从Linux内核理解JAVA的NIO
IO 可以简单分为 磁盘 IO 和 网络 IO , 磁盘 IO 相对于 网络 IO 速度会快一点,本文主要介绍 磁盘 IO , 网络 IO 下周写。
JAVA 对 NIO 抽象为 Channel , Channel 又可以分为 FileChannel (磁盘 io)和 SocketChannel (网络 io)。
如果你对 IO 的理解只是停留在 api 层面那是远远不够的,一定要了解 IO 在系统层面是怎么处理的,避免掉进一些不必要的坑。
本文内容:
- FileChannel 读写复制文件的用法。
- ByteBuffer 的介绍
- jvm 文件进程锁,FileLock
- HeapByteBuffer ,DirectByteBuffer 和 mmap 谁的速度更快
- 从
Linux 内核中的虚拟内存、系统调用、文件描述符、Inode、Page Cache、缺页异常讲述整个 IO 的过程 - jvm 堆外的 DirectByteBuffer 的内存怎么回收

本文计算机系统相关的图全部来自 《深入理解计算机系统》
对 Linux 的了解都是来自书上和查阅资料,本文内容主要是我自己的理解和代码验证,有的描述不一定准确,重在理解过程即可。
NIO
NIO 是 从 Java 1.4 开始引入的,被称之为 Non Blocking IO,也有称之为 New IO。
NIO 抽象为 Channel 是面向缓冲区的(操作的是一块数据),非阻塞 IO。
Channel 只负责传输,数据由 Buffer 负责存储。
Buffer
Buffer 中的 capacity 、 limit 和 position 属性是比较重要的,这些弄不明白,读写文件会遇到很多坑。
capacity 标识 Buffer 最大数据容量,相等于一个数组的长度。
limit 为一个指针,标识当前数组可操作的数据的最大索引。
position 表示为下一个读取数据时的索引

@Test
public void run1() {
// `DirectByteBuffer`
final ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024);
// `HeapByteBuffer`
final ByteBuffer allocate = ByteBuffer.allocate(1024);
}
复制代码
HeapByteBuffer 会分配在 Jvm堆内 ,受 JVM 堆大小的限制,创建速度快,但是读写速度慢。实际底层是一个字节数组。
DirectByteBuffer 会分配 Jvm 堆外 ,不受 JVM 堆大小的限制,创建速度慢,读写快。 DirectByteBuffer 内存在 Linux 中,属于进程的堆内。 DirectByteBuffer 受 jvm 参数 MaxDirectMemorySize 的影响。
设置 jvm 堆 100m,运行程序报错 Exception in thread "main" java.lang.OutOfMemoryError: Java heap space 。因为指定了 jvm 堆为 100m,然后一些 class 文件也会放在 堆中的,实际堆内存时不足 100m,当申请 100m 堆内存只能报错了。
public class BufferNio {
// -Xmx100m
public static void main(String[] args) throws InterruptedException {
// HeapByteBuffer 是 jvm 堆内,因为堆不足分配 100m(java 中的一些 class 也会占用堆),导致 oom
System.out.println("申请 100 m `HeapByteBuffer`");
Thread.sleep(5000);
ByteBuffer.allocate(100 * 1024 * 1024);
}
}
复制代码
设置 jvm 堆为 100m,MaxDirectMemorySize 为 1g,死循环创建 DirectByteBuffer ,打印 10 次 申请 directbuffer 成功 ,报错 Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory ,后面再说这个堆外的 DirectByteBuffer 怎么进行回收。
public class BufferNio {
// -Xmx100m -XX:MaxDirectMemorySize=1g
public static void main(String[] args) throws InterruptedException {
System.out.println("申请 100 m DirectByteBuffer");
final ArrayList<Object> objects = new ArrayList<>();
while (true) {
// DirectByteBuffer 不在 jvm 堆内,所以可以申请成功,但是不是无限制的,也有限制(MaxDirectMemorySize)
final ByteBuffer byteBuffer = ByteBuffer.allocateDirect(100 * 1024 * 1024);
objects.add(byteBuffer);
System.out.println("申请 directbuffer 成功");
System.out.println(ManagementFactory.getMemoryMXBean().getHeapMemoryUsage());
System.out.println(ManagementFactory.getMemoryMXBean().getNonHeapMemoryUsage());
}
}
}
复制代码
FileChannel
读文件
@Test
public void read() throws IOException {
final Path path = Paths.get(FILE_NAME);
// 创建一个 FileChannel,指定这个 channel 读写的权限
final FileChannel open = FileChannel.open(path, StandardOpenOption.READ);
// 创建一个和这个文件大小一样的 buffer,小文件可以这样,大文件,循环读
final ByteBuffer allocate = ByteBuffer.allocate((int) open.size());
open.read(allocate);
