基础篇:JAVA基本类型
1:java几种基本类型大小
| 关键字 | 类型 | 位数 (8位一字节) | 取值范围(表示范围) |
|---|---|---|---|
| byte | 整型 | 8 | -2^7 ~ 2^7-1 |
| short | 整型 | 16 | -2^15 ~ 2^15-1 |
| int | 整型 | 32 | -2^31 ~ 2^31-1 |
| long | 整型 | 64 | -2^63 ~ 2^63-1 |
| float | 浮点数 | 32 | 3.402823e+38 ~ 1.401298e-45 |
| double | 浮点数 | 64 | 1.797693e+308~ 4.9000000e-324 |
| char | 文本型 | 16 | 0 ~ 2^16-1 |
| boolean | 布尔值 | 32/8 | true/false |
boolean的占用大小是多少,有如下说法
- 1bit : boolean编译后的是使用1和0储存,理论上只需1bit即可储存
- 1byte : 计算机处理数据的最小单位是1byte,用一字节的最低位存储,其他的用0填补。如果值是true则储存二进制为0000 0001,false则是0000 0000
- 4byte or 1btye : java虚拟机没有对boolean类型的专用字节码指令,表达式所操作的boolean在编译之后是使用int数据类型来代替的,而boolean数组则会被编译成byte数组
正解在java里的正确回答应该是boolean类型单独使用是4个byte,在数组里则是1个byte。但是虚拟机为什么不用byte或short代替boolean而是int,这样不是更节省内存空间?因为int对于32位处理器,一次处理的数据是32位,CPU寻址也是32位的查找,具有高效储存的特点(如果有更好的理解,大家共同交流下)
2:64位的JVM中,int类型长度是多少
32位;int是32位类型,不会随着系统或者jvm的位数而改变
3:char类型变量能不能储存一个中文的汉字,为什么
java默认编码是unicode编码方式每个字符占用两个字节,char是16位类型,中文储存需要两个字节,因此可以储存中文字符。
4:浮点数float和双精度浮点数double表示法
浮点数的二进制表示法由三部分组成
- 符号位
- 指数位
- 尾数为
float、double二进制结构
| 类型 | 符号位 | 指数位(e) | 尾数位(m) |
|---|---|---|---|
| float | 1 | 8 | 23 |
| double | 1 | 11 | 52 |
- 符号位部分用来储存数字符号,区分正负数,0 正 1 负
-
指数位储存指数,指数也有正负,指数确定大小范围
- 指数是有符号的,但有符号整数比无符号整数计算麻烦,因此实际储存是将指数转为无符号整数,8bit的范围为0~255,真实的指数需要减去偏移量127。范围在(-126 ~ 128)
-
尾数位存储小数部分,确定浮点数精度,小数能表示的数越大,精度越大,数值越准确
- float的尾数位是23,2^23=8388608 ,8388608是个7位数的十进制,如果加上忽略的整数位,最多可表示8位的十进制。但是绝对能保证有效是7位左右的十进制数;double尾数位是52,2^52=4503599627370496,16位的数字,加上整数位2^53也是个16位数字,因此绝对能保证有效位精确是15位的十进制数
