面试之敌系列 5 Spring
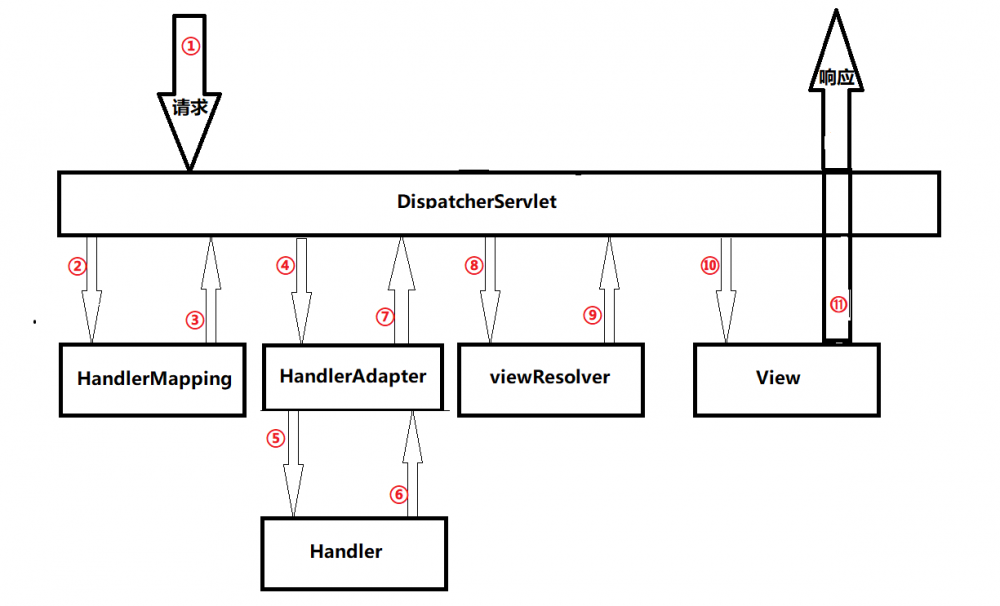
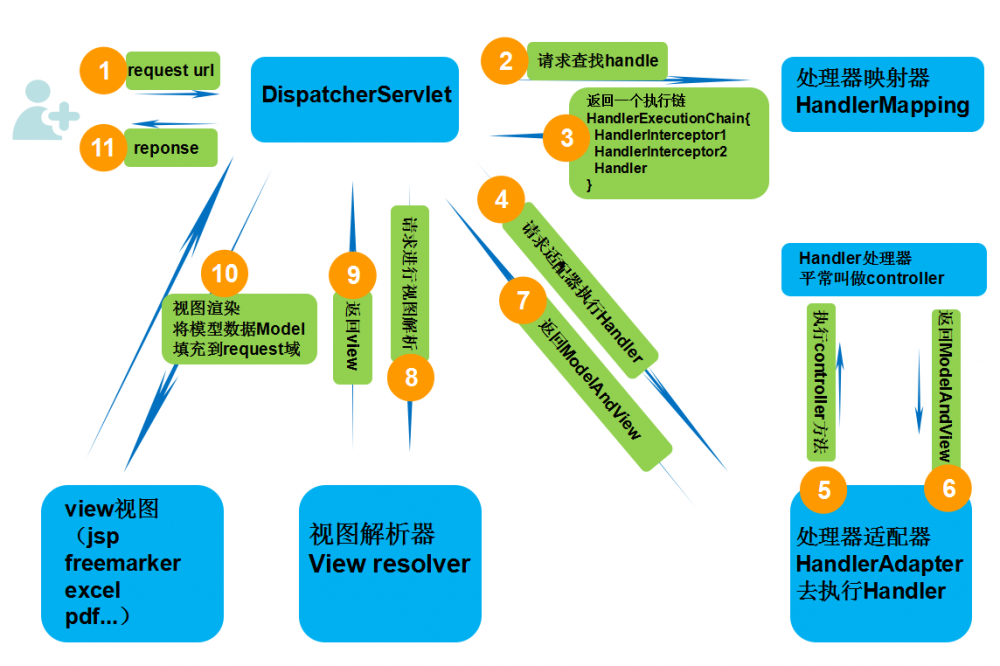
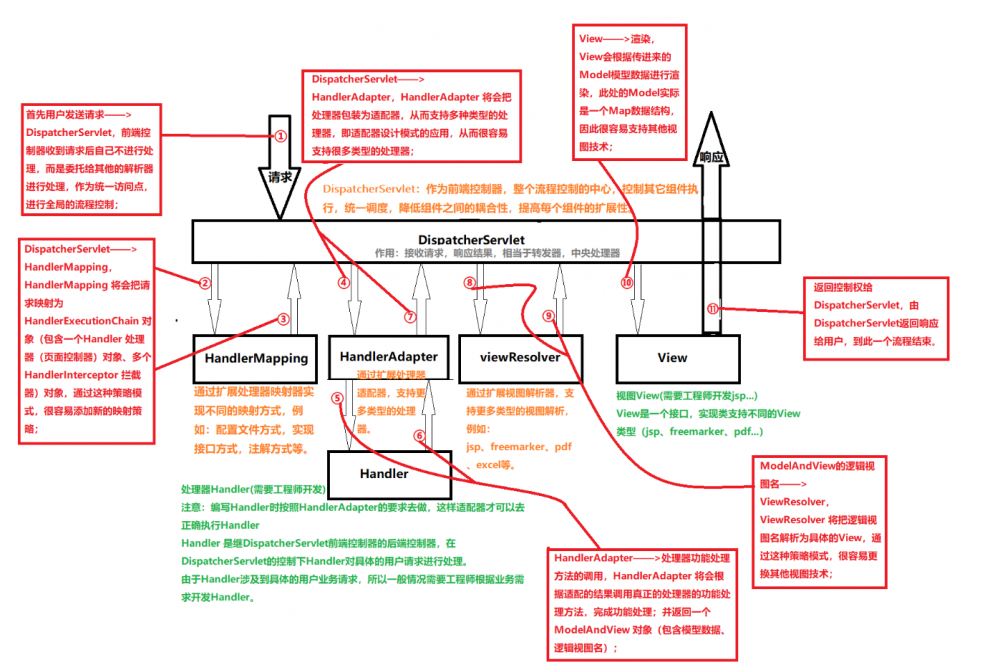
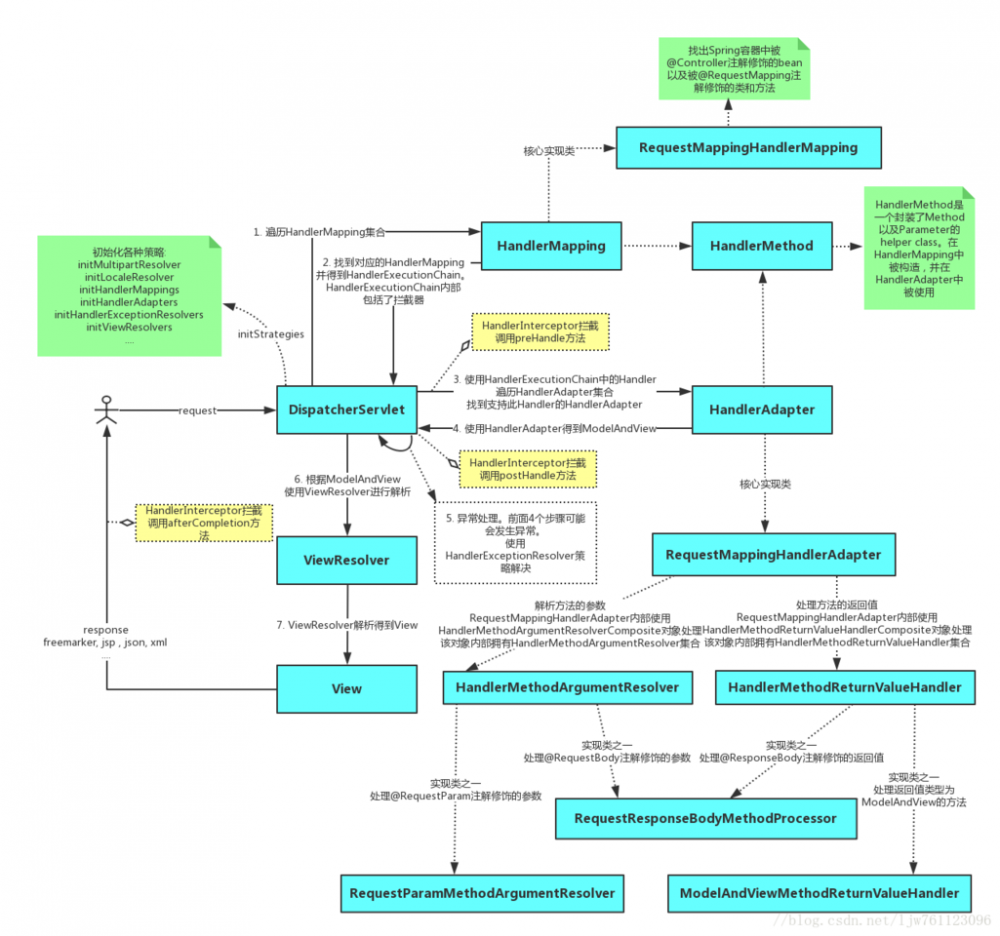
- 请求转发给到DispatcherServlet。
- DispatcherServlet请求HandleMapping,查找到对应的handle。可以根据注解或xml 文件查找。
- 找到对应的handle 之后,会加入一些必要的和配置的拦截器,组成了一个HandleExcutionChain对象返回DispatcherServlet
- DispatcherServlet根据其中的handle,请求对应的HandleAdapter去执行这个handle。并返回一个ModelAndView 对象给到DispatcherServlet。
- DispatcherServlet请求ViewResolver解析这个ModelAndView对象,得到一个View 对象,这个对象比较容易转换成其他的视图技术【】
- 根据得到的view 进行视图的渲染,返回响应给请求。完成此次请求流程。
执行链的执行是按照配置文件的先后顺序执行的。当执行到handle的时候,会去请求合适的HandleAdapter去执行,而不是自己执行。执行之后返回一个ModelAndView对象。之后在请求一个ViewResolver来解析ModelAndView对象得到View对象,这个对象可以用于解析和渲染得到最终的数据。
Spring 的整体的架构
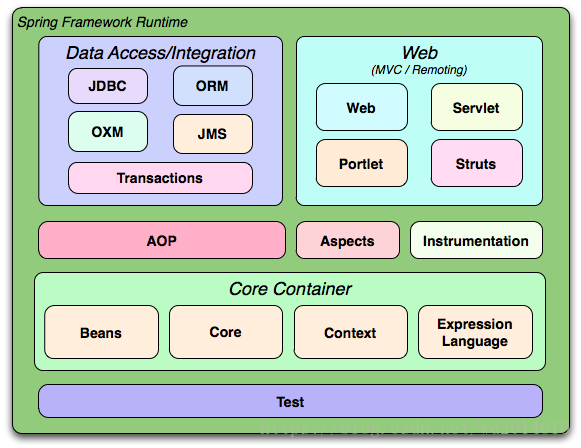
Core Container
ore Container(核心容器)包含Core、Beans、Context和Expression Language模块。Core和Beans模块是框架的基础部分,提供IoC(控制反转)和依赖注入特性。此处涉及到的基础概念是BeanFactory,其提供对于Factory模式的经典实现来消除对程序性单例模式的需要,并真正的允许从程序逻辑中分离出依赖关系和配置。
- Core模块主要包含框架基本的核心工具类,Spring的其他组件都要使用这里的类,是其他组件的基本核心。
- Bean模块是所有应用都要使用到的,包含访问配置文件、创建和管理bean以及进行Inversion of Control/Dependency Injection(IoC/DI)操作相关的所有类。
