Jar包冲突问题原理及解决方案
背景:
新需求需要引入新jar包,引入后发现本地启动没有报错,发到测试环境提示某个bean无法创建,nested exception is java.lang.VerifyError: Bad type on operand stack。
解决:
1,没有引入新jar包之前是没有提示这个报错了,猜测是jar包冲突。
2,到测试环境的lib目录根据新引入jar包的关键字找到如图所示的jar,图中最下面三个jar是新功能需要引入的jar,多了excelmagic-1.3-20190806.100559-3.jar这个包,基本确定是这个jar造成的冲突。
3,通过idea自带的show dependencies没有找到这个jar是哪个包引入的
4,通过maven helper没有找到关于这个jar的冲突记录
5,快11点了下班回家。回到家灵机一动,能否从jenkins构建日志查查。最终根据这个jar的关键字找到如图构建日志:
6,在引入这个baseinfo包的地方exclusion掉excelmagic之后,重新构建成功。
<exclusion> <artifactId>excelmagic</artifactId> <groupId>com.隐藏.fop.fnp.excelmagic</groupId> </exclusion>
7,回过头来用maven helper查看,至此不明白的地方在于为何这个excelmagic包没有体现在baseinfo包上,并且这个networkinit包在pom里是已经做了exclude的
8,把目光集中在引入baseinfo包的exclusion的写法上,如下:
<exclusion> <groupId>*</groupId> <artifactId>*</artifactId> </exclusion>
这个用法没怎么用过,不清楚啥原理。将其注释后,在maven helper能找到excelmagic这个包是由baseinfo引入的。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
时间:2020-07-17
Hbase、elasticsearch整合中jar包冲突的问题解决
问题背景 再数据平台中,项目搭建需要使用es和HBASE搭建数据查询接口,整合的过程中出现jar包冲突的bug :com.google.common.base.Stopwatch.()V from class org.apache.hadoop.hbase.zookeeper.MetaTableLocator org.apache.hadoop.hbase.DoNotRetryIOException: java.lang.IllegalAccessError: tried to access m
如何用Intellij idea2020打包jar的方法步骤
这篇博客,由图片构成,方便我自己记住如何打包,最后一张图带上,如何引入第三方文件 1. 自己鼓捣一个工程,一路新建哈 2.在工程上右键,然后点击Open Moudle Setting 3. 选择 Artifacts 翻译成中文"史前古器物" 看来这个词来自考古学.意思是打包就变成古董了. 4. 顶部的条理,选择 build Artifacts 5. 成功的用Intellij 做成了一个jar 6. 如何引入第三方类包,进行开发 工程下新建一个文件夹 lib 将需要用的第三方类包拷贝进来
服务器使用Nginx部署Springboot项目的详细教程(jar包)
1,将java项目打成jar包 这里我用到的是maven工具 这里有两个项目,打包完成后一个为demo.jar,另一个为jst.jar 2.准备工具 1.服务器 2.域名(注:经过备案) 3.Xshell用于连接服务器 4.WinScp(注:视图工具,用于传输jar) 3.将jar包传入服务器 直接拖动即可 3.使用Xshell运行jar包 注:(服务器的java环境以及maven环境,各位请自行配置,这里不做描述.) cd到jar包路径下执行:nohup java -jar demo.jar
完美解决android 项目jar包冲突的问题
大家在做开发中竟然需要用到一些三方库 或者 需要集成三方的SDK开发包,尤其是项目特别庞大的时候,引用的三方的东西特别多,那么肯定会碰到一些jar包冲突的情况. 常见的情况有以下几种 1.项目自己引用jar包重复 2.项目中jar包和三方SDK 3.三方sdk之间都含有相同类 4.打包时候出现编译错误,出现冲突 1.项目自己引用jar包重复 com.android.dex.DexException: Multiple dex files define Landroid/support/v4/ac
Maven jar包冲突的解决方案