-
15.625的存储示例:
- 15.625 换成二进制 1111.101
- 将1111.101 右移三位,剩小数点前1位: 1.111101 * 2^3
- 底数位:因为小数点前必是1,因此只需记录小数点后的位数即可,此时底数是 1111 01 ,低位补零:111 1010 0000 0000 0000 0000
- 指数位:指数为3,加上127(反转时则减去127)得130,指数位二进制为1000 0010
- 符号位:正数 0
-
15.625 在内存的二进制形式表示为
符号 指数 尾数 0 1000 0010 111 1010 0000 0000 0000 0000
5:基本类型对应的包装类,区别
| 基本类型 | 包装类 |
|---|---|
| boolean | Boolean |
| short | Short |
| byte | Byte |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
- 对于万物皆对象的java,为什么会存在基本类型?因为java产生对象,一般是需在堆创建维护,再通过栈的引用来使用,但是对于简单的小的变量,需要在堆创建再使用太麻烦了
-
为什么会有包装类
- 包装类将基本类型包装起来,使其具有对象的性质,可以添加属性和方法,丰富基本类型的操作
- 对于泛型编程,或使用collection集合,需要包装类。因为ArrayList,HashMap的泛型无法指定基本类型
- 区别,基本类型可以直接声明使用,包装类需要在堆创建,再通过引用使用;基本类型默认初始值,int为0,boolean则是true/false,且无法赋值为null;而包装类默认初始值是null
- 需要注意的点:Byte、Int、Short、Long直接赋值(或使用valueOf)如Integer x = value(value 在-128 ~ 127)是直接引用常量池里的对象,此时对象比较 == 和 equals 都为true ;Character声明值则在0~127 是引用常量池对象、
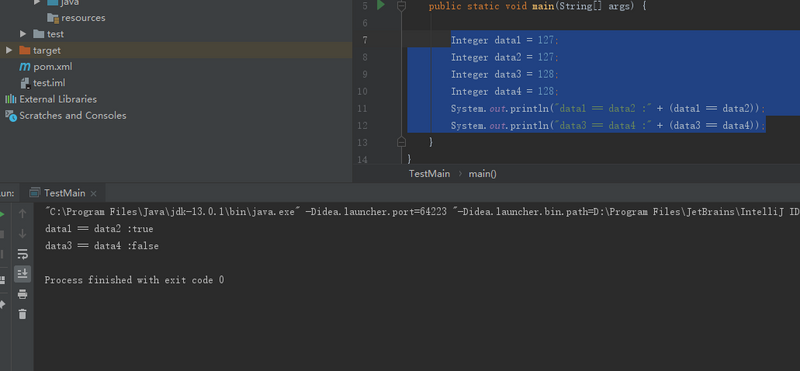
6:基本类型的自动转换
自动转换规则有如下几个
- 布尔类型boolean不存在隐式转换为其他类型(非自动封装类型)
-
整数类型的自动提升
- byte -> (short/char) -> int -> long (自动提升链)
- 表示范围低的数据类型可隐式自动提升为表示范围高的数据类型(byte b = 1; short s = b; );无编译错误
- short 和 char 都是16位,但是不能隐式转换
-
字符型数据向整型数据的自动转换
- char是无符号类型,表示范围在(0~2^16-1),可隐式转为int或long类型
-
整型、字符型数据都可向浮点型的自动转换
- 因为浮点型能保存的有效数字是限制的,需要考虑转换后的有效位问题
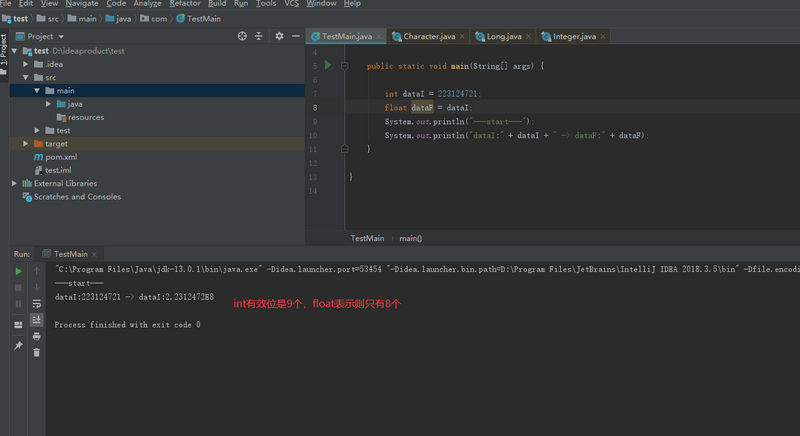
-
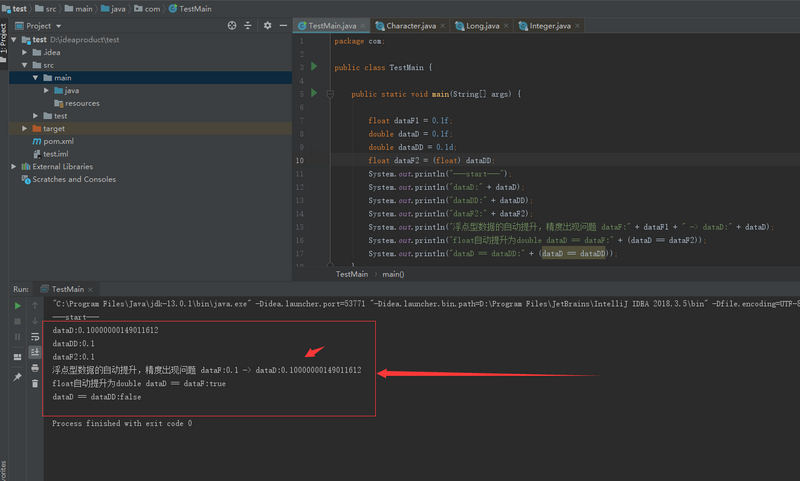
浮点型数据的自动提升
- float转double存在精误差问题,double如果强制转float则存在精度丢失问题
7:short s1 = 1; s1 = s1 + 1;有错吗? short s1 = 1; s1 += 1;有错吗?