- Context模块构建于Core和Bean模块基础之上,其提供了一种类似于JNDI注册器的框架式的对象访问方法。其继承了Bean的特性,为Spring核心提供了大量扩展,添加了对国际化(例如资源绑定)、事件传播、资源加载和对Context的透明创建的支持。同时,也支持J2EE的一些特性,例如EJB、JMX和基础的远程处理。ApplicationContext接口是该模块的关键。
- Expression Language模块提供了一个强大的表达式语言用于在运行时查询和操作对象。该语言支持设置/获取属性的值,属性的分配,方法的调用,访问数组上下文(accessiong the context of arrays)、容器和索引器、逻辑和算术运算符、命名变量以及从Spring的IoC容器中根据名称检索对象。同时,也支持list投影、选择和一般的list集合。
Data Access/Integration
Data Access/Integration包含JDBC、ORM、OXM、JMX和Transaction模块。
-
JDBC模块提供一个JDBC抽象层,可以完全消除冗长的JDBC编码和解析数据库厂商特有的错误代码。此模块包含了Spring对JDBC数据访问进行封装的所有类。
-
ORM模块为流行的对象-关系映射API,如JPA、JDO、Hibernate、iBatis等,提供了一个交互层。利用ORM封装包,可以混合使用所有Spring提供的特性进行O/R映射。
-
OXM模块提供了一个对Object/XML映射实现的抽象层,Object/XML映射实现包括JAXB、Castor、XMLBeans、JiBX和XStream。
-
JMS(Java Messaging Service)包含了一些制造和消息消息的特性。
-
Transaction模块支持编程和声明性的事物管理,这些事物必须实现特定的接口,并且对所有的POJO适用。
Web
Web上下文模块建立在应用程序上下文模块之上,为基于Web的应用程序提供上下文。同时,该模块还简化了处理多部分请求以及将请求参数绑定到域对象的工作。
-
Web模块提供了基础的面向Web的集成特性。例如,多文件上传、使用servlet listeners初始化IoC容器以及一个面向Web的应用上下文,还包含了Spring远程支持中Web的相关部分。
-
Web-Servlet模块(web.servlet.jar)包含了Spring的model-view-controller(MVC)实现。Spring的MVC框架使得模型范围内的代码和web forms之间能够清楚地分离开来,并与Spring框架的其他特性集成在一起。
