使用sqlserver搭建高可用双机热备的Quartz集群部署
一般拿 Timer 和 Quartz 相比较的,简直就是对 Quartz 的侮辱,两者的功能根本就不在一个层级上,如本篇介绍的Quartz强大的集群机制,可以采用基于sqlserver,mysql的集群方案,当然还可以在第三方插件的基础上实现quartz序列化到nosql的mongodb,redis,震撼力可想而知,接下来本篇就和大家聊一聊怎么搭建基于sqlserver的quartz集群,实现这么一种双机热备的集群功能。
一:下载sqlserver版的建表脚本
首先在 github 上搜索quartz的源代码,在源码项目的/database/tables目录下,可以找到firebird,oracle,mysql,sqlserver等建库脚本,本篇演示sqlserver版本的建表脚本。https://github.com/quartznet/quartznet/tree/master/database/tables 如下图所示
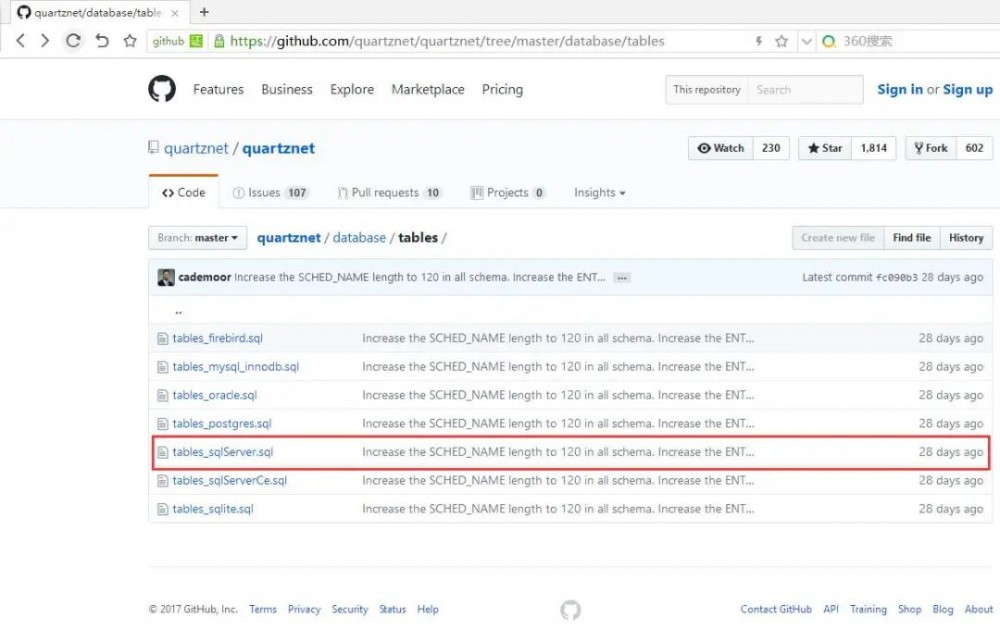
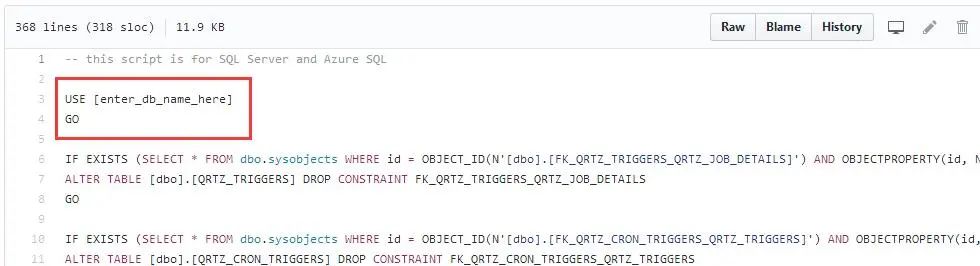
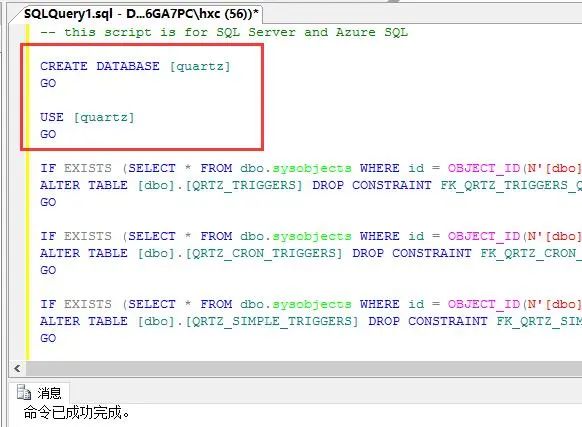
从上面的截图中可以看到,我接下来要做的事情就是增加一个你需要创建的database名字,这里取为:【quartz】,改后如下:
二:配置quartz的集群参数
当我们写 var scheduler = StdSchedulerFactory.GetDefaultScheduler()
这段代码的时候,如果大家看过源码的话,会知道这个GetScheduler的过程中有一个初始化方法 Instantiate
,此方法中你会发现在做 DBProvider 的时候会需要几个参数来初始化DB的,比如下面看到的几个标红代码。
IList<string> dsNames = cfg.GetPropertyGroups(PropertyDataSourcePrefix);
foreach (string dataSourceName in dsNames)
{
string datasourceKey = "{0}.{1}".FormatInvariant(PropertyDataSourcePrefix, dataSourceName);
NameValueCollection propertyGroup = cfg.GetPropertyGroup(datasourceKey, true);
Type cpType = loadHelper.LoadType(pp.GetStringProperty(PropertyDbProviderType, null));
// custom connectionProvider...