open.close();
// 切换为读模式,position=0
allocate.flip();
// 用 UTF-8 解码
final CharBuffer decode = StandardCharsets.UTF_8.decode(allocate);
System.out.println(decode.toString());
}
复制代码
写文件
@Test
public void write() throws IOException {
final Path path = Paths.get("demo" + FILE_NAME);
// 通道具有写权限,create 标识文件不存在的时候创建
final FileChannel open = FileChannel.open(path, StandardOpenOption.WRITE, StandardOpenOption.CREATE);
final ByteBuffer allocate = ByteBuffer.allocate(1024);
allocate.put("张攀钦aaaaa-1111111".getBytes(StandardCharsets.UTF_8));
// 切换写模式,position=0
allocate.flip();
open.write(allocate);
open.close();
}
复制代码
复制文件
@Test
public void copy() throws IOException {
final Path srcPath = Paths.get(FILE_NAME);
final Path destPath = Paths.get("demo" + FILE_NAME);
final FileChannel srcChannel = FileChannel.open(srcPath, StandardOpenOption.READ);
final FileChannel destChannel = FileChannel.open(destPath, StandardOpenOption.WRITE, StandardOpenOption.CREATE);
// transferTo 实现类中,用的是一个 8M MappedByteBuffer 做数据的 copy ,但是这个方法只能 copy 文件最大字节数为 Integer.MAX
srcChannel.transferTo(0, srcChannel.size(), destChannel);
destChannel.close();
srcChannel.close();
}
复制代码
FileLock
FileLcok 是 jvm 进程文件锁,在多个 jvm 进程间生效,进程享有文件的读写权限,有共享锁 和 独占锁。
同一个进程不能锁同一个文件的重复区域,不重复是可以锁的。
同一个进程中第一个线程锁文件的 (0,2),同时另一个线程锁(1,2),文件锁的区域有重复,程序会报错。
一个进程锁(0,2),另一个进程锁(1,2)这是可以的,因为 FileLock 是 JVM 进程锁。
运行下面程序两次,打印结果为
第一个程序顺利打印
获取到锁0-3,代码没有被阻塞 获取到锁4-7,代码没有被阻塞 复制代码
第二个程序打印
获取到锁4-7,代码没有被阻塞 获取到锁0-3,代码没有被阻塞 复制代码
第一个程序运行的时候, file_lock.txt 的 0-2 位置被锁住了,第一个程序持有锁 10 s,第二个程序运行的时候,会在这里阻塞等待 FileLock ,直到第一个程序释放了锁。
public class FileLock {
public static void main(String[] args) throws IOException, InterruptedException {
final Path path = Paths.get("file_lock.txt");
final FileChannel open = FileChannel.open(path, StandardOpenOption.WRITE, StandardOpenOption.READ);
final CountDownLatch countDownLatch = new CountDownLatch(2);
new Thread(() -> {
try (final java.nio.channels.FileLock lock = open.lock(0, 3, false)) {
System.out.println("获取到锁0-3,代码没有被阻塞");
Thread.sleep(10000);
final ByteBuffer wrap = ByteBuffer.wrap("aaa".getBytes());
open.position(0);
open.write(wrap);
Thread.sleep(10000);
} catch (IOException | InterruptedException e) {
e.printStackTrace();
} finally {
countDownLatch.countDown();
}
}).start();
Thread.sleep(1000);
new Thread(() -> {
try (final java.nio.channels.FileLock lock = open.lock(4, 3, false)) {
System.out.println("获取到锁4-7,代码没有被阻塞");
final ByteBuffer wrap = ByteBuffer.wrap("bbb".getBytes());
open.position(4);
open.write(wrap);
} catch (IOException e) {
e.printStackTrace();
} finally {
countDownLatch.countDown();
}
}).start();
countDownLatch.await();
open.close();
}
}
复制代码
当将上面的程序第二个线程改为 java.nio.channels.FileLock lock = open.lock(1, 3, false) ,因为同一个进程不允许锁文件的重复区域,程序会报错。
Exception in thread "Thread-1" java.nio.channels.OverlappingFileLockException
HeapByteBuffer 和 DirectByteBuffer 谁的读写效率高?