现象 创建一个maven工程,引入spring-context包. <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>5.0.8.RELEASE</version> </dependency> 此时看左侧的lib,我们发现引入了一个坐标,多出了很多的jar包,这
一文解决springboot打包成jar文件无法正常运行的问题
1.用intellij idea 创建了一个springboot的项目,前期都运行的好好的,在ide中可以正常运行,但是打包成Jar运行却一直报错. 2.经过不懈探索,终于找到解决办法 3.首先,找到pom.xml,把下面的build块中的内容改成如下所示 <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-
Jar包一键重启的Shell脚本及新服务器部署的一些经验分享
前言 最近公司为客户重新部署了一套新环境,由我来完成了基础环境的配置,配置过程中总结了一些经验,分享给各位园友 使用 curl 命令检查网络 拿到新服务器后,首先检查服务器网络是否通畅.我们常用的 ping 命令使用的是 ICMP 协议,大部分服务器都设置了域名出入站规则,即使某些地址可以 ping 通,也存在服务器无法访问的情况.这时可以使用 curl host:port 命令来测试该服务器能否正常发送 http 请求到外部服务器 安装 JDK 新服务器一般没有 JDK ,可以使用 java
JMeter导入自定义的Jar包的详解教程
1.简介 原计划这一篇是介绍前置处理器的基础知识的,结果由于许多小伙伴或者童鞋们在微信和博客园的短消息中留言问如何引入自己定义的Jar包呢???我一一回复告诉他们和引入插件的Jar包一样的道理,一通百通.但是感觉他们还是很迷糊很迷惘,因此在这里穿插一篇导入自定义的Jar包.还有另外一个原因就是前置处理器会用到这个自定义的Jar包. 2.环境准备 (1)Eclipse 我们要引入自定义的Jar包,所以你需要一个可以编写脚本生成Jar的工具,当然了你可以选择其他的开发工具,宏哥这里选择Eclipse
在eclipse导入Java的jar包的方法JDBC(图文说明)
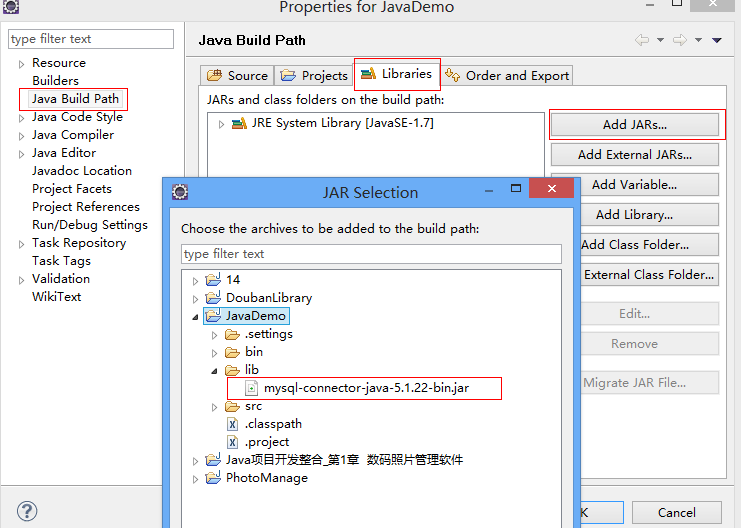
在使用JDBC编程时需要连接数据库,导入JAR包是必须的,导入其它的jar包方法同样如此,导入的方法是 打开eclipse 1.右击要导入jar包的项目,点properties 2.左边选择java build path,右边选择libraries 3.选择add External jars 4.选择jar包的按照路径下的 确定后就行了. Java连接MySQL的最新驱动包下载地址 http://www.mysql.com/downloads/connector/j 有两种方法导入jar包
对Golang import 导入包语法详解
package 的导入语法 写 Go 代码的时经常用到 import 这个命令用来导入包,参考如下: import( "fmt" ) 然后在代码里面可以通过如下的方式调用: fmt.Println( "我爱北京天安门" ) fmt 是 Go 的标准库,它其实是去 GOROOT 下去加载该模块,当然 Go 的 import 还支持如下两种方式来加载自己写的模块: 相对路径 import "./model" // 当前文件同一目录的 model 目录
Maven设置使用自定义的jar包到自己本地仓库
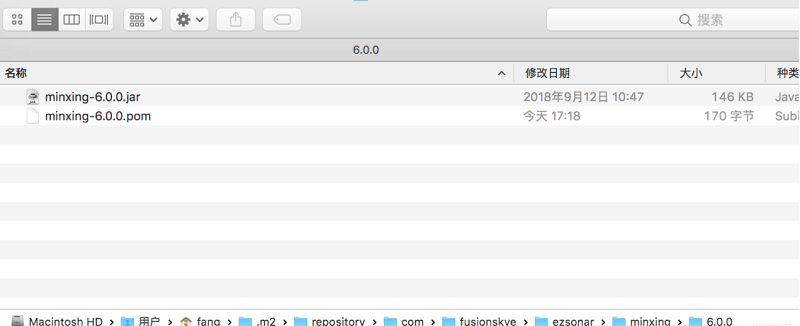
maven设置使用自定义的jar包到自己在Maven框架里,查找依赖包的顺序: 1.先在本地仓库找,有就返回,没有继续第二步: 2.到中央仓库 http://search.maven.org/ 找,有就返回,没有继续第三步: 3.在 Maven 远程仓库搜索,远程仓库,就的自己在pom文件设置. 如何在Local Repository(本地仓库)设定自行开发的Jar包 首先,找到Local Repository(本地仓库)的位置, 默认在C:/Users/King/.m2/repository,
Spring MVC自定义日期类型转换器实例详解
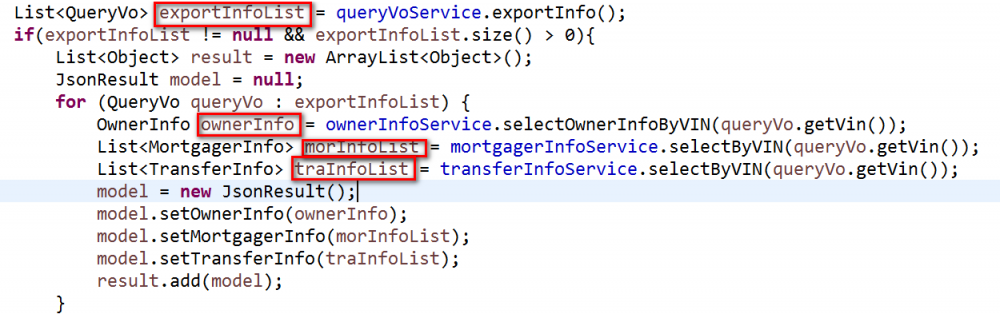
Spring MVC自定义日期类型转换器实例详解 WEB层采用Spring MVC框架,将查询到的数据传递给APP端或客户端,这没啥,但是坑的是实体类中有日期类型的属性,但是你必须提前格式化好之后返回给它们.说真的,以前真没这样做过,之前都是一口气查询到数据,然后在jsp页面上格式化,最后展示给用户.但是这次不同,这次我纯属操作数据,没有页面.直接从数据库拿数据给它们返数据.它们给我传数据我持久化数据,说到这里一个小问题就默默的来了. 首先把问题还原一下吧(这是一个数据导出功能),下图中用红框圈
