Serializable是怎么一回事
在Java中,Serializable作为一种序列化手段最为方便不过,其使用成本之低,使在完全不了解它原理的情况下,均可正常使用。
需要序列化的场景很多,当涉及如果将数据从一个地方,有效地传输到另一个地方,就可涉及到序列化的使用。侧重于目标不同,实现的序列化方式也就不同,Serializable作为出镜率超高的序列化手段,自然有不同于其他序列化方式的地方。本文也主要讲出自己对于Serializable的理解,通过本文,可以得知:
- 什么是对象序列化
- Serializable如何实现
- Serializable如何存储
- Serializable有什么使用技巧
如果以上问题你不知道答案,本文或许有些帮助。
什么是对象序列化
简单来说,对象序列化,就是把运行时的对象信息,按照一定的规则,翻译成一串有迹可循的二进制流,然后将此二进制流,传输到从一方传输到另一方。而在接收方,在接受到此二进制流之后,可以按照约定好的解析规则,进行反序列化,将对象信息解析出来,得到有用的数据信息。
对象信息,包括Class信息、继承关系、访问权限、变量类型以及数值信息等。因此,序列化后得到的二进制流,不仅仅包含了描述一个对象的Class的关键信息,也存储了具有实际意义的数值信息。因此,序列化可以描述为——转述对象信息,存储对象数据。
Serializable如何实现
既然如此,那么Serializable是如何实现序列化的呢?
对于使用来说,我们仅需要通过声明实现Serializable接口,即可使用。如果再顺嘴问一下,Serializable怎么实现,绝大多数人都能脱口而出,使用反射使用。如果再深入地问下去,为什么要使用反射实现,不少人会哑火。
在进入真正的源码讲解之前,不妨假设,如果让你来写Serializable,你会如何实现?
开发者写出的对象千差万别,并且对于Serializable的使用说来,也不会提供更多的信息。但是可以知道,每一个对象的类信息可以用一个对应的Class类型来进行描述,其中Class类型包含了一个类所的方法,成员属性,作用域,访问权限,继承关系等。每一种类型都是Object的子类,并且在运行时,可以通过对象,访问到存储于heep中的对象数据。
既然如此,当得拿到一个将要进行序列化的对象时,可以通过反射的手段提取信息。如果将一个对象视为根节点,那么一个对象的所有信息,可以粗略地用下面一课树来表示:
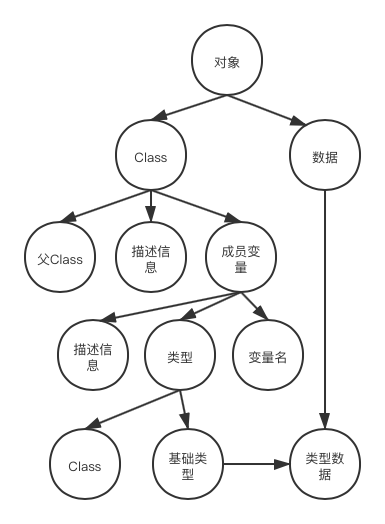
上图中,Class节点可以继续往下分解,直到为Object类型。
那么剩下的问题,就是如何通过反射,遍历这棵树,提取并存储关键信息了。
ObjectStreamClass
Serializable中,使用ObjectStreamClass来描述一种对象的存在。在ObjectStreamClass中,除了Serializable提供的此对象类型可以实现以达到其他目的的几个方法外,并不关心所包含的其他方法。因为对于将要序列化传输的对象来说,关心他的数据结构,以及各属性的基础属性值。
ObjectStreamClass接受Class类型作为参数进行实例话,并提取各层信息
private ObjectStreamClass(final Class<?> cl) {
// 代表的类类型
this.cl = cl;
// 类名
name = cl.getName();
// 是否是动态代理产生的类
isProxy = Proxy.isProxyClass(cl);
// 是否是Enum
isEnum = Enum.class.isAssignableFrom(cl);
// 是否实现了 serializable
serializable = Serializable.class.isAssignableFrom(cl);
// 是否实现了 externalizable
externalizable = Externalizable.class.isAssignableFrom(cl);
// 父类类型
Class<?> superCl = cl.getSuperclass();
// superDesc是一个ObjectStreamClass,代表父类的描述
superDesc = (superCl != null) ? lookup(superCl, false) : null;
// 指向自己的ObjectStreamClass
localDesc = this;
if (serializable) {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
if (isEnum) {
// serialVersionUID
suid = Long.valueOf(0);
// Enum没有属性
fields = NO_FIELDS;
return null;
}
if (cl.isArray()) {
// 为集合的话,没有属性
fields = NO_FIELDS;
return null;
}
// 获取serialVersionUID
suid = getDeclaredSUID(cl);
try {
// 获取此类所有需要被序列化的属性,即Filed
fields = getSerialFields(cl);
computeFieldOffsets();
} catch (InvalidClassException e) {
serializeEx = deserializeEx =
new ExceptionInfo(e.classname, e.getMessage());
fields = NO_FIELDS;
}
if (externalizable) {
// 实现了Enternalizable则反射获取构造方法
cons = getExternalizableConstructor(cl);
} else {
// 反射获取构造方法
cons = getSerializableConstructor(cl);
// 反射获取writeObject方法,实现了则有
writeObjectMethod = getPrivateMethod(cl, "writeObject",
new Class<?>[] { ObjectOutputStream.class },
Void.TYPE);
// 反射获取readObject方法,实现了则有
readObjectMethod = getPrivateMethod(cl, "readObject",
new Class<?>[] { ObjectInputStream.class },
Void.TYPE);
// 反射获取readObjectNoData方法,实现了则有
readObjectNoDataMethod = getPrivateMethod(
cl, "readObjectNoData", null, Void.TYPE);
hasWriteObjectData = (writeObjectMethod != null);
}
// 反射获取是否实现了 writeReplace,实现了则有
writeReplaceMethod = getInheritableMethod(
cl, "writeReplace", null, Object.class);
// 反射获取是否实现了 writeReplace,实现了则有
readResolveMethod = getInheritableMethod(
cl, "readResolve", null, Object.class);
return null;
}
});
} else {
suid = Long.valueOf(0);
fields = NO_FIELDS;
}
......