-
Web-Struts模块提供了对Struts的支持,使得类在Spring应用中能够与一个典型的Struts Web层集成在一起。(PS:此支持在Spring3.0中是deprecated的)。
-
Web-Portlet模块提供了用于Portlet环境和Web-Servlet模块的MVC的实现。
AOP
AOP模块提供了一个符合AOP联盟标准的面向切面编程的实现,可以定义例如方法拦截器和切点,从而将逻辑代码分开,降低耦合性。利用source-level的元数据功能,还可以将各种行为信息合并到代码中。通过配置管理特性,该模块直接将面向切面的编程集成到框架中,进而是框架管理的对象支持AOP。同时,该模块为基于Spring的应用程序中的对象提供了事务管理服务。通过使用Spring AOP,不用依赖EJB组件,就可以将声明性事务管理集成到应用程序中。
-
Aspects提供了对AspectJ的集成支持。
-
Instrumentation提供了class instrumentation支持和classloader实现,进而可以在特定的应用服务器上使用。
BeanFactory 和 ApplicationContext 有什么区别
beanfactory and applicationcontext的区别
IoC: 控制反转,是一种思想,表示将由程序员自动创建对象的权限交由spring框架来管理。当使用spring 的时候,对象的创建和其生命周期的维护全权交由spring来做,我们只要给出依赖的配置即可。
Spring IoC容器
Spring IoC容器的设计主要基于下面的两个主要的接口
- BeanFactory
- ApplicationContext
其中,ApplicationContext是BeanFactory的派生接口,但是它实现了更多,更全面的功能,也就是一种更加高级的接口,最常用的一个实现类就是ClassPathXMLApplicationContex类。因此,在绝大部分的时候使用ApplicationContext。
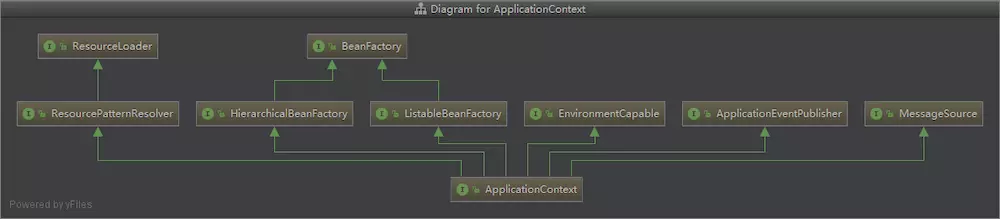
区别
-
BeanFactory: 是Spring中最底层的接口,只提供了最简单的IoC功能,负责配置,创建和管理bean。在应用中,一般不使用 BeanFactory,而推荐使用ApplicationContext
-
ApplicationContext:
- 继承了 BeanFactory,拥有了基本的 IoC 功能;
