体验了一把线上CPU100%及应用OOM的排查和解决过程
问题现象
【告警通知-应用异常告警】

简单看下告警的信息: 拒绝连接 ,反正就是服务有问题了,请不要太在意马赛克。
环境说明
Spring Cloud F版。
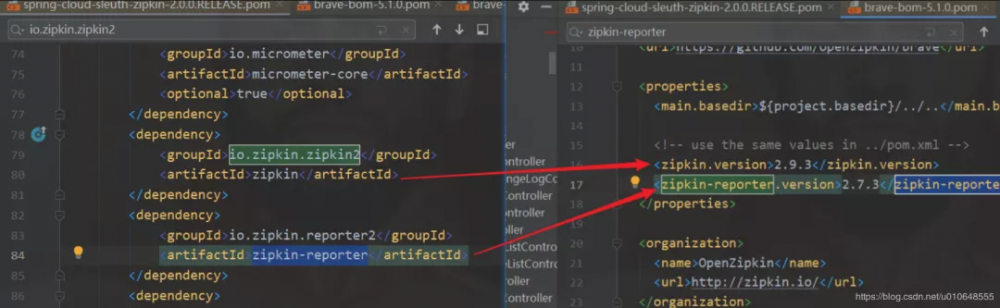
项目中默认使用 spring-cloud-sleuth-zipkin 依赖得到 zipkin-reporter。分析的版本发现是 zipkin-reporter版本是 2.7.3 。
<code><dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin</artifactId> </dependency> </code><button>复制</button>
版本:2.0.0.RELEASE
问题排查
通过告警信息,知道是哪一台服务器的哪个服务出现问题。首先登录服务器进行检查。
1、检查服务状态和验证健康检查URL是否ok
“这一步可忽略/跳过,与实际公司的的健康检查相关,不具有通用性。
- 查看服务的进程是否存在。
ps -ef | grep
服务名 ps -aux | grep
服务名
- 查看对应服务健康检查的地址是否正常,检查 ip port 是否正确
“是不是告警服务检查的url配置错了,一般这个不会出现问题
- 验证健康检查地址
“这个健康检查地址如: http://192.168.1.110:20606/serviceCheck 检查 IP 和 Port 是否正确。
# 服务正常返回结果
curl http://192.168.1.110:20606/serviceCheck
{"appName":"test-app","status":"UP"}
# 服务异常,服务挂掉
curl http://192.168.1.110:20606/serviceCheck
curl: (7) couldn't connect to host
2、查看服务的日志
查看服务的日志是否还在打印,是否有请求进来。查看发现服务OOM了。

tips:java.lang.OutOfMemoryError GC overhead limit exceeded
oracle官方给出了这个错误产生的原因和解决方法:Exception in thread thread_name: java.lang.OutOfMemoryError: GC Overhead limit exceeded Cause: The detail message “GC overhead limit exceeded” indicates that the garbage collector is running all the time and Java program is making very slow progress. After a garbage collection, if the Java process is spending more than approximately 98% of its time doing garbage collection and if it is recovering less than 2% of the heap and has been doing so far the last 5 (compile time constant) consecutive garbage collections, then a java.lang.OutOfMemoryError is thrown. This exception is typically thrown because the amount of live data barely fits into the Java heap having little free space for new allocations. Action: Increase the heap size. The java.lang.OutOfMemoryError exception for GC Overhead limit exceeded can be turned off with the command line flag -XX:-UseGCOverheadLimit.
原因:大概意思就是说,JVM花费了98%的时间进行垃圾回收,而只得到2%可用的内存,频繁的进行内存回收(最起码已经进行了5次连续的垃圾回收),JVM就会曝出ava.lang.OutOfMemoryError: GC overhead limit exceeded错误。

上面tips来源: java.lang.OutOfMemoryError GC overhead limit exceeded
原因分析及解决方案
3、检查服务器资源占用状况
查询系统中各个进程的资源占用状况,使用 top 命令。查看出有一个进程为 11441 的进程 CPU 使用率达到300%,如下截图:

然后 查询这个进程下所有线程的CPU使用情况:
“top -H -p pid 保存文件:top -H -n 1 -p pid > /tmp/pid_top.txt
# top -H -p 11441
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
11447 test 20 0 4776m 1.6g 13m R 92.4 20.3 74:54.19 java
11444 test 20 0 4776m 1.6g 13m R 91.8 20.3 74:52.53 java
11445 test 20 0 4776m 1.6g 13m R 91.8 20.3 74:50.14 java
11446 test 20 0 4776m 1.6g 13m R 91.4 20.3 74:53.97 java
....
