基础篇:Object对象
1 Object的内存结构和指针压缩了解一下
//hotspot的oop.hpp文件中class oopDesc
class oopDesc {
friend class VMStructs;
private:
volatile markOop _mark; //对象部分
union _metadata { // klassOop 类元数据指针
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
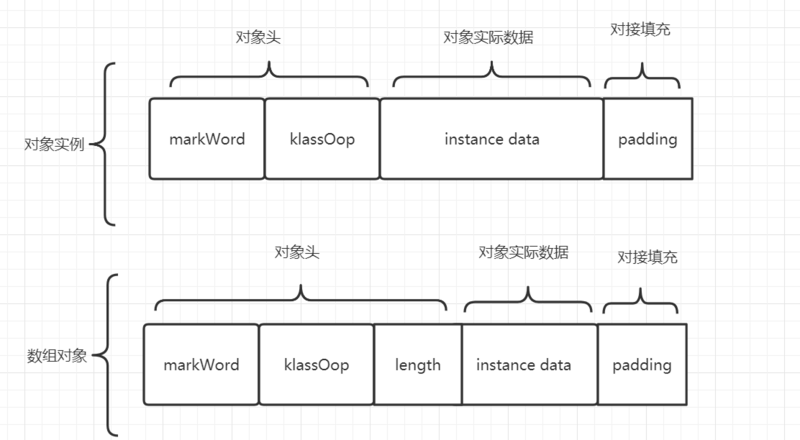
- Object的实例数据内存使用三部分组成的, 对象头 , 实际数据区域 、 内存对齐区
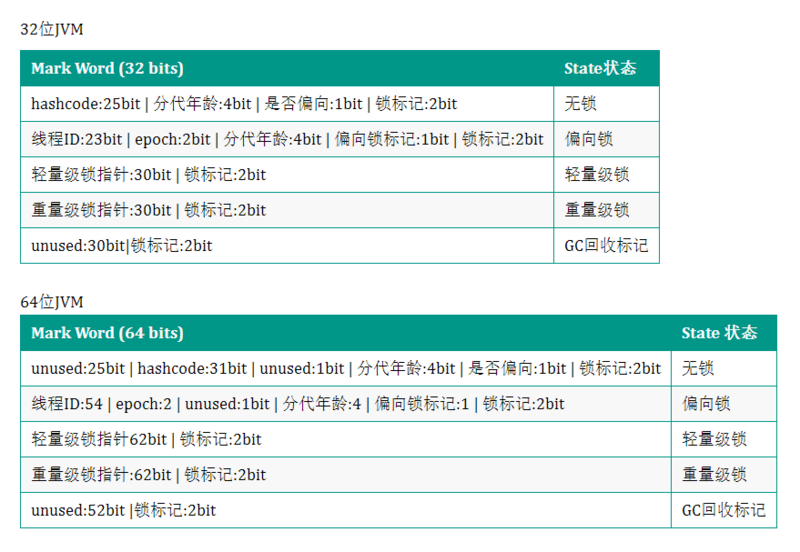
- 对象头布局如下:主要和锁,hashcode,垃圾回收有关;由于锁机制的内容篇幅过长,这里就不多解释了;和锁相关的markWord(markOop)内存布局如下
- 内存对齐 区是什么? HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说就是对象的大小必须是8字节的整数倍。因此当对象实例数据部分没有对齐的话,就需要通过对齐填充来补全。
-
内存对齐好处
- 有利于内存的管理
- 更快的CPU读取,CPU从内存获取数据,并不是一个个字节的读取,而是按CPU能处理的长度获取,如32位机,是4个字节的内存块;当只需其中两个字节时,则由内存处理器处理挑选。如果需要三个字节分布在两个不同内存块(四字节的内存块),则需要读取内存两次(如果是存在同一内存块只需一次读取)。而当对象按一定的规则合理对齐时,CPU就可以最少地请求内存,加快CPU的执行速度
-
指针压缩
- 在上图可以看到,在64位jvm里Object的MarkWord会比32位的大一倍;其实klassOop也占了64位(数组长度部分则是固定四字节)。指针的宽度增大,但是对于堆内存小于4G的,好像也用不到64位的指针。这可以优化吗?答案是就是指针压缩
- 指针压缩的原理是利用jvm植入压缩指令,进行编码、解码
-
哪些信息会被压缩
- 会被压缩对象:类属性、对象头信息、对象引用类型、对象数组类型
- 不被压缩对象:本地变量,堆栈元素,入参,返回值,NULL这些指针
- 指针压缩开启,klassOop大小可以由64bit变成32bit;对象的大小可以看看下面的具体对比: JVM - 剖析JAVA对象头OBJECT HEADER之指针压缩
public static void main(String[] args){ Object a = new Object(); // 16B 关闭压缩还是16B,需要是8B倍数;12B+填充的4B int[] arr = new int[10]; // 24B 关闭压缩则是16B } public class ObjectNum { //8B mark word //4B Klass Pointer 如果关闭压缩则占用8B //-XX:-UseCompressedClassPointers或-XX:-UseCompressedOops, int id; //4B String name; //4B 如果关闭压缩则占用8B byte b; //1B 实际内存可能会填充到4B Object o; //4B 如果关闭压缩则占用8B }- 为什么开启指针压缩时,堆内存最好不要超过32G,指针使用32个bit,为什么最大可使用内存不是4G而是32G
<br/>jvm要求对象起始位置对齐8字节的倍数,可以利用这点提升选址范围,理论上可以提升到`2^11 * 4G`。不过jvm将只是指针左移三位,因此`2^3 * 4G = 32G`。如果**大于32G**,指针压缩会失效。如果GC堆大小在 **4G以下**,直接砍掉高32位,避免了编码解码过程 - 启用指针压缩`-XX:+UseCompressedOops`(**默认开启**),禁止指针压缩:`-XX:-UseCompressedOops`
2 Object的几种基本方法
-
本地方法
-
private static native void registerNatives()将Object定义的本地方法和java程序链接起来。对JNI方面了解不多,就不多解释了 Object类中的registerNatives -
public final native Class<?> getClass()获取java的Class元数据 -
public native int hashCode()获取对象的哈希Code -
protected native Object clone() throws CloneNotSupportedException获得对象的克隆对象,浅复制 -
public final native void notify()唤醒等待对象锁waitSet队列中的一个线程 -