- 除此之外,ApplicationContext 还提供了以下功能:
- ① 支持国际化;
- ② 支持消息机制;
- ③ 支持统一的资源加载;
- ④ 支持AOP功能;
Spring IoC 的初始化和依赖注入
虽然 Spring IoC 容器的生成十分的复杂,但是大体了解一下 Spring IoC 初始化的过程还是必要的。这对于理解 Spring 的一系列行为是很有帮助的。
使用任何一个类,都需要先定义,声明,初始化这三个步骤。
-
Resource 定位 Spring IoC 容器先根据开发者的配置,进行资源的定位,在 Spring 的开发中,通过 XML 或者注解都是十分常见的方式,定位的内容是由开发者提供的。
-
BeanDefinition 的载入 这个时候只是将 Resource 定位到的信息,保存到 Bean 定义(BeanDefinition)中,此时并不会创建 Bean 的实例
-
BeanDefinition 的注册 这个过程就是将 BeanDefinition 的信息发布到 Spring IoC 容器中 注意:此时仍然没有对应的 Bean 的实例。
Ioc实现
最后我们简单说说IoC是如何实现的。想象一下如果我们自己来实现这个依赖注入的功能,我们怎么来做? 无外乎:
读取标注或者配置文件,看看JuiceMaker依赖的是哪个Source,拿到类名 使用反射的API,基于类名实例化对应的对象实例 将对象实例,通过构造函数或者 setter,传递给 JuiceMaker
区别
-
如果使用ApplicationContext,如果配置的bean是singleton,那么不管你有没有或想不想用它,它都会被实例化。好处是可以预先加载,坏处是浪费内存。
-
BeanFactory,当使用BeanFactory实例化对象时,配置的bean不会马上被实例化,而是等到你使用该bean的时候(getBean)才会被实例化。好处是节约内存,坏处是速度比较慢。多用于移动设备的开发。
-
没有特殊要求的情况下,应该使用ApplicationContext完成。因为BeanFactory能完成的事情,ApplicationContext都能完成,并且提供了更多接近现在开发的功能。
生命周期

Spring上下文中的Bean也类似,【Spring上下文的生命周期】
- 实例化一个Bean,也就是我们通常说的new
- 按照Spring上下文对实例化的Bean进行配置,也就是IOC注入
- 如果这个Bean实现了BeanNameAware接口,会调用它实现的setBeanName(String beanId)方法,此处传递的是Spring配置文件中Bean的ID
