微服务和事件驱动
最近一直着迷于“事件”这个领域,在 《重新认识事件驱动架构》 一文中,我重新认识了“事件”本身的含义,以及常见的事件驱动的范式;然后在 《微服务如何对齐业务架构》 中我们又从业务架构角度,学习了“领域事件”和领域服务在微服务架构和实现中的巨大价值; 本文继续探讨的疑问是, 事件溯源(Event Sourcing) 是事件驱动架构的必由之路?实现一个事件溯源架构困难点在哪里?能不能给一个真实的客户案例?
- 1 -
事件驱动和 FaaS/无服务器微服务
云原生世界里,微服务架构已经是一个事实标准,微服务的出现满足了研发团队初期快速开发诉求,同时也可以满足中后期随着业务扩大,不断膨胀的用户规模;而 AWS 的函数计算 Lambda 再一次使得大家开始重视无服务器架构的微服务,FaaS 或无服务器计算,是云服务赋能开发人员的高级形式,从底层资源(虚机,容器)直接提升到应用接口:
-
真正的按需: 函数计算做到了按接口请求计费的模式,用户不用为系统等待空耗付费
-
面向应用: 不需要依赖开发人员引入的服务框架实现微服务,把“服务的服务”需求托管给云服务,开发人员只需要关注业务逻辑;而服务所需要的弹性扩展、监控、日志、编排以及授权认证等等都沉淀到平台层来进行支撑;
函数计算和事件驱动架构是密切联系在一起的,所以,考察市面上提供函数计算的大厂,首先要调研的就是支持的 “事件源” 范围是否足够广泛。那基于事件驱动的函数计算微服务,有哪些应用场景呢?
由于比较熟悉 AWS,故从 AWS 角度我们来看看事件驱动的无服务器架构微服务可以实现哪些典型应用场景;大家也可以去 AWS Serverless Application Repository 页面,相当于无服务器的一个 应用市场 来发布和重用无服务器解决方案。
- 1.1 -
媒体(图片/视频)处理
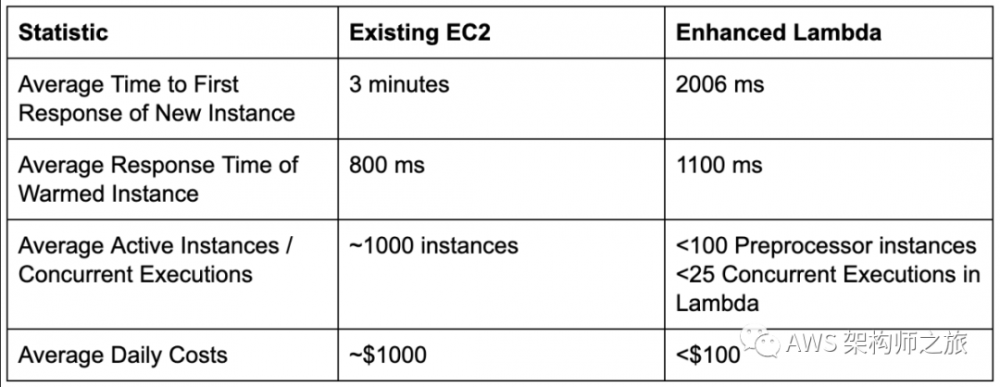
