、b对应的值,再将iadd后的值push进操作数栈中,剩下的便是 int c = 7 的操作了。
通过上面的栗子,就很容易明白;局部变量表,顾名思义就是存放每个方法中的局部变量(即编译器可知的各种基本类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型)和 returnAddress 类型(指向了一条字节码指令的地址))所在处,如图中的a、b。操作数栈,也就是存放的就是方法当中的各种操作数的临时空间,又如栗子中的3、4。
动态链接:Class文件的常量池中存在有大量的符号引用,字节码中的方法调用指令就以指向常量池的引用作为参数,而将部分符号引用在运行期间转化为直接引用,这种转化即为 动态链接 。这个解释当中会涉及到许多概念,比如常量池、符号引用等,要想理解这些概念,就需要去了解class文件的结构,内容太多就不在这里详细描述了。
方法出口:简单来说,就是用于标记当前方法执行完成之后,应该返回到下一条指令执行位置。比如就上面的栗子而言,add()在执行完毕之后,就应该返回到e1.add()之后继续执行main()后面的代码。
4. 堆
对于绝大多数应用来说,这块区域是 JVM 所管理的内存中最大的一块。线程共享,主要是用于存放对象实例和数组。除此之外,堆区还涉及到JVM中一个非常重要的工作--GC(Garbage Collection)。
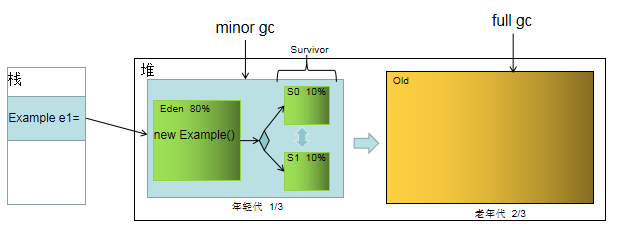
从图中就可以看出栈和堆之间的关系,对于new的对象,栈中局部变量表只会存放在堆中的地址引用,具体实例变量的空间分配都在堆中。
而堆中的内存区域又会划分为年轻代和老年代两部分,其中一般情况下年轻代占1/3内存,老年代占2/3内存;年轻代又被划分为Eden区(伊甸园区)和两个Survivor区(幸存区),各自分别占年轻代空间的8/10、/1/10、1/10。也就是说如果堆内存区域有600M,那么年轻代200M、老年代400M、Eden区160M、S0区20M、S1区20M。
这样划分区域的目的是什么呢?这个回答就关系到JVM的GC机制了。
首先,程序一开始,所有的实例对象都会生成在Eden区中,当Eden区满了的时候,这时就会触发minor gc,jvm使用gc roots的查找方式将 非 垃圾对象移动(复制算法)到S0区域中去,并且将Eden区中的其他对象视为垃圾对象,清空Eden区。
当实例对象再次充满Eden区时,又会触发minor gc;但是这次是将Eden区 和 S0区中的所有非垃圾对象移动到S1中,并清空Eden区和S0区;同样下次minor gc时,就是将Eden区和S1区中的非垃圾对象转移到S0中......当然,这个左手倒右手过程并不是无休止的。在反复minor gc的过程中,每个对象身上还有一个叫做分代年龄的属性,每次minor gc对象的分代年龄就会加1,当达到15(默认情况)时,这个对象就会被放到老年代中去,成为长期存在的对象。除此之外,还有一种情况,即是当从Eden区复制内容到Survivor区时,复制内容大小超过S0或S1任一区域一半大小,也会直接被放入到老年代中,所以老年代才会需要那么大的区域,不然怎么抗得住这些年轻人这样搞~~。
虽然老年代空间很大,但总会有满了的时候,这时麻烦的事情就出现了——full gc。在full gc时,jvm会先触发STW(Stop-The-World),也就是暂停其他所有的java进程,回收整个内存模型当中的内存资源,从而造成用户响应超时或者是系统无响应,这对于并发程序比较高的系统(比如秒杀活动)影响程度是极其之大的。
通过gc机制,我们就可以得出一个简单有效的JVM优化办法,那就是减少full gc的次数,如何减少呢?只需要调整老年代和年轻代的内存空间分配使得在minor gc的过程中尽可能的消除大部分的垃圾对象。比如这种java -Xmx3072 -Xms3072M -Xmn2048M -Xss1M
-Xmx3072M:设置JVM最大可用内存为3072M。
-Xms3072M:设置JVM初始内存为3072M。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2048M:设置年轻代大小为2G。增大年轻代后,将会减小年老代大小。不过此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss1M:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。
GC Roots: 在上面的gc过程中,我们还提到了JVM是如何判断垃圾对象的。简单地来说,就是从gc roots的根出发(即局部变量表中的引用对象),一路沿着引用关系找,凡是能够被找到的对象都是非垃圾对象,并且会被移动到下一个它应该去的区域中。剩下的对象,会在区域清空时,一同被清理掉而无须关心。
5. 小结
除了栈、堆之外,还有程序计数器、方法区(元空间)、本地方法栈,这些相对比较容易理解。
程序计数器:用来记录当前指令执行完成后下一条指令的位置,由执行引擎来完成相应的修改操作。
方法区(元空间):存放常量、静态变量、类信息等。
本地方法栈:与java虚拟机栈类似,不过存放的是native方法执行时的局部变量等数据存放位置。因为native方法一般不是由java语言编写的,常见的就是 .dll 文件当中的方法(由C/C++编写),比如 Thread 类中 start() 方法在运行时就会调用到一个 start0() 方法,查看源码时就会看到 private native void start0(); 这个方法就是一个本地方法。本地方法的作用就相当于是一个“接口”,用来连接java和其他语言的接口。
另外,对于new出来的对象,无论是在栈的局部变量表还是在方法区中的空间中,存放的都只是对象在 堆 中的地址(引用),具体的空间分配是在堆中。
公众号:良许Linux

有收获?希望老铁们来个三连击,给更多的人看到这篇文章
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