对Python模块导入时全局变量__all__的作用详解
Python中一个py文件就是一个模块,"__all__"变量是一个特殊的变量,可以在py文件中,也可以在包的__init__.py中出现. 1.在普通模块中使用时,表示一个模块中允许哪些属性可以被导入到别的模块中, 如:全局变量,函数,类.如下,test1.py和main.py test1.py __all__=["test"] def test(): print('----test-----') def test1(): print('----test1----
Spark自定义累加器的使用实例详解
累加器(accumulator)是Spark中提供的一种分布式的变量机制,其原理类似于mapreduce,即分布式的改变,然后聚合这些改变.累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数. 累加器简单使用 Spark内置的提供了Long和Double类型的累加器.下面是一个简单的使用示例,在这个例子中我们在过滤掉RDD中奇数的同时进行计数,最后计算剩下整数的和. val sparkConf = new SparkConf().setAppName("Test").setM
Android 自定义返回按钮的实例详解
Android 自定义返回按钮的实例详解 程序中我们有时候想让放回按钮按照自己的需求调整页面而不是单纯的按照系统返回上一级,这个问题很简单,重写 onKeyDown 方法即可. 下面方法,包含了 webview 中的返回上一页和普通 activity 的单击设置和双击退出程序. @Override public boolean onKeyDown(int keyCode, KeyEvent event) { //如果我们用的是webview页面,想返回网页的上一页设置这里就可以了 if (key
对Pycharm创建py文件时自定义头部模板的方法详解
如下所示: # -*- coding: utf-8 -*- """ ------------------------------------------------- File Name: ${NAME} Description : Author : ${USER} date: ${DATE} ------------------------------------------------- Change Activity: ${DATE}: ----------------
Element-ui tree组件自定义节点使用方法代码详解
工作上使用到element-ui tree 组件,主要功能是要实现节点拖拽和置顶,通过自定义内容方法(render-content)渲染树代码如下~ <template> <div class="sortDiv"> <el-tree :data="sortData" draggable node-key="id" ref="sortTree" default-expand-all :expand-
Oracle自定义脱敏函数的代码详解
对于信息安全有要求的,在数据下发和同步过程中需要对含有用户身份信息的敏感字段脱敏,包括用户姓名.证件号.地址等等,下面是自定义函数的代码 CREATE OR REPLACE FUNCTION F_GET_SENSITIVE(IN_STR VARCHAR, IN_TYPE NUMBER) RETURN VARCHAR2 IS V_STR_LENGTH NUMBER; V_NAME VARCHAR2(1000); V_N NUMBER; V_HID VARCHAR2(200); V_SQL VARC
正文到此结束
- 本文标签: 服务器 db js HBase 数据 域名 插件 http plugin bug mysql Nginx node https 安全 调试 JMeter key src bean Elasticsearch root tab ip apr UI 注释 Excel lib 处理器 springboot 2019 Hadoop shell cat 配置 时间 XML build Java环境 分布式 部署 web 测试 eclipse 数据库 安装 需求 实例 同步 下载 id rand apache 翻译 pom Oracle map 代码 Android 总结 python 希望 retry java 协议 maven description sql Google App 开发 ACE IO 测试环境 spring 编译 jenkins zookeeper IDE CTO dependencies 博客 图片 JDBC 目录
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