FileChannel 的实现类 FileChannelImpl ,当读写 ByteBuffer 会判断是否是 DirectBuffer ,不是的话,会创建一个 DirectBuffer ,将原来的的 Buffer 数据 copy 到 DirectBuffer 中使用。所以读写效率上来说,DirectByteBuffer 读写更快。但是 DirectByteBuffer 创建相对来说耗时。
尽管 DirectByteBuffer 是堆外,但是当堆外内存占用达到 -XX:MaxDirectMemorySize 的时候,也会触发 FullGC ,如果堆外没有办法回收内存,就会抛出 OOM。
// 下面这个程序会一直执行下去,但是会触发 FullGC,来回收掉堆外的直接内存
public class BufferNio {
// -Xmx100m -XX:MaxDirectMemorySize=1g
public static void main(String[] args) throws InterruptedException {
System.out.println("申请 100 m `HeapByteBuffer`");
while (true) {
// 当前对象没有被引用,GC root 也就到达不了 DirectByteBuffer
ByteBuffer.allocateDirect(100 * 1024 * 1024);
System.out.println("申请 directbuffer 成功");
}
}
}
复制代码
死循环创建的 DirectByteBuffer 没有 GC ROOT 到达,对象会被回收掉,回收掉的时候,也只是回收掉堆内啊,堆外的回收怎么做到的呢?
从 DirectByteBuffer 源码着手,可以看到它有一个成员变量 private final Cleaner cleaner; ,当触发 FullGC 的时候,因为 cleaner 没有 gc root 可达,导致 cleaner 会被回收,回收的时候会触发 Cleaner.clean (在 Reference.tryHandlePending 触发)方法的调用,thunk 就是 DirectByteBuffer.Deallocator 的示例,这个 run 方法中,调用了 Unsafe.freeMemory 来释放掉了堆外内存。
public class Cleaner extends PhantomReference<Object> {
private final Runnable thunk;
public void clean() {
if (remove(this)) {
try {
this.thunk.run();
} catch (final Throwable var2) {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
if (System.err != null) {
(new Error("Cleaner terminated abnormally", var2)).printStackTrace();
}
System.exit(1);
return null;
}
});
}
}
}
}
复制代码
内存映射
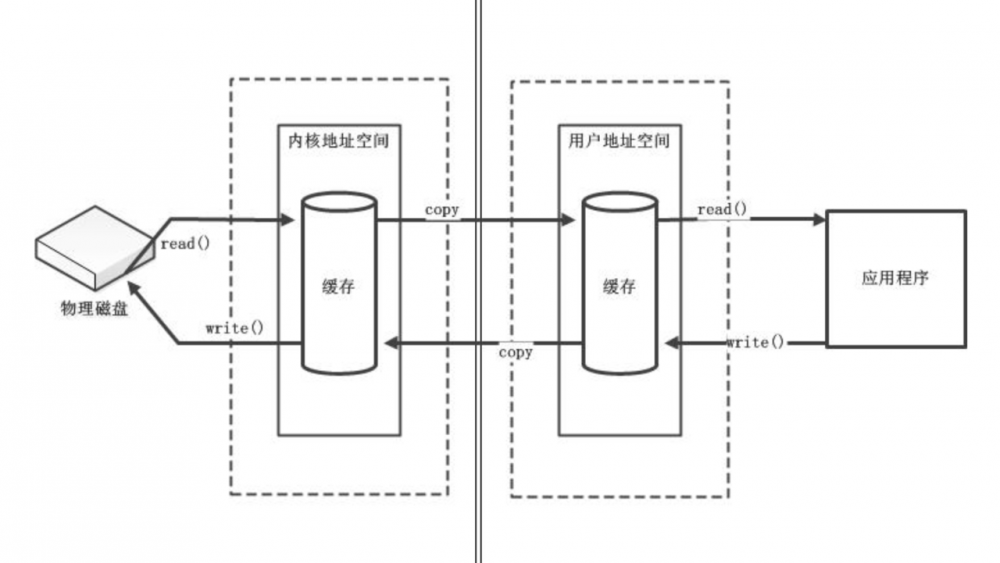
当应用程序读文件的时候,数据需要从先从磁盘读取到内核空间(第一次读写,没有 page cache 缓存数据),在从内核空间 copy 到用户空间,这样应用程序才能使用读到的数据。当一个文件的全部数据都在内核的 Page Cache 上时,就不用再从磁盘读了,直接从内核空间 copy 到用户空间去了。
应用程序对一个文件写数据时,先将要写的数据 copy 到内核 的 page cache,然后调用 fsync 将数据从内核落盘到文件上(只要调用返回成功,数据就不会丢失)。或者不调用 fsync 落盘,应用程序的数据只要写入到 内核的 pagecache 上,写入操作就算完成了,数据的落盘交由 内核 的 Io 调度程序在适当的时机来落盘(突然断电会丢数据,MySQL 这样的程序都是自己维护数据的落盘的)。