public final native void notifyAll()类似notify(),唤醒等待对象锁waitSet队列中的全部线程 -
public final native void wait(long timeout)释放对象锁,进入对象锁的waitSet队列
-
-
普通方法
public String toString() { return getClass().getName() + "@" + Integer.toHexString(hashCode());} public boolean equals(Object obj) { return (this == obj);} public final void wait(long timeout, int nanos) throws InterruptedException; //都是基于native void wait(long timeout)实现的 public final void wait() throws InterruptedException; wait(long timeout, int nanos)、wait() //jvm回收对象前,会特意调用此方法 protected void finalize() throws Throwable;
3 == 、 equals、Comparable.compareTo、Comparator.compara 四种比较方法
如不指定排序顺序,java里的默认排序顺序是升序的,从小到大
- ==, (A)对于基本类型之间的比较是值 (B)基本类型和封装类型比较也是值比较 (C)对于引用类型之间的比较则是内存地址
- equals(Object o), 在Object基本方法里可以看到
public boolean equals(Object obj) { return (this == obj);}是使用 == 去比较的。equals方法的好处是我们可以重写该方法 -
Comparable.compareTo 是接口Comparable里的抽象方法;如果对象实现该接口,可使用Collections.sort(List< T> col)进行排序。接下来看看源码怎么实现的
Collections.java //Collections.sort(List<T> list),调用的是List的sort方法 public static <T extends Comparable<? super T>> void sort(List<T> list) { list.sort(null); }List的sort 则调用了Arrays.sort
List.java default void sort(Comparator<? super E> c) { Object[] a = this.toArray(); Arrays.sort(a, (Comparator) c); ListIterator<E> i = this.listIterator(); for (Object e : a) { i.next(); i.set((E) e); } }如果Comparator c 为null,则是调用 Arrays.sort(Object[] a) ;最终调用LegacyMergeSort(归并排序)方法处理
Arrays.java public static <T> void sort(T[] a, Comparator<? super T> c) { if (c == null) { sort(a); } else { if (LegacyMergeSort.userRequested) legacyMergeSort(a, c); else TimSort.sort(a, 0, a.length, c, null, 0, 0); } }LegacyMergeSort方法里的一段代码;最终底层是使用 归并排序 和compareTo来排序
Arrays.java ...... if (length < INSERTIONSORT_THRESHOLD) { for (int i=low; i<high; i++) for (int j=i; j>low && ((Comparable) dest[j-1]).compareTo(dest[j])>0; j--) swap(dest, j, j-1); return; } -
Comparator也是一个接口,不过提供了更丰富的操作,需要实现
int compare(T o1, T o2)方法<br/>Comparator提供了常用的几个静态方法thenComparing、reversed、reverseOrder(操作对象需要实现Comparator或者Comparable);可配合List.sort、Stream.sorted、Collections.sort使用。