- s1 = s1+1 中的1默认类型是int,表达式中低范围类型s1会默认转为int来相加,得到int型的结果,最后int型的结果不能隐式转为short,编译报错
- s1 += 1; 存在隐含的强制转化 s1 += 1 -> s1 = (short) s1+ 1; 编译不会报错
8:不同的基本类型强制转换,可能会产生什么问题
- 浮点型转整型,精度丢失、数据溢出
- 取值范围大的整型转取值范围小的整型,数据溢出,高位丢失
9:float f = 3.4; 是否正确?
在java里,不加后缀修饰的浮点数默认是double类型。double类型不能隐式类型转成float,编译会报错
10:表达式3*0.1 == 0.3 将会返回什么?true还是false?
浮点型存在精度问题,3*0.1得到的double数据尾数位 和 0.3 尾数位是不一样的 ,false
11:浮点数和BigDecimal
- 浮点类型使用二进制存储,无论float(7),double(15),其有效位是有限制的,存在舍入误差,精度容易缺失
- 十进制小数转为浮点数再计算,严重存在精度问题。那么是否可以把十进制小数扩大N倍化为整数维度来计算,并保留其精度位数,这就是BigDecimal
- BigDecimal是基于BigInteger来处理计算,BigInteger内部有一个int[] mag,表示存放正数的原字节数组 BigInteger原理
-
构造BigDecimal时避免使用浮点类型构造,会出现精度问题。尽量使用字符串来创建BigDecimal,或者使用valueOf方法
BigDecimal data= new BigDecimal(0.1); System.out.println("data:" + data); result: data:0.1000000000000000055511151231257827021181583404541015625 - BigDecimal 进行除法运算不整除时出现无限循环小数,会抛出 ArithmeticException 异常,需要指定精度
- 指定精度位数,同时需要指定舍入模式
12:switch语句能否作用在 byte 类型变量上,能否作用在long类型变量上,能否作用在 String 类型变量上?
- switch(expr) expr 需要时int类型,而byte,char,short 会自动提升为int,因此可以作用在switch关键字。long,float,double不能自动转为int,编译会报错
-
String 也不能自动转为int,在1.7之前也是不能用在switch。但是1.7之后JDK支持String,通过String.hashCode返回一个int类型,并在case里再次使用String.equals比较
//语法糖反编译 switch(s.hashCode()){ default; break; case 3556498: if(s.equals("test")){ ..... } break; }
13:能否在不进行强制转换的情况下将一个double值赋值给long类型的变量
不行,因为double取值范围大于long类型。不强制转换会编译报错。如果使用 += 操作符编译不会报错,但是存在隐含的强制转换
关注公众号,大家一起交流

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