if (cpType != null)
{
// remove the type name, so it isn't attempted to be set
pp.UnderlyingProperties.Remove(PropertyDbProviderType);
ObjectUtils.SetObjectProperties(cp, pp.UnderlyingProperties);
cp.Initialize();
dbMgr = DBConnectionManager.Instance;
dbMgr.AddConnectionProvider(dataSourceName, cp);
}
else
{
string dsProvider = pp.GetStringProperty(PropertyDataSourceProvider, null);
string dsConnectionString = pp.GetStringProperty(PropertyDataSourceConnectionString, null);
string dsConnectionStringName = pp.GetStringProperty(PropertyDataSourceConnectionStringName, null);
if (dsConnectionString == null && !String.IsNullOrEmpty(dsConnectionStringName))
{
ConnectionStringSettings connectionStringSettings = ConfigurationManager.ConnectionStrings[dsConnectionStringName];
dsConnectionString = connectionStringSettings.ConnectionString;
}
try
{
DbProvider dbp = new DbProvider(dsProvider, dsConnectionString);
dbp.Initialize();
dbMgr = DBConnectionManager.Instance;
dbMgr.AddConnectionProvider(dataSourceName, dbp);
}
catch (Exception exception)
{
initException = new SchedulerException("Could not Initialize DataSource: {0}".FormatInvariant(dataSourceName), exception);
throw initException;
}
}
}
接下来的问题就是这几个属性是如何配置进去的,仔细观察上面代码,你会发现所有的配置的源头都来自于cfg变量,ok,接下来继续翻看代码,相信你会看到有一个Initialize方法就是做cfg变量的初始化,如下代码所示:
public void Initialize()
{
NameValueCollection props = (NameValueCollection) ConfigurationManager.GetSection(ConfigurationSectionName);
string requestedFile = QuartzEnvironment.GetEnvironmentVariable(PropertiesFile);
string propFileName = requestedFile != null && requestedFile.Trim().Length > 0 ? requestedFile : "~/quartz.config";
// check for specials
try
{
propFileName = FileUtil.ResolveFile(propFileName);
}
catch (SecurityException)
{
log.WarnFormat("Unable to resolve file path '{0}' due to security exception, probably running under medium trust");
propFileName = "quartz.config";
}
Initialize(OverrideWithSysProps(props));
}
仔细阅读上面的一串代码,你会发现,默认quartz参数配置来源于三个地方。
-
app.config中的section节点。
-
bin目录下的~/quartz.config文件。
-
默认配置的NameValueCollection字典集合,也就是上一篇博客给大家做的一个演示。
我个人不怎么喜欢通过 quartz.config 文件进行配置,这样也容易写死,所以我还是喜欢使用最简单的 NameValueCollection 配置,因为它的数据源可来源于第三方存储结构中,配置代码如下:
//1.首先创建一个作业调度池
var properties = new NameValueCollection();
//存储类型
properties["quartz.jobStore.type"] = "Quartz.Impl.AdoJobStore.JobStoreTX, Quartz";
//驱动类型
properties["quartz.jobStore.driverDelegateType"] = "Quartz.Impl.AdoJobStore.SqlServerDelegate, Quartz"; //数据源名称
properties["quartz.jobStore.dataSource"] = "myDS";
//连接字符串
properties["quartz.dataSource.myDS.connectionString"] = @"server=.;Initial Catalog=quartz;Integrated Security=True";
//sqlserver版本
properties["quartz.dataSource.myDS.provider"] = "SqlServer-20";
//是否集群
properties["quartz.jobStore.clustered"] = "true";
properties["quartz.scheduler.instanceId"] = "AUTO";
上面的代码配置我都加过详细的注释,大家应该都能看得懂,而且这些配置就是这么定死的,没什么修改的空间,大家记住即可。
三:Job和Trigger定义
在集群中环境下,job和trigger的定义该怎么写的?大家也不要想的太复杂,注意一点就可以了,在Schedule一个Job时候,通过CheckExists判断一下这个Job在Scheduler中是否已经存在了,如果存在,你就不能再次通过Schedule去重复调度一个Job就可以了。。。所以判断的代码也很简单,如下所示:
IScheduler scheduler = factory.GetScheduler();
scheduler.Start();
var jobKey = JobKey.Create("myjob", "group");
if (scheduler.CheckExists(jobKey))
{
Console.WriteLine("当前job已经存在,无需调度:{0}", jobKey.ToString());
}
else
{
IJobDetail job = JobBuilder.Create<HelloJob>()
.WithDescription("使用quartz进行持久化存储")
.StoreDurably()
.RequestRecovery()
.WithIdentity(jobKey)
.UsingJobData("count", 1)
.Build();
ITrigger trigger = TriggerBuilder.Create().WithSimpleSchedule(x => x.WithIntervalInSeconds(2).RepeatForever())
.Build();
scheduler.ScheduleJob(job, trigger);
Console.WriteLine("调度进行中!!!");
}
上面这段代码,大家就可以部署在多台机器中了,是不是很简单?