@Data @AllArgsConstructor static class Pair implements Comparator<Pair>, Comparable<Pair> { Integer one; Integer two; @Override public String toString() { return one + "-" + two; } @Override public int compareTo(Pair o) { return one.compareTo(o.one); } @Override public int compare(Pair o1, Pair o2) {return o1.compareTo(o2);} } public static void main(String[] args) { List<Pair> col = Arrays.asList( new Pair(4, 6), new Pair(4, 2),new Pair(1, 3)); col.sort(Comparator.reverseOrder()); col.stream().sorted(Comparator.comparing(Pair::getOne).thenComparing(Pair::getTwo)) .forEach(item -> System.out.println(item.toString()) ); }Collections.sort默认是升序排序的,可以看到reverseOrder将顺序反过来了; 用了thenComparing的col则是先判断Pair::getOne的大小,如果相等则判断Pair::getTwo大小来排序
result: 4-6 4-2 1-3 ---------------- 1-3 4-2 4-6
4 方法的重写和重载
- 方法的 重写 是指子类定义和父类方法的 名称、参数及顺序一致 的方法;需要注意的是,子类重写方法 修饰符 不能更加严格,就是说父类方法的修饰符是protected,子类不能使用private修饰而可用public,抛出的 异常 也不能比父类方法定义的更广
- 方法的 重载 则是同一个类中定义和已有方法的 名称一致而参数及顺序不一致 的方法,(返回值不能决定方法的重载)
- 重载的方法在编译时就可确定(编译时多态),而重写的方法需要在运行时确定(运行时多态,我们常说的多态)
<br/>多态的三个必要条件 1、有继承关系 2、子类重写父类方法 3、父类引用指向子类对象
5 构造方法是否可被重写
构造方法是每一个类独有的,并不能被子类继承,因为构造方法没有返回值,子类定义不了和父类的构造方法一样的方法。但是在同一个类中,构造方法可以重载
public class TestEquals {
int i;
public TestEquals() { i = 0; }
//构造方法重载
public TestEquals(int i) { this.i = i }
}
6 Object的equals和hashCode
equals是用来比较两个对象是否相等的,可以重写该方法来实现自定义的比较方法;而hashCode则是用来获取对象的哈希值,也可以重写该方法。当对象存储在Map时,是首先利用Object.hashCode判断是否映射在同一位置,若在同一映射位,则再使用equals比较两个对象是否相同。
7 equals一样,hashCode不一样有什么问题?
如果重写equals导致对象比较相同而hashCode不一样,是违反JDK规范的;而且当用HashMap存储时,可能会存在多个我们自定义认为相同的对象,这样会为我们代码逻辑埋下坑。
8 Object.wait和Thread.sheep
Object.wait是需要在synchronized修饰的代码内使用,会让出CPU,并放弃对对象锁的持有状态。而Thread.sleep则简单的挂起,让出CPU,没有释放任何锁资源
9 finalize方法的使用
- 如果对象重写了finalize方法,jvm会把当前对象注册到FinalizerThread的ReferenceQueue队列中。对象没有其他强引用被当垃圾回收时,jvm会判断ReferenceQueue存在该对象,则暂时不回收。之后FinalizerThread(独立于垃圾回收线程)从ReferenceQueue取出该对象,执行自定义的finalize方法,结束之后并从队列移除该对象,以便被下次垃圾回收
- finalize会造成对象延后回收,可能导致内存溢出,慎用
-
finally和finalize区别
- finallyjava关键字是用来处理异常的,和try搭配使用
- 如果在finally之前return,finally的代码块会执行吗? <br/>try内的continue,break,return都不能绕过finally代码块的执行,try结束之后finally是一定会被执行的
-
相似的关键字final
- final修饰类,该类不能被继承;修饰方法,方法不能被重写;修饰变量,变量不能指向新的值;修饰数组,数组引用不能指向新数组,但是数组元素可以更改
- 如果对象被final修饰,变量有哪几种声明赋值方式?