如今图片和视频处理是很多应用的必备功能,典型流媒体公司通常都是开源方案加自研扩展跑在虚机或容器中,比如 Netflix 的动态图片处理程序 Dynimo 平均所需要的 EC2 数量在 1000台左右 ,自2020年初开始,技术团队开始使用 Lambda 函数重构并部署到生产环境,团队利用高于平时 15倍的用户请求进行压测,结果生产环境的 Lambda 函数承受住了平时 20倍的请求量,从而验证了新的架构不需要像以前一样预热大量虚机,Lambda 提供了足够的大规模弹性扩展能力。
大家感兴趣可以查看视频和图片处理的无服务器架构源代码和直接试用, Media2Cloud(https://aws.amazon.com/cn/solutions/implementations/media2cloud/)和无服务器图像处理程序(https://www.amazonaws.cn/solutions/serverless-image-handler/)
该模式中,可以集成高级的机器学习 SaaS 服务,比如图片识别,语言翻译,文本转语音,视频分析,个性化等能力,快速构建高效智能的媒体应用。
- 1.2 -
数据格式处理
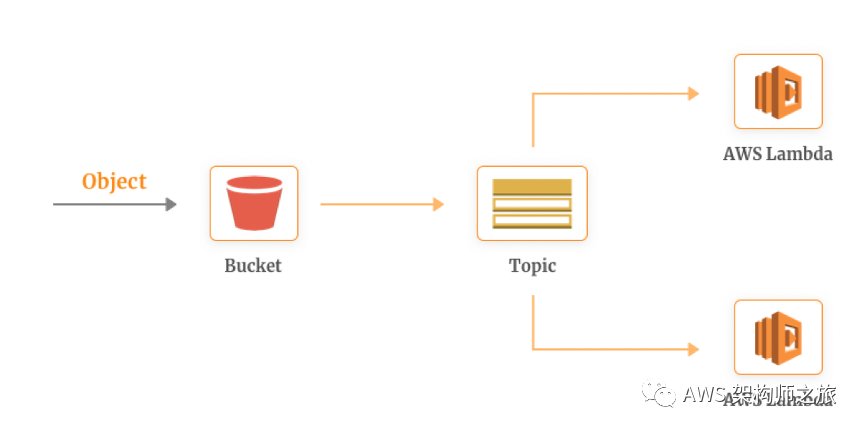
很多时候当单个数据对象需要不同格式以便于后续应用处理时,函数计算和消息中间件配合,可以构建一个通用的事件驱动的数据并行处理架构。如下图,SNS 作为消息发布订阅的中间件,解耦数据对象事件(新对象创建/修改)和数据对象处理(函数计算),快速构建和自动扩展,没有太多的维护麻烦。
- 1.3 -
实时流处理
实时处理数据并响应数据对现代数字化业务至关重要,典型场景有:
-
行为数据分析:用户点击流分析等
-
业务事件流:支付事务实时分析
-
日志流
-
IoT 场景
-
数据库 Change Data Capture(CDC)
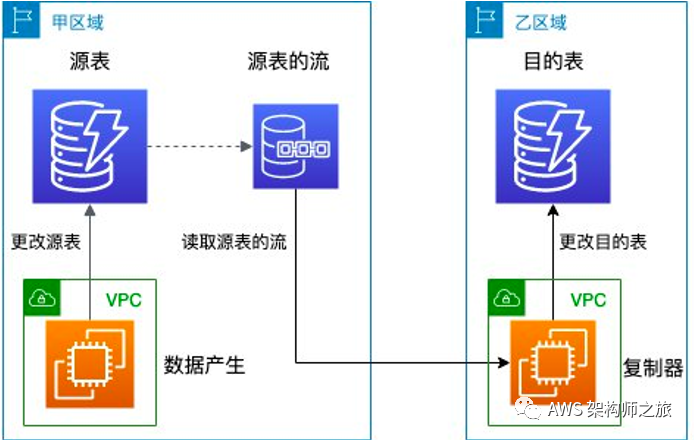