四:强大的cluster完整演示
所有的初始化工作都做完了,接下来我们copy一份bin文件,同时打开两个console程序,如下所示,可以看到job任务只会被一个console调度,另外一个在空等待。
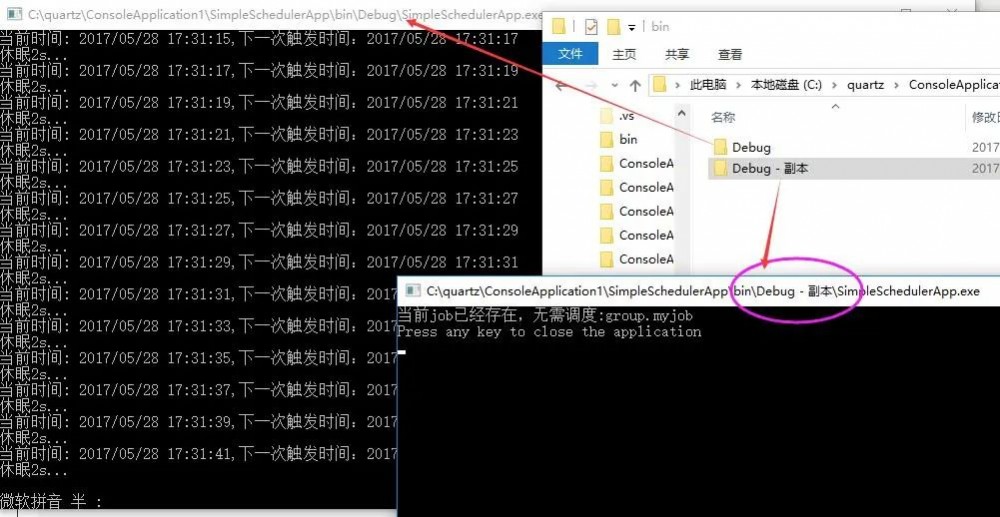
然后你肯定很好奇的跑到sqlserver中去看看,是否已经有job和trigger的db存储,很开心吧,数据都有的。。。
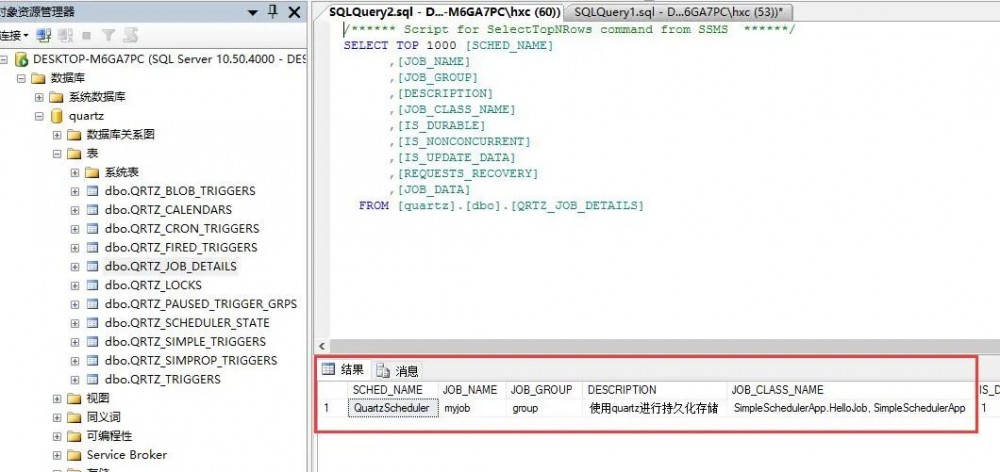
好了,一切都是那么完美,接下来可以展示一下quartz集群下的高可用啦,如果某一个console挂了,那么另一台console会把这个任务给接过来,实现强大的高可用。。。所以我要做的事情就是把console1关掉,再看看console2是不是可以开始调度job了???

完美,这个就是本篇给大家介绍的Quartz的Cluster集群,一台挂,另一台顶住,双机热备,当然这些console你可以部署在多台机器中,要做的就是保持各个server的时间同步,因为quarz是依赖于本机server的时间,好了,本篇就先说到这里吧。
正文到此结束
- 本文标签: description 数据 空间 插件 entity StdSchedulerFactory id 源码 tar UI 注释 list src trigger Master 目录 配置 时间 value build Job Collection mysql https NOSQL 代码 key Connection JobDetail IO git sql GitHub MongoDB dataSource Quartz ORM ip 集群 集群方案 HTML 同步 下载 Property 部署 db cat IDE App provider 博客 Security mongo tab Oracle redis CTO 参数 http Jobs 高可用
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