- 如果这个Bean实现了BeanFactoryAware接口,会调用它实现的setBeanFactory(),传递的是Spring工厂本身(可以用这个方法获取到其他Bean)
- 如果这个Bean实现了ApplicationContextAware接口,会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文,该方式同样可以实现步骤4,但比4更好,以为ApplicationContext是BeanFactory的子接口,有更多的实现方法
- 如果这个Bean关联了BeanPostProcessor接口,将会调用postProcessBeforeInitialization(Object obj, String s)方法,BeanPostProcessor经常被用作是Bean内容的更改,并且由于这个是在Bean初始化结束时调用After方法,也可用于内存或缓存技术
- 如果这个Bean在Spring配置文件中配置了init-method属性会自动调用其配置的初始化方法
- 如果这个Bean关联了BeanPostProcessor接口,将会调用postAfterInitialization(Object obj, String s)方法注意:以上工作完成以后就可以用这个Bean了,那这个Bean是一个single的,所以一般情况下我们调用同一个ID的Bean会是在内容地址相同的实例
- 当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean接口,会调用其实现的destroy方法
- 最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法以上10步骤可以作为面试或者笔试的模板,另外我们这里描述的是应用Spring上下文Bean的生命周期,如果应用Spring的工厂也就是BeanFactory的话去掉第5步就Ok了
其实在初始化之前的很多东西很像是一个声明,注册的一个过程,使得spring 可以对此bean进行必要的控制的过程。
Bean的创建流程

spring读取配置或注解的过程
1:先通过扫描指定包路径下的spring注解,比如@Component、@Service、@Lazy @Sope等spring识别的注解或者是xml配置的属性(通过读取流,解析成Document,Document)然后spring会解析这些属性,将这些属性封装到BeanDefintaion这个接口的实现类中.