- fianl修饰普通变量:1、定义时声明 2、类内代码块声明 3、构造器声明
- fianl修饰静态变量:1、定义时声明 2、类内静态代码块声明
10 创建对象有哪几种方法
ObjectInputStream.readObject()
11 猜猜创建对象的数量
-
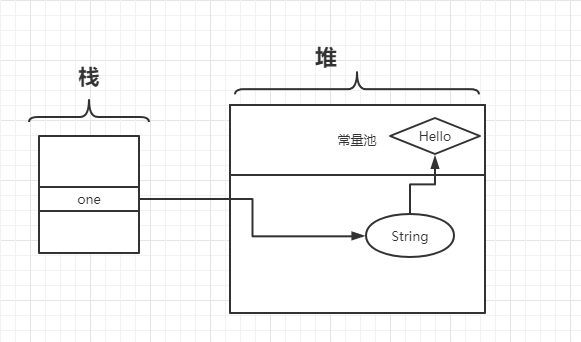
String one = new String("Hello");
<br/> 两个对象 和一个 栈变量 :一个栈变量one和一个new String()实例对象、一个"hello"字符串对象
- 题外话:string.intern();intern先判断常量池是否存相同字符串,存在则返回该引用;否则在常量池中记录堆中首次出现该字符串的引用,并返回该引用。
<br/>如果是先执行 String s = "hello" ; 相当于执行了intern();先在常量池创建"hello",并且将引用A存入常量池,返回给s。此时String("hello").intern()会返回常量池的引用A返回
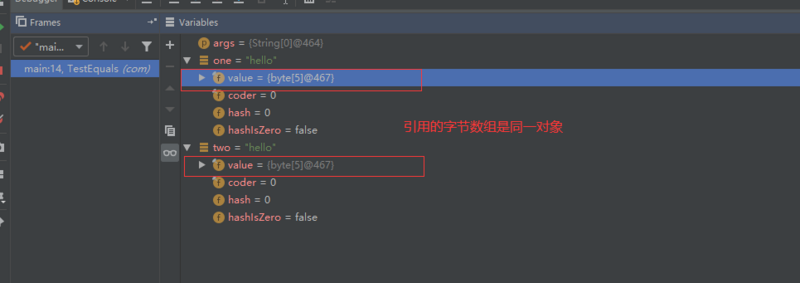
String one = "hello";
String two = new String("hello");
String three = one.intern();
System.out.println(two == one);
System.out.println(three == one);
result:
false // one虽然不等于two;但是它们具体的char[] value 还是指向同一块内存的
true // one 和 three 引用相同
12 对象拷贝问题
- 引用对象的 赋值复制 是复制的引用对象,
A a = new A(); A b = a;此时a和b指向同一块内存的对象 -
使用Object.clone()方法,如果字段是值类型(基本类型)则是复制该值,如果是引用类型则复制对象的引用而并非对象
@Getter static class A implements Cloneable{ private B b; private int index; public A(){ b = new B(); index = 1000; } public A clone()throws CloneNotSupportedException{ return (A)super.clone(); } } static class B{ } public static void main(String[] args) throws Exception{ A a = new A(); A copyA = a.clone(); System.out.println( a.getIndex() == copyA.getIndex() ); System.out.println( a.getB() == copyA.getB() ); }//返回结果都是true,引用类型只是复制了引用值 true true
-
深复制:重写clone方法时使用序列化复制,(注意需要实现Cloneable,Serializable)
public A clone() throws CloneNotSupportedException { try { ByteArrayOutputStream byteOut = new ByteArrayOutputStream(); ObjectOutputStream out = new ObjectOutputStream(byteOut); out.writeObject(this); ByteArrayInputStream byteIn = new ByteArrayInputStream(byteOut.toByteArray()); ObjectInputStream inputStream = new ObjectInputStream(byteIn); return (A) inputStream.readObject(); } catch (Exception e) { e.printStackTrace(); throw new CloneNotSupportedException(e.getLocalizedMessage()); } }
关注公众号,大家一起交流

正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