}
复制代码
ObjectStreamClass的实例化过程可看到的关键点为:
- Enum和集合类型是不会收集FIELDS的
- 会获取自定义的serialVersionUID,没有则生成
- 成员属性以ObjectStreamField来表示,通过getSerialFields()来获取,在此方法中,先通过getDeclaredSerialFields()先尝试获取通过变量serialPersistentFields声明的要进行序列化的成员属性,如果获取不到则通过getDefaultSerialFields()反射获取类型中声明的成员属性
看一眼getDefaultSerialFields()
private static ObjectStreamField[] getDefaultSerialFields(Class<?> cl) {
// 获取所有 Field
Field[] clFields = cl.getDeclaredFields();
ArrayList<ObjectStreamField> list = new ArrayList<>();
// static 和 transient 的掩码
int mask = Modifier.STATIC | Modifier.TRANSIENT;
for (int i = 0; i < clFields.length; i++) {
if ((clFields[i].getModifiers() & mask) == 0) {
// 添加所有不被声明为 STATIC或 TRANSIENT 的 FIELD,以ObjectStreamField来描述
list.add(new ObjectStreamField(clFields[i], false, true));
}
}
int size = list.size();
return (size == 0) ? NO_FIELDS :
list.toArray(new ObjectStreamField[size]);
}
复制代码
获取其他各种信息也主要通过反射来获取。上文源码中看到的一些方法:
- writeObject()
- readObject()
- readObjectNoData()
- writeReplace()
- readResolve()
即是Serializable提供的一些可自定义操作的方法入口,在下文中会提到。
ObjectStreamField
ObjectStreamClass用来描述一个对象,对象有属性。ObjectStreamField则描述了属性信息。
ObjectStreamField的结构相对简单不少,它只需要描述一个对象的属性信息
ObjectStreamField(Field field, boolean unshared, boolean showType) {
// 反射中代表属性的类,Field
this.field = field;
this.unshared = unshared;
// 属性名
name = field.getName();
// 属性的类类型,因为类的类型信息由ObjectStreamClass保存,因此只要知道类型即可
Class<?> ftype = field.getType();
// 此属性的类型,是基本类型,或者是对象类型
type = (showType || ftype.isPrimitive()) ? ftype : Object.class;
// 获取类标识符
signature = getClassSignature(ftype).intern();
}
复制代码
signature记录类标识符,类标识符是指用一串字符串来表示一种类型,在当前上下文中为:
- I: Integer
- B: Byte
- J: Long
- F: Float
- D: Double
- S: Short
- C: Character
- Z: Boolean
- V: Void
- L...: 引用类型
L...用来表示引用类型,假如有类为com.qinx.Example,则类标识符为: L/com/qinx/Example .
HandleTable
HandleTable是Serializable中的缓存池,在序列化或者反序列化是,当遇到同一种信息时,如果缓存池中有缓存信息,则可以减少很多不必要的解析,引用到缓存池的那个信息即可。以序列化时为列,会缓存下来的信息有:
- Class
- ObjectStreamClass
- String
- Array
- Enum
HandleTable源码可不深究,仅了解作用也可。
实际上,有了上面提到ObjectStreamClass、ObjectStreamField、HandleTable以及前面提到的从一个对象中提取信息的思路,Serializable的实现能猜出个雏型。因为,知道了获取信息的思路,对象和属性的表示方式,以及过程中减少解析的手段。下一小节则是源码过程。
ObjectOutputStream
序列化的入口类为ObjectOutputStream
public ObjectOutputStream(OutputStream out) throws IOException {
// 校验继承权限
verifySubclass();
// 构造类型为BlockDataOutputStream的OutputStream,解析过程中的数据会先写入bout,经过一些处理后,写入out
bout = new BlockDataOutputStream(out);
// 缓存
handles = new HandleTable(10, (float) 3.00);
// 替换表,在解析过程中,可以通过ObjectOutputStream提供的一些入口,来替换一些对象
subs = new ReplaceTable(10, (float) 3.00);
// 如果这个变量为true时,意味着需要重写writeObjectOverride()
enableOverride = false;
// 向bout先写入魔数以及版本号
writeStreamHeader();
// 设置BlockDataOutputStream的模式,为true则数据显写入bout
bout.setBlockDataMode(true);
......