比如这个配置Bean,spring也会将className、scope、lazy等这些属性装配到PersonAction对应的BeanDefintaion中.具体采用的是BeanDefinitionParser接口中的parse(Element element, ParserContext parserContext)方法,该接口有很多不同的实现类。通过实现类去解析注解或者xml然后放到BeanDefination中,BeanDefintaion的作用是集成了我们的配置对象中的各种属性,重要的有这个bean的ClassName,还有是否是Singleton、对象的属性和值等(如果是单例的话,后面会将这个单例对象放入到spring的单例池中)。spring后期如果需要这些属性就会直接从它中获取。然后,再注册到一个ConcurrentHashMap中,在spring中具体的方法就是registerBeanDefinition(),这个Map存的key是对象的名字,比如Person这个对象,它的名字就是person,值是BeanDefination,它位于DefaultListableBeanFactory类下面的beanDefinitionMap类属性中,同时将所有的bean的名字放入到beanDefinitionNames这个list中,目的就是方便取beanName;
spring的bean的生命周期
spring的bean生命周期其实最核心的分为4个步骤,只要理清三个关键的步骤,其他的只是在这三个细节中添加不同的细节实现,也就是spring的bean生明周期:
实例化和初始化的区别:实例化是在jvm的堆中创建了这个对象实例,此时它只是一个空的对象,所有的属性为null。而初始化的过程就是讲对象依赖的一些属性进行赋值之后,调用某些方法来开启一些默认加载。比如spring中配置的数据库属性Bean,在初始化的时候就会将这些属性填充,比如driver、jdbcurl等,然后初始化连接
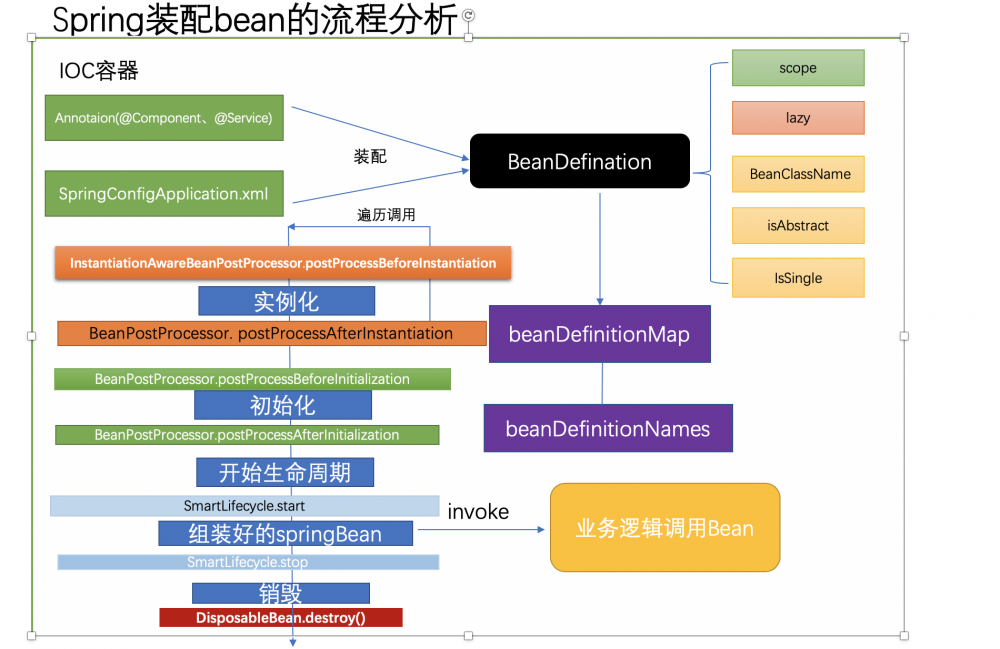
2.1:实例化 Instantiation
AbstractAutowireCapableBeanFactory.doCreateBean中会调用createBeanInstance()方法,该阶段主要是从beanDefinitionMap循环读取bean,获取它的属性,然后利用反射(core包下有ReflectionUtil会先强行将构造方法setAccessible(true))读取对象的构造方法(spring会自动判断是否是有参数还是无参数,以及构造方法中的参数是否可用),然后再去创建实例(newInstance) 复制代码
2.2:初始化
初始化主要包括两个步骤,一个是属性填充,另一个就是具体的初始化过程
2.2.1:属性赋值
PopulateBean()会对bean的依赖属性进行填充,@AutoWired注解注入的属性就发生这个阶段,假如我们的bean有很多依赖的对象,那么spring会依次调用这些依赖的对象进行实例化,注意这里可能会有循环依赖的问题。后面我们会讲到spring是如何解决循环依赖的问题 复制代码
2.2.2:初始化 Initialization
初始化的过程包括将初始化好的bean放入到spring的缓存中、填充我们预设的属性进一步做后置处理等 复制代码
2.3: 使用和销毁 Destruction