查看 PID:11441 下面的线程,发现有几个线程占用cpu较高。
4、保存堆栈数据
- 打印系统负载快照
top -b -n 2 > /tmp/top.txt
top -H -n 1 -p pid > /tmp/pid_top.txt
- cpu升序打印进程对应线程列表
<code>ps -mp-o THREAD,tid,time | sort -k2r > /tmp/进程号_threads.txt </code><button>复制</button>
- 看tcp连接数 (最好多次采样)
<code>lsof -p 进程号 > /tmp/进程号_lsof.txt lsof -p 进程号 > /tmp/进程号_lsof2.txt </code><button>复制</button>
- 查看线程信息 (最好多次采样)
<code>jstack -l 进程号 > /tmp/进程号_jstack.txt jstack -l 进程号 > /tmp/进程号_jstack2.txt jstack -l 进程号 > /tmp/进程号_jstack3.txt </code><button>复制</button>
- 查看堆内存占用概况
<code>jmap -heap 进程号 > /tmp/进程号_jmap_heap.txt </code><button>复制</button>
- 查看堆中对象的统计信息
jmap -histo 进程号 | head -n 100 > /tmp/进程号_jmap_histo.txt
- 查看GC统计信息
<code>jstat -gcutil 进程号 > /tmp/进程号_jstat_gc.txt </code><button>复制</button>
- 生产对堆快照Heap dump
<code>jmap -dump:format=b,file=/tmp/进程号_jmap_dump.hprof 进程号 </code><button>复制</button>
堆的全部数据,生成的文件较大。
jmap -dump:live,format=b,file=/tmp/进程号_live_jmap_dump.hprof 进程号
dump:live,这个参数表示我们需要抓取目前在生命周期内的内存对象,也就是说GC收不走的对象,一般用这个就行。