}
复制代码
序列化的入口方法为writeObject()
public final void writeObject(Object obj) throws IOException {
if (enableOverride) {
// enableOverride为前面所说,也就是当自定义ObjectOutputStream并使用无参构造时,需要重写writeObjectOverride()来做序列化工作。
writeObjectOverride(obj);
return;
}
try {
writeObject0(obj, false);
} catch (IOException ex) {
if (depth == 0) {
// 说明遍历信息的方式有错误
writeFatalException(ex);
}
throw ex;
}
}
复制代码
一般来说,使用ObjectOutputStream()有参构造,走writeObject0()来实现序列化。还记得前面说过的提取对象信息的思路吗, 这里看到的变量depth,也就是当前遍历这颗树的节点所处的深度。
下面的源码有点长,耐心看
boolean oldMode = bout.setBlockDataMode(false);
depth++;
try {
// handle previously written and non-replaceable objects
int h;
if ((obj = subs.lookup(obj)) == null) {
// 处理需要被替换的对象,如果obj不需要被替换,subs.lookup()会返回obj本身,而如果当obj需要被替换,会出现被替换为null的情况
// 这里是写入null
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
// 如果obj已经被解析过, 写入索引信息就好,不需要重复解析
writeHandle(h);
return;
} else if (obj instanceof Class) {
// Class类型的处理方式,不深入
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
// ObjectStreamClass类型的处理方式,不深入
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}
// check for replacement object
Object orig = obj;
Class<?> cl = obj.getClass();
ObjectStreamClass desc;
for (;;) {
// REMIND: skip this check for strings/arrays?
Class<?> repCl;
// 拿到当前obj的类型的描述ObjectStreamClass
desc = ObjectStreamClass.lookup(cl, true);
if (!desc.hasWriteReplaceMethod() ||
(obj = desc.invokeWriteReplace(obj)) == null ||
(repCl = obj.getClass()) == cl)
{
// 三个条件满足一个即可
// 1. 此类型没有实现writeReplace()
// 2. 此类型实现了writeReplace()替换对象,但返回了空对象
// 3. 此类型实现了writeReplace()并返回了空对象,获取被替换对象的类型
break;
}
cl = repCl;
}
if (enableReplace) {
// 如果允许替换对象的话,进到这里
// 默认情况下replaceObject()返回本是,也就是说,ObjectOutputStream的子类可以重写replaceObject()来对一些对象进行操作
Object rep = replaceObject(obj);
if (rep != obj && rep != null) {
// 如果obj被替换成不同类型的对象,通过ObjectOutputStream解析出此类型的信息
cl = rep.getClass();
desc = ObjectStreamClass.lookup(cl, true);
}
// obj赋值为更换后的对象
obj = rep;
}
// 如果发生替换时,要再此做前面的检查
if (obj != orig) {
// 记录替换关系
subs.assign(orig, obj);
if (obj == null) {
// null的情况
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) { // 类型已被解析过的情况
writeHandle(h);
return;
} else if (obj instanceof Class) {
// Class类型的情况
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
// ObjectStreamClass类型的情况
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}
}
// 下面分别是obj为String、集合、枚举、对象类型时的处理情况
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "/n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
} finally {
// 遍历完了,恢复遍历深度信息
depth--;
bout.setBlockDataMode(oldMode);
}
复制代码
概括地说,做了以下事情:
- 首先会检查并处理obj被替换、被解析过、是Class类型、和ObjectStreamClass类型时的情况,此时会通过各自的处理方法,向bout想入信息。Class和ObjectStreamClass的处理情况不是本文的重点,因此不拓展。obj被替换以及被解析过的处理情况写入代码较简单,也不多贴例行代码
- obj没有被处理过,通过ObjectStreamClass.lookup()拿到它的类型描述。如果ObjectOutputStream重写了替换方法,则要将obj进行替换,并拿到替换的对象以及它的描述,因为后面的操作是基于真正要被写入的obj来操作的
- 当发生了替换,重写执行1
- 分别处理obj为String、集合、枚举、以及对象类型时的情况,其中前三者不难,不拓展。重点是对象类型时的处理方式。按照之前说的思路,最终当一个种类型的成员变量不再包含对象类型时,也就不再继续往下解析(处理父类的情况当作处理对象类型的情况来处理)
- 恢复遍历深度
因此,关注的点为ObjectStreamClass.lookup()如果拿到对象描述,以及writeOrdinaryObject()如何处理对象类型的解析。
获取对象描述ObjectStreamClass
static ObjectStreamClass lookup(Class<?> cl, boolean all) {
if (!(all || Serializable.class.isAssignableFrom(cl))) {
// 如果all为true,所有类型都能拿到对象描述
// 否则,只有实现了Serializable的类型能拿到对象描述
return null;
}
// 因为对象描述ObjectStreamClass是与Class关联的,并且在JVM类可以被卸载,
// 因此当类被卸载时,与Class相关的对象描述也也就无效了
// 所要移除这层关系并重新建立关系
processQueue(Caches.localDescsQueue, Caches.localDescs);
// WeakClassKey是WeakReference,弱引用Class
WeakClassKey key = new WeakClassKey(cl, Caches.localDescsQueue);
// 获取EntryFutrue或ObjectStreamClass
// key实际为Class的hashCode
Reference<?> ref = Caches.localDescs.get(key);
Object entry = null;
if (ref != null) {
// 获取实际的引用类型
entry = ref.get();
}
EntryFuture future = null;
if (entry == null) {
// entry被回收了
// 创建EntryFuture,使用软引用关联
EntryFuture newEntry = new EntryFuture();
Reference<?> newRef = new SoftReference<>(newEntry);
do {
if (ref != null) {
Caches.localDescs.remove(key, ref);
}
// 当第一次解析这个类型时,或者entry被回收时,必定拿不到entry,
// 因此先将key与EntryFuture相关联占位
ref = Caches.localDescs.putIfAbsent(key, newRef);
if (ref != null) {
entry = ref.get();
}
// 下面的判断条件,是要保证ref弱引用到的对象没有被卸载
} while (ref != null && entry == null);
if (entry == null) {
future = newEntry;
}
}
if (entry instanceof ObjectStreamClass) {
// 如果拿到ObjectStreamClass,直接返回
return (ObjectStreamClass) entry;
}
if (entry instanceof EntryFuture) {
// 如果走这里,说明是第一次获取次类型的描述,或者描述已经被卸载
future = (EntryFuture) entry;
if (future.getOwner() == Thread.currentThread()) {
// 如果是当前线程创建的,置空
entry = null;
} else {
// 如果是其他线程创建的,获取到其他线程创建的结果
entry = future.get();
}
}
if (entry == null) {
try {
// 说明类其他线程并未创建,创建对象描述
entry = new ObjectStreamClass(cl);
} catch (Throwable th) {
entry = th;
}
if (future.set(entry)) {
// 说明由当前线程创建的对象描述可用
// 与Class建立关联
Caches.localDescs.put(key, new SoftReference<Object>(entry));
} else {
// 说明当前线程穿件的对象描述不可用,其它线程已经建立好了
// 使用其他线程创建的对象描述
entry = future.get();
}
}
......