我们可以看到数据的读写总会经过从用户空间与内核空间的 copy ,如果能把这个 copy 去掉,效率就会高很多,这就是 mmap (内存映射)。将用户空间和内核空间的内存指向同一块物理内存。 内存映射 英文为 Memory Mapping ,缩写 mmap 。对应系统调用 mmap
这样在用户空间读写数据,实际操作的也是内核空间的,减少了数据的 copy 。

怎么实现的呢,简单来说就是 linux 中进程的地址是虚拟地址,cpu 会将虚拟地址映射到物理内存的物理地址上。mmap 实际是将用户进程的某块虚拟地址与内核空间的某块虚拟地址映射到同一块物理内存上,已达到减少数据的 copy 。
用户程序调用系统调用 mmap 之后的数据的读写都不需要调用系统调用 read 和 write 了。
虚拟内存与物理内存的映射
计算机的主存可以看做是由 M 个连续字节组成的数组,每个字节都有一个唯一 物理地址 ( Physical Address )。
Cpu 使用的 虚拟寻址 ( VA , Virtual Address ) 来查找物理地址。
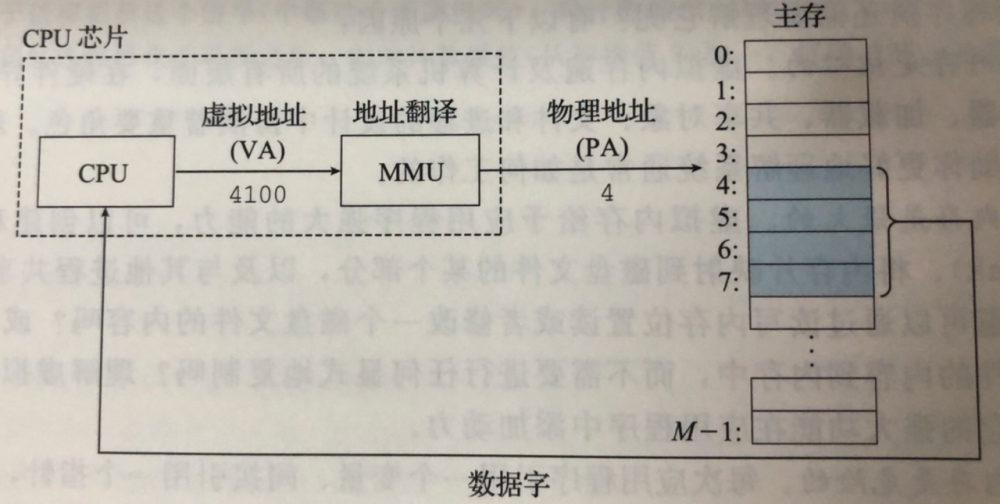
CPU 会将进程使用的 虚拟地址 通过 CPU 上的硬件 内存管理单元 ( Memory Management Unit MMU ) 的进行地址翻译找到物理主存中的物理地址,从而获取数据。
当进程加载之后,系统会为进程分配一个 虚拟地址空间 ,当虚拟地址空间中的某个 虚拟地址 被使用的时候,就会将其先映射到主存上的 物理地址 。
当多个进程需要共享数据的时候,只需要将其虚拟地址空间中的某些虚拟地址映射相同的物理地址即可。
通常我们操作数据的时候,不会一个字节一个字节的操作,这样效率太低,通常都是连续访问某些字节。所以在内存管理的时候,将内存空间分割为页来管理,物理内存中有 物理页 ( Physical Page ),虚拟内存中有 Virtual Page 来管理。通常页的大小为 4KB。
系统通过 MMU 和 页表(Page Table) 来管理 虚拟页 和 物理也 的对应关系,页表就是页表条目( Page Table Entry,PTE )的数组

PTE 的有效为1时,标识数据在内存中,标识为 0 时,标识在磁盘上。
当访问的虚拟地址对应的数据不再物理内存上时,会有两种情况处理:
1、在内存够用的时候,会直接将虚拟页对应在磁盘上的数据加载到物理内存上,
2、当内存不够用的时候,就会触发 swap,会根据 LRU 将最近使用频率比较低的虚拟页对应物理也淘汰掉,写入到磁盘中去,淘汰掉一部分物理内存中的数据,然后对对应的虚拟页设置为 0,然后将磁盘上的数据再加载到内存中去。
进程的虚拟内存
Linux 会为每个进程分配一个单独的虚拟内存地址,

当我们的程序运行的时候,不是整个程序的代码文件一次性全部加载到内存中去,而是执行懒加载。
机械硬盘使用扇区来管理磁盘,磁盘控制器会通过块管理磁盘,系统通过 Page Cache 与磁盘控制器打交道。 一个块包含多个扇区,一个页也包含多个块。 磁盘上会有一个文件对应一个 Inode,Innode 记录文件的元数据及数据所在位置。 当系统启动的时候,这些 Inode 数据会被加载到主存中去。不过系统中的 Inode 还记录他们对应的物理内存中的位置(实际就是对应 Page Cache),有的 Inode 对应的数据没有加载到内存中,Inode 就不会记录其对应的内存地址。 程序执行之前会初始化其虚拟内存,虚拟内存会记录代码对应哪些 Innode。 复制代码
当执行程序的时候,系统会初始化当前程序的虚拟内存,然后运行 main 函数,当发现执行代码时,有的代码没有加载到内存,就会触发缺页异常,将根据虚拟页找到对应的 Innoe ,然后将磁盘中需要的数据加载到内存中,然后将虚拟页标记为已加载到内存,下次访问直接从内存中访问。
##Java 中的 mmap
看源码我们发现 open.map 返回的也是 DirectByteBuffer ,只是这个方法返回的 DirectByteBuffer 使用了不同的构造方法,它绑定了一个 fd 。当我们读写数据的时候是不会触发系统调用 read 和 write 的,也就是内存映射的好处。