拿到出现问题的快照数据,然后重启服务。
问题分析
根据上述的操作,已经获取了出现问题的服务的GC信息、线程堆栈、堆快照等数据。下面就进行分析,看问题到底出在哪里。
1、分析cpu占用100%的线程
转换线程ID
从jstack生成的线程堆栈进程分析。
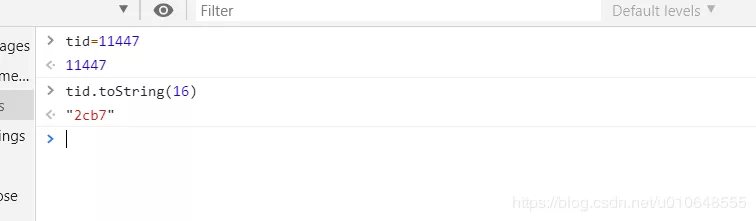
将 上面线程ID 为
11447 :0x2cb7
11444 :0x2cb4
11445 :0x2cb5
11446 :0x2cb6
转为 16进制(jstack命令输出文件记录的线程ID是16进制)。
第一种转换方法 :
$ printf “0x%x” 11447
“0x2cb7”
第二种转换方法 : 在转换的结果加上 0x即可。
查找线程堆栈
$ cat 11441_jstack.txt | grep "GC task thread"
"GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007f971401e000 nid=0x2cb4 runnable
"GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007f9714020000 nid=0x2cb5 runnable
"GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007f9714022000 nid=0x2cb6 runnable
"GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007f9714023800 nid=0x2cb7 runnable
发现这些线程都是在做GC操作。
2、分析生成的GC文件
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 100.00 99.94 90.56 87.86 875 9.307 3223 5313.139 5322.446
S0:幸存1区当前使用比例
S1:幸存2区当前使用比例
E:Eden Space(伊甸园)区使用比例
O:Old Gen(老年代)使用比例
M:元数据区使用比例
CCS:压缩使用比例