}
复制代码
lookup()方法最终目的,是拿到一个可用的对象描述:
- 在开始阶段,在all为false的情况下,会检查此类型是否实现了Serializable,实现了才可进行下一步
- 如果能拿到对象描述,需要检查是否可能,因为类可能被卸载过,描述信息失效,需要重新建立
- 拿不到可用的对象描述,只需要通过 ObjectStreamClass(final Class<?> cl)就可以拿到可用的对象描述。但是实际情况要复杂一些,因为在此时此刻,很可能有多个线程在序列化解析同一类型,因此需要考虑并发问题
- 在处理并发问题时,会使用EntryFuture来对Class的关联进行占位,EntryFuture中保存了当前线程。然后,再次从缓存里获取EntryFuture,EntryFuture可用。此时,虽然之前使用当前线程使用了自己创建的EntryFuture来进行占位,但是不代表能占位成功,因此再次从缓存里获取得到的EntryFuture就是真正占位成功的对象。再从EntryFuture获取对象描述entry。需要注意的是,当前阶段保证了所有线程拿到同一个EntryFuture,但是里面的entry还不一定存在。因此这种情况下,会去尝试对象描述新建使用EntryFuture.(set)关联。关联上,说明可用;关联不上,说明其他线程已经新建关联了,EntryFuture.get()拿到真正的对象描述即可
写入对象信息
private void writeOrdinaryObject(Object obj,
ObjectStreamClass desc,
boolean unshared)
throws IOException
{
......
try {
// 检查obj是不是可以进行序列化
desc.checkSerialize();
// 写入信息,TC_OBJECT值为0x73,代表要写入一个新对象
bout.writeByte(TC_OBJECT);
// 写入对象描述信息
writeClassDesc(desc, false);
// 如果unshared为true的话,每次都会重新解析出对象描述,
// 正常情况为false,因此对象描述可以被缓存复用
handles.assign(unshared ? null : obj);
if (desc.isExternalizable() && !desc.isProxy()) {
// 实现了Externalizable()的情况
writeExternalData((Externalizable) obj);
} else {
// 实现了Serialazable的情况,前面已经写入了类型信息
// 接下来要写入数据信息
writeSerialData(obj, desc);
}
} finally {
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
}
复制代码
对象信息包含两方面,类型信息以及数据信息,这两种信息都会存在于序列化后的二进制流里。类型信息通过writeClassDesc()来写入,其中包含四种情况的写入规则:
- 描述为null时
- 描述被缓存时
- 描述的类型时动态代理产生时
- 描述还未曾被写入时
这里不深入writeClassDesc(),深入下去是具体的二进制流写入规则。
数据信息则是通过writeSerialData()写入
private void writeSerialData(Object obj, ObjectStreamClass desc)
throws IOException
{
ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout();
for (int i = 0; i < slots.length; i++) {
ObjectStreamClass slotDesc = slots[i].desc;
if (slotDesc.hasWriteObjectMethod()) {
// 前面有提到过,对象有一个可以操作的方法入口,writeObject()
// 如果对象实现了这个方法,这里就会反射用 writeObject()
....
} else {
// 一般情况下,执行这个方法
defaultWriteFields(obj, slotDesc);
}
}
}
复制代码
注释已解释清楚,直接看defaultWriteFields()
private void defaultWriteFields(Object obj, ObjectStreamClass desc)
throws IOException
{
Class<?> cl = desc.forClass();
// 做类型校验,保证从Obj获得的对象描述正确
if (cl != null && obj != null && !cl.isInstance(obj)) {
throw new ClassCastException();
}
......