Amazon DynamoDB 托管的全球表(Global Table)以及基于数据变更事件流自定义实现的数据跨区域同步方案是一个典型的例子,具体实现可以参考最新的博客 《基于 Amazon DynamoDB 流对 Amazon DynamoDB 表进行跨区复制实践》 以及 《一桥飞架南北-中国区与 Global 区域 DynamoDB 表双向同步 (上)》 。
而兼容 PostgreSQL/MySQL 的 Amazon Aurora也在今年宣布支持和 DynamoDB 类似的数据库活动流特性,关系数据库活动(连接,查询,插入,修改等)将异步推送到 Aurora 集群预置的加密 Amazon Kinesis 数据流,数据库活动流可以支撑旁路的监控和审核能力,为您的数据库提供安全保护,比如陆续支持 IBM Security Guardium、McAfee Data Center Security Suite 和 Imperva SecureSphere 数据库审核和保护应用程序的集成。
- 1.4 -
自定义业务流程
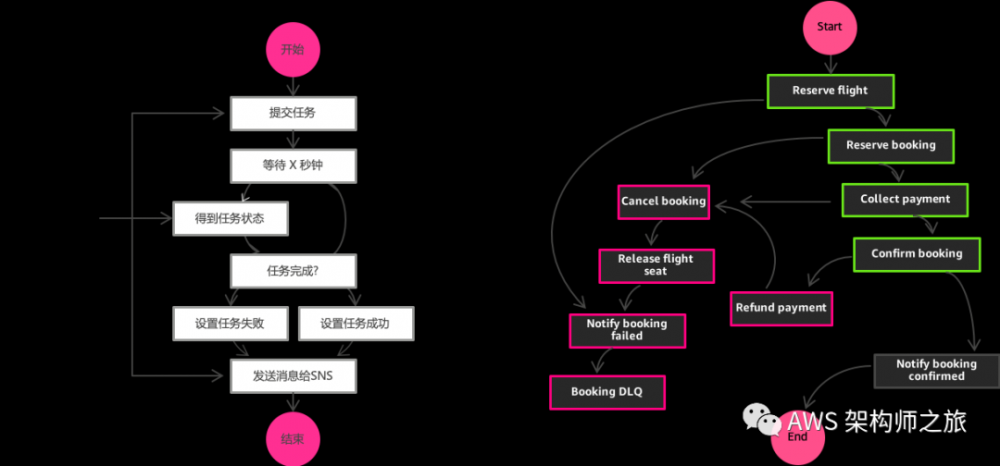
很多业务逻辑涉及多个函数功能,用户常常需要一个编排工具,实现基于状态机的复杂业务逻辑。比如用户注册,购物车,会员管理等等。
- 1.5 -
自定义 Alexa Skills 语音交互逻辑
智能音箱普及的非常快,从智能家居延伸到办公,行车等更广泛的用户日常活动,而在用户语音理解背后的业务逻辑实现也是通过关联函数计算来实现的。
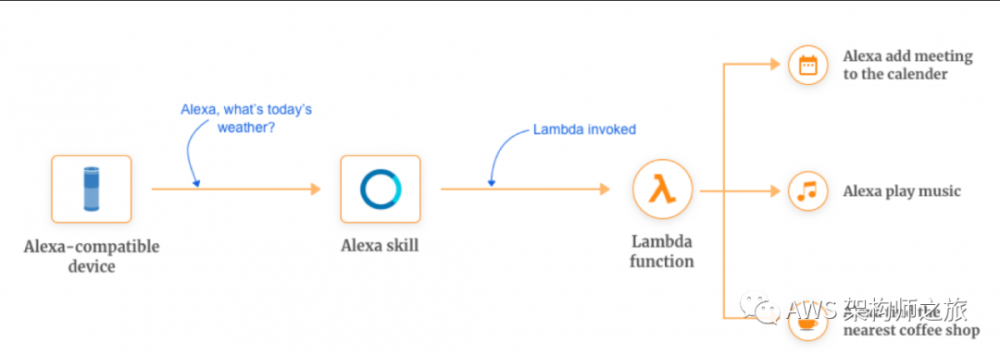
- 1.6 -
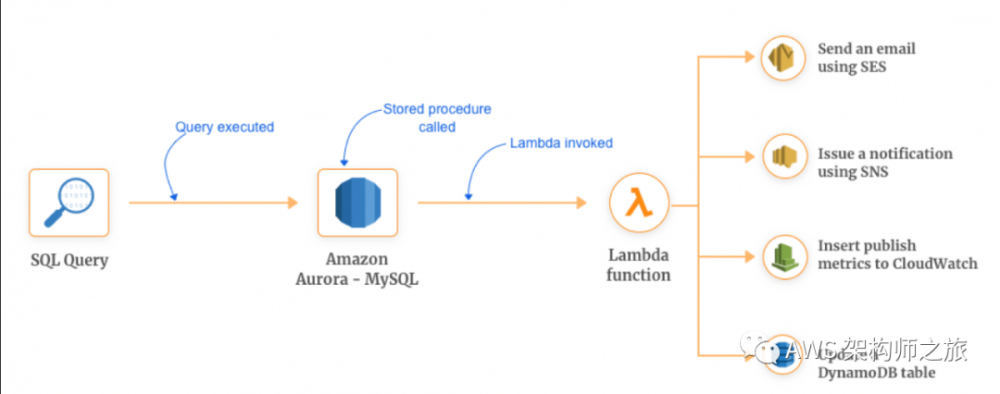
数据库存储过程外部实现
这是一个很有意思的集成,也就是存储过程的逻辑可以使用 Lambda 函数来进行扩展了,如下图所示,数据库层面定义存储过程和调用外部函数的例子,这样做有什么好处呢?
