Spring IOC 源码解析(二),容器中的 BeanDefinition(Annotation 解析篇)
Spring 源码解析篇都没有贴源码,贴了就太多太长了研究源码时候可能容易看晕,先大体理清楚源码设计编写的整体流程,流程中的几个阶段,然后在细看每一个阶段,当然这每一个阶段里面可能又是涉及到庞大的代码量,那么又需要将其分为多个阶段,这样一层一层的抽丝剥茧去看不会让自己一上来就产生强烈的挫败感(因为直接去 DEBUG Spring 源码会发现太深了)
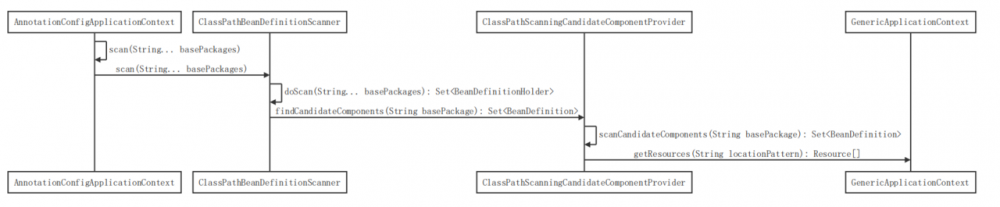
通过扫描包路径加载其下的 Class 文件为 Resource 数组
-
首先是调用构造器创建 AnnotatedBeanDefinitionReader 和 ClassPathBeanDefinitionScanner 他们分别是用于处理读取注解 BeanDefinition 和 classPath 路径下的 BeanDefinition 的
-
调用 ClassPathBeanDefinitionScanner 的 doScan 方法开始做扫描工作
-
在 ClassPathScanningCandidateComponentProvider 根据需要扫描的路径调用 GenericApplicationContext 的 getResources 方法,该方法会去递归扫描包路径下面所有的 Class 文件然后将其解析为 Resource 数组返回;就算一个类没有被 @Component 等注解修饰也会加载到 Resource 数组中
根据 Resource 数组创建 BeanDefinition 并放入容器中

-
首先创建 MetadataReader 用于读取 Resource 文件的元数据,主要包括 Resource、 ClassMetadata、AnnotationMetadata
-
然后判断是否在类上标注了 @Component 等注解,如果标注了进行下一步, 如果只是一个单纯的类则跳过
-
根据 MetadataReader 等信息创建 ScannedGenericBeanDefinition 放入 Set 中,ScannedGenericBeanDefinition 是一个早期 的 BeanDefinition 它目前包含了,类的元数据,Resource 文件,ClassName 等信息,Spring 称 之为 candidates(候选者)
-
遍历这些 candidates,根据其包含的信息做下一步操作;主要包含提取出 Scope 信息,创建 BeanName(一般是将类似 com.xxx.User 全称取类名称小写 beanName = user)
-
然后根据上面获取到的信息去创建一个 BeanDefinitionHolder ,该对象除了持有 BeanDefinition 外存有 beanName 和别名的相关信息
-
最后根据 BeanDefinitionHolder 获取到 BeanDefinition 放入到 DefaultListableBeanFactory 的 beanDefinitionMap 中,同时将其 beanName 对应的别名存放在 Map 中
总结
关于扫描包加载注解类的步骤为,首先根据定义路径递归遍历其下所有文件将其解析为 Resource 数组。然后遍历 Resource 数组根据其信息创建 ScannedGenericBeanDefinition 这样一个待完善的 BeanDefinition 集合。然后遍历这个集合解析出 Scope、创建 BeanName 解析出别名等信息据此创建出 BeanDefinition。最后将 BeanDefinition 放入容器中同时保存好它的对应别名信息
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