// 获取所有成员变量,在对象描述实例化时,已经完成了解析
ObjectStreamField[] fields = desc.getFields(false);
// 之后对象的属性值存在这里
Object[] objVals = new Object[desc.getNumObjFields()];
// 属性个数
int numPrimFields = fields.length - objVals.length;
// 反射获取属性值
desc.getObjFieldValues(obj, objVals);
for (int i = 0; i < objVals.length; i++) {
if (extendedDebugInfo) {
debugInfoStack.push(
"field (class /"" + desc.getName() + "/", name: /"" +
fields[numPrimFields + i].getName() + "/", type: /"" +
fields[numPrimFields + i].getType() + "/")");
}
try {
// 解析为对象类型的属性
writeObject0(objVals[i],
fields[numPrimFields + i].isUnshared());
} finally {
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
}
}
复制代码
对象描述里,存有一种类型下,所有的成员变量信息。拿到这些信息后,又依次遍历调用writeObject0()解析成员变量。这里需要注意,只有对象类型才会被遍历解析,而基本类型能直接确定。在上面的代码 desc.getNumObjFields() 处,就是获取类的为对象类型的成员变量数,此数值在对象描述实例化阶段,解析出属性后,通过computeFieldOffsets()计算。
回到writeObject0()后,就是熟悉的内容了。
Serializable实现小结
- 将对象当成一棵树,将类型、父类、成员变量视为节点,遍历这颗树获取信息
- 默认情况下,通过ObjectOutputStream.writeObject0(),使用系统提供的方式解析信息;也可以通过重写writeObjectOverride()来按照自己的规则解析
- 通过反射解析出对象描述、属性的描述,其中成员变量的描述存于对象描述中
- 会以HandleTable来缓存解析信息,包括Class、ObjectStreamClass、String、Array、Enum
- 如果ObjectOutputStream重写了replaceObject(),可以在序列化过程中,替换某些对象
- 写入对象描述信息、为基本类型的成员信息,通过2-6过程,解析为对象类型的成员属性,直到某一类为Object了型或者所有成员变量为基本类型,树收敛。
存储
序列化最终的解决,是得到一组有规则的二进制流。而这部分的写入信息,分布在序列化过程代码中的边边角角,如果要把这部分信息的相关代码都贴出来,不免阅读起来失去重心,也没有营养。因此这部分的内容不会看到实际的写入代码。
如果曾了解过Class文件结构,这部分内容则非常容易消化,不了解也不妨碍理解。 Class 文件解析
简单来说,序列化出的二进制流,需要包含所序列化对象的类型描述、父类、属性描述、属性值信息,并且最终目的是要进行传输以反序列化后形成有效的数据。因此这个二进制流是紧凑的,不携带多余信息,又应该的安全的,不遗漏任何信息。除了描述、父类、属性描述、属性值这些必备的不可避免的信息外,序列化与反序列化双方必须遵守阅读此二进制流的规则,加上一些助记、索引信息,最终形成一张携带信息的索引表。
写个例子
public class Phone implements Serializable {
private Card card1;
private Card card2;
private String brand;
private String color;
private int price;
.......
}
public class Card implements Serializable {
private String number;
......
}
public static void main(String[] args) {
String FILE_PATH = "info.txt";
try {
File f = new File(FILE_PATH);
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(FILE_PATH));
Phone phone = new Phone();
phone.setColor("0xFFFFFF");
phone.setBrand("OnePlus");
phone.setPrice(3000);