-
存储过程的执行不再消耗数据库的宝贵资源
-
Lambda 函数逻辑可以实现的逻辑更加广泛(发送通知,执行 ETL,数据库审计活动,传递信息到其他存储等等)
DROP PROCEDURE IF EXISTS SES_send_email;
DELIMITER ;;
CREATE PROCEDURE SES_send_email(IN email_from VARCHAR(255),
IN email_to VARCHAR(255),
IN subject VARCHAR(255),
IN body TEXT) LANGUAGE SQL
BEGIN
CALL mysql.lambda_async(
'arn:aws:lambda:us-west-2:123456789012:function:SES_send_email',
CONCAT('{"email_to" : "', email_to,
'", "email_from" : "', email_from,
'", "email_subject" : "', subject,
'", "email_body" : "', body, '"}')
);
END
;;
DELIMITER ;
- 1.7 -
边缘计算
如今边缘计算不仅仅包含动静态内容缓存,而且还支持客户自定义业务逻辑的能力,函数计算模型支持边缘 Edge 节点,比如请求的处理,内容预热等等,甚至设备端的离线计算能力。详细代码请参考 https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/lambda-examples.html
- 2 -
事件溯源和微服务
第一段我们回顾了事件驱动架构和 FaaS/无服务器架构之间的关系和常见场景,回到比较复杂的业务后台逻辑的微服务场景,比如电商,流媒体等场景;事件驱动的架构往往都会演变成 事件溯源(Event Sourcing) 模式:
在一个实现了事件溯源的应用中,业务领域的状态以及应用状态通过“事件”独立进行存储,如此模式,结合事件发生的时间戳,可以通过顺序重放事件来构建应用的状态(Martin Fowler 2015)
下面以一个客户(Customer)实体为例,客户的状态变更通过带时间戳的事件记录列表;在一个大的应用系统中,比如电商平台,建设一个统一的单一事实来源(Single Source of Truth)的事件账本数据源(被称为日志、流或者数据表等),这个想法有点疯狂,实现真正完美的事件溯源架构相当困难,不过设定这样的挑战目标,过程中,有助于团队优化提升数据流的设计以及数据流处理系统的质量。
| Event Name | Event Data |
|---|---|
