集合在耗时程序中流遍历、迭代遍历的效率测量对比
测试环境
操作系统:WIN10
逻辑处理器:4核
运行内存:16G
测试程序:
CloudLogVo.java
import lombok.Data;
/**
* @className: CloudLogVo
* @description: 日志信息Vo
* @author: niaonao
**/
@Data
public class CloudLogVo {
private String level;
private String location;
private String message;
private String time;
public CloudLogVo(String level, String location, String message, String time) {
this.level = level;
this.location = location;
this.message = message;
this.time = time;
}
}
TraversalTimeConsume.java
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* @className: TraversalStatisticsConsumeTime
* @description: 耗时操作的测试类
* 此处使用 System.out.print() 模拟耗时操作;为什么耗时?点进去看内部实现,write()方法就很重量级
* @author: niaonao
**/
public class TraversalTimeConsume {
// 遍历测试集合
private static List<CloudLogVo> voList = null;
/**
* @description: 内部类:for-i 线程类
*/
class ForIThread extends Thread {
@Override
public void run() {
long start = System.currentTimeMillis();
for (int i = 0; i < voList.size(); i++) {
voList.get(i).getLevel();
System.out.print("");
}
long end = System.currentTimeMillis();
System.out.println(" for-i: " + (end - start));
}
}
/**
* @description: 内部类:foreach 线程类
*/
class ForeachThread extends Thread {
@Override
public void run() {
long start = System.currentTimeMillis();
for (CloudLogVo item : voList) {
item.getLevel();
System.out.print("");
}
long end = System.currentTimeMillis();
System.out.println(" foreach: " + (end - start));
}
}
/**
* @description: 内部类:stream 线程类
*/
class StreamThread extends Thread {
@Override
public void run() {
long start = System.currentTimeMillis();
voList.stream().forEach(item -> {
item.getLevel();
System.out.print("");
});
long end = System.currentTimeMillis();
System.out.println(" stream: " + (end - start));
}
}
/**
* @description: 内部类:parallelStream 线程类
*/
class ParallelStreamThread extends Thread {
@Override
public void run() {
long start = System.currentTimeMillis();