Card card1 = new Card("12345678901");
Card card2 = new Card("98765432109");
phone.setCard1(card1);
phone.setCard2(card2);
out.writeObject(phone);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
复制代码
上面代码phone序列化后,写入文件中,再借用二进制工具打开这个文件后,有如下信息
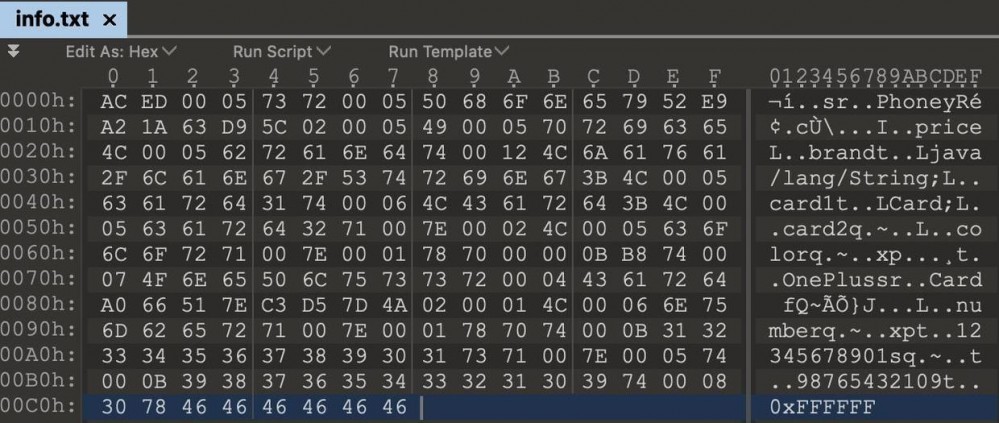
上面将二进制数据转为了十六进制,每一个位置即是一个字节码。如果没有工具,可以用ByteArrayOutputSteam来接收流,然后配合DadatypeConverter也可以在控制台输出十六进制内容。
加上阅读规则,就可以阅读以上信息。下图是我看源码过程中读出的阅读规则。
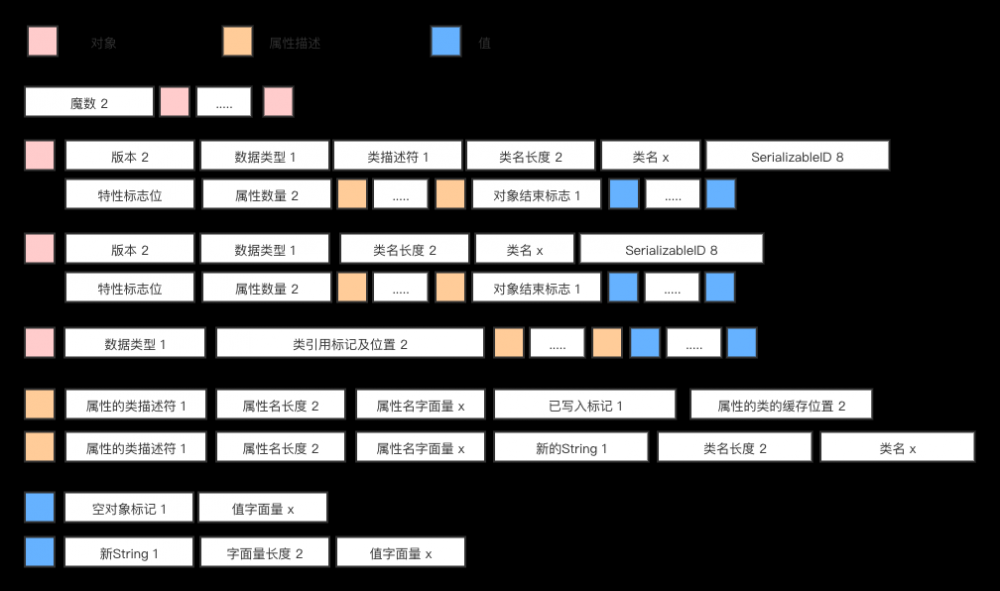
图中的含义为:
- 带颜色方形代表一种区块
- 颜色后面的一整块结构,代表这种颜色区块可能具有的结构
- 数字代表占多少个字节
上面所给出的阅读规则不代表所有的规则,如果对更多的规则感兴趣,可以参考: Serializable Specification
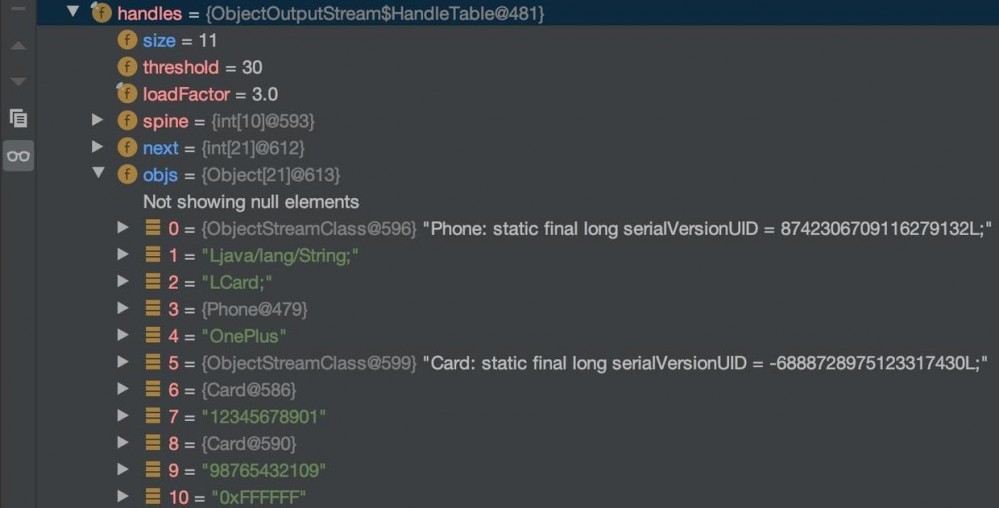
如果你的例子不同,可以跟上图去阅读。下面是对于当前例子序列化出的二进制的具体阅读解释。其中很多常量可以在ObjectStreamConstants中找到,如果需要自己跟写入规则,以ObjectStreamConstants来索引源码会有帮助。再附上当前情况的HandleTable表便于查看
下面每一行十六个字节码
AC ED(魔数) 00 05(版本) 73(新对象) 72(新的对象描述) 00 05(类名长度) 50 68 6F 6E 65(代表Phone的ascil码) 79 52 E9 A2 1A 63 D9 5C(Phone的serialVersionUID) 02(代表实现了Serializable) 00 05(属性数量为5) 49(属性类型为I) 00 05(属性名长度为5) 70 72 69 63 65(代表price的ascil码) 4C(属性类型为L) 00 05(属性名长度为5) 62 72 61 6E 64(代表brand的ascil码) 74(新的String) 00 12(类名字面量长度为18) 4C 6A 61 76 61 2F 6C 61 6E 67 2F 53 74 72 69 6E 67 3B(代表Ljava/lang/String;的ascil码) 4C(属性类型为L) 00 05(属性名长度为5) 63 61 72 64 31(代表card1的ascil码) 74(新的String,将指向的是后面属性类型的字面量) 00 06(类名字面量长度为6) 4C 43 61 72 64 3B(LCard;的ascil码) 4C(属性类型为L) 00 05(属性名长度5) 63 61 72 64 32(代表card2的ascil码) 71(已写入标记) 00 7E 00 02(这里是0x7E0000 + 0x02,前者代表缓存索引标记,后者代表位置,因为按照Int写入,占四字节,所以前面有00) 4C(属性类型为L) 00 05(属性名长度为5) 63 6F 6C 6F 72(color的ascil码) 71(已写入标记) 00 7E 00 01(缓存表第一个位置) 78(对象结束标记) 70(空对象) 00 00 0B B8(int,为3000,price的值) 74(新String) 00 07(字面量长度7) 4F 6E 65 50 6C 75 73(OnePlus的ascil码) 73(新对象) 72(新的对象描述) 00 04(类名) 43 61 72 64(Card的ascil码) A0 66 51 7E C3 D5 7D 4A(Card的serialVersionUID) 02(代表实现了Serializable) 00 01(属性数量为1) 4C(属性类型为L) 00 06(属性名长度为6) 6E 75 6D 62 65 72(number的ascil码) 71(已写入标记) 00 7E 00 01(HandleTable第一个位置) 78(对象结束) 70(对象为空) 74(新的String) 00 0B(值字面量长度为11) 31 32 33 34 35 36 37 38 39 30 31 73(1245678901的ascil码) 71(已写入标记) 00 7E 00 05(HandleTable第5个位置) 74(新String) 00 0B(值字面量长度11) 39 38 37 36 35 34 33 32 31 30 39(98765432109的acill码) 74(新String) 00 08(值字面量长度8) 30 78 46 46 46 46 46 46(0xFFFFFF的ascil码) 复制代码