| NewCustomerEntityRequested | { “time_occurred”: “Tue 01-01-2018 6:00”, “time_registered”: “Tue 01-01-2018 6:01”, “customerId”: “8511ae86-5d9c-11e8-9c2d-fa7ae01bbebc”, “firstName”: “Foo”,”lastName”: “Bar”,”emailAddress”: “foo@bar.com” } |
| ContactPhoneNumberAddedEvent | { “time_occurred”: “Tue 01-01-2018 6:30”, “time_registered”: “Tue 01-01-2018 6:31”, “customerId”: “8511ae86-5d9c-11e8-9c2d-fa7ae01bbebc” “phoneNumber”: “+4548484848” } |
| CustomerEmailAddressUpdatedEvent | { “time_occurred”: “Tue 01-01-2018 6:40”, “time_registered”: “Tue 01-01-2018 6:41”, “customerId”: “8511ae86-5d9c-11e8-9c2d-fa7ae01bbebc” “newEmailAddress”: “fooz@bar.com” } |
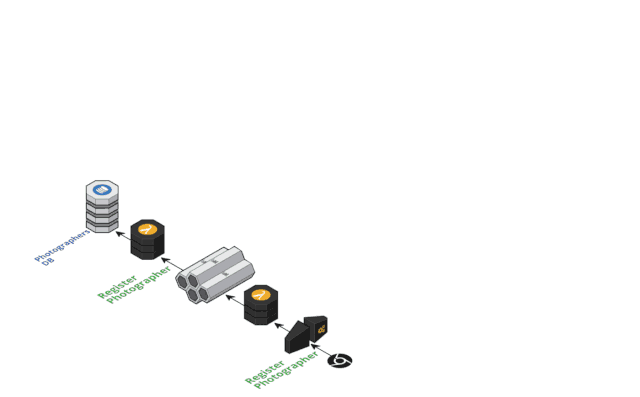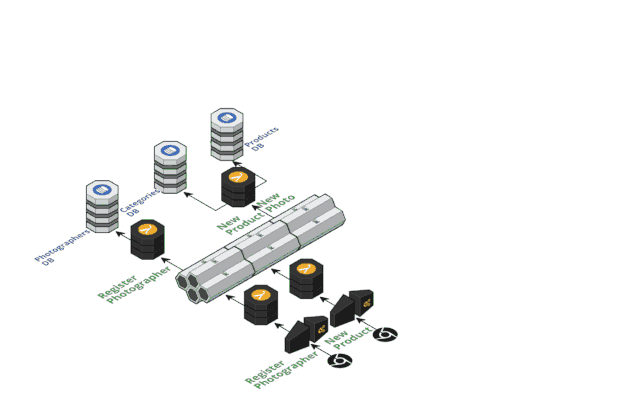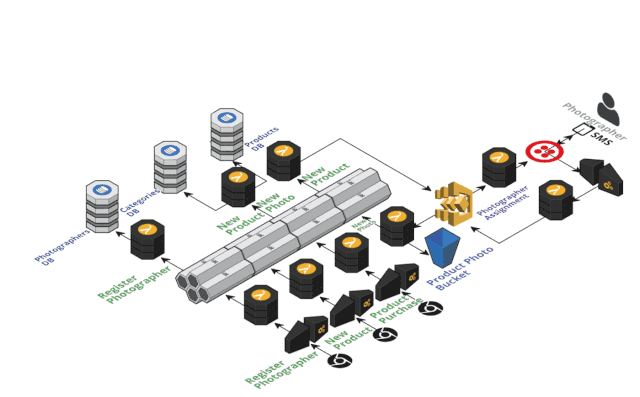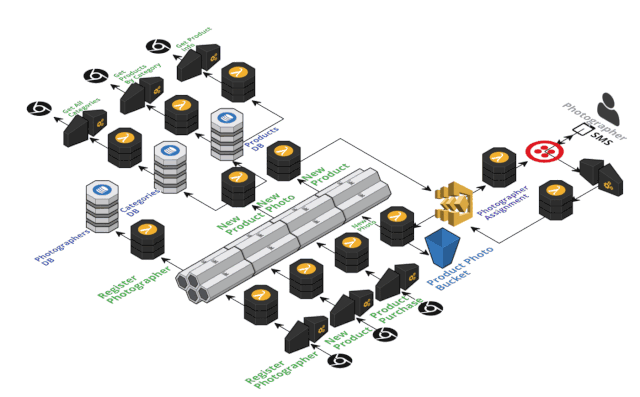
Nordstorm 团队是无服务器架构的践行者,他们在 2017年的 Austin 无服务器架构大赛上设计了一个基于无服务器的事件溯源零售店系统,在众多提交的项目中获得的大赛的最终的 Winner奖项( https://read.acloud.guru/announcing-the-winners-of-the-inaugural-serverlessconf-architecture-competition-1dce2db6da3 ),该演示项目主要聚焦新商品上架的两个个关键事件:(1)新商品图片已注册(2)新商品已上架,微服务之间通过集中的事件存储(Amazon Kinese Stream)进行通信连接;
事件溯源架构带来的好处有很多,比如:
-
提高数据质量 :由于你的分析任务和业务系统使用相同的事件数据,因此用来进行机器学习和数据分析的质量大幅提升
-
技术和业务更加统一的架构 :由于技术实现更接近现实世界的情况,更有利于团队理解业务(那个时刻发生了什么?)