YGC:年轻代垃圾回收次数
FGC:老年代垃圾回收次数
FGCT:老年代垃圾回收消耗时间
GCT:垃圾回收消耗总时间
FGC 十分频繁。
3、分析生成的堆快照
使用 Eclipse Memory Analyzer 工具。
分析的结果:
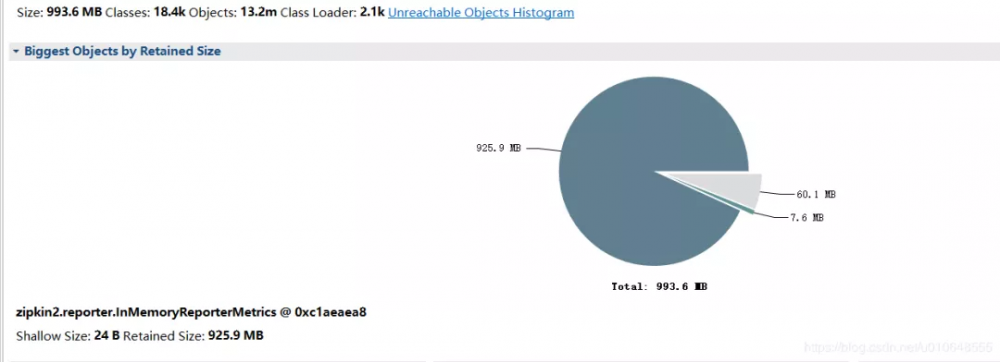
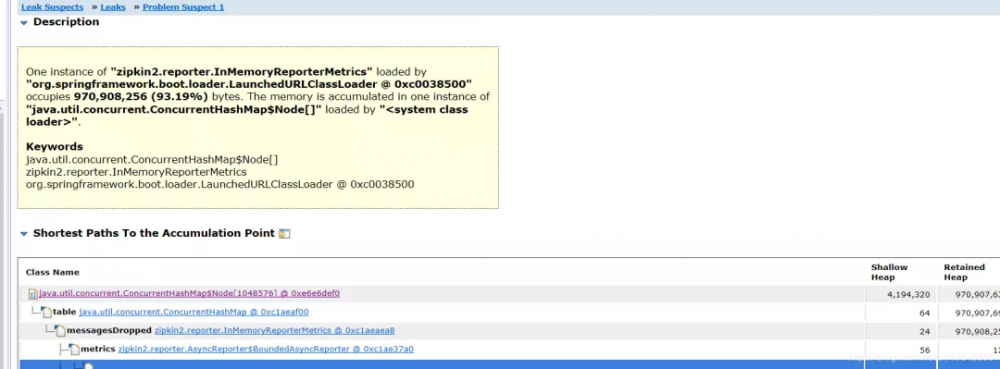
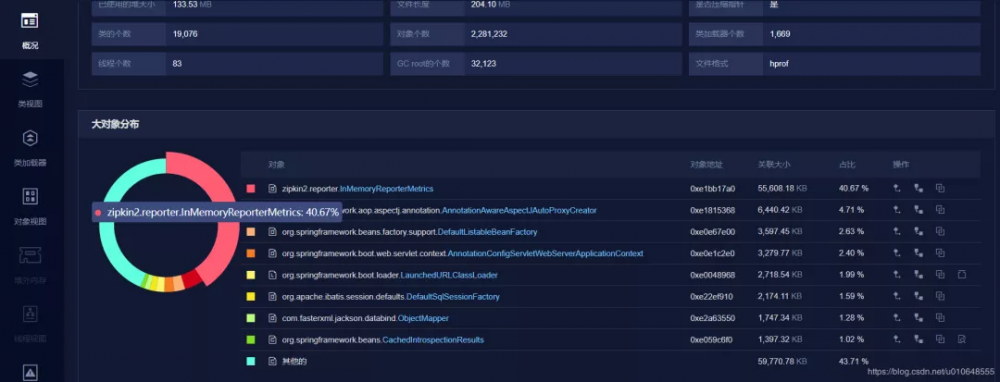
看到堆积的大对象的具体内容:

问题大致原因,InMemoryReporterMetrics 引起的OOM。
zipkin2.reporter.InMemoryReporterMetrics @ 0xc1aeaea8
Shallow Size: 24 B Retained Size: 925.9 MB
也可以使用:Java内存分析进行分析,如下截图。
4、原因分析和验证
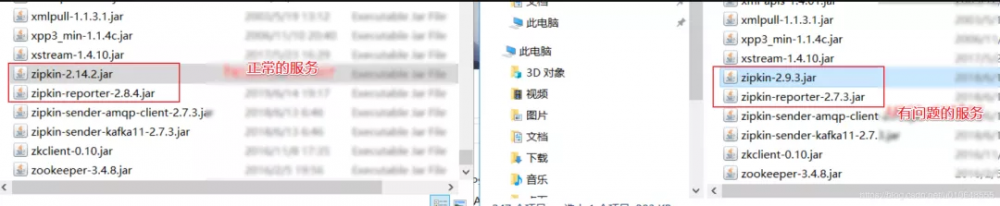
因为出现了这个问题,查看出现问题的这个服务 zipkin的配置,和其他服务没有区别。发现配置都一样。
然后看在试着对应的 zipkin 的jar包,发现出现问题的这个服务依赖的 zipkin版本较低。
有问题的服务的 zipkin-reporter-2.7.3.jar
其他没有问题的服务 依赖的包 :zipkin-reporter-2.8.4.jar
将有问题的服务依赖的包版本升级,在测试环境进行验证,查看堆栈快照发现没有此问题了。
原因探索
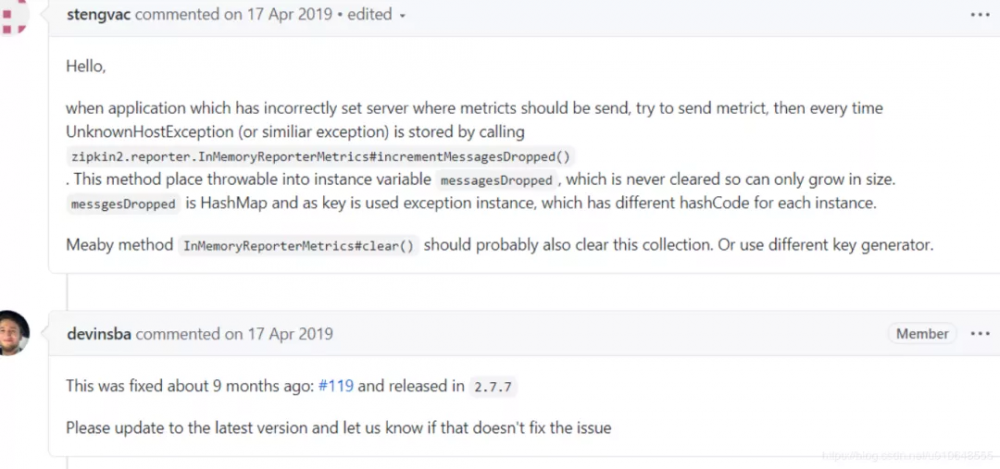
查 zipkin-reporter的 github:搜索 相应的 资料
找到此 下面这个 issues
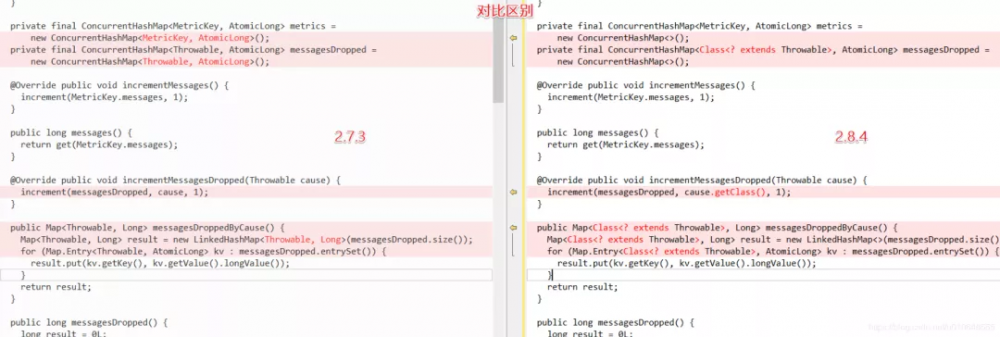
修复代码和验证 代码
对比两个版本代码的差异:
简单的DEMO验证:
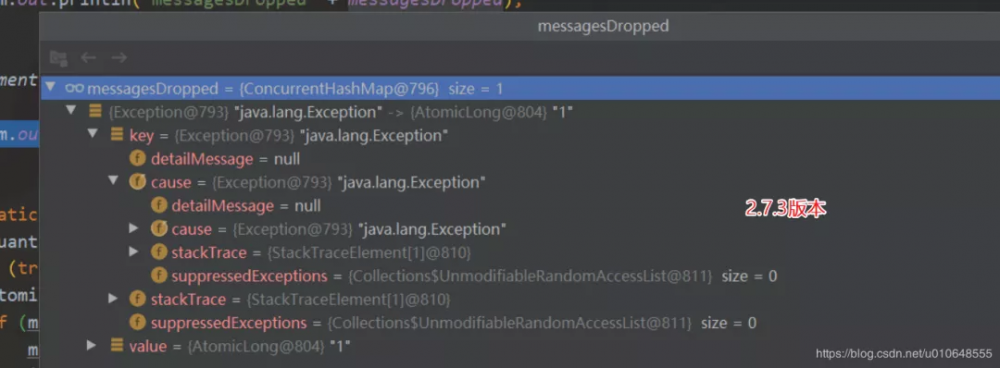
// 修复前的代码:
private final ConcurrentHashMap<Throwable, AtomicLong> messagesDropped =