如有错误望指出。
使用技巧
前面有提到,Serializable的序列化机制里,提供了一些操作入口。在对象侧,有
- writeObject()
- readObject()
- readObjectNoData()
- writeReplace()
- readResolve()
以及serialPersistentFields
在解析测,有:
- writeObjectOverride()
- replaceObject()
下面是以上一些操作的例子
serialPersistentFields
对象可以实现serialPersistentFields,用来声明序列化规则,比如,在上面的Phone代码中添加
private static final ObjectStreamField[] serialPersistentFields = {
new ObjectStreamField("brand", String.class),
new ObjectStreamField("card1", Card.class),
};
复制代码
再次进行序列化,只有brand和card1的信息被包含了,其他属性的信息没有录入。
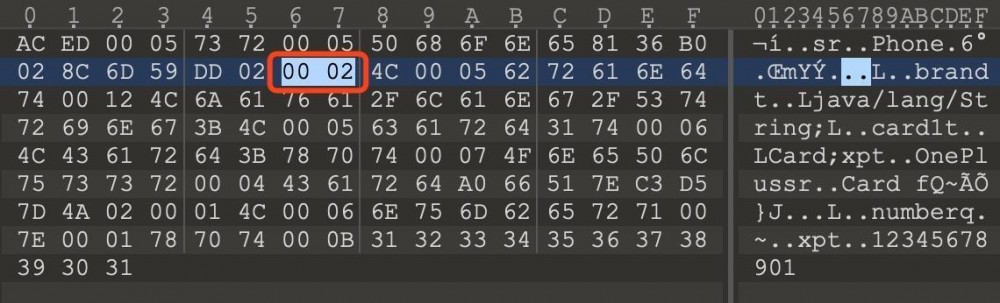
serialPersistentFields声明了序列化哪些属性,而transient声明了不序列化哪些属性,这里就不做验证。关于serialPersistentFields的具体代码,可见ObjectSteamClass.getSerialFields() -> ObjectSteamClass.getDeclaredSerialFields()
writeObject
对象可以声明writeObject(),可以在属性被序列化之前进行操作。可以在Phone中加入代码
private void writeObject(java.io.ObjectOutputStream steam) throws java.io.IOException{
// 咱们的手机打折了
price = price * 7 / 10;
// 继续使用默认序列化流程
steam.defaultWriteObject();
}
复制代码
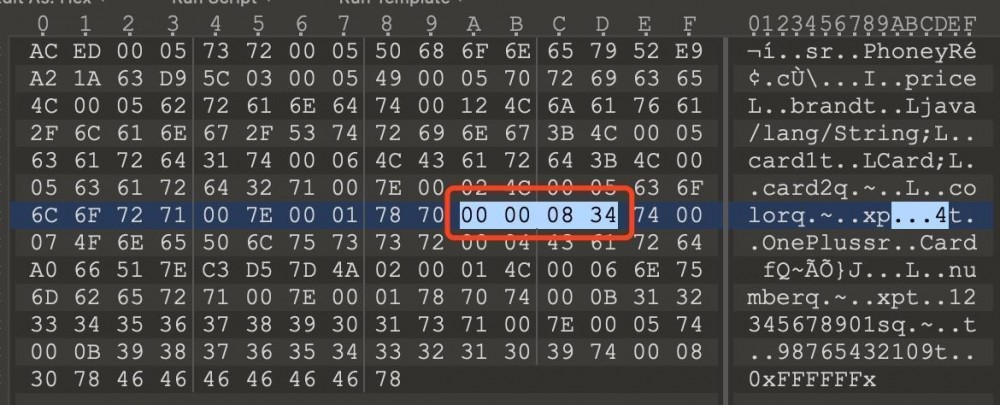
原先的代码里,price设置为3000,在序列化前被打了7折,变成了2100,对应的16进制就是 0x00000834。在实际的场景里,这里可以用于对具体数据加密操作。既然有writeObject()做预处理,那么就会有readObject()做解预处理, 这里过程体现在反序列化中,这里就不做例子了。
writeObject代码见 ObjectOutputStraem.writeOrdinaryObject() -> writeSerialData()
writeReplace
对象可以实现writeReplace(),在获取对象描述前,可对对象进行替换。代码位于ObjectOutputStraem.writeObject0()。而在那段代码中,可以看出两层信息:
- 可以在这里对对象里的属性值进行修改
- 可以替换整个对象
先看第一种情况,在Phone中加入代码
private Object writeReplace(){
Card replaceCard = new Card("super card!!!");
card1 = replaceCard;
return this;
}
复制代码
将card1替换为别的卡,下面是序列化后的二进制流
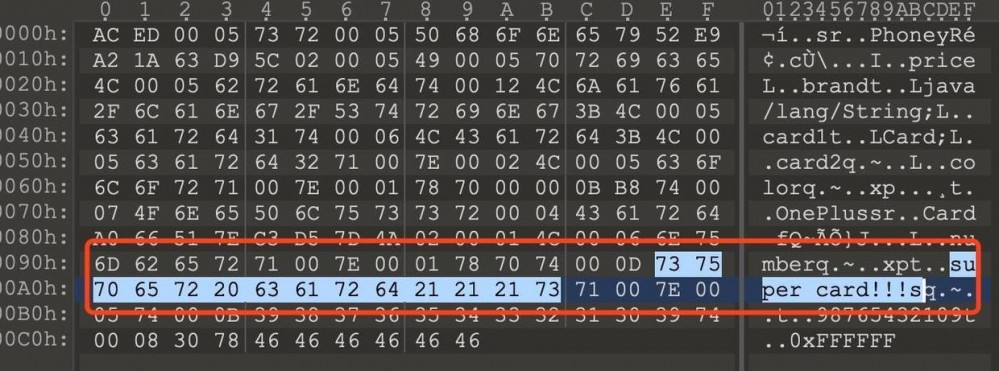
card1已经被替换
将刚才的代码更换,看第二种情况
private Object writeReplace(){
return "all phone sale out";
}
复制代码
将Phone替换为String,下面是二进制流

Phone已经被整个替换。 这里也可以看出,默认的String是不带serialVersionUID的。
readResolve
readResolve()与writeReplace()类似,也可以替换对象。readResolve()是在反序列化过程中,解析出对象后,对这个对象进行再操作并返回一个新的对象。这里就不做例子。
readObjectNoData
当序列化的过程中,如果这个对象所有的属性都没有值,可以实现readObjectNoData(),以在这种场景下做一些操作,比如设置特殊值,这里不做例子,具体的方法为:
private void readObjectNoData(){
}
复制代码
replaceObject()
可以自定义ObjectOutputStream()来实现replaceObject(),反序列化过程,对一些对象进行替换,如自定义MyObjectOutputStream,并使用此类替换例子中的ObjectOutputStream