-
快速反应 :近实时(通常~2秒内)响应系统中任意地方的事件,从而降低了复杂性
-
扩展性 :轻松扩展每秒数十万事件,并增加数百个事件消费者
-
业务连续性 :每个消费者服务按照自身的节奏从事件账本中读取和处理事件,减轻了后端系统的压力并创造一个更自然的断路器保护,以及更优化的故障恢复
-
服务开通效率 :服务的强制解耦加速了服务上线速度(包括新服务上线和旧服务升级改造),支持生产库上运行多个版本服务的能力,允许团队更容易从旧服务迁移到新服务
-
屏蔽技术细节 :事件不依赖任何产生事件的源系统技术实现,同时领域事件更容易被业务人员理解;
-
审计友好 :有完整的状态历史记录,允许团队重建任何时间点的应用状态进行调试和恢复
-
设定一个高标准 :每个新的消费者都会对生产者提交到数据流的质量和新鲜度有所要求,从而有助于创建一个人人都可以从中获益的正向循环
- 2.1 -
事件溯源和物联网应用
在物联网世界里,传感器(如温度,气压,光等)是事件的生产者,而消费者是类似的智能家居产品比如灯,锁等等;通常生产者和消费者之间的联系依靠不可靠的网络连接,账本(Ledgers)数据库是处理偶尔连线或离线场景强大工具,比如 AWS IoT 产品就有一个设备影子就是一个可靠的设备事件存储,确保消费者(应用,其他服务,甚至其他设备)的上线和离线不会错过关注设备的状态;CRDT(Conflict-free Replicated Data Type)也称为免冲突的可复制数据类型,它可以用于数据跨网络复制并且可以自动解决冲突收敛达成一致,非常适合使用 AP 架构的系统在各个分区之间复制数据时使用,也是保障不同偶尔连接设备之间数据收敛一致的一个方向。
- 3 -
能否给个事件溯源例子?
前文我们提到的版本控制系统 git 就是一个典型的事件溯源的系统,再比如一个象棋游戏,传统的数据库架构,只会记录当前的棋盘状态快照,基于此刻的状态,来预测谁会赢得比赛;如果利用事件溯源架构,每个动作都会记录到不可更改的账本中,每次移动我们在账本数据库中都会看到一条记录,包含游戏编号,游戏玩家代号,动作的发生的时间,以及动作的结果等等;通过访问该游戏账本数据库,你可以精确恢复任意时刻的游戏状态(事件溯源的理想标准),你还可以轻松添加更多功能,比如锦标赛,作弊分析,教练系统,游戏评论等等。棋盘的移动检测仅仅负责监听并记录该动作事件。
下一篇,我们会进一步分析一个真实客户的事件溯源系统设计和实现过程
参考资料和扩展阅读:
-
《Microservices with Clojure: Develop event-driven, scalable, and reactive microservices with real-time monitoring》by Anuj Kumar
-
《Netflix Images Enhanced With AWS Lambda》
-
《Book: Microservices patterns》 by Chris Richardson
-
《一桥飞架南北-中国区与 Global 区域 DynamoDB 表双向同步 (上)》(https://aws.amazon.com/cn/blogs/china/one-bridge-fly-north-south-china-and-global-area-dynamodb-table-two-way-synchronization1/)
-
《基于 Amazon DynamoDB 流对 Amazon DynamoDB 表进行跨区复制实践》(https://aws.amazon.com/cn/blogs/china/cross-regional-replication-practices-for-amazon-dynamodb-table-based-on-amazon-dynamodb-streams/)
-
《Media2Cloud 解决方案》(https://aws.amazon.com/cn/solutions/implementations/media2cloud/)
-
《无服务器图像处理程序》(https://www.amazonaws.cn/solutions/serverless-image-handler/?nc1=h_ls)
申明
本站点所有文章,仅代表个人想法,不代表任何公司立场,所有数据都来自公开资料* 转载请注明出处*
正文到此结束
- 本文标签: 站点 mail 集群 管理 开发 src scala Netflix update 质量 cat IDE HTML example Security 模型 云 db 产品 数据 App Developer 2015 id 部署 mysql IBM 压力 调试 智能 Amazon 文章 IO 加密 tab 数据库 UI 时间 同步 Architect 图片 stream 认证 Region 需求 博客 ORM 微服务 翻译 https sql 代码 开源 http Service lambda 服务器 git 安全 Amazon Auror 锁 entity 物联网 缓存
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