new ConcurrentHashMap<Throwable, AtomicLong>();
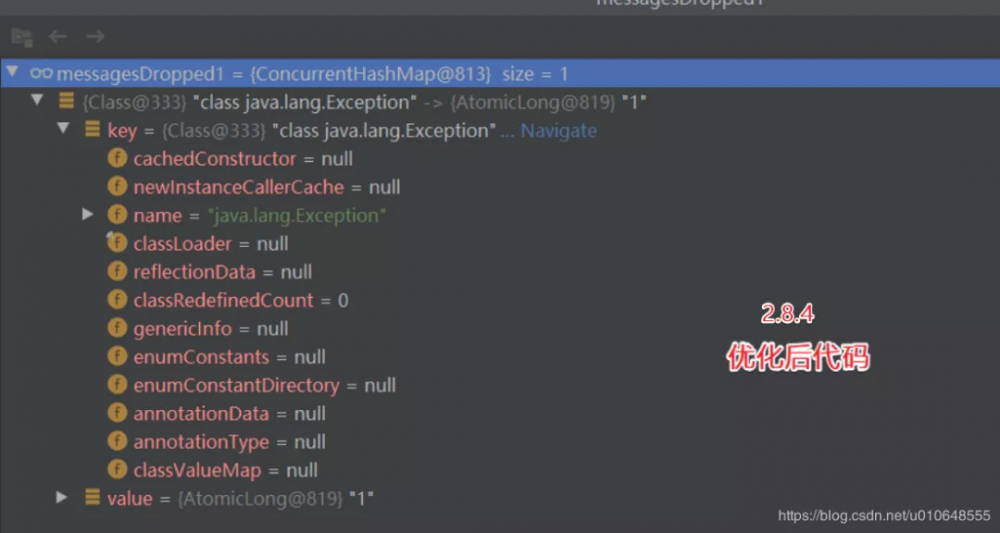
// 修复后的代码:
private final ConcurrentHashMap<Class<? extends Throwable>, AtomicLong> messagesDropped =
new ConcurrentHashMap<>();
修复后使用 这个key :Class<? extends Throwable> 替换 Throwable。
简单验证:
解决方案
将zipkin-reporter 版本进行升级即可。使用下面依赖配置,引入的 zipkin-reporter版本为 2.8.4 。
<!-- zipkin 依赖包 -->
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave</artifactId>
<version>5.6.4</version>
</dependency>
小建议:配置JVM参数的时候还是加上下面参数,设置内存溢出的时候输出堆栈快照.
<code> -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=path/filename.hprof </code><button>复制</button>
正文到此结束
- 本文标签: 服务器 tar UI App 统计 Action zipkin zip 配置 CTO src Atom id java js map TCP final message 垃圾回收 测试环境 spring https cat 时间 解决方法 ACE Collection JVM git 进程 代码 参数 jstack IO ConcurrentHashMap ip 线程 GitHub key 生命 ORM HashMap eclipse Oracle FIT Collections http constant Sleuth 测试 grep 数据 HTML ask Service Spring cloud
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