public class MyObjectOutputStream extends ObjectOutputStream {
public MyObjectOutputStream(OutputStream out) throws IOException {
super(out);
enableReplaceObject(true);
}
@Override
protected Object replaceObject(Object obj) throws IOException {
if (obj instanceof Card){
Card curCard = (Card)obj;
curCard.setNumber("857857857");
}
return super.replaceObject(obj);
}
}
复制代码
序列化后的信息为
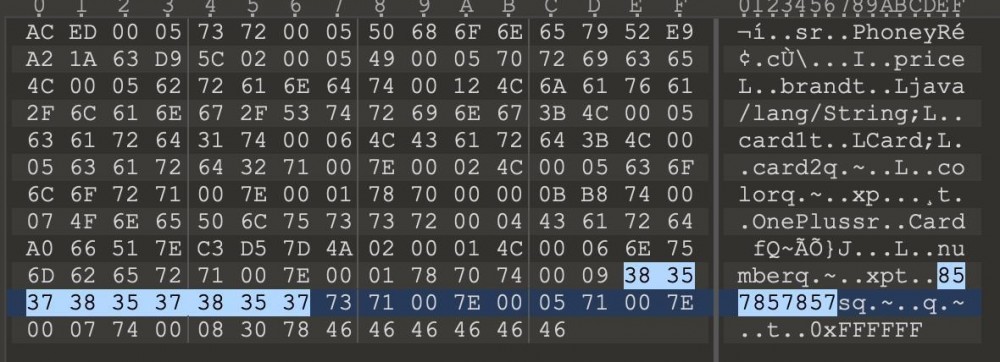
完成替换。 代码位于ObjectOutputStream.writeObject0()
writeObjectOverride
如果对于系统提供的序列化过程不满足,还可以实现writeObjectOverride()来自定义序列化过程。将MyObjectOutputStream的代码替换为:
public class MyObjectOutputStream extends ObjectOutputStream {
public MyObjectOutputStream(OutputStream out) throws IOException {
super(out);
// enableOverride 是私有的,为了方便这里反射更改
Class<?> parentCl = getClass().getSuperclass();
try {
Field enableOverride = parentCl.getDeclaredField("enableOverride");
enableOverride.setAccessible(true);
enableOverride.set(this, true);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
protected void writeObjectOverride(Object obj) throws IOException {
// 模拟自己先序列化过程
writeBytes("I know the Serializable!!");
}
}
复制代码

完成序列化,代码位于ObjectOutputStream.writeObject().
总结
文章到这里就结束了,以writeObjectOverride()结尾,也祝大家在看完后,know the Serializable。文章中并未涉及到反序列化的讲解,而在知道了序列化原理之后,反序列化可见一斑,想要了解反序列化的原理会很轻松,因此不做陈述。对于serialVersionUID的使用也没有做例子验证,大家感兴趣的话,可以自行验证。
回答
1、什么是对象序列化将对象的类型、属性、父类、数据信息,按照一定规则解析成二进制,存储、传输,并能通过反序列化得到有意义的对象。
2、Serializable如何实现以对象为根结点,将类型、父类、成员变量视为子节点,遍历这颗树,反射获取信息。并借助ObjectSteamClass、ObjectStreamField、HandleTable记录过程信息。最后将这些信息按约定规则输出二进制流。
3、Serializable如何存储存储于二进制流中。可以将这串流视为携带数据的索引表
4、Serializable有什么使用技巧对象侧:
- writeObject(): 序列化前操作对象数据,比如加密
- readObject(): 反序列化前操作对象数据,比如揭秘
- readObjectNoData():对象没有属性数据时,可以提供特殊处理
- writeReplace():替换序列化的对象
- readResolve(): 替换反序列化后的对象
解析侧:
- writeObjectOverride(): 自定义序列化过程
- replaceObject():切面替换要序列化的对象
正文到此结束
- 本文标签: 翻译 cat CEO 参数 ACE IO 字节码 rand java 线程 注释 list http cache JVM 加密 代码 value ask constant ArrayList 并发 https IDE key src Action 索引 stream struct 数据 实例 example queue 集合类 zab ip 开发者 遍历 总结 message 回答 缓存 tab UI 解析 final 文章 bug Proxy 源码 安全 CTO 开发 营养 id 构造方法
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