voList.parallelStream().forEach(item -> {
item.getLevel();
System.out.print("");
});
long end = System.currentTimeMillis();
System.out.println("parallelStream: " + (end - start));
}
}
/**
* @description: 初始化集合
*/
private static void initList(int quantity) {
List<CloudLogVo> cloudLogVoList = new ArrayList<>(quantity);
for (int i = 0; i < quantity; i++) {
String value = String.valueOf(i);
cloudLogVoList.add(new CloudLogVo(value, value, value, value));
}
voList = Collections.synchronizedList(cloudLogVoList);
}
public static void main(String[] args) throws InterruptedException {
// 遍历量级
int quantity = 1 * 1000 * 1000;
initList(quantity);
// 统计遍历耗时
TraversalTimeConsume.ForIThread forIThread = new TraversalTimeConsume().new ForIThread();
TraversalTimeConsume.ForeachThread foreachThread = new TraversalTimeConsume().new ForeachThread();
TraversalTimeConsume.StreamThread streamThread = new TraversalTimeConsume().new StreamThread();
TraversalTimeConsume.ParallelStreamThread parallelStreamThread = new TraversalTimeConsume().new ParallelStreamThread();
new Thread().sleep(2000);
forIThread.start();
foreachThread.start();
streamThread.start();
parallelStreamThread.start();
}
}
测试量级
测试数据量级如下
data: ['10万','30万','40万','50万','60万','70万','100万','150万','200万','300万']
测试结果
纵坐标为耗时/毫秒,横坐标为集合量级。数据量级越大,统计耗时数据误差越小。
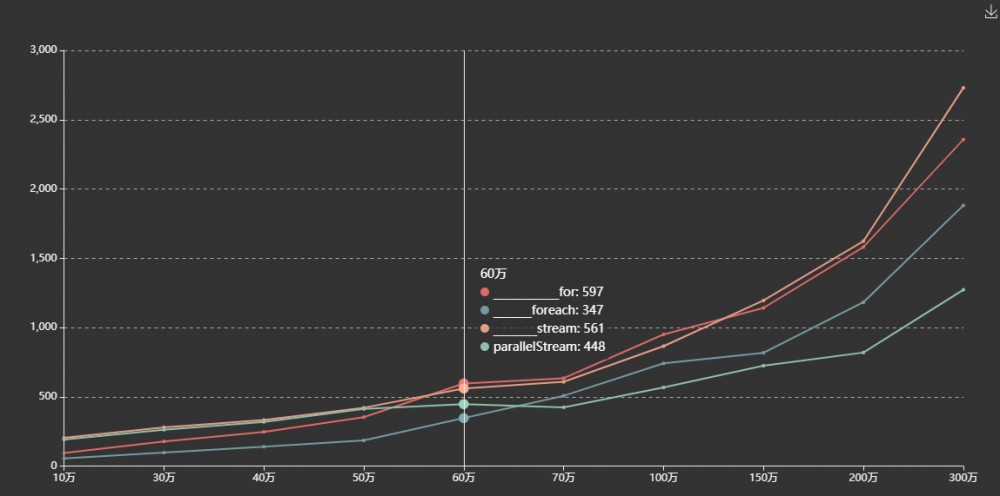
遍历结构体存在耗时程序时,综合来看:
增强for循环表现较好,foreach效率整体较高 在 65 万级数据量左右,parallelStream 效率会超过 foreach,随着数据量级增加,差距增大 stream 与 parallelStream 在 50 万数量级别之后,parallelStream 遍历效率更高,并且随着数据量增大,差距越大
附:非耗时程序集合遍历效率图
附图:非耗时遍历程序测试数据图
非耗时操作,stream 内部做了些不可描述的事情,相对普通 for 循环一定要多耗时的。普通 for 循环和增强 for 循环始终优于 stream,而 foreach 是更优的选择。
Stream API 借助 Lambda 表达式提高编程效率及程序可读性,提供了串行、并行来进行汇聚操作。优势在于可读性,简洁性和并行效率。
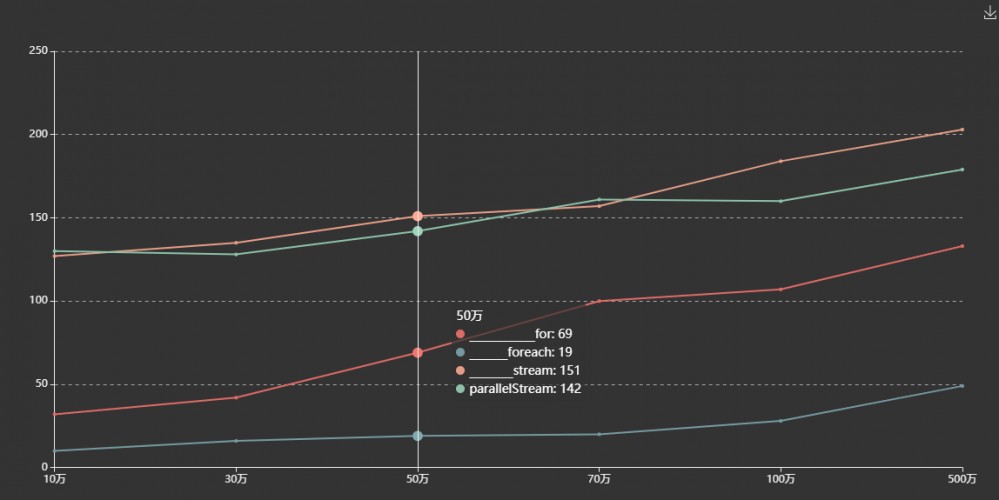
以上数据存在误差,仅做参考。
Power By niaonao, The End
正文到此结束
热门推荐










相关文章

近期评论
-
主要用的是AI
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