public class MMapDemo {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
final URL resource = MMapDemo.class.getClassLoader().getResource("demo.txt");
final Path path = Paths.get(resource.toURI());
final FileChannel open = FileChannel.open(path, StandardOpenOption.READ);
// 发起系统调用 mmap
final MappedByteBuffer map = open.map(FileChannel.MapMode.READ_ONLY, 0, open.size());
// 读取数据时,不会再出发调用 read,直接从自己的虚拟内存中即可拿数据
final CharBuffer decode = StandardCharsets.UTF_8.decode(map);
System.out.println(decode.toString());
open.close();
Thread.sleep(100000);
}
}
复制代码
尽管下面这个也是 DirectByteBuffer ,但是它和 mmap 不同的是,他没有绑定 fd,读写数据的时候还是要经过从用户空间到内核空间的 copy ,也会发生系统调用,效率相对 mmap 低。
public class MMapDemo {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException {
final URL resource = MMapDemo.class.getClassLoader().getResource("demo.txt");
final Path path = Paths.get(resource.toURI());
final FileChannel open = FileChannel.open(path, StandardOpenOption.READ);
// 这个 DirectByteBuffer 使用的构造不一样,它会走系统调用 read
final ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024);
final int read = open.read(byteBuffer);
byteBuffer.flip();
System.out.println(StandardCharsets.UTF_8.decode(byteBuffer).toString());
Thread.sleep(100000);
}
}
复制代码
追踪代码的系统调用,在 linux 下使用 strace
#!/bin/bash rm -fr /nio/out.* cd /nio/target/classes strace -ff -o /nio/out java com.fly.blog.nio.MMapDemo 复制代码
数据读写速度上 mmap 大于 ByteBuffer.allocateDirect 大于 ByteBuffer.allocate 。
本文由 张攀钦的博客 www.mflyyou.cn/ 创作。 可自由转载、引用,但需署名作者且注明文章出处。
如转载至微信公众号,请在文末添加作者公众号二维码。微信公众号名称:Mflyyou
正文到此结束
- 本文标签: tab swap NSA list strace cache 索引 linux 源码 tar 数据 App 博客 ORM id 翻译 UI CTO http bean mmap ssl https map 空间 src Action 物理内存 缓存 root ip sql 代码 final 微信公众号 虚拟内存 CountDownLatch java mina cat API 锁 文章 MQ 构造方法 rmi db 进程 管理 参数 1111 IO JVM node 线程 大数据 二维码 ACE NIO ArrayList mysql
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