在Spring将所有的bean都初始化好之后,我们的业务系统就可以调用了。而销毁主要的操作是销毁bean,主要是伴随着spring容器的关闭,此时会将spring的bean移除容器之中。此后spring的生命周期到这一步彻底结束,不再接受spring的管理和约束。 复制代码
spring 循环依赖
- bean有一个创建中的状态
- bean 有一个提前曝光的机制(所谓的提前曝光,就是仅仅实例化,没有初始化完成的)。这里考虑的是一个bean创建的完整流程是会包括实例化和初始化的。提前曝光就是仅仅实例化还没有初始化。
- 一般的依赖循环发生在setter 里面的单例模式的创建过程中。
spring单例对象的初始化大略分为三步:
- createBeanInstance:实例化,其实也就是调用对象的构造方法实例化对象
- populateBean:填充属性,这一步主要是多bean的依赖属性进行填充
- initializeBean:调用spring xml中的init 方法。
从上面讲述的单例bean初始化步骤我们可以知道,循环依赖主要发生在第一、第二步。也就是构造器循环依赖和field循环依赖。 接下来,我们具体看看spring是如何处理三种循环依赖的。
这三级缓存的作用分别是: singletonFactories : 进入实例化阶段的单例对象工厂的cache (三级缓存) earlySingletonObjects :完成实例化但是尚未初始化的,提前暴光的单例对象的Cache (二级缓存) singletonObjects:完成初始化的单例对象的cache(一级缓存)
通过查询第三级缓存可以知道哪些对象其实已经创建,可以依赖了,尽管此时还没有完成初始化的整个流程。这样就可以提前终止了依赖圈。
这样做有什么好处呢?让我们来分析一下“A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情况。A首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀),B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中。此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进去了一级缓存singletonObjects中,而且更加幸运的是,由于B拿到了A的对象引用,所以B现在hold住的A对象完成了初始化。
正文到此结束
- 本文标签: java struct 开发者 CTO key core Service AOP 构造方法 spring servlet UI 代码 XML src Action IO JVM db 配置 NFV 实例 信息发布 BeanDefinition 一级缓存 索引 tab map API Document spring ioc JMS 二级缓存 ConcurrentHashMap classpath cat 管理 parse 开发 Listeners cache HashMap stream ssl 数据库 移动设备 解析 参数 JPA ORM 模型 缓存 服务器 NSA 程序员 文件上传 生命 ioc id JDBC web https 数据 App list http bean iBATIS AIO
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

